관계 데이터 모델
1. 관계 데이터 모델의 개념
릴레이션
relation
행과 열로 구성된 테이블
관계 데이터 모델은 모든 게 관계임!
relation은 테이블이라고도 부르기도함.(한국어로) 관계라고 사용하지 않는다!
관계는 relationship이라고 함. 테이블 간의 관계가 이것을 말한다.
관련된 한글 용어들

+) relational algebra -> 관계 대수
algebra : 대수학 (수학적 기호로 개념을 대변하다? 라고 할때 일반적으로 한다고함~)
ex) 선형대수학. 수학적 개념이 아닌 것을 이용해 수학적으로 푸는것
행렬 연산 같은거...?
엄연히 말하자면 수학적 개념은 아님. 컴퓨터 쪽에서 관계형 모델에서 어떤 특성들을 연산하는 것.
정처기에서 relation대신 가끔씩 테이블이라고도 나온다.
relationship은 관계다. 혼동 주의
relationship
relation 내에서 생성되는 관계 : relation 내 데이터들의 관계
relation 간에 생성되는 관계 : relation 간의 관계
열 : attribute = feature = column = degree
차수(degree)는 정처기에서도 가끔씩 출제됨.
column은 이 차수인 이유:
기하학에서 행렬 표현시 차수를 차원으로 보기 때문.
데이터의 차원이라고 생각하면 된다?
행 : row = tuple = record = instance(-> 잘 안씀.)
릴레이션 스키마와 인스턴스
schema
데이터 구조도, 청사진 같은 것.
전체 테이블 설계를 스키마라고 한다. 틀, 구조, 테이블간의 관계 이런 것 다 포함.
스키마는 틀을 나타냄
스키마를 클래스라고 생각하면 된다
-> 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조이다
relation schema
schema의 요소
속성(attribute) : 릴레이션 스키마의 열
도메인(domain) : 속성이 가질 수 있는 값의 집합
-> 수학의 함수에서 나옴. 정의역(domain). 대표적인 게 자료형. int, str, ... enum 등...
영역, 범위 이런 뜻임.
IP address로 각각의 컴퓨터들이 인터넷에서 식별이 된다.
사람이 읽기 쉽게 만든게 도메인 주소.
DNS : domain name server. 도메인과 IP address를 매핑시켜준다.
차수(degree) : 속성의 개수
schema의 표현
릴레이션 이름(속성1 : 도메인1, 속성2 : 도메인2, 속성3 : 도메인3 …)
EX) 도서(도서번호, 도서이름, 출판사, 가격)
relation instance
인스턴스 요소
투플(tuple) : 릴레이션의 행
카디날리티(cardinality) : 투플의 수
-> 정처기에서도 가끔 출제. degree와 cardinality의 갯수 등.
relation의 특징
➊ 속성은 단일 값을 가진다
각 속성의 값은 도메인에 정의된 값만을 가지며 그 값은 모두 단일 값이어야 함
-> 하나의 셀에는 하나의 값만 들어가야 한다.
➋ 속성은 서로 다른 이름을 가진다
속성은 한 릴레이션에서 서로 다른 이름을 가져야만 함
-> relation 내에서 유일해야 함.
➌ 한 속성의 값은 모두 같은 도메인 값을 가진다
한 속성에 속한 열은 모두 그 속성에서 정의한 도메인 값만 가질 수 있음
➍ 속성의 순서는 상관없다
속성의 순서가 달라도 릴레이션 스키마는 같음
예) 릴레이션 스키마에서 (이름, 주소) 순으로 속성을 표시하거나 (주소, 이름) 순으로
표시하여도 상관없음
-> 물리적으로는 PK순으로 sorting되어 있다.
PK 제외하면 순서가 상관없다고 한다?
➎ 릴레이션 내의 중복된 투플은 허용하지 않는다
하나의 릴레이션 인스턴스 내에서는 서로 중복된 값을 가질 수 없음,
즉 모든 투플은 서로 값이 달라야 함
-> PK는 항상 유일해야함.
PK가 아니면 상관없긴 하다. 라고 한다?
➏ 투플의 순서는 상관없다
투플의 순서가 달라도 같은 릴레이션임. 관계 데이터 모델의 투플은 실제적인 값을 가지고 있으며 이 값은 시간이 지남에 따라 데이터의 삭제, 수정, 삽입에 따라 순서가 바뀔 수 있음
-> 이것도 상관없다고 한다.
ex) 3번 삭제되고 맨 끝에 다시 들어옴.
sorting을 해주긴 한다.
+) 추가
투플이 가지는 속성의 개수는 릴레이션 스키마의 차수와 동일하고,
릴레이션 내의 모든 투플들은 서로 중복되지 않아야 함
relation = table = file
하나의 데이터 파일에 table을 넣는다
.csv(엑셀파일) 보면 하나의 시트에 하나의 테이블이 있다.
csv는 comma seperate value의 줄임말.
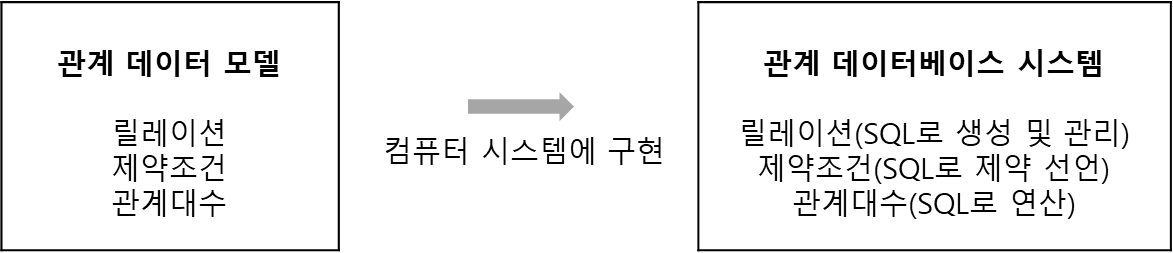
관계 데이터 모델
관계 데이터 모델은 데이터를 2차원 테이블 형태인 릴레이션으로 표현함
릴레이션에 대한 제약조건과 관계 연산을 위한 관계대수를 정의함
2. 무결성 제약조건
가장 간단한 제약조건
핵심 키워드 : 키
키
특정 투플을 식별할 때 사용하는 속성 혹은 속성의 집합
-> 속성을 묶어서도 사용가능!
릴레이션은 중복된 투플을 허용하지 않음 → 각각의 투플에 포함된 속성들 중 어느 하나(혹은 하나 이상)는 값이 달라야 함. 즉 키가 되는 속성(혹은 속성의 집합)은 반드시 값이 달라서 투플들을 서로 구별할 수 있어야 함
키는 릴레이션 간의 관계를 맺는 데도 사용됨
-> join연산등을 할때 키를 기반으로 한다.
예시로 사용할 테이블들

고객 : 고객번호
도서 : 도서번호
주문 : 고객번호, 도서번호, 주문일자 집합으로 할 수 있음.
제일 중요한 3가지 키
슈퍼키 후보키 기본키
슈퍼키
투플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합
투플을 유일하게 식별할 수 있는 값이면 모두 슈퍼키가 될 수 있음
-> 식별할 수 있다는 조건 하나만 있기 때문에 키 중에 가장 큰 개념임. 열 전체가 슈퍼키가 될 수도 있다.
고객 릴레이션 예:
고객번호 : 고객별로 유일한 값이 부여되어 있기 때문에 투플을 식별할 수 있음
이름 : 동명이인이 있을 경우 투플을 유일하게 식별할 수 없음
주민번호 : 개인별로 유일한 값이 부여되어 있기 때문에 투플을 식별할 수 있음
주소 : 가족끼리는 같은 정보를 사용하므로 투플을 식별할 수 없음
핸드폰 : 한 사람이 여러 개의 핸드폰을 사용할 수 있고 반대로 핸드폰을 사용하지 않는 사람이 있을 수 있기 때문에 투플을 식별할 수 없음
고객 릴레이션은 고객번호와 주민번호를 포함한 모든 속성의 집합이 슈퍼키가 됨.
(주민번호), (주민번호, 이름), (주민번호, 이름, 주소), (주민번호, 이름, 핸드폰),
(고객번호), (고객번호, 이름, 주소), (고객번호, 이름, 주민번호, 주소, 핸드폰) 등
후보 키(candidate key)
투플을 유일하게 식별할 수 있는 속성의 최소 집합
-> 최소 집합이라는 조건이 추가됨!
고객번호 : 한 명의 고객이 여러 권의 도서를 구입할 수 있으므로 후보키가 될 수 없고, 고객번호가 1인 박지성 고객은 세 번의 주문 기록이 있으므로 투플을 유일하게 식별할 수 없음
도서번호 : 도서번호가 2인 ‘축구아는 여자’는 두 번의 주문 기록이 있으므로 투플을 유일하게 식별할 수 없음
주문 릴레이션의 후보키는 2개의 속성을 합한 (고객번호, 도서번호)가 됨
2개 이상의 속성으로 이루어진 키를 복합키(composite key)라고 함
기본 키 (primary key)
여러 후보키 중 하나를 선정하여 대표로 삼는 키
후보키가 하나뿐이라면 그 후보키를 기본키로 사용하면 되고,
여러 개라면 릴레이션의 특성을 반영하여 하나를 선택하면 됨
기본키 선정 시 고려사항
릴레이션 내 투플을 식별할 수 있는 고유한 값을 가져야 함.
NULL 값은 허용하지 않음.
키 값의 변동이 일어나지 않아야 함.
최대한 적은 수의 속성을 가진 것이라야 함.
향후 키를 사용하는 데 있어서 문제 발생 소지가 없어야 함.
릴레이션 스키마를 표현할 때 기본키는 밑줄을 그어 표시함
릴레이션 이름(속성1, 속성2, …. 속성N)
고객(고객번호, 이름, 주민번호, 주소, 핸드폰)
도서(도서번호, 도서이름, 출판사, 가격)
책에는 안나오는데 주민번호같은건 PK로 안쓴다. 그리고 애초에 생년월일, 성별정보만 가짐.
있어도 동사무소. 저장자체를 안한다.
대리 키 (surrogate key)
기본키가 보안을 요하거나, 여러 개의 속성으로 구성되어 복잡하거나, 마땅한 기본키가 없을 때는 일련번호 같은 가상의 속성을 만들어 기본키로 삼는 경우가 있음 이러한 키를 대리키(surrogate key) 혹은 인조키(artificial key)라고 함
대리키는 DBMS나 관련 소프트웨어에서 임의로 생성하는 값으로 사용자가 직관적으로 그 값의 의미를 알 수 없음
주문 테이블의 고객번호도 대리키라고 볼 수 있음.
주문도 고객 + 도서 + 주문일자 대신 order ID에 대한 대리키를 만들어냄.
실제로는 구매를 나타내는 속성이 굉장히많다! 키로 사용하기 위해 이걸 대신해서 가상의 키를 만들어내는 것이다.
대체 키
기본키로 선정되지 않은 후보키
고객 릴레이션의 경우 고객번호와 주민번호 중 고객번호를 기본키로 정하면 주민번호가 대체키가 됨
-> 많이 사용하진 않는다.
외래키(foreign key)
다른 릴레이션의 기본키를 참조하는 속성을 말함
다른 릴레이션의 기본키를 참조하여 관계 데이터 모델의 특징인 릴레이션 간의 관계(relationship)를 표현함
외래키의 특징
관계 데이터 모델의 릴레이션 간의 관계를 표현함
다른 릴레이션의 기본키를 참조하는 속성임
참조하고(외래키) 참조되는(기본키) 양쪽 릴레이션의 도메인은 서로 같아야 함
참조되는(기본키) 값이 변경되면 참조하는(외래키) 값도 변경됨
NULL 값과 중복 값 등이 허용됨
자기 자신의 기본키를 참조하는 외래키도 가능함
-> 테이블 자체에서 속성을 따로 만들어서 참조 가능하다고 함.
외래키가 기본키의 일부가 될 수 있음
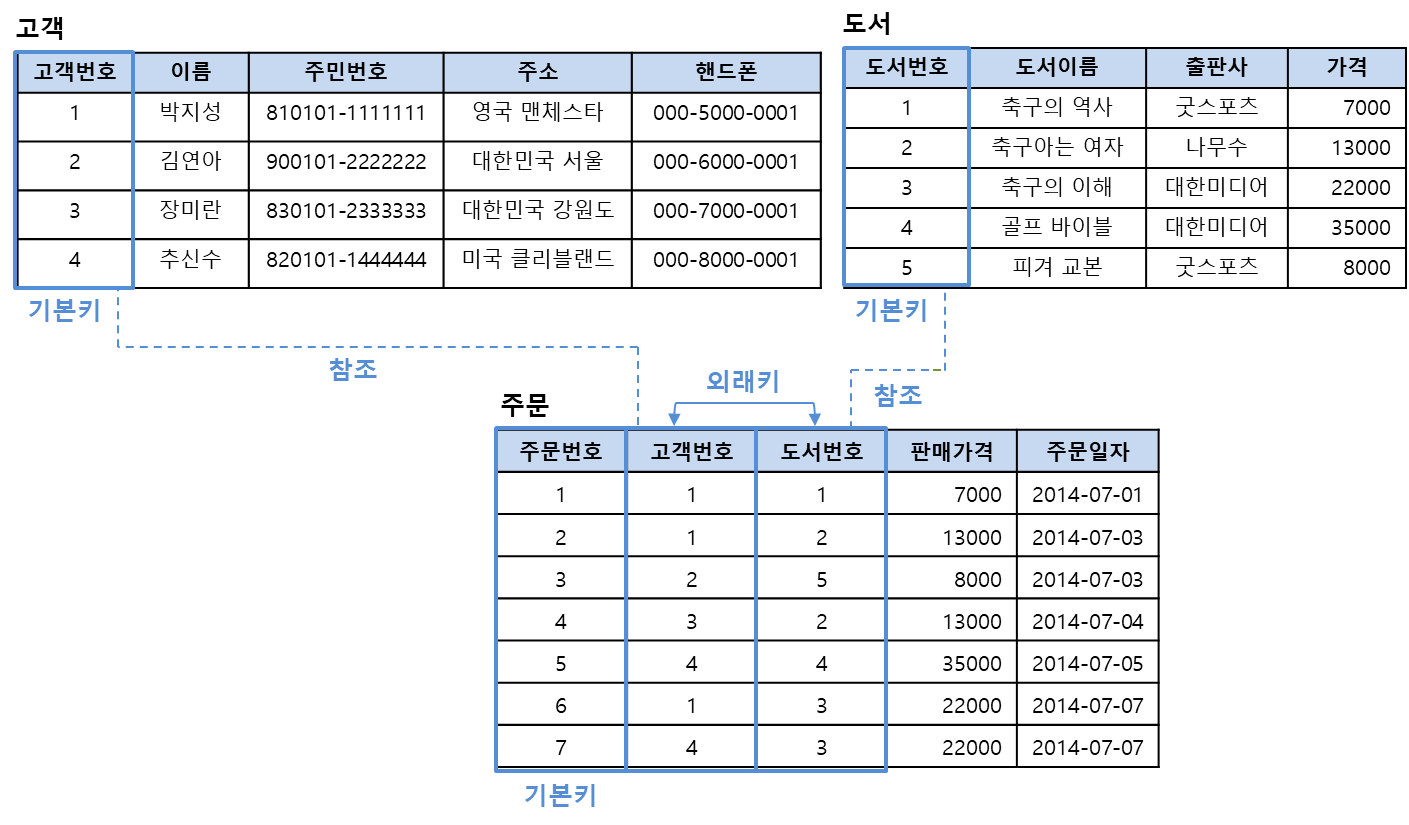
어질어질 참조관계...
외래키 사용 시 참조하는 릴레이션과 참조되는 릴레이션이 꼭 다른 릴레이션일 필요는 없음. 자기 자신의 기본키를 참조할 수도 있음
밴다이어그램으로 표현한 키의 포함 관계
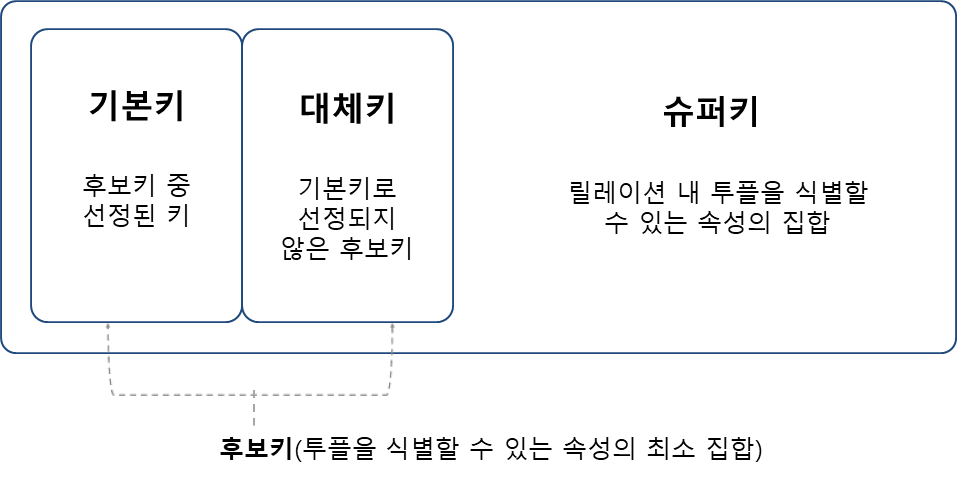
슈퍼키가 가장 큰 집합
슈퍼키 최소집합 : 후보키
후보키중 하나 : 기본키
기본키는 슈퍼키이기도 하다.
후보키도 이러한 포함관계를 가진다.
가끔 연산할 때 대체키를 사용한다. 대체키로 join하는게 더 unique한 sorting을 할 경우(???) 쓴다고 함.
대체키 잘 안씀.
무결성 제약조건
데이터 무결성(integrity, 無缺性)
데이터베이스에 저장된 데이터의 일관성과 정확성을 지키는 것
도메인, 개체, 참조 무결성 제약조건은 정처기에도 나온다.
도메인 무결성 제약조건
도메인 제약(domain constraint)이라고도 하며, 릴레이션 내의 투플들이 각 속성의 도메인에 지정된 값만을 가져야 한다는 조건. SQL 문에서 데이터 형식(type), 널(null/not null), 기본 값(default), 체크(check) 등을 사용하여 지정할 수 있음.
-> DB 개발자는 신경을 안써도 된다? DBA 쪽에서 관리함.
맞지 않게 넣으면 사용이 안된다. 다 체크를 해준다.
not null의 경우 null 값을 허용하지 않는다. default값은 속성 미지정시 자동으로 넣어주는거.
check는 값의 범위 지정.
스키마 디자인 시 정확히 지정을 해줘야 한다.
개체 무결성 제약조건
기본키 제약(primary key constraint)이라고도 함. 릴레이션은 기본키를 지정하고 그에 따른 무결성 원칙, 즉 기본키는 NULL 값을 가져서는 안 되며 릴레이션 내에 오직 하나의 값만 존재해야 한다는 조건임.
-> 별거 없다. 큰 조건. null 값 없고 unique 해야한다.
삽입 : 기본키 값이 같으면 삽입이 금지됨
수정 : 기본키 값이 같거나 NULL로도 수정이 금지됨
삭제 : 특별한 확인이 필요하지 않으며 즉시 수행함
참조 무결성 제약조건
외래키 제약(foreign key constraint)이라고도 하며, 릴레이션 간의 참조 관계를 선언하는 제약조건임.
자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 동일해야 하며, 자식 릴레이션의 값이 변경될 때 부모 릴레이션의 제약을 받는다는 것임
-> 참조 무결성은 많이 나온다.
자식(외래키)은 부모(기본키)의 값(도메인)만을 가질 수 있다. 값이 변경되더라도 부모의 영향을 받는다.
삽입 시
학과(부모 릴레이션) : 투플 삽입한 후 수행하면 정상적으로 진행된다.
학생(자식 릴레이션) : 참조받는 테이블에 외래키 값이 없으므로 삽입이 금지된다.
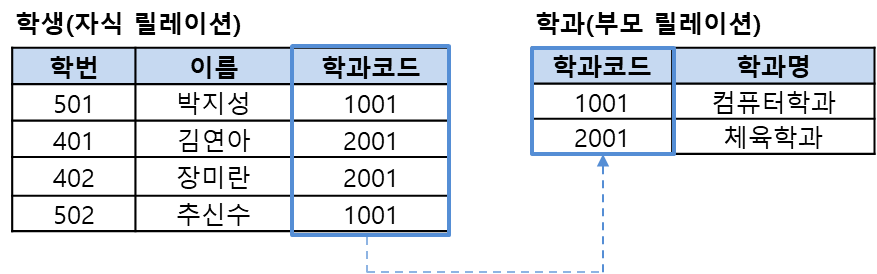
삭제 시
학과(부모 릴레이션) : 참조하는 테이블을 같이 삭제할 수 있어서 금지하거나 다른 추가 작업이 필요함
학생(자식 릴레이션) : 바로 삭제 가능함
※ 부모 릴레이션에서 투플을 삭제할 경우 참조 무결성 조건을 수행하기 위한 고려사항
1. 즉시 작업을 중지
2. 자식 릴레이션의 관련 투플을 삭제
3. 초기에 설정된 다른 어떤 값으로 변경
4. NULL 값으로 설정
수정
삭제와 삽입 명령이 연속해서 수행됨.
부모 릴레이션의 수정이 일어날 경우 삭제 옵션에 따라 처리된 후 문제가 없으면 다시 삽입 제약조건에 따라 처리됨.
삭제 명령의 옵션
Restricted
부모릴레이션을 지우려고할때 DBMS는 참조하고 있는 테이블에서 이걸 사용하는지 체크.
그리고 존재시 거부함.
삭제하고싶다? 자식을 NULL로 바꿔도 되고, 다른 키를 사용해서 이전시켜도 된다.
수동으로 해야됨. 여러가지 프로세스가 존재한다.
Cascade
관련된 자식까지 싹 다 지움. 연좌제?
계정삭제 같은 거?
policy긴 한데 그 사람의 데이터를 가지고싶다면 다른 DB로 옮기는 경우도 있음.
운영 테이블에서는 다 지운다. 백업DB로 이전함. 분석을 위해 쇼핑기록만 갖고있는 경우 등의 케이스가 있다.
Default
자식 릴레이션의 관련 투플을 미리 설정해둔 값으로 변경
삭제했을 때 기본값으로 설정하는 경우. 레코드를 유지하는데 참조값을 기본으로 설정
Null
자식 릴레이션의 관련 투플을 NULL 값으로 설정
Restricted에서 설명한거 말하는 듯?
DB Admin이 테이블 디자인 시 foreign key가 참조 무결성 제약조건과 연관됨.
그래서 이런걸 설정해준다.
무결성 제약조건 요약
개체 무결성 요약
유일해야한다. NULL 값 안됨
참조 무결성 요약
참조 테이블은 참조하는 대상에서 값을 가져와야함. 그래서 마음대로 못지우고, 못가져옴.
도메인 무결성 제약조건
컬럼의 속성과 관련이 있다.
테이블 디자인할 때 주로 됨.
정의역. int의 경우 범위 설정해준다 등등
+) 개체는 PK, 참조는 FK 제약조건이라고 줄여부르기도 함.
