
Threads
프로세스를 더 잘게 쪼갤 수 있으면 그들 각각을 스레드라고 한다.
✔ Thread란
- CPU 이용의 가장 기본 단위 (basic unit of CPU utilization)
- 경량 프로세스 (Lightweight Process)
✔ Thread의 구성 요소
- Thread ID
- Program Counter (PC)
- Register Set
- Stack Space
✔ Thread가 공유하는 것
같은 프로세스 내의 thread들은 다음을 공유한다. 즉 어느 한 프로세스가 여러 개로 쪼개져서 multithread 환경이 되면, 그 thread들 간에는 다음을 함께 공유한다.
- Code Section
- Data Section
- OS Resources
heavyweight process vs ligthweight process
- heaveyweight process(중량급 프로세스): 프로세스 안에 thread가 하나만 존재하는 프로세스. 즉 전통적인 "프로세스"를 의미
- lightweight process(경량급 프로세스): 프로세스 안에 여러 개의 thread가 존재. 즉 thread를 부르는 또다른 이름
Single and Multithreaded Process
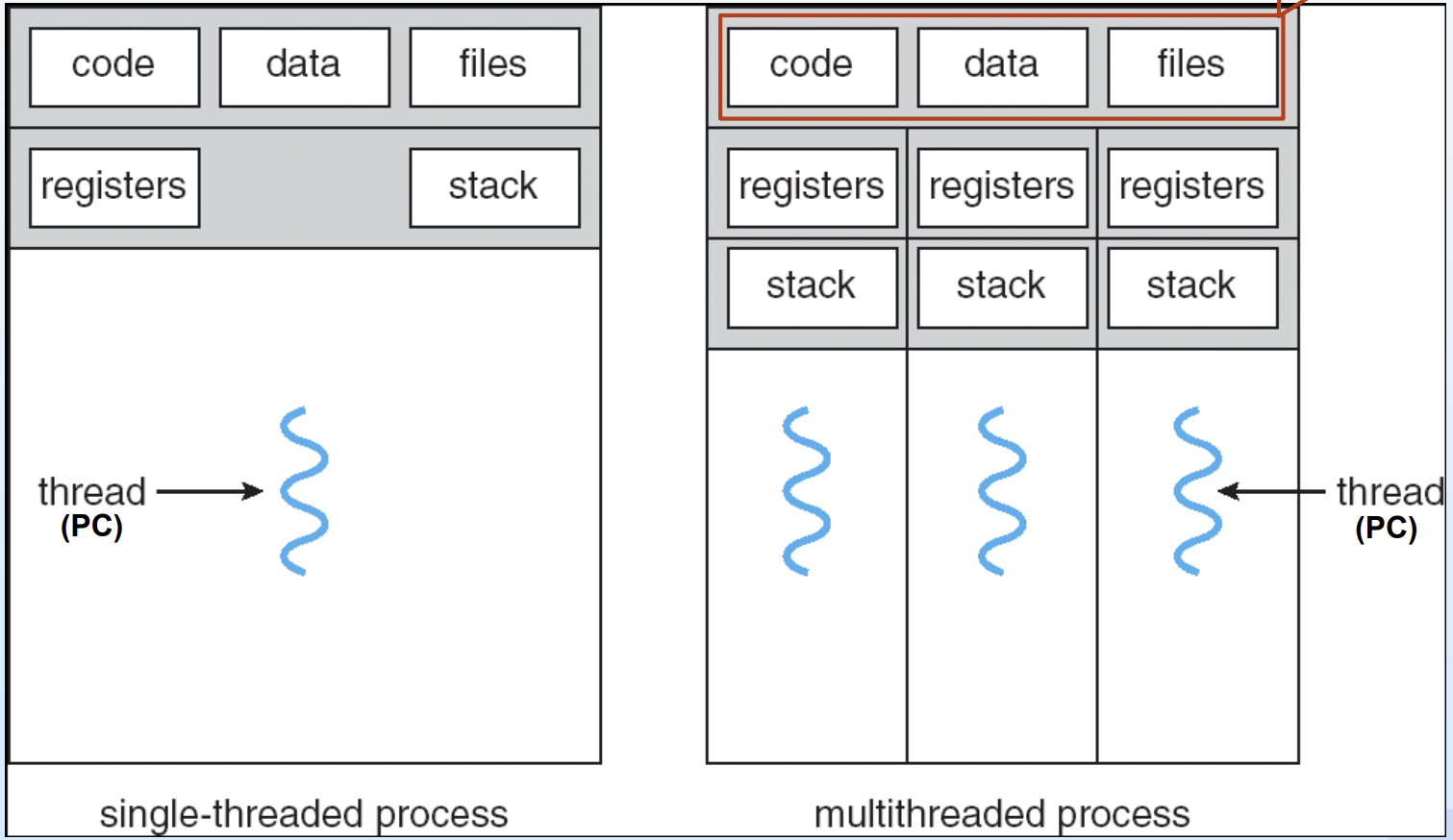
✔ Single-threaded Process
- 하나의 실행 흐름만 존재
- heavyweight process
✔ Multithreaded Process
- 여러 thread가 동시에 실행
- 각 thread는 독립적인 실행을 위해 자신만의 register set과 stack공간을 따로 보유하지만, code section, data section, os자원들은 thread 간에 서로 공유함
- multithread환경에서는 하나의 thread가 block당하거나 waiting상태에 빠진다고 해도, 같은 작업에서 파생된 다른 thread들을 계속 실행될 수 있다.
- 이러한 협력(cooperation) 덕분에 시스템 전체의 처리량(throughput)과 성능이 증가한다.
Process vs Thread (producer-consumer예시)
producer-consumer 처럼 공통된 buffer를 공유해야 하는 application에서 thread를 사용하면 process에 비해 이득이 많다. 아래의 흐름을 통해 확인해보자.
✔ Process 이용 시
- 한 프로그램 내에서 producer consumer가 돌다가 buffer가 꽉 찼는지 확인(while문)했을때 buffer가 꽉 찼다면, producer는 아무 작업도 하지 못하게 block당하게 된다.
- 이 상황이 해결되려면 아래쪽의 consumer process가 실행되어 buffer 안의 데이터를 꺼내가야 한다.
- 하지만 이처럼 process 기반에서는 하나의 흐름이 막히면 전체 프로그램이 block당한 상태에 빠지기 때문에 consumer process까지 실행이 도달하지 못해 시스템이 멈춰있게 된다.
✔ Thread 이용 시
- 이를 thread로 구현하게 되면, producer thread가 buffer가 꽉 차서 block 당하더라도 같은 프로그램 내에 있는 consumer thread는 중단 없이 계속 돌 수 있다.
- 살아있는 consumer thread가 buffer 안에 만들어진 데이터를 끄집어 가져가게 되고, 이로 인해 buffer full이 깨지게 된다.
- 빈 공간이 생겼으므로, block 당해있던 producer thread가 다시 대기 상태에서 풀려나 자신의 작업을 정상적으로 이어서 수행할 수 있게 된다.
Thread의 장점
1. Responsiveness (반응성)
어느 한 thread가 I/O 작업이나 인터럽트 등의 이유로 block당하거나 waiting 상태에 빠지더라도 같은 작업에서 파생된 다른 thread들은 중단 없이 계속 실행될 수 있어 더 빠른 반응성을 제공한다.
2. Resource Sharing (자원 공유)
여러 thread들은 code section, data section, os자원들을 함께 공유하기에 자원 관리가 용이하다.
3. Economy (경제성)
thread들은 동일한 주소공간을 사용하기 때문에, 실행 중인 thread를 중지하고 다른 thread로 전환하는 context switching 시 레지스터 값 변경 등 메모리 관리에 수반되는 오버헤드가 발생하지 않는다.
4. Multiprocessor 활용
CPU가 여러 개인 multiprocessor 환경에서는, 하나의 프로세스가 여러 thread로 나뉘어있을 때, CPU 하나당 thread를 하나씩 할당해 병렬로 작업을 처리할 수 있다. 이를 통해 단위 시간당 처리하는 일의 양(throughput)이 늘어나고 전체적인 성능이 좋아진다.
Multi Process vs Multi Thread
✔ Multi Process
- 각각의 프로세스들은 서로 독립적
- 다른 주소 공간 사용
- 서로 보호 필요
- PC, register set, stack pointer로 구성
✔ Multi Thread
- 각각의 스레드들은 하나의 프로세스 내부에서 쪼개져나옴
- 같은 주소 공간 공유
- context switch 비용 감소
- 보호장치 불필요
- PC, register set, stack space로 구성
Stack pointer (multiple process)
process는 중량급 프로세스로 분류되며, 작업에 따라 상대적으로 훨씬 더 많은 스택 공간을 필요로 할 가능성이 높음. 따라서 운영체제는 처음부터 큰 공간을 무작정 할당하는 대신, stack pointer의 값(위치)만 제공. process가 실행되면서 해당 pointer가 가리키는 위치로 접근하면, 그 시점부터 필요한만큼의 스택 공간이 계속해서 동적으로 제공되는 방식
Stack space (multiple thread)
-> thread는 process를 더 잘게 쪼갠 경량급 프로세스이므로 사용하는 스택 공간의 크기가 상대적으로 작음. 즉 운영체제는 pointer만 주고 나중에 공간을 늘려주는 방식 대신 처음부터 필요한만큼의 스택 공간 전체를 한번에 다 줘버리는 방식 사용
Thread의 종류 3가지
1. Kernel-supoorted threads
OS의 kernel level에서 직접 지원하는 thread이다. OS가 주체가 되어 thread의 생성, 관리, 종료 등과 관련된 전반적인 작업을 kernel level에서 처리한다.
2. User-level threads
OS의 kernel과는 무관하게 user level에서 독자적으로 지원되는 thread이다. user level에 있는 thread library에서 제공하는 기능들을 이용해 thread의 생성, 관리, 종료 작업 등을 수행하며, kernel에게 인터럽트 걸어서 발생하는 오버헤드가 없어 thread switching이 빠르게 수행된다.
3. Hybrid approach
kernel level thread와 user level thread를 모두 지원하는 형태이다.
User-Level Thread vs Kernel-Level Thread
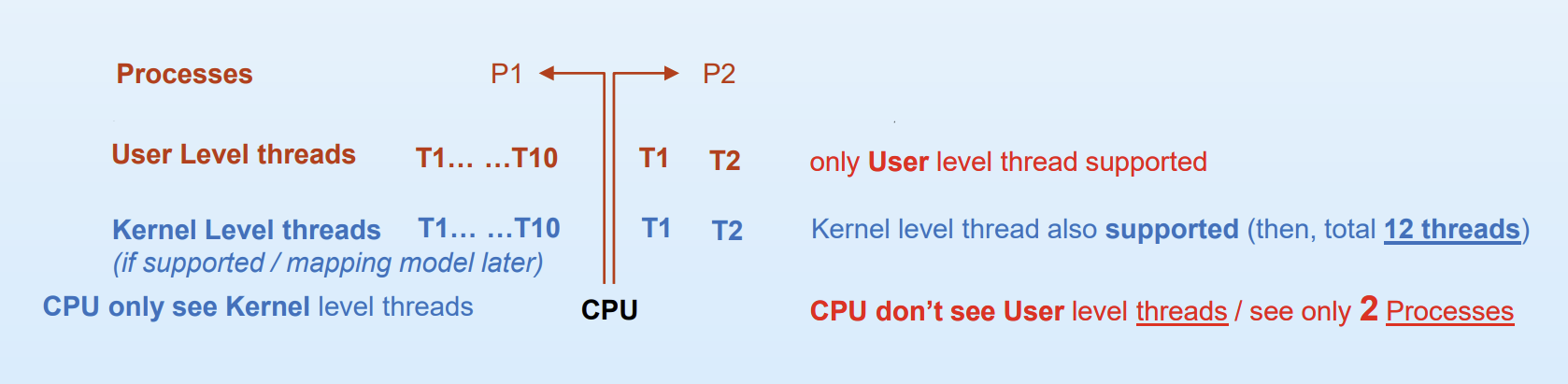 user level thread와 kernel level thread를 이해하기 위해 위 사진을 통해 알아보자.
user level thread와 kernel level thread를 이해하기 위해 위 사진을 통해 알아보자.
P1, P2 두개의 프로세스가 있고, P1은 T1~T10, P2는 T1~T2로 쪼개지는 상황이다.
이때, CPU는 kernel level의 thread만 보고, user level의 thread는 보지 못한다.
✔ User-Level Thread만 지원되는 경우
위 그림 속 빨간 글씨에 해당한다. CPU는 user level의 thread는 보지 못하기 때문에 P1, P2 오직 두개의 프로세스만 보인다. 즉 CPU는 P1 내부의 thread 중 어떤 것이 실행 중인지 모른다. 그냥 P1 실행 중인 것만 안다. 이때 kernel은 프로세스만 스케줄링하고, 프로세스 내부 thread는 그걸 나눠 써야하므로 user-level thread는 unfair scheduling의 특징을 가진다.
✔ kernel-Level Thread도 지원되는 경우
위 그림 속 파란 글씨에 해당한다. kernel은 thread를 알고 있으므로 CPU가 프로세스 말고 thread를 직접 실행 단위로 사용한다. 즉 CPU는 T1, T2 등을 직접 실행 가능하고, 총 12개의 thread를 실행할 수 있다. 12개의 thread를 놓고 kernel이 직접 스케줄링해주기 때문에 kernel-level thread는 fair scheduling의 특징을 가진다.
Multithreading Models
앞서 살펴 본 그림에서는 user level thread의 개수와 kernel level thread의 개수가 동일해 1:1 매핑이 되지만, 주로 kernel level thread 개수가 훨씬 더 적은 경우가 대부분이기 때문에 그런 경우에는 경합을 벌여야 한다. multithreading models에서는 그러한 내용을 학습하고자 한다.
1. Many-to-One
여러 개의 user level thread가 단 1개의 kernel level thread에 매핑되는 방식이다.
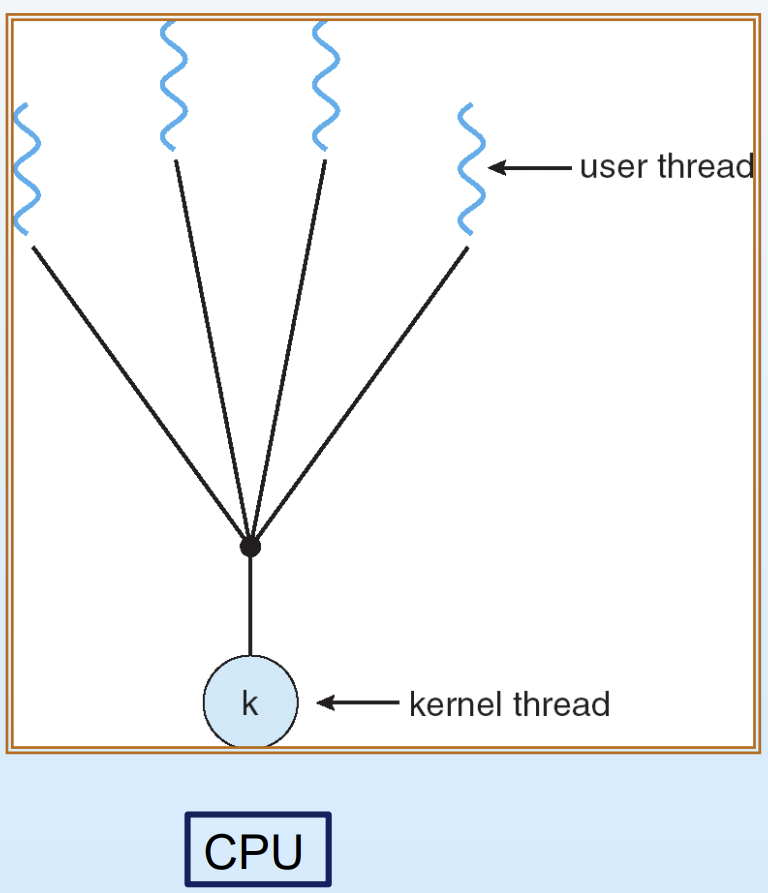 process라는 커다한 작업을 user level에서 임의로 잘게 쪼개 일감을 나눠놓는다. 이걸 "말"로 일한다고 표현한다. user level thread는 OS(kernel)와 무관하게 만들어지므로 자원을 거의 소모하지 않아 그냥 논리적으로 "작업을 4개로 쪼개라" 라고 말로만 지시해놓은 상태와 같기 때문이다. 반면, 실제로 CPU의 일감으로 보여지며 실질적인 일 처리를 수행하는 주체인 kernel level thread를 "행동"으로 일한다고 표현한다. 즉 user level에서 아무리 말로 일감을 여러 개로 쪼개놨더라도, 그 작업들이 실제로 실행되고 완료되려면 반드시 행동으로 일 처리를 담당하는 kernel level thread에 매핑되어야 한다.
process라는 커다한 작업을 user level에서 임의로 잘게 쪼개 일감을 나눠놓는다. 이걸 "말"로 일한다고 표현한다. user level thread는 OS(kernel)와 무관하게 만들어지므로 자원을 거의 소모하지 않아 그냥 논리적으로 "작업을 4개로 쪼개라" 라고 말로만 지시해놓은 상태와 같기 때문이다. 반면, 실제로 CPU의 일감으로 보여지며 실질적인 일 처리를 수행하는 주체인 kernel level thread를 "행동"으로 일한다고 표현한다. 즉 user level에서 아무리 말로 일감을 여러 개로 쪼개놨더라도, 그 작업들이 실제로 실행되고 완료되려면 반드시 행동으로 일 처리를 담당하는 kernel level thread에 매핑되어야 한다.
단점
CPU가 인식하는 kernel level thread가 하나뿐이기 때문에, 실행 중이던 user level thread가 I/O 작업 등의 이유로 block 당하게 되면 나머지 user level thread들이 대기하고 있더라도 전체 작업이 멈춰버린다.
2. One-to-One
user level thread 하나당 kernel level thread 하나를 1:1로 매핑하는 방식이다.
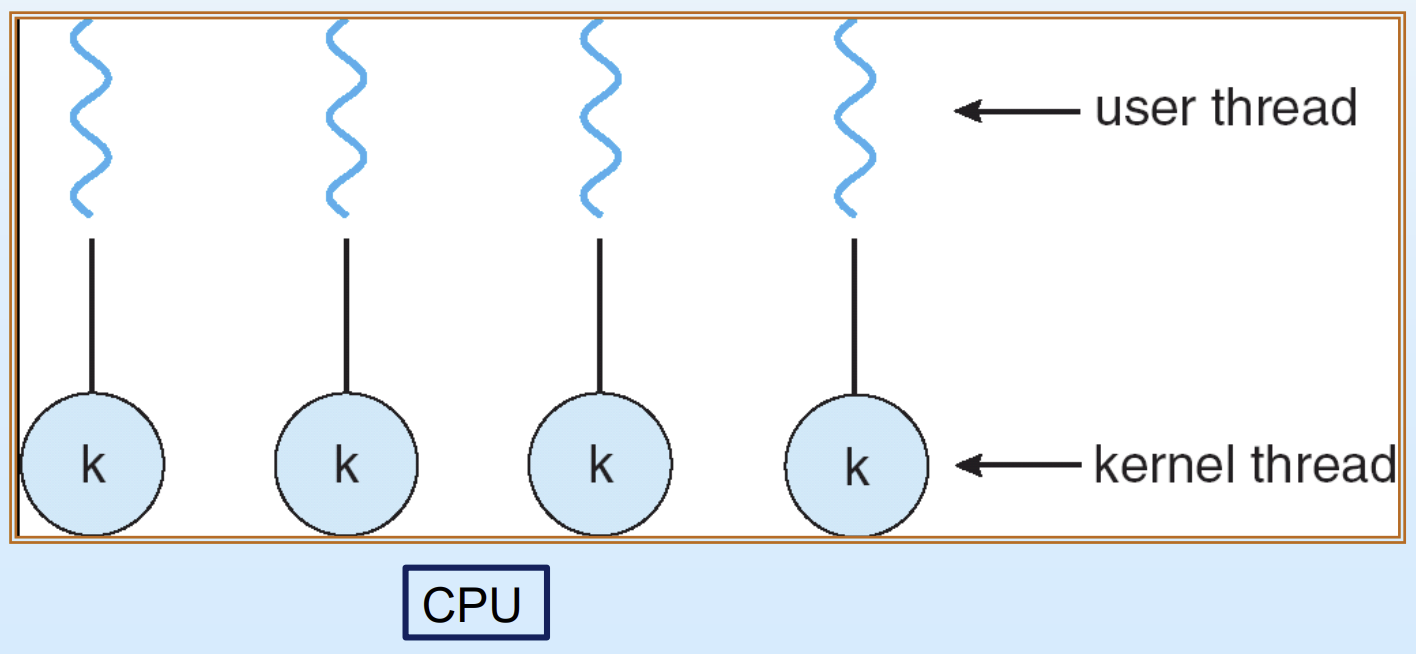
장점
어느 한 thread가 block 되도 CPU가 다른 kernel level thread를 선택해 작업을 이어갈 수 있으므로 many-to-one 모델의 blocking 문제를 해결한다.
단점
user level thread를 만들때마다 kernel level thread도 함께 만들어야 하므로 시스템 자원 소모와 오버헤드가 발생하며, thread를 무한정 만들 수 없다는 제약이 따른다.
3. Many-to-Many
다수의 user level thread가 그보다 적거나 같은 적정 개수의 kernel level thread에 매핑되어 kernel thread를 잡기 위해 경합하는 방식이다.
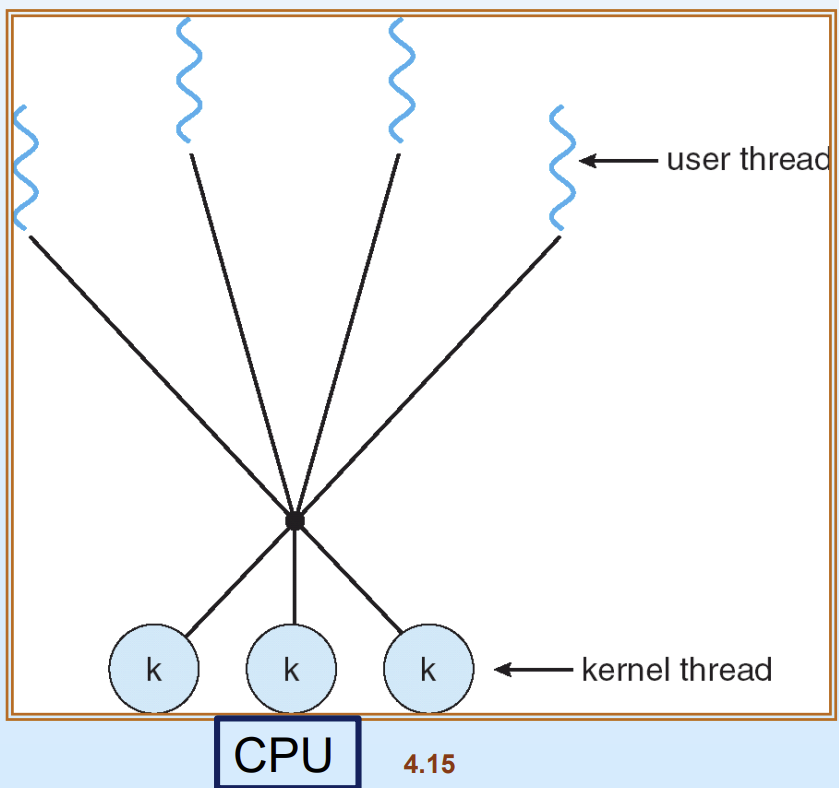
장점
시스템 자원을 고려해 최적이 kernel level thread 개수(ex:100개)를 미리 정해놓고 운영하므로, user thread가 아주 많아져도(ex:500개) 과부하가 걸리지 않아 many-to-one과 one-to-one모델의 단점을 모두 보완할 수 있다.
4. Two-Level Model
다대다 모델 운영 중, 중요한 user level thread가 kernel thread를 잡기 위한 경합에서 밀려 뒤로 쳐지는 것을 막기 위해 등장한 혼합 모델이다.
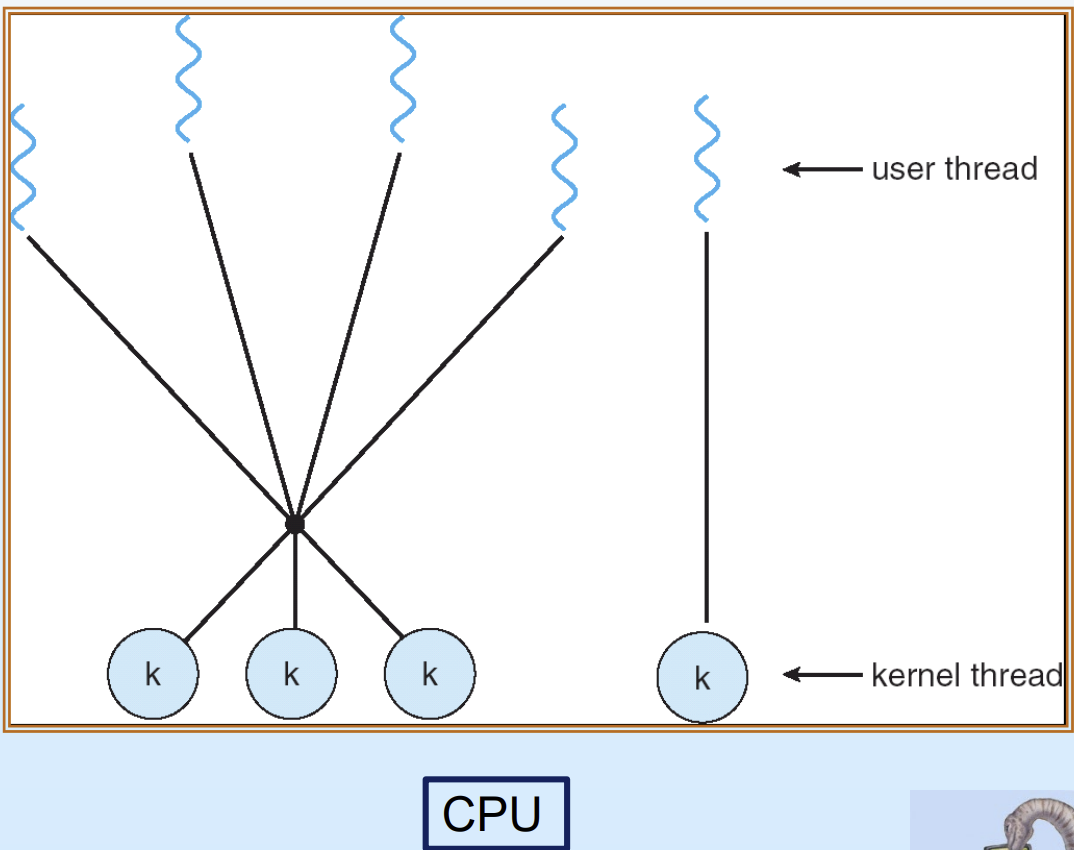 빨리 처리해야 하는 중요한 thread는 kernel level thread와 1:1로 전용 할당해주고, 덜 중요한 나머지 thread들만 many-to-many 방식으로 경합하게 만든다.
빨리 처리해야 하는 중요한 thread는 kernel level thread와 1:1로 전용 할당해주고, 덜 중요한 나머지 thread들만 many-to-many 방식으로 경합하게 만든다.
Threading Issues
thread 환경을 구성하고 사용할 때 발생할 수 있는 여러 가지 고려 사항들에 대해 알아보자.
✔ fork() & exec()
어느 한 thread가 자식 프로세스를 생성하는 fork() system call을 호출했을 때 동작 방식에 관한 이슈. 즉 fork()라는 system call을 호출하면 해당 thread 하나만 복제할 것인지, 아니면 프로세스 내 모든 thread를 전부 다 복제할 것인지에 관한 이슈이다.
이는 fork()호출 이후 exec() system call이 바로 이어서 실행되는지 여부에 따라 결정된다.
- exec()이 바로 이어지는 경우: 해당 system call을 호출한 그 thread 하나만 복제
- exec()이 바로 이어지지 않는 경우: 기존 프로세스 내 같이 있던 모든 thread들을 전부 다 복제
✔ Thread Cancellation
thread가 작업을 끝마치기 전에 강제로 종료시키는 것을 말하며, 두 가지 방식이 있다.
1. Asynchronous Cancellation
- 비동기식 취소
- 명령이 떨어지면 그 즉시 thread를 비정상 종료시킴
2. Deferred Cancellation
- 지연된 취소
- thread가 중요한 공유 데이터를 변경하고 있을 때 강제 종료되는 것을 막기 위해 thread code 중간중간에 cancellation point를 삽입해두며, 취소 명령이 떨어져도 즉시 종료하지 않고 이 point에 도달했을 때만 안전하게 종료되도록 지연시킴
✔ Signal Handling
어떤 signal이 발생했을 때, 이를 어떤 thread에 알려주어 처리하게 할 것인지에 관한 이슈이다.
Signal 처리 방법
- 특정 thread에 전달
- 모든 thread에 전달
- 특정 thread 그룹에 전달
- 하나의 thread가 전담
✔ Thread Pool
시스템의 자원을 고려해 적정 kernel level thread의 개수를 미리 정해 pool에 집어넣는다. 이 thread들은 평소에 pool에 대기하고 있다가, 작업 요청이 들어오면 하나씩 배정받아 일을 처리하며, 작업이 끝나면 thread를 삭제하지 않고 다시 pool로 돌아가 다음 작업을 기다린다.
장점
- 새로운 요청이 들어올때마다 thread를 새로 생성하는 것보다 작업 처리 속도가 훨씬 빠름
- 동시에 실행되는 thread의 총 개수를 pool의 크기만큼으로 제한해 자원 관리를 용이하게 함
✔ Thread Specific Data
thread들이 code나 data section을 공유함에도 불구하고, 각각의 thread가 자신만의 고유한 별도 데이터를 가질 수 있도록 지원하는 기능이다.
왜 필요한가?
- Thread pool 환경에서의 작업 할당
: 새로운 일감이 들어왔을 때 thread pool에서 대기 중인 thread 하나를 배정해 일처리를 맡기게 되는데, 이때 해당 작업 처리에만 필요한 특정 고유 데이터를 thread에 전달해 실행하게 할 수 있어야 한다. - 은행 트랜잭션 예시
: 은행 시스템에서 여러 thread들이 송금이나 인출 같은 트랜잭션을 각각 하나씩 맡아서 처리한다고 가정할 때, 여러 thread들이 동시에 '송금'이라는 같은 작업을 수행하더라도, 각 트랜잭션마다 대상이 되는 '계좌번호'는 전부 다를 수밖에 없다.
-> 즉 thread들이 code와 data 등 자원을 공유하는 환경 속에서도 계좌번호와 같이 각자의 작업에 필요한 고유 데이터를 개별적으로 저장하고 활용할 수 있도록 지원하기 위해 thread specific data가 필요하다.
✔ Scheduler Activations
시스템을 효율적으로 운영하기 위해 user level thread와 kernel level thread 간에 정보를 주고받는 communication 방법에 관한 이슈이다. M:M모델이나 two-level모델은 user level thread를 처리하기 위해 kernel level thread를 몇개나 할당할지가 매우 중요하다. 너무 많으면 자원이 낭비되고, 너무 적으면 병렬성이 떨어지기 때문이다. 따라서 kernel과 thread library간 의사소통이 필수적이다.
이때 application이 수행하는 작업이 CPU를 많이 사용하는 CPU-bound 작업인지, 입/출력 대기가 많은 I/O-bound 작업인지에 따라 필요한 kernel level thread의 적정 개수가 달라진다.
- CPU-bound: kernel level thread 많이 필요
- I/O-bound: kernel level thread 조금만 있어도 됨
즉 시스템은 상황에 맞춰 이 적정 개수를 결정하고 유지해야하므로, 두 level간에 지속적으로 통신할 필요성이 생기게 되고, 이런 통신 방식을 upcall이라 한다.
LWP (Lightweight Process)
LWP는 user level thread와 kernel level thread 중간에 위치해 동작하는 가상의 프로세서 역할을 한다. 그림을 통해 구조를 살펴보자.
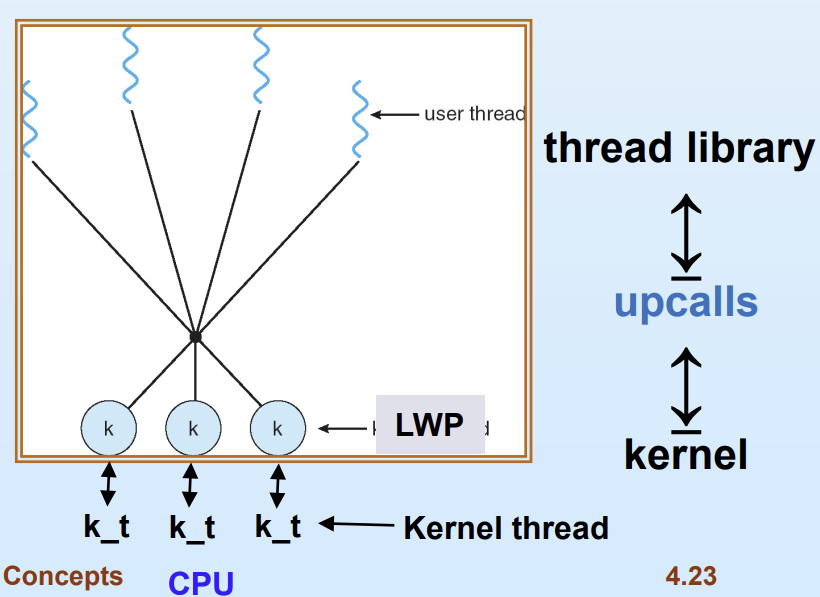 즉 user level thread들이 실제 일감을 처리하는 kernel level thread를 직접 잡기 위해 복잡한 경합을 벌이는 대신, 우선 중간에 있는 가상 프로세서인 LWP를 잡기 위해 경합하도록 구조를 단순화하기 위해 사용한다. 이러한 기법을 사용하는 핵심 이유는 LWP와 그 밑에 있는 kernel level thread가 1:1로 매핑되어있기 때문이다. 즉 user level thread가 일단 LWP를 성공적으로 붙잡고 나면 하위 kernel thread를 얻기 위해 더이상 추가 경합 없이 바로 연결되어 작업을 수행할 수 있다.
즉 user level thread들이 실제 일감을 처리하는 kernel level thread를 직접 잡기 위해 복잡한 경합을 벌이는 대신, 우선 중간에 있는 가상 프로세서인 LWP를 잡기 위해 경합하도록 구조를 단순화하기 위해 사용한다. 이러한 기법을 사용하는 핵심 이유는 LWP와 그 밑에 있는 kernel level thread가 1:1로 매핑되어있기 때문이다. 즉 user level thread가 일단 LWP를 성공적으로 붙잡고 나면 하위 kernel thread를 얻기 위해 더이상 추가 경합 없이 바로 연결되어 작업을 수행할 수 있다.
Thread Libraries
아래의 내용은 thread library에 관한 case study 내용이다.
✔ Pthreads
- user level에서 동작하는 thread libray
- POSIX API 규격 안에서 제공되며, 스레드의 생성과 동기화에 관련된 다양한 함수 제공
- 운영체제 커널이 아닌 user level 환경에서 library를 통해 스레드의 생성과 관리가 이루어짐
- 대부분의 유닉스 계열 운영체제들이 스레드를 생성하고 관리할때 기본적으로 Pthreads 방식 사용
✔ Windows Threads
- one-to-one 매핑 모델을 지원
- 스레드 ID, 레지스터 셋, 별도로 제공되는 사용자 및 커널 스택, 그리고 트랜잭션 처리 등에 필요한 개별 데이터를 저장할 수 있는 프라이빗 데이터 스토리지 영역을 가짐
- 컨텍스트(Context): 이 중에서 레지스터 셋, 스택, 프라이빗 스토리지 영역 등의 요소들을 묶어서 스레드의 '컨텍스트'라고 부름
✔ Linux Threads
- Linux 환경에서는 thread라는 명칭 대신 task라는 용어 사용
- clone(): 스레드를 생성하는 system call
-> clone()을 통해 생성된 스레드들은 서로 주소 공간을 함께 공유하며 동작한다는 특징이 있음
✔ Java Threads
- 운영체제가 아닌 자바 가상 머신(JVM)이 생성과 관리를 전담
- 생성방법 2가지
- thread 클래스를 확장
- runnable 인터페이스를 구현
Java thread states
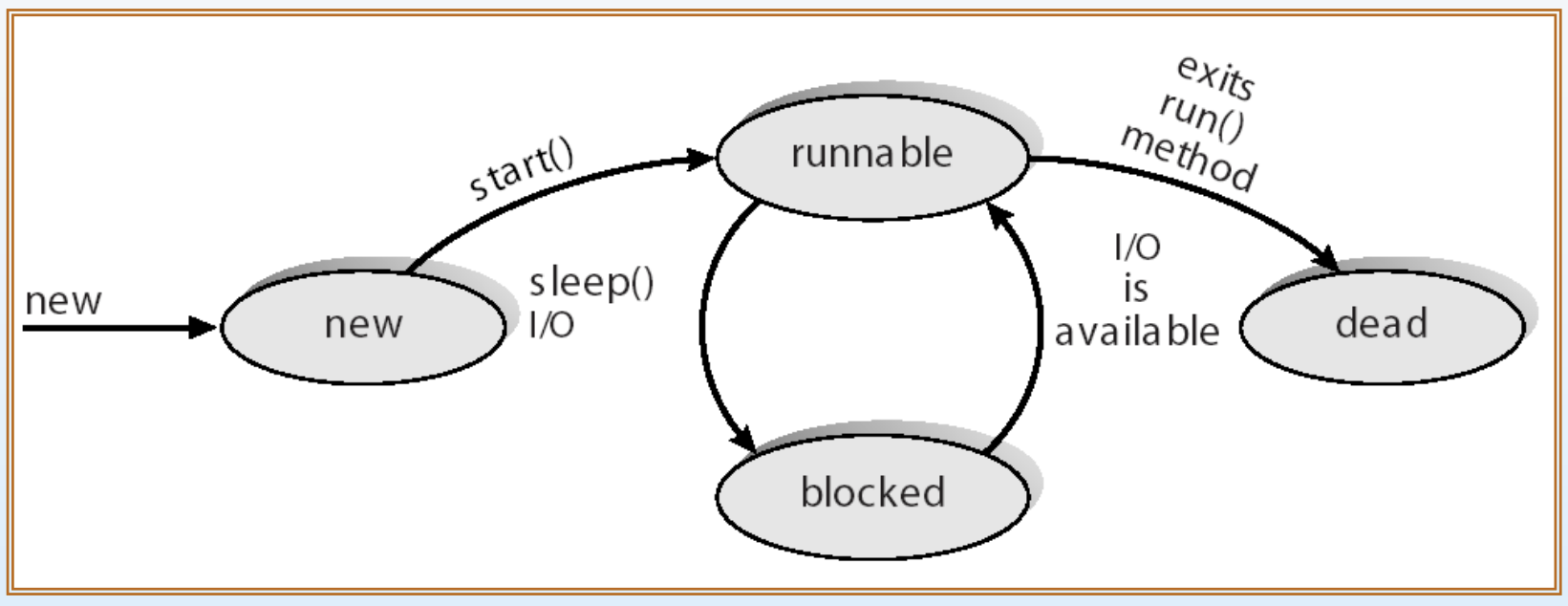
- new: 스레드가 새롭게 만들어져 필요한 자원까지 모두 확보한 상태. 일반적인 프로세스의 상태 중 ready상태와 비슷하다고 볼 수 있음.
- runnable: 스레드가 현재 실제로 CPU를 할당받아 실행되고 있는 상태. 프로세스의 running 상태와 동일한 개념.
- blocked: 스레드가 작업을 진행하다가 특정 조건이나 I/O 작업 등으로 인해 일시적으로 막혀서 기다리고 있는 상태. 프로세스의 waiting 상태와 동일.
- dead: 스레드가 맡은 일 처리를 모두 마치고 정상적으로 완전히 끝난 상태. 프로세스의 terminated 상태와 매칭됨.
