
문제 상황
Spark executor는 JVM process 이고, Spark 에서의 cores per executor 는 executor 에서 parallel 하게 수행될 수 있는 task 개수(=thread 개수)를 의미한다. cores per executor 가 너무 커지면 task 당 I/O 성능이 떨어지고, cores per executor 가 너무 작으면 task 들이 JVM resource 를 공유하는 이점을 충분히 얻지 못한다. 경험적으로 4-5 개 정도가 최적이라고 알려져 있다. Spark application 에서 설정한 total core 수(total thread 수)와 실제로 application 에 할당되는 vCPU 의 개수를 일치시켜야 최적으로 사용할 수 있다.
하지만 실제로 트리거 되고 있는 Spark application 을 살펴보면 vCPU 가 YARN container 개수 만큼만 할당 되는 것을 확인할 수 있었다. YARN container 개수는 executor 개수 + 1 (for driver) 이다. 즉 vCPU 가 executor 개수 만큼 할당이 되고 있었다. 이는 task 병렬 처리 성능에 악영향을 주고 있었다.

문제 원인
YARN 에서 클러스터 자원을 할당할 때 Capacity Scheduler 를 기본으로 사용하고 있다. 각각의 잡은 서로 구분되는 전용 큐에서 처리되며, 잡을 위한 리소스를 잡별로 예약해둔다. 잡별로 할당해야 하는 리소스를 계산할 때 Resource Calculator 를 사용한다. YARN 에서 기본적으로 사용하는 DefaultResourceCalculator 이다. DefaultResourceCalculator 는 메모리만을 기준으로 하여 리소스를 할당한다.
문제 해결
cluster config 직접 변경
YARN 에서 사용하는 Resource Calculator 를 DominantResourceCalculator 로 변경한다. /etc/hadoop/conf/capacity-scheduler.xml 에 다음과 같이 property를 변경해준다.
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>property 변경 후, yarn resource manager를 restart 해준다.
$ sudo systemctl --type=service | grep 'yarn-resourcemanager'
**hadoop-yarn-resourcemanager.service** loaded active running Hadoop resourcemanager
$ sudo systemctl stop hadoop-yarn-resourcemanager.service
$ sudo systemctl start hadoop-yarn-resourcemanager.service"executors": 7, "executor_cores": 5, "executor_memory": "5G" 와 같이 config 하여 Spark application 을 실행하면 다음과 같이 리소스가 할당된다.
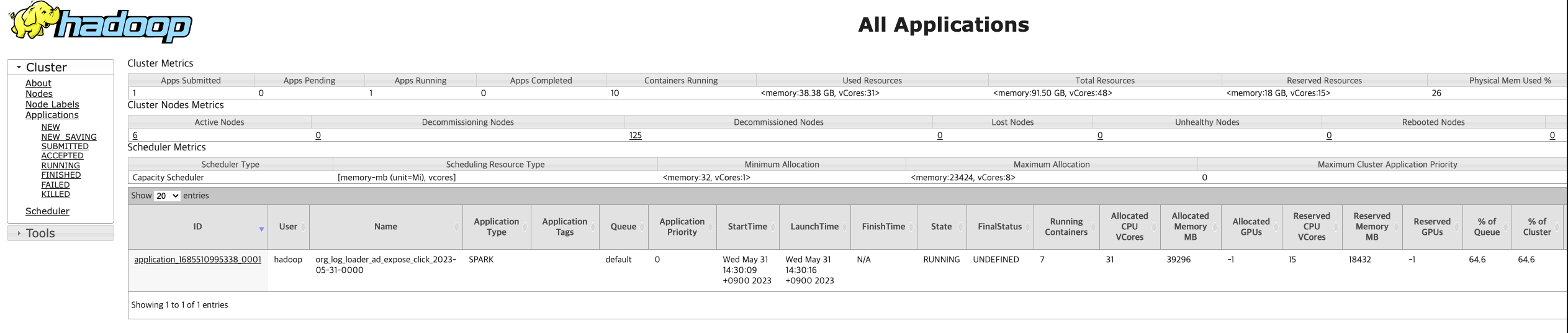
cluster 생성 시 세팅
emr 생성 명령어 emr create-cluster --configurations``"file://${configurations_json}" 에서 configurations_json 파일에 다음을 추가한다.
{
"Classification": "capacity-scheduler",
"Properties": {
"yarn.scheduler.capacity.resource-calculator": "org.apache.hadoop.yarn.util.resource.DominantResourceCalculator"
}
}Reference
