Connection Pool
-
DB에 직접 연결해서 처리하는 경우 Driver를 로드하고 커넥션 객체를 받아와야 하는데 매번 사용자가 요청을 할 때마다 드라이버를 로드하고 커넥션 객체를 생성하여 연결하고 종료하기 때문에 매우 비효율적임
-
이런 문제를 해결하기 위해서 커넥션 풀을 사용
개념
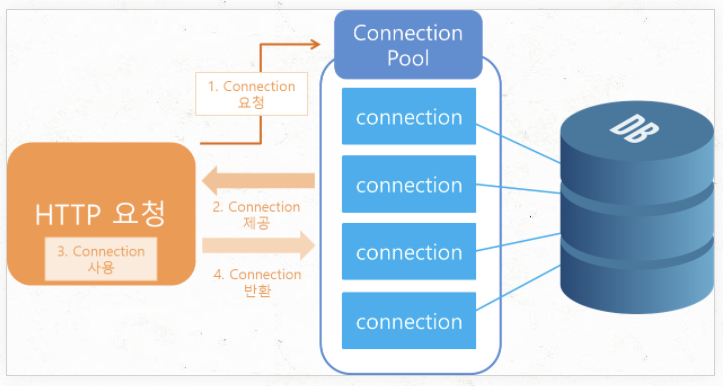
- 웹 컨테이너(WAS)가 실행되면서 일정량의 Connection 객체를 미리 만들어서 pool에 저장했다가, 클라이언트 요청이 오면 Connection 객체를 빌려주고 해당 객체의 임무가 완료되면 다시 Connection 객체를 반납 받아서 pool에 저장하는 프로그래밍 기법
1. Container 구동 시 일정 수의 Connection 객체를 생성
2. 클라이언트의 요청에 의해 애플리케이션이 Connection Pool에서 Connection 객체를 받아와 DBMS 작업을 수행
3. 작업이 끝나면 Connetion Pool에 Connection 객체를 반납
동작 원리
-
Hikari CP가 동작하는 방식
-
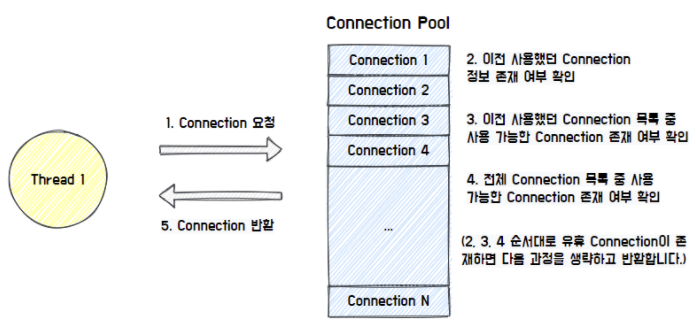
Thread가 Connection을 요청하면 Connection Pool의 각자의 방식에 따라 유휴 Connection을 찾아서 반환
Hikari CP의 경우, 이전에 사용했던 Connection이 존재하는지 확인하고, 이를 우선적으로 반환하는 특징이 있다.
-
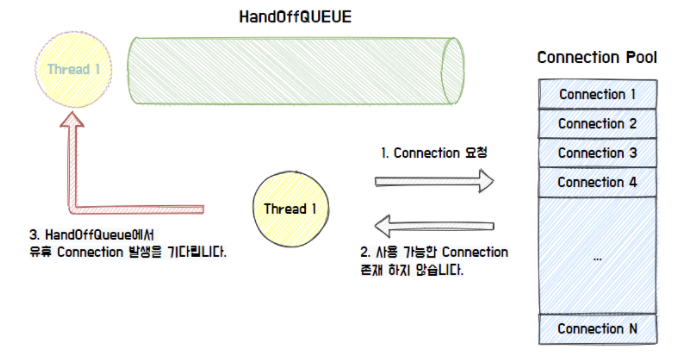
가능한 Connection이 존재하지 않으면, HandOffQueue를 Polling하면서 다른 Thread가 Connection을 반납하기를 기다림
지정한 TimeOut 시간까지 대기하다가 시간이 만료되면 예외를 던진다.
-
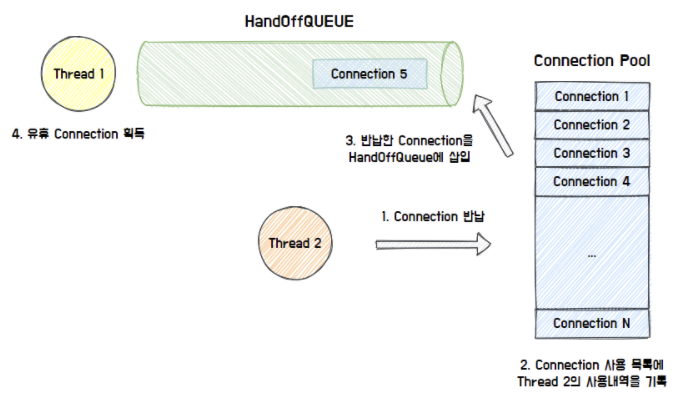
최종적으로 사용한 Connection을 반납하면 Connection Pool이 Connection 사용 내역을 기록하고, HandOffQueue에 반납된 Connection을 삽입
-
이를 통해 HandOffQueue를 Polling하던 Thread는 Connection을 획득하고 작업을 이어나감
장점
-
DB 접속 설정 객체를 미리 만들어 연결하여 메모리 상에 등록해 놓기 때문에 불필요한 작업(커넥션 생성, 삭제)이 사라지므로 클라이언트가 빠르게 DB에 접속이 가능
-
DB Connection 수를 제한할 수 있어서 과도한 접속으로 인한 서버 자원 고갈 방지가 가능
-
DB 접속 모듈을 공통화하여 DB 서버의 환경이 바뀔 경우 쉬운 유지 보수가 가능
-
연결이 끝난 Connection을 재사용함으로써 새로 객체를 만드는 비용을 줄일 수 있음
유의 사항
동시 접속자가 많을 경우
-
너무 많은 DB 접근이 발생할 경우에는 커넥션은 한정되어 있기 때문에 쓸 수 있는 커넥션이 발납될 때까지 기다려야 함
-
너무 많은 커넥션을 생성할 시에는 커넥션 또한 객체이므로 많은 메모리를 차지하게 되고, 프로그램의 성능을 떨어뜨리는 원인이 됨
-
WAS에서 커넥션 풀을 크게 설정하면 메모리 소모가 큰 대신 많은 사용자가 대기 시간이 줄어 들고, 반대로 커넥션 풀을 작게 설정하면 그 만큼 대기 시간이 길어지므로 사용량에 따라 적정량의 커넥션 객체를 생성해 두어야 함
Connection Pool의 크기와 성능의 관계
-
Connection의 주체는 Thread이므로 Thread와 함께 고려해야 함
-
Thread Pool 크기 < Connection Pool 크기
Thread Pool에서 트랜잭션을 처리하는 Thread가 사용하는 Connection 외에 남는 Connection은 실질적으로 메모리 공간만 차지하게 된다. -
Thread Pool 크기와 Connection Pool 모두 크기 증가
- Thread 증가로 인해 더 많은 Context Switching이 발생
- Disk 경합 측면에서 성능 한계가 발생
- 데이터베이스는 하드 디스크 하나 당 하나의 I/O를 처리하므로 블로킹이 발생
- 특정 시점부터는 성능적인 증가가 Disk 병목으로 인해 미비해짐
-
데이터베이스 입자에서 Connection은 Thread와 어느 정도 일치한다고 볼 수 있음
-
Connection이 많다는 의미는 데이터베이스 서버가 Thread를 많이 사용한다는 것을 의미하고, 이에 따라 Context Switching으로 인한 오버헤드가 더 많이 발생하기 때문에 Connection Pool을 아무리 늘리더라도 성능적인 한계가 존재
Connection Pool의 적절한 크기
-
Hikari CP의 공식 문서에 의하면, 1 connections = ((core_count) * 2) + effective_spindle_count)로 정의
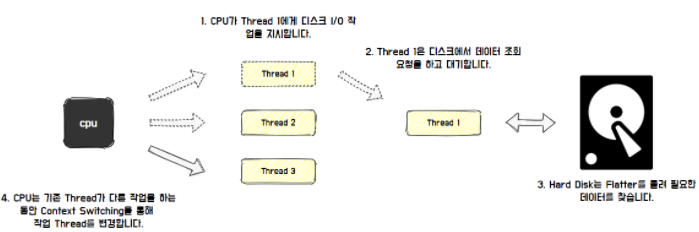
-
core_count는 현재 사용하는 서버 환경에서의 CPU 개수를 의미
- core_count * 2 를 하는 이유는 Context Switching 및 Disk I/O와 관련이 있음
- Context Switching으로 인한 오버헤드를 고려하더라도 데이터베이스에서 Disk I/O(혹은 DRAM이 처리하는 속도)보다 CPU 속도가 월등히 빠름
- Thread가 Disk와 같은 작업에서 블로킹되는 시간에 다른 Thread의 작업을 처리할 수 있는 여유가 생기고, 여유 정도에 따라 멀티 스레드 작업을 수행할 수 있게 됨
- core_count * 2 를 하는 이유는 Context Switching 및 Disk I/O와 관련이 있음
-
effective_spindle_count는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수
- 하드 디스크 하나는 spindle 하나를 갖음
- 디스크가 16개 있는 경우, 시스템은 동시에 16개의 I/O 요청을 처리할 수 있음
Reference
