Apache Flink는 상태가 있는(stateful) 연산으로 병렬 스트림을 처리하는 분산 시스템이다. Exactly-once의 이벤트 처리를 보장하는 네이티브 스트림 방식이다. Stream processing과 batch processing의 차이를 생각하면서 flink의 구조와 장애복구 방식을 중심으로 정리해보았다.
Flink의 구조
Flink는 크게 네 개의 컴포넌트로 구성돼 있다. Flink는 Java, Scala로 구현되어 있으며, 각 컴포넌트들은 JVM 상에서 프로세스로 실행된다.
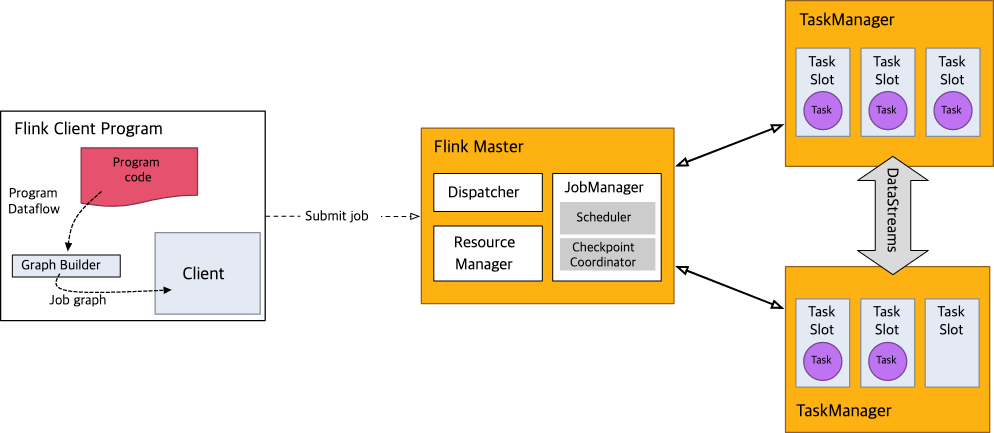
JobManager
애플리케이션의 실행을 제어하는 마스터 프로세스다. 잡매니저는 사용자로 부터 전달 받은 애플리케이션을 바탕으로 JobGraph와 ExecutionGraph를 생성한다. 리소스 매니저에 태스크 슬롯(태스크 실행에 필요한 자원)을 요청하고, 충분한 자원을 할당 받으면 작업을 처리할 태스크로 실행 그래프를 배포한다. 또한 체크포인트를 관리하며 마스터 프로세스가 조율해야하는 모든 제어 동작을 관리한다.
ResourceManager
YARN, Mesos, standalone cluster, Kubernetes 등의 환경에서 리소스를 관리한다. 잡매니저가 태스크 슬롯을 요청하면 리소스매니저는 태스크매니저가 잡매니저에게 태스크 슬롯을 제공하도록 지시한다.
TaskManager
Worker 프로세스이다. 일반적으로 Flink 클러스터는 여러 태스크 매니저를 갖고 있다. 태스크매니저는 여러 태스크 슬롯을 갖고 있으며, 이는 configuration이나 실행 인자로 정해진다. 태스크매니저는 JVM 프로세스이며, 그 안에서 태스크는 멀티스레드로 실행된다.
Dispatcher
애플리케이션을 잡매니저에게 submit할 수 있는 REST API를 제공한다.
Flink의 장애 복구
Flink는 분산 데이터 처리 프레임워크에서 발생할 수 있는 프로세스가 죽거나, 노드가 다운되거나, 네트워크 연결이 안되는 등의 장애를 처리할 수 있어햐 한다. Flink는 exactly-once 상태 일관성(이벤트 유실이 없고, 이벤트마다 한번씩만 내부 상태를 갱신하는 것)을 보장하기 위해 체크포인트를 사용한다. 또한 세이브포인트 기능도 존재한다.
Flink에서의 state
대부분의 스트리밍 애플리케이션은 state를 갖는다. state는 뜻 그대로 애플리케이션의 그 시점 상태를 기록한다. state는 태스크가 유지하고 있는 데이터, 함수의 결과를 계산할 때 사용하는 모든 데이터, stream offset 등이 기록된다. Flink의 state는 연산자와 연관돼 있으며, 연산자는 자기가 사용할 state를 등록해둔다. state의 종류에 따라 접근 가능한 scope가 다르다. Flink에는 크게 operator state와 keyed state가 존재한다.
- operator state는 병렬적으로 수행되는 operation, 즉 task 단위로 scope가 한정된다.
- keyed state는 레코드의 각 키 값 단위로 scope가 한정된다.
Checkpoint
checkpointing은 특정 시점의 애플리케이션 state를 저장하는 것이다. 장애로 인해 애플리케이션을 재시작할때 미리 저장해둔 checkpoint에서 이전 시점의 애플리케이션 상태를 불러와 해당 시점부터 다시 처리한다. Flink는 모든 태스크가 동일한 시점에 각 태스크의 상채를 복사하는 consistent checkpoint 방식을 채택하고 있다.
Savepoint
savepoint는 근본적으로 checkpoint에 몇가지 메타데이터를 추가하여 만든다. checkpoint를 사용한 장애복구는 동일한 시점에서 동일한 설정으로 동일 애플리케이션을 실행하는 것이다. 이는 예기치 못한 상황을 대비하는 것이다. 반면 savepoint를 사용하면 호환되는 다른 애플리케이션을 시작할 수 있다. 버그 수정 후 데이터의 유실 없이 savepoint 부터 재처리 할 수 있는 것이다.
Flink의 연산
Transformation
transformation은 각 이벤트를 독립적으로 처리한다. 값을 변형하거나, 특정 값에 가중치를 주거나, 특정 키 값 기반으로 파티셔닝하여 처리할 수 있다.
Rolling Aggregation
새로 들어온 이벤트와 현재 상태를 결함해 집계 값을 계산한다. sum, max, min 등이 있다.
Window
transformation과 rolling aggregation은 한 번에 한 이벤트만 처리하는 반면 window 연산은 일정량의 이벤트를 모아서 한번에 처리한다. 윈도우 시멘틱에는 다음과 같은 종류가 있다.
- Tumbling Window: 고정된 길이만큼 겹치지 않는 버킷으로 이벤트를 할당한다. 윈도우의 길이는 time-based, count-based 등으로 정해진다.
- Sliding Window: 고정된 길이만큼 겹치는 버킷으로 이벤트를 할당한다. 윈도우의 길이와 윈도우가 이동하는 간격인 slide 값으로 정의 한다.
- Session Window: session gap을 정의하여 session gap 이내의 간격을 갖는 이벤트를 하나의 버킷에 포함시킨다. 윈도우의 길이는 들어오는 이벤트간의 간격에 따라 가변적이다.
Reference
