
Process Concept
- Process = 현재 실행 중인 프로그램
- 프로세스의 실행은 항상 순차적으로 진행됨
✔ 운영체제가 실행하는 프로그램 유형
프로세스라는 용어는 컴퓨터 실행 환경에 따라 job, 또는 user program, tasks라는 용어로 불리기도 한다.
- Batch system→ job 단위 실행
- Time-sharing system → 사용자 프로그램(task) 실행
- job, task ≈ process (거의 동일하게 사용됨)
✔ Process 구성 요소
- Program Counter: 다음에 실행시킬 instruction의 주소가 들어있는 레지스터
- Stack: 메모리의 한 영역을 stack으로 지정
- Data section: 프로세스 실행을 위해 필요한 데이터
Process in Memory
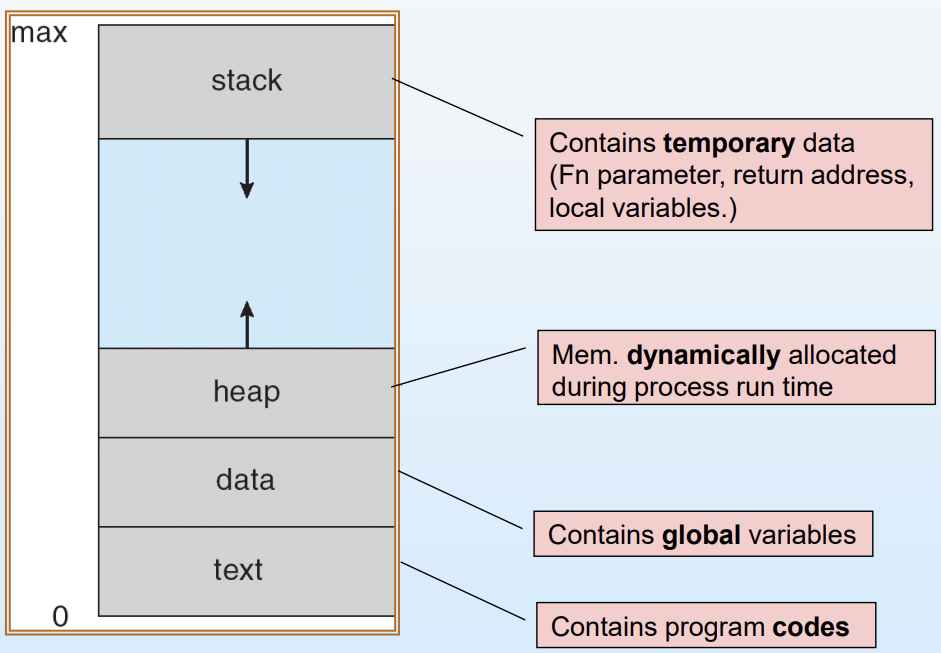 위 그림을 통해 이해해보자.
위 그림을 통해 이해해보자.
프로세스는 메모리에 다음 구조로 올라간다.
- Text
- 프로그램 코드(instruction 집합)
- Data
- 전역 변수(global variables) 저장
- 전역 변수: 여러 프로세스가 함께 공유 및 접근이 가능한 변수
- Heap
- 프로세스들의 실행 과정에서 dynamic하게 할당되는 메모리 공간
- 크기 변화 가능 (위로 증가)
- Stack
- 임시로 보관해야 할 데이터들이 저장되는 곳
- 지역 변수(local variables), 파라미터, return address 등을 저장
ex) 특정 system call을 호출할 때 같이 전달되어야 할 파라미터 값들을 stack을 이용해 전달할 때(저번 chapter에서 학습한 내용), 파라미터 값들의 시작 주소(=stack 중 가장 마지막으로 push된 곳의 주소)를 특정 레지스터를 통해 OS에게 알려줌
- 크기 변화 가능 (아래로 증가)
Process State
프로세스는 실행 중 상태가 계속 변하며, 아래의 5가지 상태로 구분할 수 있다.
✔ 상태 종류
1. new: 프로세스가 생성된 상태
2. ready: CPU 할당 대기 상태. CPU 할당 받으면 바로 running 상태가 됨
3. running: 실행되고 있는 상태
4. waiting: 이벤트(I/O작업 종료 등) 대기
5. terminated: 프로세스 끝난 상태
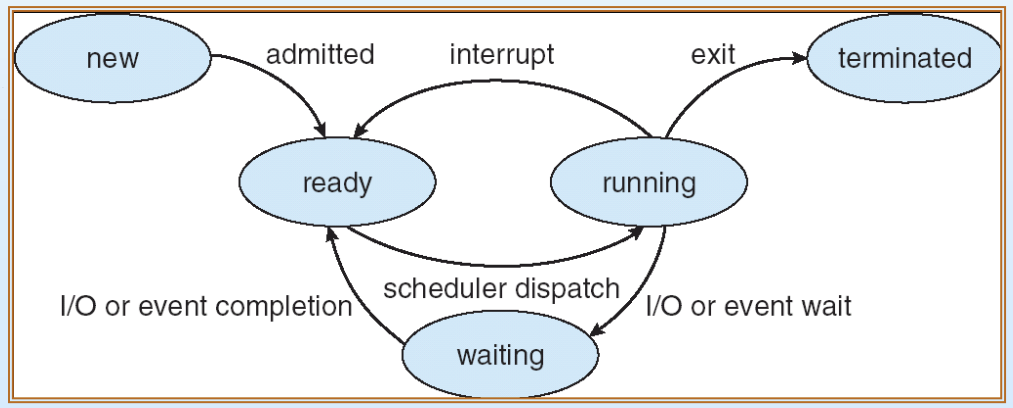
✔ 상태 전이 흐름
위 그림을 통해 process state의 전이 흐름에 대해 살펴보자.
new는 프로세스가 생성된 상태이다. 이 프로세스가 실행되려면, 자원들(코드, 메모리 공간, I/O장치 등등)이 필요하다. 이러한 자원들이 확보가 되면(CPU제외), ready 상태로 넘어간다.
이때 ready 상태인 프로세스는 하나가 아닐 수 있는데, scheduling에 의해 CPU에게 선택이 되면 running 상태로 넘어간다.
이후 running 상태에서 할 일을 다 끝내면 terminated가 되고, 프로세스에 인터럽트가 걸리면 작업을 잠시 멈추게 되는데, 이러한 인터럽트 처리는 금방 끝나기 때문에 멈췄던 프로세스가 굳이 waiting 상태로 빠질 필요 없이 바로 다시 CPU를 할당받을 수 있도록 ready 상태로 넘어간다.
만약 실행 중이던 프로세스가 파일을 읽거나 프린터를 출력하는 등 시간이 오래 걸리는 I/O 작업을 요청했는데 CPU가 그 작업이 끝날 때까지 멍하니 기다리면 낭비가 심하니 이 프로세스를 waiting 상태로 만든다.
오랜 시간이 걸려 I/O 작업이 끝나면, 프로세스는 waiting 상태에서 빠져나와 다시 CPU를 할당받을 준비를 갖춘 ready 상태로 바뀌어 Ready Queue의 맨 뒤에 가서 줄을 서게 된다.
이후 순서가 되어 scheduler에 의해 선택되면, 다시 running 상태로 돌아가 멈췄던 부분부터 실행을 이어나가게 된다.
Process Control Block (PCB)
각각의 프로세스는 자기 자신 프로세스에 대한 모든 정보를 PCB 안에 저장한다. 즉 모든 프로세스는 자기 자신의 PCB를 하나씩 갖고있다는 것을 말한다.
✔ 포함 정보
- Process state: new, ready 등등
- Program counter: 다음에 실행시킬 instruction의 주소
- CPU registers: CPU 내부 레지스터들의 값을 저장 (해당 프로세스 중지 후 나중에 다시 실행시킬 것을 대비해서)
- CPU scheduling info" 우선순위, pointer to queue 등
- Memory management info
- base/limit register: 프로세스한테 연속적인 메모리 공간이 한 덩어리로 할당될 때, 그 연속공간의 맨 처음 시작 주소 값을 base register에 저장하고, 시작 주소로부터 해당 프로세스가 얼만큼의 메모리 공간을 연속적으로 사용하고 있는지의 크기 정보를 limit register에 저장.
- page register: 메모리를 바둑판의 칸처럼 동일한 크기의 '페이지' 단위로 나누어 관리하는 paging 방식에서 사용되며, 프로세스에 필요한 메모리를 한 덩어리로 할당하는 대신 메모리 여기저기에 흩어져 있는 빈 공간(페이지)들을 찾아서 필요한 개수만큼 프로세스에 제공함. 이때 프로세스의 첫 번째 페이지부터 마지막 페이지까지 각각이 메모리의 어느 위치에 흩어져 있는지 순서대로 추적하고 관리해야 하는데, 이를 기록해 두는 곳이 page table이고, 모든 프로세스는 자기 자신만의 page table을 별도로 가짐
- segment table: 프로그램을 메인 프로그램, 데이터 파일, 서브루틴 등 논리적인 구성 요소(세그먼트) 단위로 나누어 관리하는 segmentation 방식에서 사용되며, paging 방식과 달리 각 segment는 그 크기가 서로 다름. 하나의 segment 내부는 연속적인 메모리 공간을 차지해야 하지만, 프로그램 전체를 구성하는 여러 segment들이 메모리상에서 서로 연속적으로 붙어있을 필요는 없음. 즉 segment table은 이렇게 메모리 곳곳에 분산되어 깔려 있는 크기가 서로 다른 세그먼트들이 각각 크기가 얼마이고 메모리의 어디에 위치해 있는지 관리하는 역할을 함.
- Accounting info: CPU 사용량, job/process 고유번호 등
- I/O status: 열린 파일, 장치 등
Context Switch
context switch는 실행 중이던 한 프로세스를 정지시키고, 스케줄링을 통해 다른 프로세스를 선택한 다음 CPU의 제어권을 새로운 프로세스로 넘겨주는 과정이다.
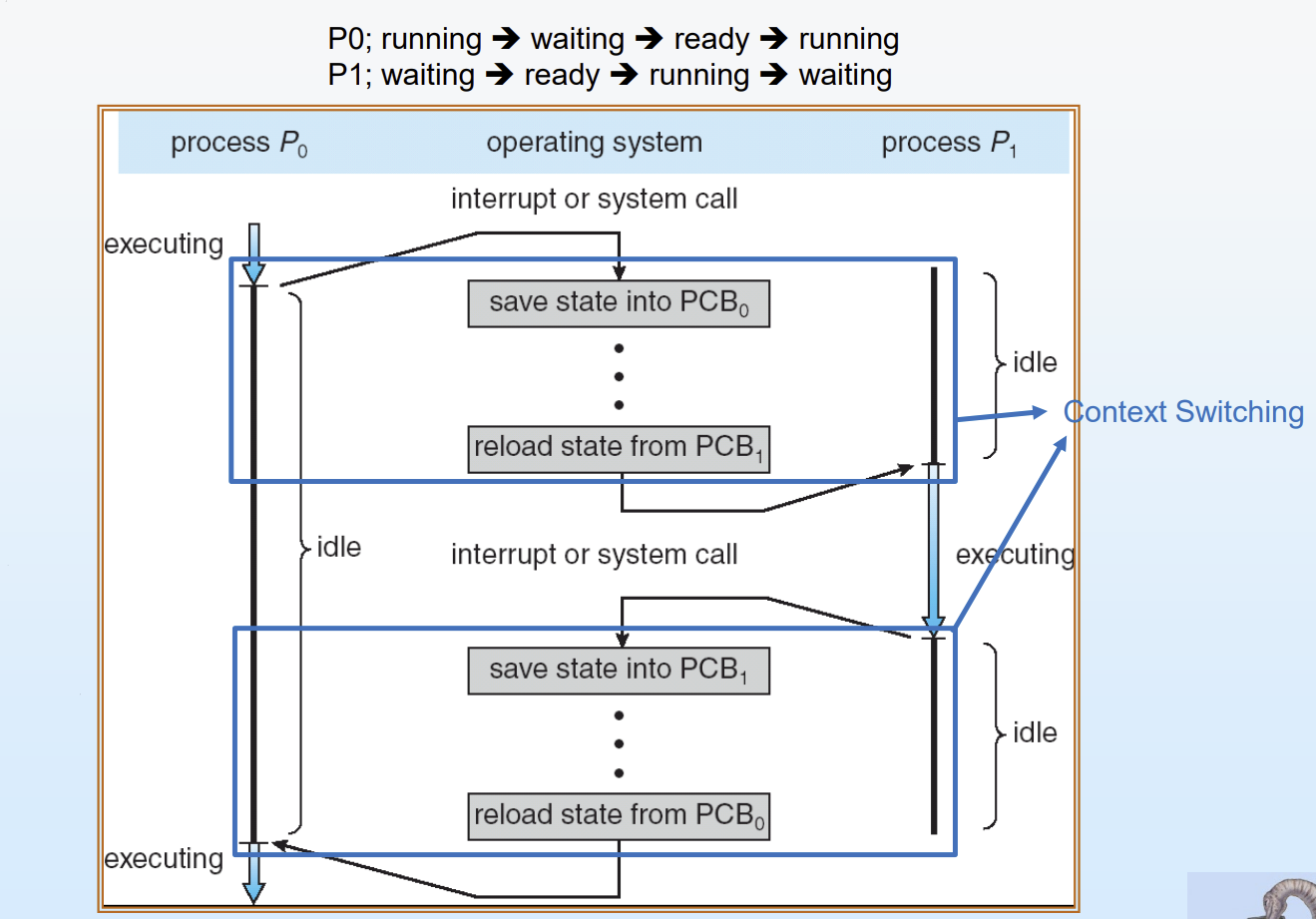
위 그림을 통해 Context switch 흐름을 이해해보자.
현재 CPU는 프로세스 P0을 실행 중이다. 이때 CPU 내부 레지스터에는 P0의 실행 상태가 들어 있다. 그러다가 인터럽트나 시스템 콜이 발생하면, 운영체제가 개입하게 된다.
운영체제는 먼저 지금까지 실행하던 P0의 상태를 잃어버리지 않기 위해, CPU 레지스터에 있는 현재 상태를 PCB₀에 저장(save)한다. 이 과정을 통해 P0의 실행 상태가 메모리에 안전하게 보관된다.
그 다음, CPU는 다른 프로세스(P1)를 실행해야 하므로, PCB₁에 저장되어 있던 P1의 상태를 가져와서 CPU 레지스터에 다시 올린다(reload). 이 순간부터 CPU는 더 이상 P0가 아니라 P1의 상태를 가지게 되고, 이어서 P1을 실행한다.
이후 P1이 실행되다가 다시 인터럽트나 시스템 콜이 발생하면, 동일한 과정이 반복된다. 즉, P1의 현재 상태를 PCB₁에 저장하고, PCB₀에 저장되어 있던 P0의 상태를 다시 CPU로 불러와서 실행을 이어간다.
결국 이 전체 흐름은, CPU가 한 번에 하나의 프로세스만 실행할 수 있기 때문에, 각 프로세스의 실행 상태를 PCB에 번갈아 저장하고 다시 불러오면서 여러 프로세스를 동시에 실행되는 것처럼 보이게 하는 과정이다.
✔ 특징
- context-switch time은 순수 오버헤드
- 하드웨어 성능에 따라 시간 달라짐
Process Scheduling Queues
✔ Queue 종류
- Job queue
- 시스템 내 모든 프로세스들이 거치게 되는 queue
- job queue에서 선택이 되면 new 상태가 됨. 즉 프로그램에서 프로세스로 바뀜
- Ready queue
- 메모리에 올라와 있고 CPU 기다리는 프로세스
- 즉 ready queue 안에 들어와있는 프로세스들이 ready상태인 프로세스들
- Device queue
- I/O 작업 대기
-> 프로세스는 상태 변화에 따라 queue 이동
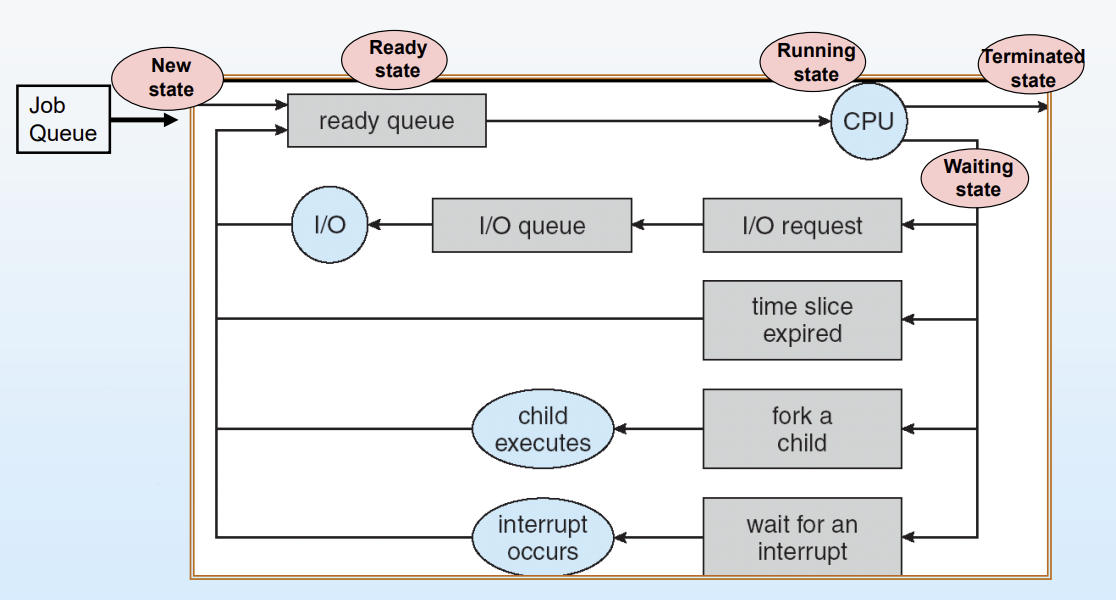 위 그림을 통해 process scheduling에 대해 알아보자.
위 그림을 통해 process scheduling에 대해 알아보자.
job queue에서 출발해 자원이 확보된 프로세스는 ready queue에 들어와 줄을 선다.
이후 차례가 되어 CPU를 할당받으면 프로세스는 running 상태가 되고, 실행 중인 프로세스에 다음과 같은 상황이 발생하면 정해진 큐로 다시 이동한다.
-
I/O 작업 요청: 오랜 시간이 걸리므로 하던 일을 멈추고 I/O queue (waiting상태)로 빠지고, 이후 I/O 작업이 완료되면 다시 ready queue로 돌아와 줄을 선다.
-
Time slice 만료: 특정 프로세스가 CPU를 너무 오래 독점하지 못하도록 정해진 최대 사용 시간이 만료되면, 강제로 실행을 멈추고 ready queue의 맨 뒤로 돌아가 다시 대기한다.
-
자식 프로세스 생성(Fork) 및 인터럽트 대기: 자식 프로세스를 만들어 작업이 끝나길 기다리거나, 특정 이벤트(인터럽트) 발생을 기다려야 하는 경우 waiting 상태로 빠졌다가 완료 후 ready queue로 돌아간다.
정리하자면, 프로세스 스케줄링의 표현은 프로세스들이 ready queue -> CPU 실행 -> device queue(또는 시간 초과로 바로 복귀) -> 다시 ready queue의 과정을 끊임없이 돌고 돌며 queue 사이를 이동하다가 최종적으로 terminated 상태에 이르는 과정으로 그려짐을 알 수 있다.
Schedulers
✔ Long-term scheduler (Job scheduler)
- job queue에서 프로세스를 꺼내서 ready queue로 넣어줌 (main memory로 올려줌)
- 호출 빈도 낮음 (long-term) -> 느리게 동작해도 상관없음 (may be slow)
✔ Short-term scheduler (CPU scheduler)
- ready queue에서 하나 선택해 CPU 할당시켜줌
- 매우 자주 실행됨 (short-term) → 빠르게 동작해야 함 (must be fast)
✔ Medium-term scheduler
- 어떤 프로세스가 swapping 되어야 하는지 결정
- swap out: 메모리 공간은 한정되어 있기 때문에, OS는 메모리를 잘 활용하기 위해 일부분만 실행된 프로세스들을 잠시 디스크로 내려보냄
- swap in: swap out된 프로세스들은 아직 실행이 완전히 끝난게 아니므로, 나중에 실행을 이어가려면 반드시 다시 메모리로 갖고와야함
-> 즉 medium-term scheduler는 swapping 작업을 조율하는 스케줄러
Process 유형
프로세스들은 하는 작업의 특성에 따라 I/O-bound process, CPU-bound process로 나눌 수 있다.
✔ I/O-bound process
- I/O 작업 많음
- CPU burst 짧음
✔ CPU-bound process
- 연산 많음
- CPU burst 김
Process Creation
✔ 특징
- 부모 → 자식 프로세스 생성 (tree 구조)
- 부모 & 자식의 자원 공유 방식
- 모든 자원 공유
- 일부 자원 공유
- 자원 공유 없음
✔ 실행 방식
- 부모/자식 동시 실행
- 부모가 자식 종료 기다릴 수도 있음
✔ Address space 할당 방식
부모 프로세스가 자식 프로세스를 생성할 때 주소 공간을 어떻게 구성할지에 대해 크게 두 가지 접근 방식이 있다.
-
주소 공간을 공유하는 경우: 자식 프로세스가 부모 프로세스와 동일한 프로그램과 데이터를 사용하며 메모리 공간을 같이 공유하는 방식. 이 경우 자식 프로세스는 부모가 하던 일을 똑같이 이어서 수행함
-
새로운 주소 공간을 부여하는 경우: 생성된 자식 프로세스에게 완전히 새로운 일감을 주기 위해 새로운 프로그램을 적재할 수 있는 별도의 새로운 주소 공간을 할당해 주는 방식
✔ UNIX 예시
UNIX 시스템에서는 fork와 exec라는 시스템 콜(System Call)을 사용하여 위와 같은 프로세스 생성 및 주소 공간 할당을 처리한다.
fork(): 새로운 자식 프로세스를 생성하는 시스템 콜. 만약 fork 명령만 사용하고 끝난다면, 자식 프로세스는 부모의 프로그램과 데이터, 즉 메모리 공간을 그대로 공유하여 부모와 똑같은 작업을 넘겨받아 수행함.exec(): 자식 프로세스에게 완전히 새로운 작업을 시키고자 할 때 사용하는 시스템 콜. fork를 통해 자식 프로세스를 먼저 생성한 뒤 이어서 exec를 호출하면, 자식 프로세스에게 새로운 메모리 공간을 부여하고 그곳에 새로운 프로그램과 데이터를 던져주어 전혀 다른 일감을 처리하게 만들 수 있음.
✔ C Program Forking Example
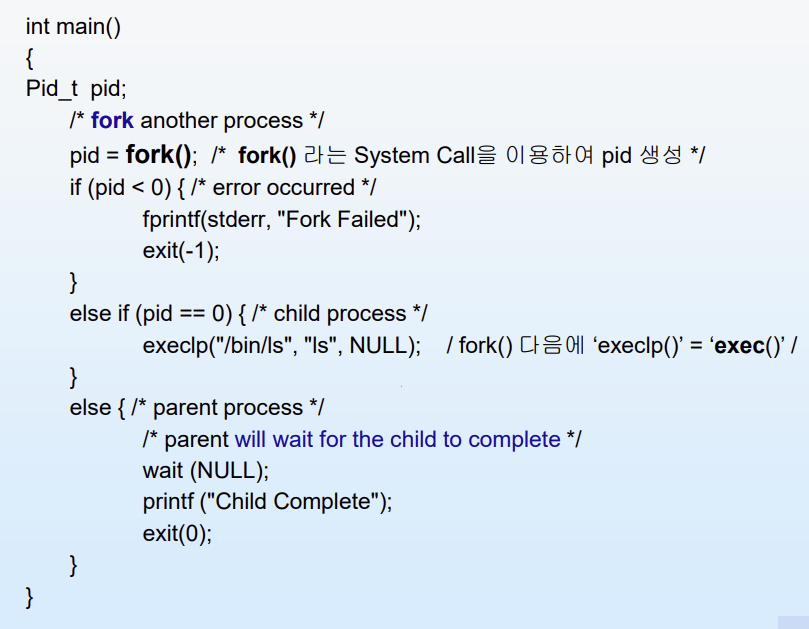 프로그램에서 fork 시스템 콜을 실행하면 새로운 프로세스 ID(PID)를 생성한다.
프로그램에서 fork 시스템 콜을 실행하면 새로운 프로세스 ID(PID)를 생성한다.
-
PID < 0 인 경우: 자식 프로세스 생성에 실패(Error)했음을 의미
-
PID == 0 인 경우: 성공적으로 자식 프로세스가 실행되는 부분이며, 이 안에서 exec 시스템 콜을 호출해 자식 프로세스에게 새로운 일을 부여할 수 있음
-
그 외의 경우 (부모 프로세스): 부모 프로세스는 자식 프로세스가 생성되어 맡은 작업을 다 끝마칠 때까지 대기(wait)하게 되며, 작업이 완료되면 결과를 넘겨받아 자신의 남은 작업을 계속 이어나감
Process Termination
process termination은 프로세스가 맡은 바 실행을 마치고 종료되는 것을 의미하며, '자연스러운 종료'와 '강제 종료' 두 가지 경우로 나누어 이해하면 좋다.
자연스러운 종료: 프로세스가 할 일을 무사히 마치고 정상적으로 종료될 때 다음과 같은 작업이 이뤄짐
-
결과 반환: 그동안 수행해 온 작업의 최종 결과물을 자신을 생성했던 부모 프로세스에게 넘겨줌
-
자원 반납 (Deallocation): 프로세스가 실행되는 동안 운영체제로부터 할당받아 사용했던 모든 시스템 자원들을 다시 운영체제에 반납
강제 종료 (Aborting)
-
자원 초과 사용: 자식 프로세스가 자신에게 허용된 제한치를 초과하여 너무 많은 자원을 무단으로 가져다 쓰는 경우, 이걸 그대로 두면 시스템 전체 자원이 고갈되어 시스템이 멈춰버리는 데드락(Deadlock) 상태에 빠질 수 있으므로 운영체제가 강제로 종료시킴
-
작업의 불필요: 자식 프로세스에게 시켰던 특정한 일이나 작업이 더 이상 필요 없어졌을 때 종료시킴
-
부모 프로세스의 종료: 부모 프로세스가 종료되면 그 밑에 딸려 있는 자식 프로세스들도 무조건 다 같이 종료시켜야함. 이렇게 부모 프로세스의 종료로 인해 연쇄적으로 밑에 있는 자식 프로세스들까지 모두 강제 종료시키는 현상을 캐스케이딩 터미네이션(Cascading Termination)이라고 함
Cooperating Processes
-
Independent Process
- 다른 프로세스의 실행에 영향을 주지도, 받지도 않는 독립적인 프로세스
-
Cooperating Process
- 다른 프로세스의 실행에 영향을 주거나 받는 프로세스
- 대표적으로 부모-자식 프로세스
Cooperating process의 장점
1. Information Sharing
- 메모리 공유를 통한 데이터 공유
2. Computation Speed-up
- 작업 분할 + 병렬 처리 (multi-CPU)
3. Modularity
- 유사한 기능을 갖고있는 것들은 별도의 프로세스한테 집어넣어서 모듈화시킴
4. Convenience
- 편집, 컴파일, 출력 등을 동시에 수행
Producer-Consumer Problem
producer-consumer problem은 cooperating process의 가장 대표적인 패러다임이다.
- producer: 뭔가를 만듦
- consumer: 만들어진 정보를 갖다 씀
즉 producer가 데이터를 생성하고 consumer가 이를 소비하는 구조
Producer → (Buffer) → Consumer
이때 producer<->consumer 간 데이터 이동은 buffer를 통해 이루어진다.

위 예시를 통해 살펴보면, compiler는 producer로서 assembly code를 만들어내고, assembler는 consumer로서 assembly code를 갖다쓴다.
즉 역할은 고정되지 않고 관점에 따라 바뀌는 것을 알 수 있다.
✔ Buffer 종류
이때 buffer의 종류로는 아래와 같이 크게 두 가지가 있다.
-
Unbounded Buffer
- buffer 크기 제한 X
-
Bounded Buffer
- buffer 크기 고정
Bounded Buffer (Shared Memory)
bounded buffer의 자료구조에 대해 알아보자.
✔ 자료구조 정의
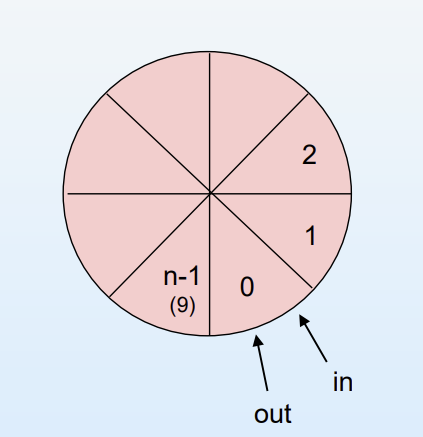
해당 예시에서는 이해를 돕기 위해 원형(Circular) 형태의 배열로 구성되어있고, 버퍼의 전체 개수(BUFFER_SIZE)를 10으로 선언했다.
in: producer에 의해 만들어진 data item을 집어넣는 위치out: consumer가 데이터를 빼가는 위치
#define BUFFER_SIZE 10
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;실제 사용 가능 공간 = BUFFER_SIZE - 1
✔ Insert() Method - Producer
producer는 뭔가를 만들고 난 이후에 buffer에 집어넣어야 하는데, 이때 producer의 가장 큰 관심사는 buffer가 꽉찼냐 안찼냐이다.
아래 코드를 살펴보면, (((in + 1) % BUFFER_SIZE) == out) 이 부분이 buffer가 꽉 찬 상태를 말하는 것을 알 수 있다.
while (true) {
/* Produce an item */
while (((in + 1) % BUFFER_SIZE) == out)
; /* do nothing -- no free buffers */
buffer[in] = item;
in = (in + 1) % BUFFER_SIZE; /* 9 다음에 0이 되도록 함 */
}✔ Remove() Method - Consumer
consumer의 가장 큰 관심사는 buffer에서 빼갈게 있는지 없는지이다.
아래 코드를 살펴보면, (in==out) 이 부분이 buffer가 비어있는지 체크하는 것임을 알 수 있다.
while (true) {
while (in == out)
; // do nothing -- nothing to consume
// remove an item from the buffer
item = buffer[out];
out = (out + 1) % BUFFER_SIZE;
return item;
}
- buffer full →
(in + 1) % BUFFER_SIZE == out- buffer empty →
in == out
이 알고리즘은 전체 버퍼 사이즈가 10개라도 최대 9개(BUFFER_SIZE - 1)까지만 채울 수 있고, 마지막 1칸은 항상 비워둬야해서 쓰지 못하게 된다. 만약 10칸을 꽉 채워버리게 되면, in이 out을 한 바퀴 돌아 따라잡게 되어 in == out 상태가 되는데, 이 상태는 '버퍼가 완전히 비어있을 때'의 조건과 완벽히 동일해지기 때문에, 시스템이 버퍼가 꽉 찬 것인지 비어있는 것인지 구분할 수 없게 되는 문제가 발생하기 때문이다.
InterProcess Communication (IPC)
IPC는 아래의 두 가지 이유로 사용한다.
1. 프로세스와 프로세스 간의 통신
2. 동기화(순서화) 시킴
✔ 특징
- IPC는 shared variable 방식을 사용하지 않고, message passing 방식을 사용함
- 두 프로세스 간 link를 연결하고, send/receive 하여 통신함
- link 구현 시 고려사항
- link에 2개 이상의 프로세스들이 연결될 수 있도록 할 것인가
- 통신하는 한 쌍의 프로세스 간 몇 개의 link를 만들 것인가
- 대역폭(성능)은 어떻게 할 것인가
- 메세지의 크기를 고정적으로 할 것인가 가변적으로 할 것인가
- 단방향 link인가 양방향 link인가
Communications Models
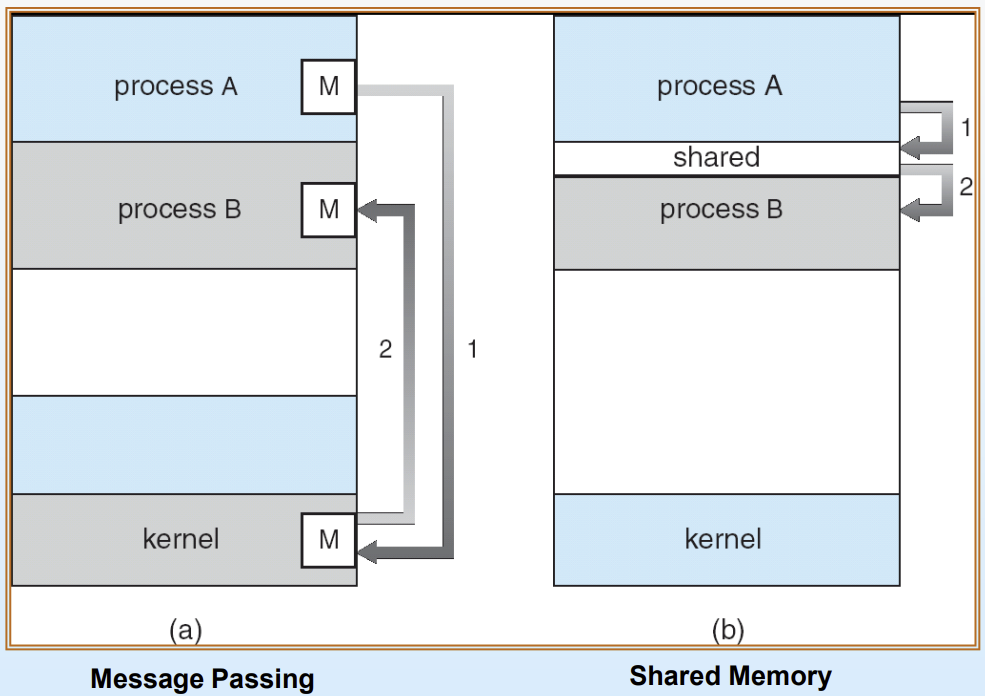
✔ Message Passing
위 그림 속 왼쪽에 해당하는 방식이 message passing방식이다. 이 방식에서는 직접적으로 send/receive 명령어를 사용해 통신하며, kernel에서 message passing방식을 지원해준다.
✔ Shared Memory
위 그림 속 오른쪽에 해당하는 방식이 shared memory방식이며, 통신하고자 하는 여러 프로세스들이 메모리의 일부분을 같이 공유한다. 프로세스 A는 shared memory에 쓰고, B는 여기서 읽어오는 구조다.
Communication 방식
✔ Direct Communication
직접 통신 방식에서는 sender 또는 receiver가 누군지 명시적으로 표시해야 한다.
send(P, message) - 프로세스 P에게 메세지를 보냄
receive(Q, message) - 프로세스 Q로부터 메세지를 받음
- link가 자동으로 형성됨
- 한 link는 오직 한 쌍의 프로세스하고만 연결됨
- 각 쌍 사이에는 오직 하나의 link만 존재
- 단방향 또는 양방향 link
✔ Indirect Communication (Mailbox)
간접 통신 방식에서는 sender 프로세스와 receiver 프로세스 사이에 mailbox가 존재하며, 데이터는 mailbox를 거쳐서 전달된다.
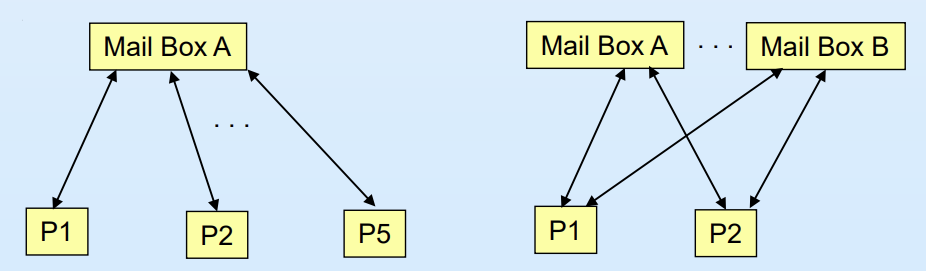
- 모든 mailbox 고유id를 갖고 있음
- 동일한 mailbox를 같이 공유하고 있는 프로세스들 사이에서만 전송이 이뤄짐. 즉 프로세스들이 같은 mailbox를 공유하고 있어야만 link가 형성됨
- 하나의 link(mailbox)에 여러 프로세스가 붙을 수 있음 -> 위 그림 속 왼쪽 부분
- 통신하고자 하는 프로세스 사이에 mailbox를 여러개 만듦. 즉 특정 mailbox가 고장나도 다른 mailbox를 이용해 통신 가능 -> 위 그림 속 오른쪽 부분
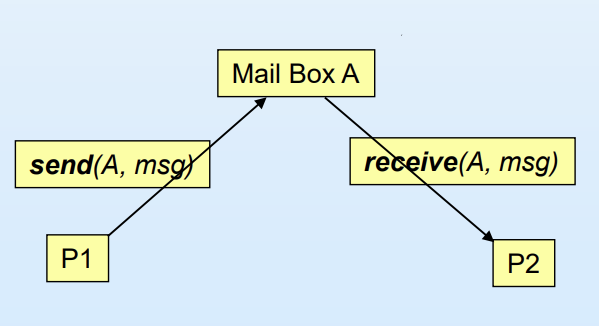
send(A, message) - mailbox A에게 메세지를 보냄
receive(A, message) - mailbox A로부터 메세지를 받음
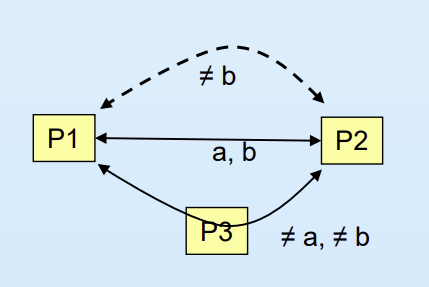
Mailbox sharing 문제
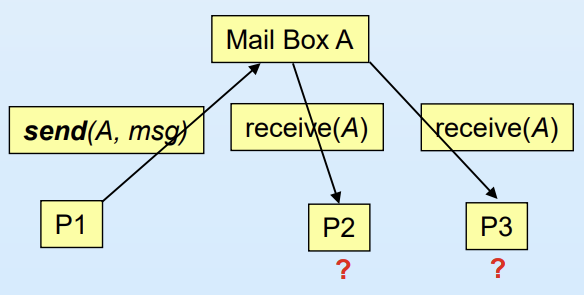 위 그림처럼 P1,P2,P3가 다 mailbox A를 공유하고 있는 상황에서, P1이 mailbox A로 메세지를 보냈을 때, 거의 동시에 P2와 P3가 mailbox A에서 receive명령어를 실행한다면, P1이 보낸 메세지를 P2가 가져갔는지 P3가 가져갔는지 불명확해지는 문제가 생긴다.
위 그림처럼 P1,P2,P3가 다 mailbox A를 공유하고 있는 상황에서, P1이 mailbox A로 메세지를 보냈을 때, 거의 동시에 P2와 P3가 mailbox A에서 receive명령어를 실행한다면, P1이 보낸 메세지를 P2가 가져갔는지 P3가 가져갔는지 불명확해지는 문제가 생긴다.
해결 방법
- 하나의 link가 최대 두 개의 프로세스 사이에서만 생성되도록 강제
- 어느 한 순간에는 오직 하나의 프로세스만이 receive명령어를 실행할 수 있도록 제한
- 시스템이 P2와 P3 중 아무거나 무작위로 receiver를 하나 선택해 메세지를 전달하게 두고, 이 경우 시스템이 sender에게 "네가 보낸 메세지 누가 받아갔다" 라고 알려주는 과정이 반드시 포함되어야 함
Synchronization
프로세스 간 통신(IPC)에서 동기화(Synchronization)란 프로세스들의 행동을 순서화하고, 메세지를 주고받을때 sender와 receiver가 모두 준비되어 서로 연결된 상태를 만드는 것을 의미한다.
message passing 환경에서 메세지를 주고받을때, 동기화 여부에 따라 blocking과 non-blocking 방식으로 나뉘어서 동작한다.
✔ Blocking (Synchronous)
- sender와 receiver 중 어느 한쪽이라도 준비가 되지 않았다면, 상대방이 준비돼 서로 연결될때까지 계속 대기함(blocking)
- 데이터를 임시로 담아둘 buffer 공간이 아예 없는 경우(zero capacity)에 sender와 receiver가 완벽히 맞물려야 가능하므로 이때 발생
- rendezvous(랑데뷰): sender와 receiver가 모두 준비돼 대기 상태(blocking)를 풀고 마침내 만나는 순간
✔ Non-Blocking (Asynchronous)
- 상대방의 준비 상태는 신경 쓰지 않고 즉시 자신의 작업을 수행
- 이 방식의 경우 중간에 buffer가 있어야 함
- sender는 메세지를 buffer에 보내놓고 자기 할 일 하러감
- receiver 역시 본인이 원할때 buffer에서 데이터 가져가며, 만약 buffer가 비어있으면(null) 그냥 다른일 하러감
만약 buffer 크기가 무제한이라면(unbounded capacity) sender는 언제든 제약 없이 보낼 수 있는 완벽한 비동기가 되지만, buffer 크기가 제한적이라면(bounded capacity) buffer가 꽉 차는 순간부터는 sender도 대기(blocking)해야함
Client-Server Communication
✔ Socket
socket은 네트워크 상에서 물리적으로 떨어져 있는 두 컴퓨터(client, server)가 통신을 하기 위해 연결하는 종단점으로, 통신은 한 쌍의 socket 사이에서 이루어지는 것이다.
즉 양쪽 컴퓨터에 socket이라는 문을 열어두고 데이터를 주고받는 것이라고 이해하면 된다.
✔ socket의 구성 요소
- IP 주소: 해당 컴퓨터의 고유 주소
- 포트 번호: 목적지 프로그램 (서비스)
✔ 예시
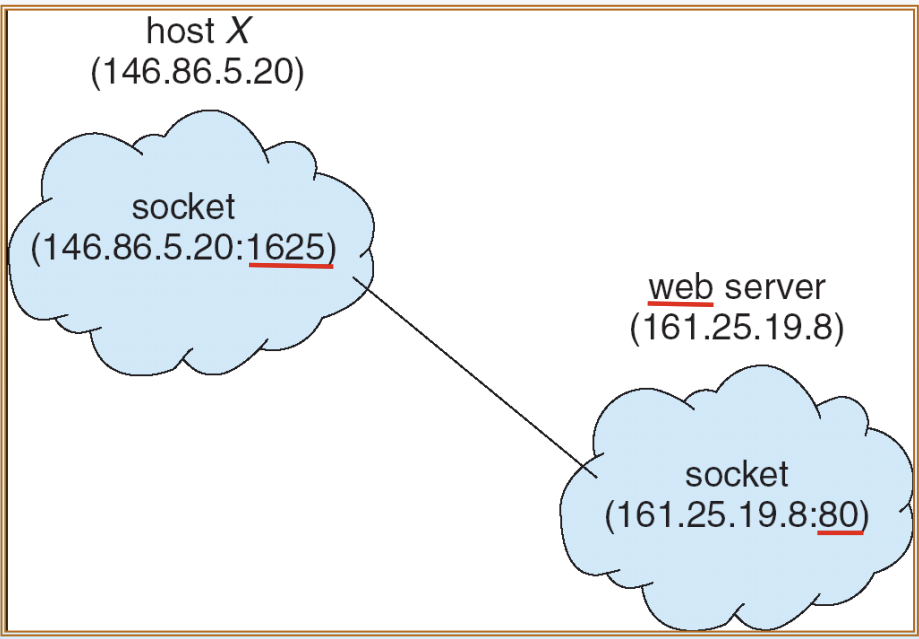
146.86.5.20: 내 컴퓨터의 주소
1625: 포트 번호
-> 146.86.5.20:1625이 socket
161.25.19.8: 웹 서버 주소
80: 포트 번호
-> 161.25.19.8:80이 socket
✔ RPC (Remote Procedure Call)
RPC는 우리가 일반적인 프로그래밍에서 미리 만들어진 라이브러리 함수를 호출하듯이, 물리적으로 멀리 떨어져있는 원격 컴퓨터에 존재하는 프로시저를 마치 내 컴퓨터에 있는 것처럼 호출해 실행하는 것으로, 네트워크를 통해 연결된 시스템 간에 프로시저 호출을 추상화하는 기술이다.
RPC가 네트워크 상에서 원활하게 작동하기 위해서는 client와 server 양쪽에 proxy(안내자) 역할을 하는 stub이 필요하다.
- client-side stub
- client의 proxy역할을 담당
- 먼저 server의 위치를 알아낸 뒤, 실행을 요청할 프로시저의 이름과 거기에 사용될 파라미터들을 하나의 메세지로 packing해 server로 전송
- server-side stub
- server의 proxy역할을 담당
- client-stud이 보낸 메세지를 전달받아 포장을 풀고(unpacking), 요청받은 실제 프로시저를 찾아 client가 보낸 파라미터를 넘겨주어 실행시킨 뒤, 최종 실행값을 다시 client측으로 돌려보냄
✔ RPC 동작 예시
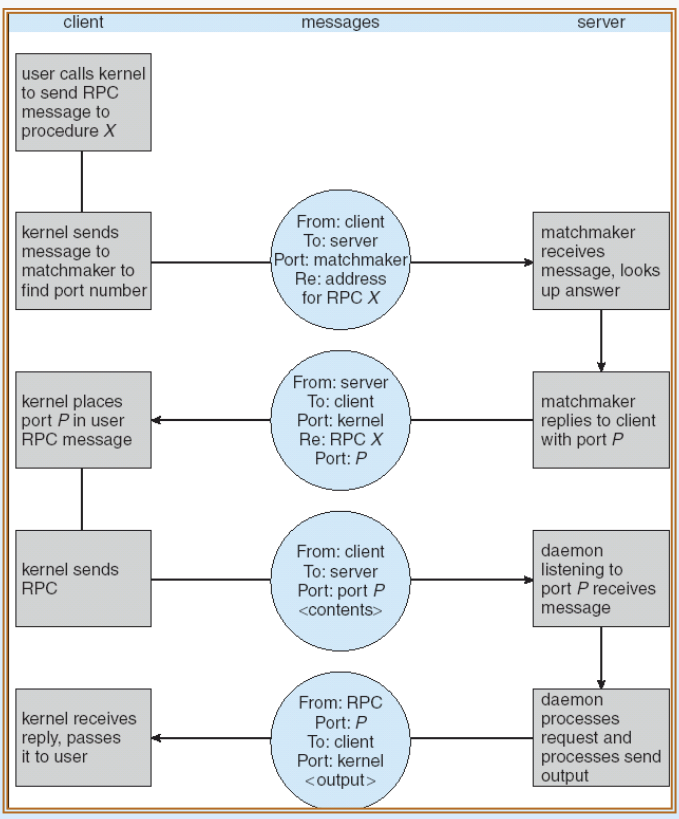 위 그림을 통해 RPC의 흐름을 살펴보자.
위 그림을 통해 RPC의 흐름을 살펴보자.
일단 해당 상황은 client쪽에서 server쪽에 있는 특정 프로시저 X를 호출해서 쓰는 상황이다.
먼저 client는 server의 matchmaker에게 연락해 자신이 원하는 프로시저 X에 접근하기 위해 몇번 포트를 사용해야 하는지 물어본다.
포트 번호를 전달받은 client가 해당 포트로 호출 요청을 보내면, server측에서는 demon 프로세스가 이를 대기하고 있다가 받아서 처리한 후 결과값을 다시 돌려주며, 최종적으로 client의 커널을 거쳐 user program에 결과가 전달된다.
✔ RMI (Remote Method Invocation)
RMI는 Java와 같은 객체지향 환경에서 물리적으로 떨어져있는 원격 컴퓨터의 객체 내부에 존재하는 method를 호출해 실행하는 기술이다.
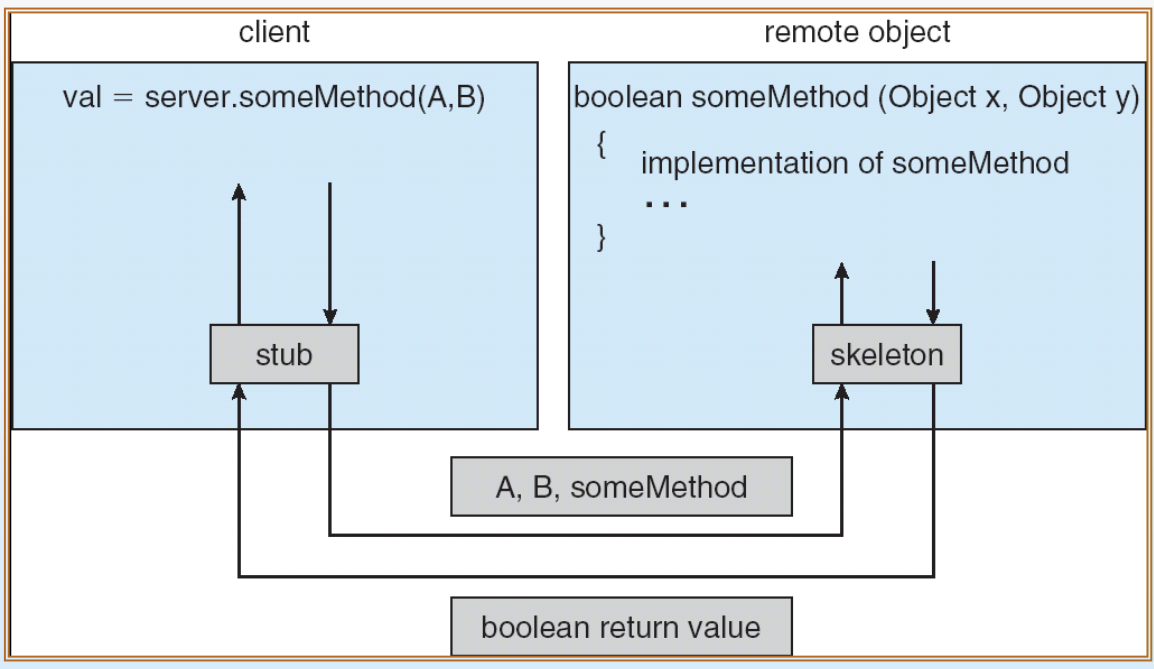 마찬가지로 그림을 통해 흐름을 살펴보자.
마찬가지로 그림을 통해 흐름을 살펴보자.
client측의 proxy 역할을 하는 stub가 실행하고자 하는 server의 method이름(ex:someMethod)과 여기에 전달할 파라미터 값들을 하나로 포장해 server쪽으로 전송한다.
server측에는 client의 stub과 같은 역할을 하는 skeleton이 있고, skeleton은 전달받은 메세지의 포장을 풀고, 그 안에 들어있던 파라미터들을 이용해 server 내 실제 method를 찾아 실행한다.
method실행이 끝나고 결과값(boolean값)이 나오면, server의 skeleton이 이 결과값을 다시 포장해 client쪽으로 돌려보낸다.
마지막으로 client의 stub가 이 결과 메세지를 받아 포장을 푼 뒤, 최초에 원격 요청을 했던 user program에게 최종적으로 넘겨준다.
