문제 상황
Data source, sink로 AWS Kinesis를 사용하는 Flink application이 있다. 이 application을 수정하고 테스트를 하고자 production application은 유지한 상태에서 새로운 application을 추가로 실행시켰다. 테스트용 application은 production application과 (약간의 기능이 추가된) 거의 동일한 코드와 설정을 사용하며, production application과 동일한 data source를 사용하고 테스트용 kinesis를 data sink로 사용했다. 즉 data source로 사용되는 하나의 kinesis stream에 두 개의 거의 동일한 flink application이 consumer로 동작하는 구조였다. 하지만 테스트용 applicaton을 실행하니 두 application 모두 getRecords에 실패하는 이슈가 있었다.
Data source로 사용되는 kinesis는 분당 500개 정도 record가 들어오며, 15개의 shard가 provision 돼 있었다.
문제 분석 및 해결
getRecords interval의 조정
Kinesis에서 shard는 스트림에서 구분되는 레코드 시퀀스의 단위이다. 한 개 이상의 shard로 stream이 구성된다. Kinesis에서 shard 당 getRecords API의 TPS (Transaction Per Second)는 최대 5로 제한 된다. 만약 5를 넘어서면 ReadProvisionedThroughputExceeded 에러가 발생하며 일정 시간동안 getRecords API의 call이 제한된다.
Flink는 call 하는 getRecords operation 사이의 interval을 인자로 조정할 수 있으며, interval의 기본값은 200ms 이다. 즉 초당 많으면 4번까지도 getRecords API를 call 한다. Flink에서는 records 를 가져올때의 latency를 최소화 하고자 kinesis의 getRecords TPS limit에 근접하게 API call을 하는 것으로 추정된다.
Flink에서 getRecords operation 사이의 interval은 flink.shard.getrecords.intervalmillis 라는 configuration으로 설정할 수 있다. 이 값을 기본 200ms 에서 600ms로 변경한다면 하나의 shard에서 초당 1~2회 정도 getRecords API를 실행할 것이라 예상했다. 이렇게 설정을 변경한다면, 두 애플리케이션을 실행해도 문제 없이 동작할 것 이라 예상했다.
코드 분석
PollingRecordPublisher class의 getRecords를 실행하며, 후에 adjustRunLoopFrequency 를 실행하며 sleep을 한다. sleep을 하는 시간은 fetchIntervalMillis 에서 getRecords를 수행하는데 걸린 시간을 뺀 만큼 이다. fetchIntervalMillis 는 flink.shard.getrecords.intervalmillis 의 값이며 기본값은 200ms이다.
PollingRecordPublisher class의 getRecords에서는 KinesisProxy class의 getRecords를 실행한다.
KinesisProxy 객체에서 실제로 KCL을 사용하여 getRecords를 호출한다. 이때 getRecords의 result가 null이라면 backoffMillis만큼 sleep 한 후에 다시 재실행 한다. getRecordsBaseBackoffMillis 는 flink.shard.getrecords.backoff.base 의 값이며, 기본값은 300ms이다. 재실행은 max retry 까지만 수행한다. backoffMillis은 FullJitterBackoff class에서 구현돼 있다.
shard에 record가 없으면 빈 record array가 리턴되며, shard가 없어졌을 경우 null이 return된다. 또한 Exception이 발생하면 기본값인 null 이 result 변수에 그대로 남아있게 된다.
최종 backoffMillis 를 return 할 때 생성된 sleep 시간에 nextDouble()을 통해 생성된 0 ~ 1 사이 double 값을 곱해준다.
조정 후 예상 동작 방식
다음과 같이 정의를 하였다. 초록색 화살표는 getRecords 에 성공한 것을, 빨간색 화살표는 getRecords에 실패한 것을 나타낸다.
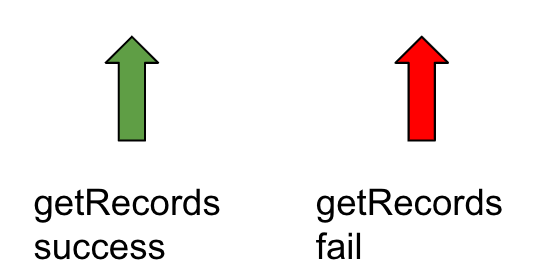
기본 interval 설정 값과 하나의 애플리케이션을 사용할 때의 shard별 getRecords는 다음과 같다. 기본 interval이 200ms이기 때문에 윈도우에서 최대 다섯번의 getRecords만 call되며, ReadProvisionedThroughputExceeded 에러가 발생하지 않는다.
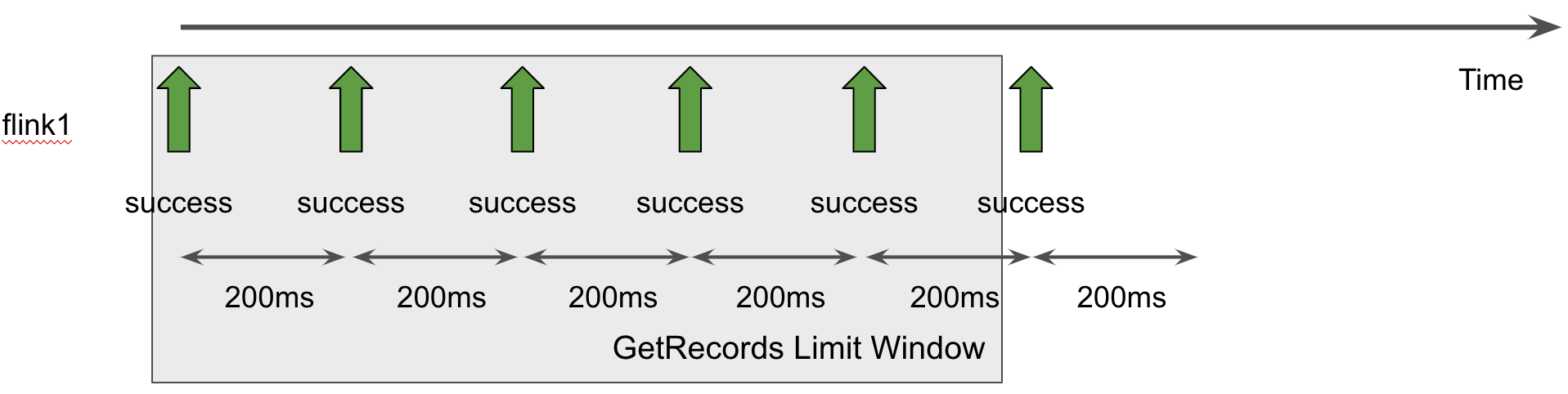
기본 interval 설정 값과 두개의 애플리케이션을 사용할 때의 shard별 getRecords는 다음과 같다. 두 애플리케이션에서 getRecords를 shard별로 호출하기에 1초에 10번까지도 getRecords가 호출될 수 있고, 따라서 getRecords TPS 제한에 걸려 ReadProvisionedThroughputExceeded 에러가 발생한다.
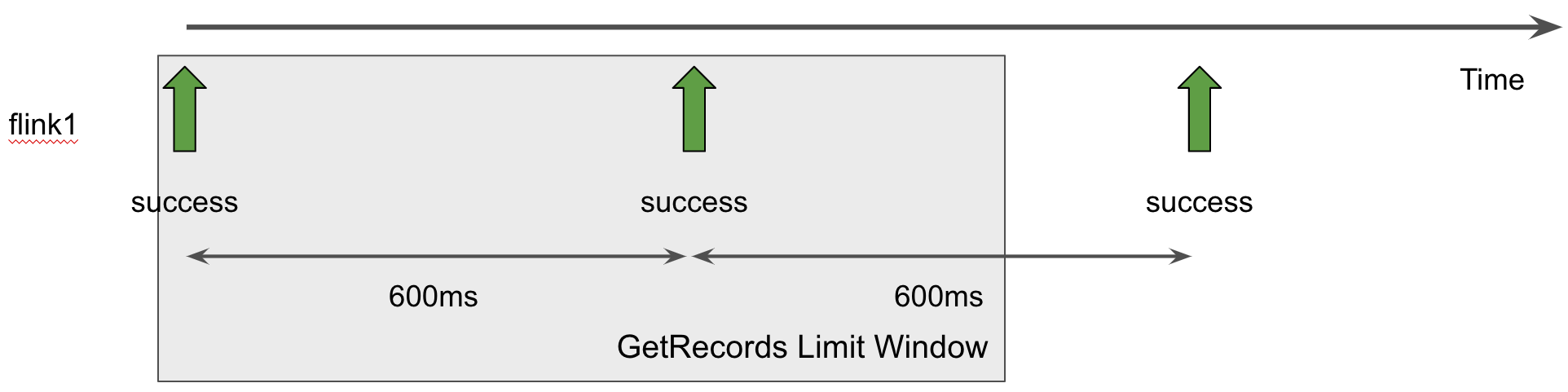
flink.shard.getrecords.intervalmillis 를 600ms로 설정하고 하나의 애플리케이션을 사용할 때의 shard별 getRecords는 다음과 같다. 초당 두 번 getRecords가 call 된다. 500ms로 설정해도 초당 두 번 getRecords가 호출 되겠으나 집계 방식 및 윈도우 방식에 따라 오류로 세번의 getRecords가 호출된 것으로 집계 될 수 있다고 판단하였고, 안정적인 운영을 위해 600ms로 설정하였다.
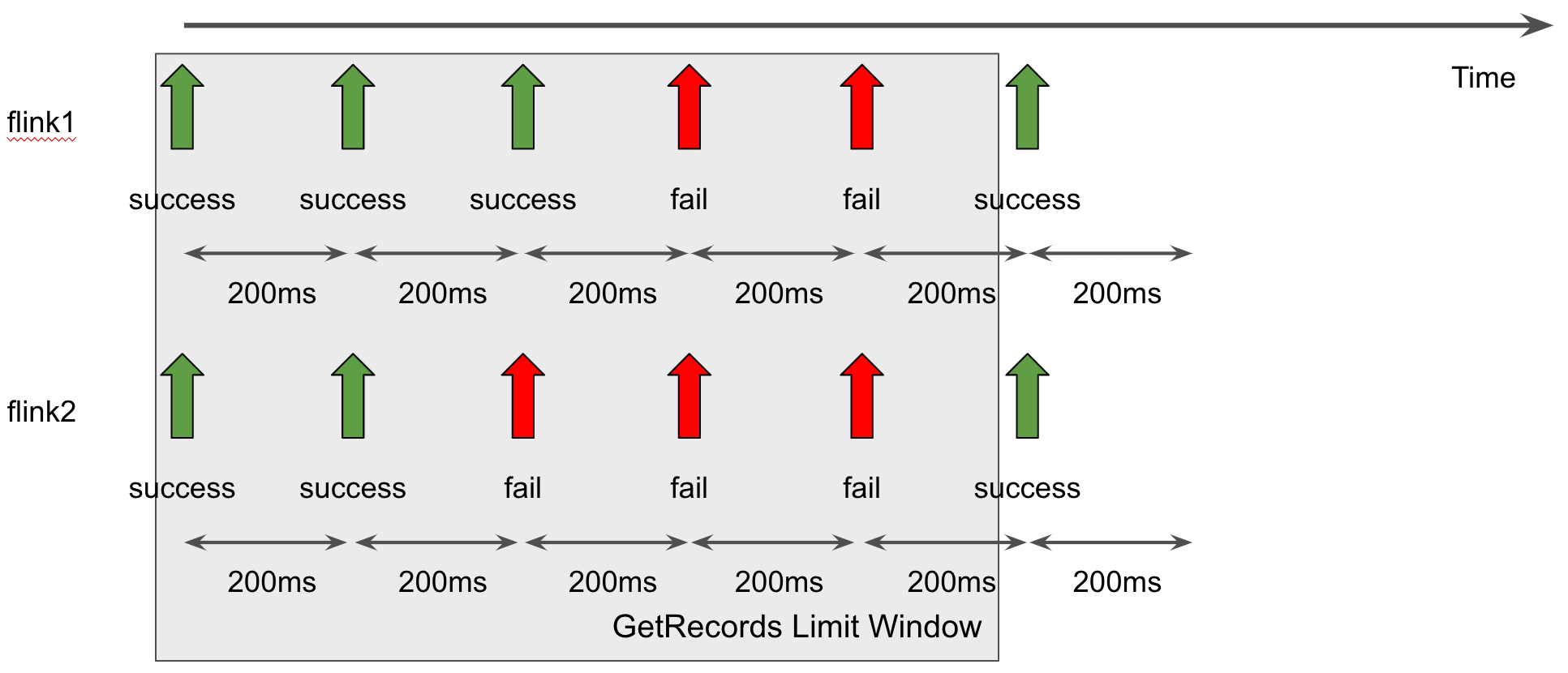
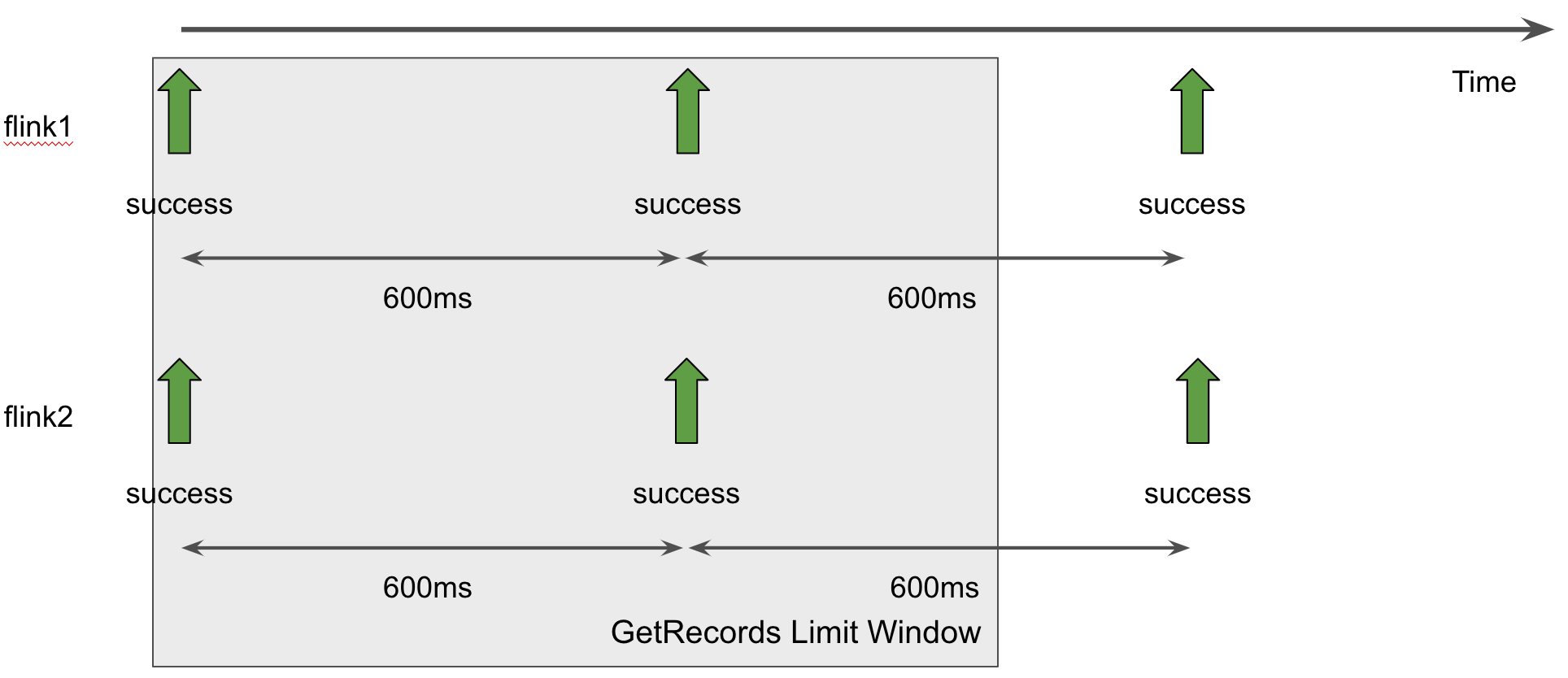
flink.shard.getrecords.intervalmillis 를 600ms로 설정하고 두개의 애플리케이션을 사용할 때의 shard별 getRecords는 다음과 같다. 두개의 애플리케이션을 운영해도 초당 getRecords가 네번 호출되며, ReadProvisionedThroughputExceeded 에러가 발생하지 않는다.
getRecords interval 적용 방식 수정
위와 같은 분석을 기반으로 flink.shard.getrecords.intervalmillis 를 조정하였다. CLI에서 flink application을 실행할 때 인자로 -Dflink.shard.getrecords.intervalmillis 를 넘겨주었다. Flink job manager에서 configuration이 등록된 것을 확인하였다. 하지만 문제가 해결되지 않았다.
이유는 해당 configuration이 FlinkKinesisConsumer에 반영되지 않았던 것이다. Kinesis를 source로 연결하기 위해 FlinkKinesisConsumer를 생성하는데, 인자로 넘겨준 cofiguration이 사용되지 않고 있었다. FlinkKinesisConsumer 를 생성할 때 직접 configuration을 설정하도록 다음과 같이 코드를 수정하였다. 수정후에는 원하는대로 동작하였고, 하나의 kinesis source에 두개의 application을 consumer로 두어도 무리없이 동작하였다.
def createSource(streamName: String) = {
val sourceProperties: Properties = new Properties()
sourceProperties.put(AWSConfigConstants.AWS_REGION, "ap-northeast-2")
sourceProperties.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST")
sourceProperties.put(ConsumerConfigConstants.SHARD_GETRECORDS_INTERVAL_MILLIS, "600")
new FlinkKinesisConsumer[String](
streamName,
new SimpleStringSchema,
sourceProperties
)
}결론
Flink application을 수정한 후 유닛 테스트와는 별개로 배포 전에 새로운 application이 생성하는 데이터 스트림을 확인해야 할 때가 있다. 그러기 위해서 하나의 kinesis stream을 source로 하는 두 개의 application이 동작해야 하는데, 이 경우 ReadProvisionedThroughputExceeded 가 발생하여 테스트에 어려움을 겪었다. 이 문제를 해결하기 위해 flink.shard.getrecords.intervalmillis 를 조정하는 방법을 제안 및 정리하였다. 이 방법을 사용하면 테스트가 가능해지지만 application의 latency가 오를 수 있으니 애플리케이션에 적용 가능한지 사전에 확인이 필요하다.
