1. 이진 분류 모델의 평가
- TP, FN, TN, FP : 뒤에 Positive/Negative가 예측, True/False가 예측이 맞았는지 틀렸는지 (실제 Positive/Negative)
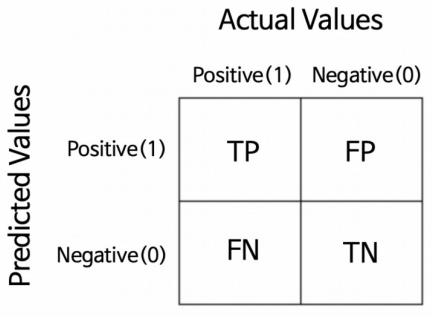
- Accuracy (정확도) : 전체 데이터 중 맞게 예측한 것의 비율, TP+TN+FP+FNTP+TN
- Precision (정밀도) : Positive라고 예측한 것 중 실제 Positive인 것의 비율, TP+FPTP
Ex) 스팸 메일 예측 모델에 있어 중요함.(스팸이라고 예측한 것이 실제 스팸이 아니면 큰 문제)
- Recall (재현율, TPR) : 실제 Positive인 것 중 Positive라고 예측한 것의 비율(Sensitivity), TP+FNTP
Ex) 암 진단 예측 모델에 있어 중요함.(암 환자인 사람을 암 환자가 아니라고 예측하면 큰 문제)
- Fall-Out (FPR) : 실제 Negative인 것 중 Positve라고 예측한 것의 비율,
FP+TNFP
- Recall과 Precision은 Trade-off 관계이기 때문에, Threshold를 변경하여 한 쪽을 극단적으로 높게 설정해서는 안됨.(Threshold는 0~1 사이의 확률 값, Positive/Negative 결정)
F1-Score : Recall과 Precision이 둘다 높은 값을 가질수록 높은 값을 가짐.(조화 평균, 결합 지표) Precision+Recall2×Precision×Recall
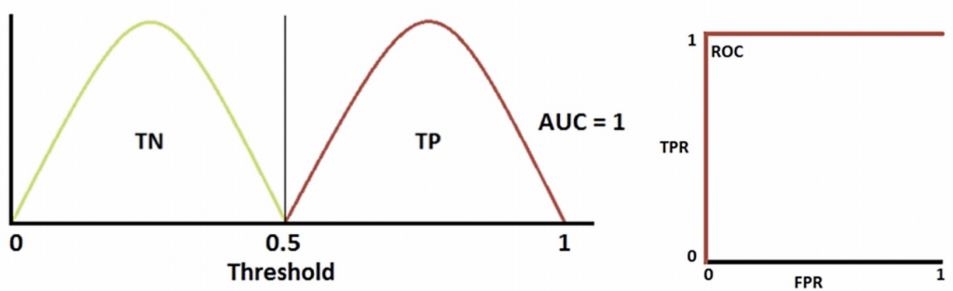
2. ROC Curve
- FPR(x축)이 변할 때, TPR(y축)의 변화를 그린 그림
- 직선에 가까울수록 머신러닝 모델의 성능이 떨어지는 것으로 판단
- 완벽한 모델 (AUC는 ROC Curve 아래의 면적 → 1에 가까울수록 좋음. 직선인 경우인 0.5보다 커야함.)
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import recall_score, f1_score
from sklearn.metrics import roc_auc_score
print('Accuracy : ', accuracy_score(y_test, y_pred_test))
print('Precision : ', precision_score(y_test, y_pred_test))
print('Recall : ', recall_score(y_test, y_pred_test))
print('F1 Score : ', f1_score(y_test, y_pred_test))
print('AUC Score : ', roc_auc_score(y_test, y_pred_test))
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
%matplotlib inline
pred_proba = clf.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred_proba)
plt.figure(figsize=(10,8))
plt.plot([0,1], [0,1], 'r', ls='dashed')
plt.plot(fpr, tpr)
plt.grid()
plt.show()
