
Spring Stereotype
Beans
우리가 쓰는 Component, Controller, Repository 등이 담겨 있는 곳이 org.stereotype이다. Spring boot의 작동 원리는 Bean 객체를 만든 뒤 IoC Container가 가지고 있다가 필요한 곳에 가져다 사용하는 것이다. 여기에서 라이브러리와의 차이점이 있다. 라이브러리는 이미 만들어진 코드를 내가 가져다가 쓰는 것이지만, 프레임워크는 내 코드를 가져다가 쓰는 것이다.
Annotation들은 구현된 기능상의 차이점도 있지만 주된 목적은 역할의 표시이다. 해당 클래스가 어떤 역할을 하는지 명확히 확인이 가능한 것이다. Annotation 기반의 관점 지향 프로그래밍이다. 넓은 의미에서 같은 역할을 했으면 좋겠다고 명시해 주는 것이다.
Stereotype이라는 이름이 붙은 이유는 다음과 같다. 사전적 정의를 따지면 고정적이거나 일반적인 패턴에 부합하는 것이라고 나온다. 즉, 실질적인 구현보다 역할적인 구분에 초점을 두고 있다는 것을 알 수 있다.
Component
Component
Controller, Service, Repository가 아닌 평범한 Bean 객체를 나타내는 Annotation이다.
Controller, Service, Repository 모두 Component의 하위 개념이라고 생각해도 좋다. Spring boot의 기능을 적극적으로 사용하는 것보다 외부 API를 사용한다거나 공유된 기능을 개발한다거나 IoC에 등록해야 할 일이 있는 객체를 Component로 정의한다.
Controller
Controller
사용자의 입력을 직접 받는 곳이다. MVC 패턴에서 C를 담당한다. 사용자의 요청을 받아 해석한 뒤 서비스로 넘겨 주는 역할을 한다.
RequestMapping()과 같은 Annotation을 활용할 수 있다. Spring boot 관점에서는 Controller가 붙은 객체들은 RequestMapping을 사용할 것이라고 예상할 수 있기 때문에, Controller로 이미 등록된 객체들만 RequestMapping 과 같은 기능을 사용할 수 있다.
@GetMapping("home")
public String home() {
return "home";
}위의 경우 home이라는 String을 반환하면 View Resolver가 html 요소를 훑어 보고 home이라는 이름을 가진 html 을 반환한다. 백엔드 개발의 경우 html 외에도 반환해 줘야 할 값이 매우 많기에 이는 효율적이지 않다.
@GetMapping("body")
public @ResponseBody String body() {
return "body";
}이럴 경우 @ResponseBody라는 Annotation을 추가해 **html이 아닌 data 형식**으로 반환할 수 있다. 즉 나는 데이터를 돌려 주겠다고 명시하는 것이다. 백과 프론트의 구조적인 구분을 위해 이를 더 많이 사용한다.
API마다 반환해야 할 data 형식이 다를 수도 있는데, 이를 메소드마다 붙이는 것이 번거로울 수도 있다. 따라서 클래스 앞에 @Controller가 아닌 @RestController를 사용한다. @RestController는 모든 메소드에 @ResponseBody를 붙인 클래스라고 생각하면 된다.
Service
Service
주된 비즈니스 로직이 구현되는 공간이다.
Controller와 Service를 분리하는 이유는, 예를 들어 나중에 다른 요청을 받을 때로 Controller를 수정할 일이 생긴다면 Service는 건드리지 않아도 되는 유지 보수의 편리함 때문이다.
Service에서는 Controller에서 해석해서 온 요청에 따라 1. 데이터베이스를 조회 2. Componenet 사용 3. 모은 데이터를 이용해서 의사 결정 등을 한다.
Repository
Repository
데이터베이스와의 소통을 담당한다.
전체적인 큰 흐름을 봤을 때 Controller → Service → Repository 순으로 정보를 전달하면서 데이터베이스에 접근해 CRUD 작업을 한다.
Configuration
Configuration
Spring을 활용하는 데 필요한 다양한 설정을 담고 있는 용도이다.
예를 들어 비즈니스 로직 처리를 위해 외부 api를 사용해야 한다. 즉 참고해야 할 외부 url 이 있다고 생각해 보자. 그러나 서비스를 구동하는 과정에서 참고할 url이 변동적일 수도 있다. API Component의 설정값에 따라 참고해야 할 url이 다를 경우 이를 Configuration으로 관리할 수 있다.
@Configuration
public class AppConfiguration {
@Bean
public String connectionUrl() {
// 이 메소드의 결과를 Bean 객체로 등록
if(/*현재 나의 상황에 따라 다른 url을 반환*/) {
return "main-url";
}
else return "backup-url";
}
}JPA
Project
Spring Initializer를 통해서 다음과 같이 새 프로젝트를 빌드한다.
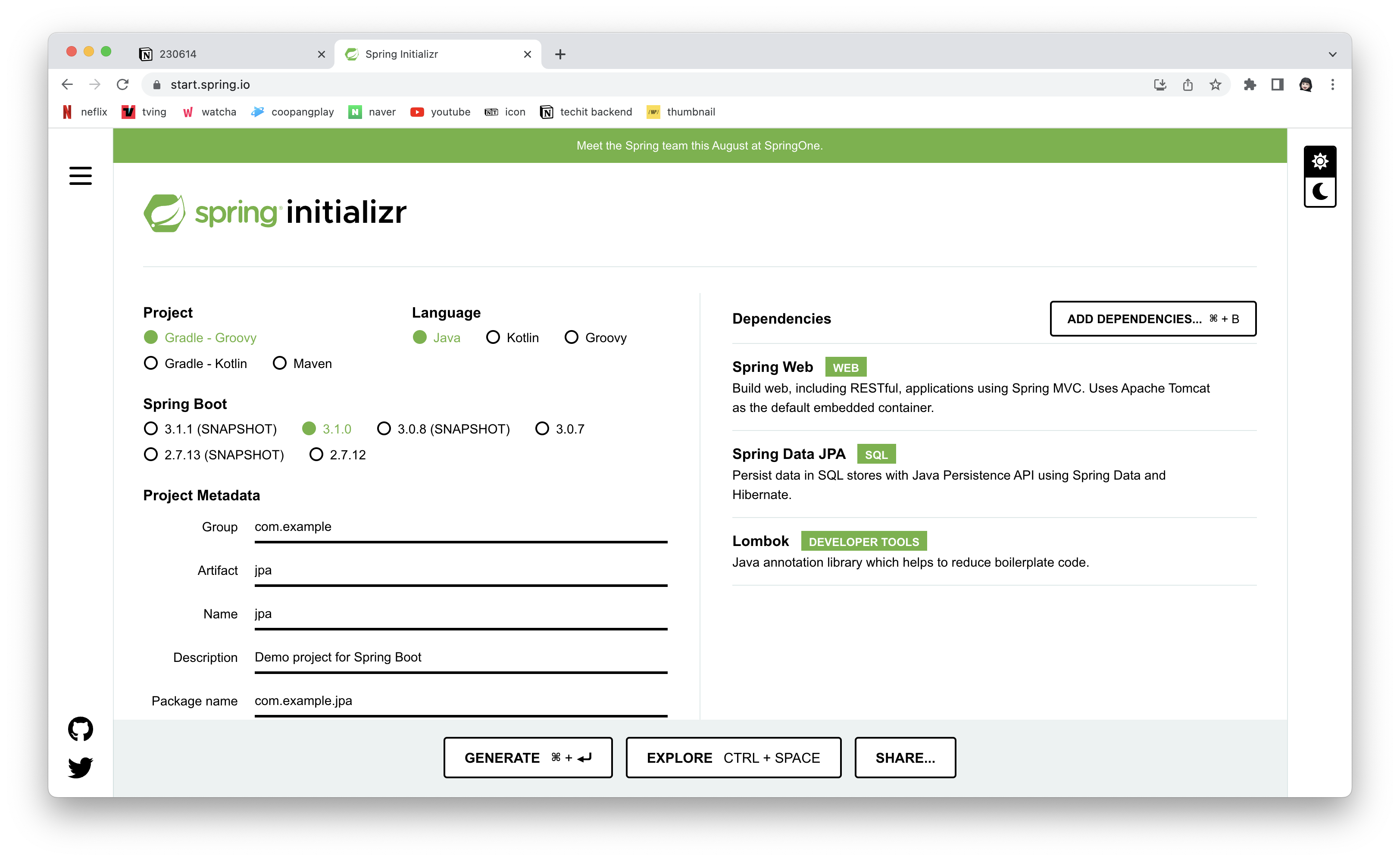
이후 의존성을 다음과 같이 추가해 준다.
// gson
implementation 'com.google.code.gson:gson:2.10.1'
// sqlite
runtimeOnly 'org.xerial:sqlite-jdbc:3.41.2.2'
runtimeOnly 'org.hibernate.orm:hibernate-community-dialects:6.2.4.Final'이후 application.yaml 파일을 생성해 설정을 마무리해 준다.
spring:
datasource:
url: jdbc:sqlite:db.sqlite
driver-class-name: org.sqlite.JDBC
jpa:
hibernate:
ddl-auto: create
show-sql: true
database-platform: org.hibernate.community.dialect.SQLiteDialectHibernate를 사용하는 데 필요한 설정들을 보자. show-sql은 JPA에서 자동으로 생성해 주는 sql 문을 console에 찍어서 확인할 수 있게 해 주는 옵션이다. ddl-auto 속성은 create로 두면 실행할 때마다 자동으로 삭제하고 다시 만든다. create-drop으로 두면 spring이 꺼지면서 자동으로 테이블도 날린다. 따라서 두 옵션은 테스트 용도로 사용하는 경우가 많다. none 같은 경우는 테이블은 내가 관리할 테니 hibernate가 관리하지 못하도록 한다. database-platform 은 데이터베이스마다 자료형이나 함수 같은 부분이 제품마다 조금씩 다를 수 있다. 따라서 제품마다 조금씩 다른 쿼리를 조정해 주기 위해 SQLIteDialect를 사용해 달라고 요청한 것이다. 실무에서는 내가 사용하는 제품에 따라 다르다.
Controller는 사용자의 입력을 해석해서 Service에 넘겨 주는 역할을 한다. 따라서 Service와 소통할 줄 알아야 한다. 소통해야 하는 부분을 객체로 생성하고 생성자를 통하면 된다.
@Controller
public class AppController {
**private final AppService service;
public AppController(AppService service) {
this.service = service;
}**
@RequestMapping("student")
public void student() {
List<Object> result = **service.readStudentAll();**
}
@GetMapping("home")
public String home() {
return "home";
}
@GetMapping("body")
public @ResponseBody String body() {
return "body";
}
}Service는 직접적으로 데이터베이스랑 소통하기보다 받아온 데이터를 이용해 비즈니스 로직만 담당하는 것이 권장된다. 데이터베이스 사용 권한은 Repository를 통해 하도록 한다. 즉 의존성을 주입받아서 Service와 Repository를 연결하는 것이다. 생성자를 굳이 만들지 않고 lombok annotation을 사용해도 된다 (@AllArgsConstructor)
@Service
public class AppService {
**private final AppRepository repository;
public AppService(AppRepository repository) {
this.repository = repository;
}**
public List<Object> readStudentAll() {
List<Object> queryResult = repository.selectStudentAll();
return queryResult;
}
}이후 실제로 데이터베이스와 접근하는 코드를 Repository에 작성하면 된다.
@Repository
public class AppRepository {
public List<Object> selectStudentAll() {
return new ArrayList<>();
}
}JPA Start
가장 많이 사용하는 관계형 데이터베이스는 데이터를 테이블의 형태로 관리한다. JAVA에서는 데이터를 객체를 통해 관리하고 있다. 우리가 객체 지향 언어를 쓰고 객체를 정의해서 쓰고 있는데, 객체 정보를 담고 있는 데이터베이스는 표현이 매우 어렵기 때문에 JPA가 시작되었다.
ORM(Object Relational Mapping)
객체지향적 관점에서 객체를 사용하여 관계형 데이터베이스를 사용하는 기술이다. 객체를 테이블 및 레코드에 매핑해 주는 것이다.
우리가 사용하는 언어는 객체지향 프로그래밍 언어로 객체와 객체가 상호작용한다. 또는 하나의 객체가 다른 객체를 소유하고 있을 수 있다.
public class Food {
private String name;
private Integer price;
private String category;
}하지만 관계형 데이터베이스는 한 컬럼에 다른 객체에 대한 정보를 직접 다룰 수 없고 조회 후에 별도로 Join이 필요하다.
| id | name | price | category |
|---|---|---|---|
이때 ORM 기술을 사용하면 생산성이 증가되고 중복이 감소하고 데이터베이스 의존성이 감소한다. 설정하게 줄어든다는 것은 장점이라기보다는 현상으로 이해하는 것이 좋다. 데이터베이스와 직접 소통하는 여지를 줄여 주는 것이다. 실제 SQL을 작성하지 않고 위임하기 때문에 성능에 영향이 없지 않다.
JPA 프레임워크가 자동으로 SQL문을 작성해 준다. 말만 들으면 좋아 보이지만 단점으로 작용할 수 있다. 세심한 SQL을 작성도 가능하지만 이를 제대로 사용하기 위한 프레임워크를 익히는 방법이 더욱 어려울 수도 있다.
JPA & Hibermate
JPA는 Java Persistence API로 ORM 기술이 아닌 객체를 꾸며 주는 용도의 Annotation으로 구성되는 라이브러리이다. 즉 데이터가 어떻게 테이블에 매핑되는지 명세하기 위한 Interface와 Annotation으로 구성되어 있다.
이를 실제로 테이블로 옮겨 주는 역할은 Hibernate가 한다. JPA 명세를 바탕으로 작동하는 ORM 프레임워크이다.
JPA가 ORM을 위한 기초 단계라면 Hibernate가 실제로 그 일을 동작한다.
Entities
students 테이블을 만들 때 썼던 SQL문을 생각해 보자.
CREATE TABLE students (
id INTEGER PRIMARY KEY AUTOINCREMEMT,
name TEXT,
age INTEGER,
phone TEXT,
email TEXT)이를 Java 객체지향 코드로 바꿔 작성하면 다음과 같다.
@Data
@Entity
public class StudentEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Integer age;
private String phone;
private String email;
}@Entity Annotation을 통해 멤버 변수가 테이블의 칼럼이 되고, @Id Annocation을 통해 primary key를 지정하고 @GeneratedValue Annotation을 통해 자동으로 값을 설정할 수 있도록 한다.
이후 실행하면 다음과 같이 테이블이 생성된 것을 확인할 수 있다. 이때 테이블 이름을 알아서 지정해 주고 싶으면 클래스 위에 @Table(name = “students”)로 설정해 줄 수 있다.
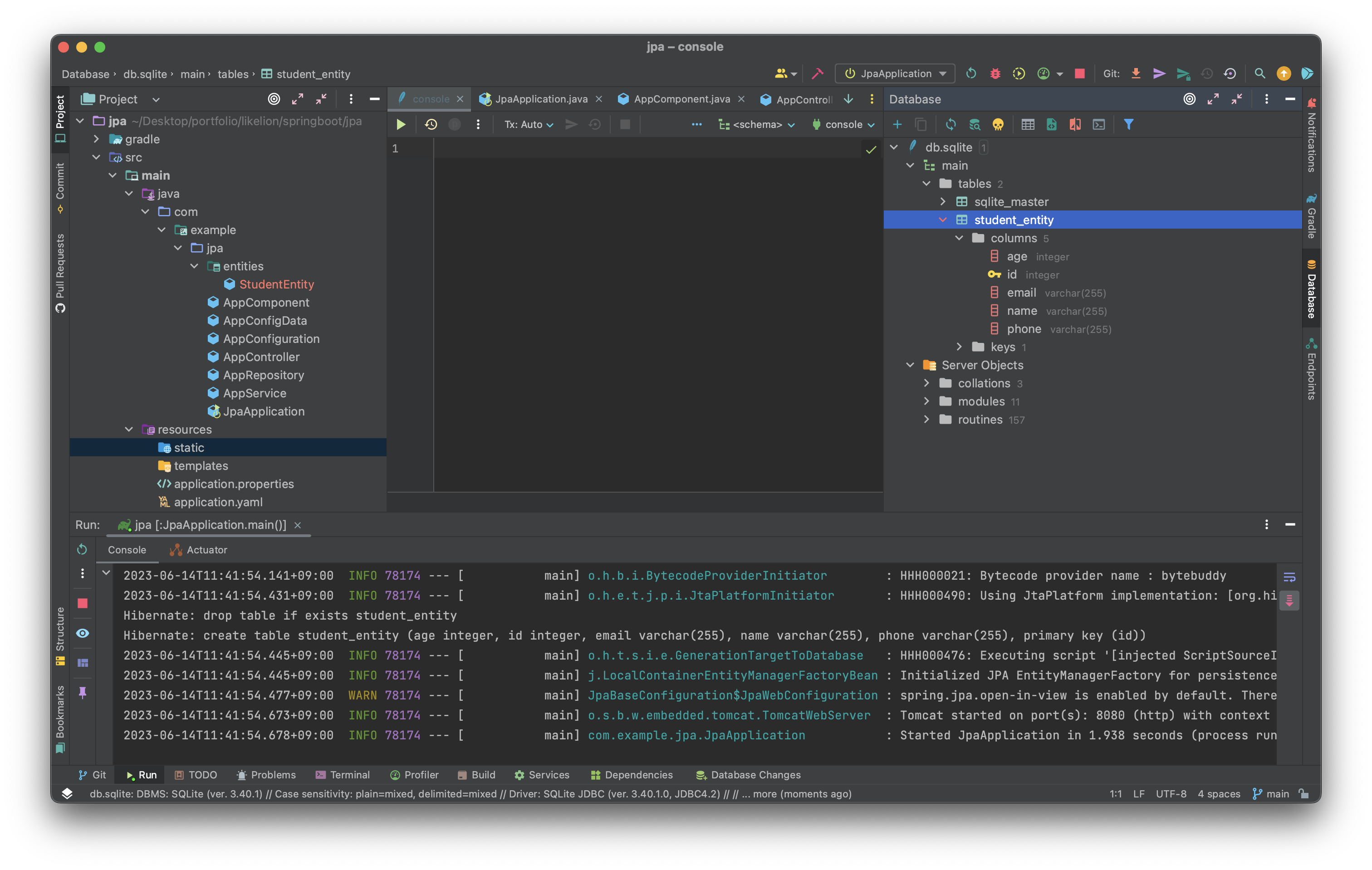
@Column(nama=”user_name”) 등으로 객체에서의 name이 데이터베이스에서는 user_name으로 매칭될 수 있도록 칼럼의 이름도 지정할 수 있다. 이때 CONSTRAINT를 넣기 위해 추가하는 Annotation은 @Column(nullable = false, unique = true) 등으로 넣을 수 있다.
@Data
@Entity
@Table(name = "students")
public class StudentEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "username", nullable = false)
private String name;
private Integer age;
@Column(unique = true)
private String phone;
private String email;
}실행하면 잘 적용된 것을 볼 수 있다.
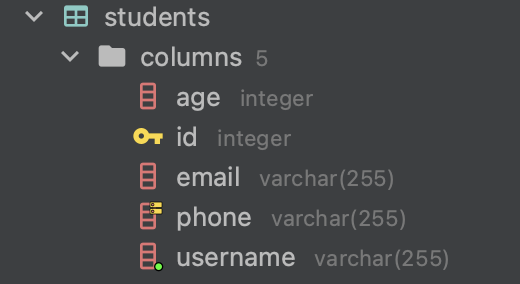
Repos
Repos 패키지 밑에 StudentRepository를 만든 뒤 JpaRepository를 상속받는다. 이는 Hibernate를 더 잘 사용하기 위한 또 다른 프레임워크이다.
import org.springframework.data.jpa.repository.JpaRepository;
public interface StudentRepository extends JpaRepository {
}Repository는 Entity를 다루는 것은 맞지만 모든 걸 다룬다면 너무 커진다. 따라서 Generic Type을 이용해서 어떤 Entity를 관리할 것인지 지정해 준다.
import com.example.jpa.entities.StudentEntity;
import org.springframework.data.jpa.repository.JpaRepository;
public interface StudentRepository
//JpaRepository<내가 다룰 Entity, Entity의 PK>
extends JpaRepository<StudentEntity, Long> {
}상속을 받았으니 JpaRepository의 메소드를 내가 만든 클래스도 사용할 수 있게 된다. JpaRepository의 메소드가 CRUD에 있어서 편리한 기능을 제공해 준다. Service에서 로직을 구현하기 위해 의존성을 추가해 준다.
import com.example.jpa.repos.StudentRepository;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class AppService {
private final AppRepository repository;
private final StudentRepository studentRepository;
public AppService(AppRepository repository, StudentRepository studentRepository) {
this.repository = repository;
this.studentRepository = studentRepository;
}
// CREATE
// READ
// READ ALL
// UPDATE
// DELETE
public List<Object> readStudentAll() {
List<Object> queryResult = repository.selectStudentAll();
return queryResult;
}
}CREATE
새로운 학생을 등록할 때 name, age, phone, email 정보가 필요하다. 이를 파라미터로 지정해 준다. 이후 Lombok이 만든 Setter를 통해 Entity를 만들고 save하면 된다. save는 StudentRepository가 상속받은 JpaRepository의 메소드이다.
// CREATE
public void createStudent(
String name,
Integer age,
String phone,
String email
) {
// 새로운 학생을 만들고 싶다
StudentEntity newEntity = new StudentEntity();
newEntity.setName(name);
newEntity.setAge(age);
newEntity.setPhone(phone);
newEntity.setEmail(email);
this.studentRepository.save(newEntity);
}이후 Controller를 통해 요청을 받은 뒤 임의의 alex를 추가하면 되는지 보자.
@GetMapping("create")
public @ResponseBody String create() {
this.service.createStudent(
"alex",
35,
"010-1234-5678",
"alex@gmail.com"
);
return "done";
}
Read All
같은 방식을 반복하면서 api를 만들 수 있다.
// READ ALL
public void readStudentAll() {
System.out.println(this.studentRepository.**findAll()**);
}@GetMapping("read-all")
public @ResponseBody String readAll() {
this.service.readStudentAll();
return "done-read-all";
}이후 화면을 실행하면 잘 나오는 것을 확인할 수 있다.
Hibernate: insert into students (age,email,name,phone) values (?,?,?,?)
Hibernate: select s1_0.id,s1_0.age,s1_0.email,s1_0.name,s1_0.phone from students s1_0
[StudentEntity(id=1, name=alex, age=35, phone=010-1234-5678, email=alex@gmail.com)]READ: this.studentRepository.**findById(id)**)
