
본 포스트팅은 인하대학교 컴퓨터공학과 시스템 프로그래밍 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
일반적인 캐시(Cache) 의 개념
-
메모리와 CPU 사이에 존재하며, 수많은 데이터중에서 일부 중요한 몇개의 데이터만 사용하고 싶을떄 캐시에 따로 저장한다.
-
아래 그림을 보듯이 메모리보다 더 크기가 작아서, 소량의 데이터를 저장 가능하다.
-
메모리도 캐시(Cache) 의 기능처럼, 디스크에 있는 대용량의 데이터중 일부 데이터만을 추출해서 저장하는 방식이였다. 즉, 메모리 계층(Memory Hierarchy) 에서 동일한 기능을 수행하는데 저장하는 데이터 용량 사이즈에 차이가 있는 것이다.
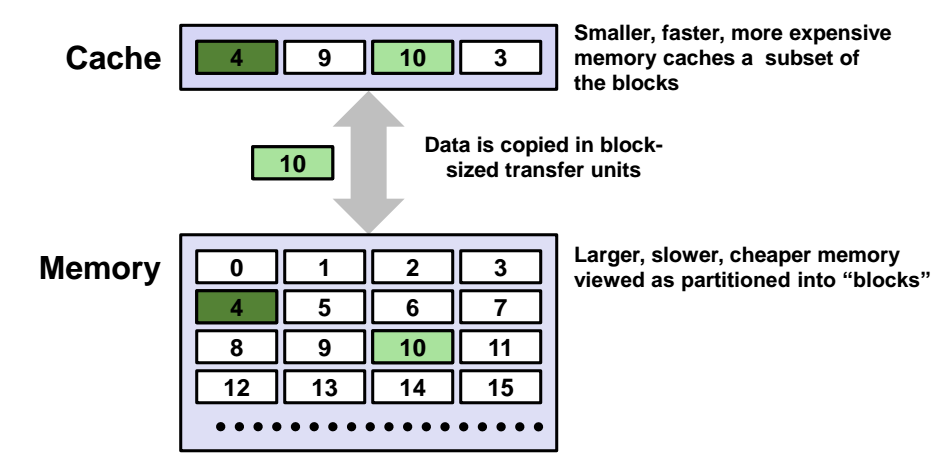
캐시 메모리(Cache Memory)
-
CPU chip 안에있는 Bus interface 란 외부와 소통하게 해주는 녀석으로써, CPU chip 과 외부에 있는 디스크,캐시(Cache) 등과 데이터를 주고 받게 해주었다.
-
Register file 과 Bus interface 사이에 캐시가 존재한다.
즉 CPU 안의 레지스터와 Main memory 사이에서 Bus interface 로 데이터를 주고받을떄 이 중간에서 데이터를 주고받는 녀석이다.
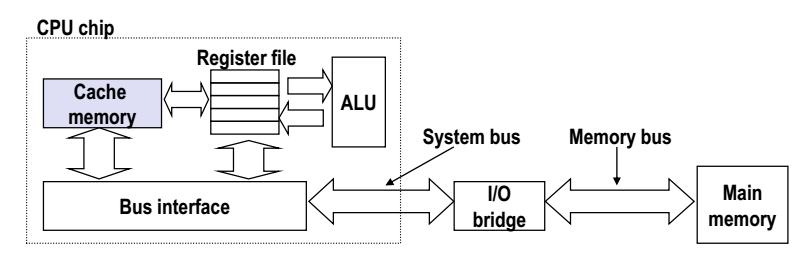
캐시의 구성요소
- line : 캐시의 가장 작은 최소단위 (block 이라고도 부름)
- set : 여러개의 line 이 모여서 생긴 한 줄을 set 이라고 부른다.
- S : 여러개의 set이 모여서 생긴 캐시의 가로크기 (쉽게말해, 몇행인지 크기)
- E : 각 줄안에 몇개의 line 이 있는지 크기 (쉽게말해, 몇열인지 크기)
- 캐시의 전체 크기 : S x E X B ( = 행크기 X 열크기 X 각 line의 Byte 크기)
=> S 와 E 의 크기에 따라서, 즉 캐시의 크기에 따라서 캐시의 종류가 달라진다.
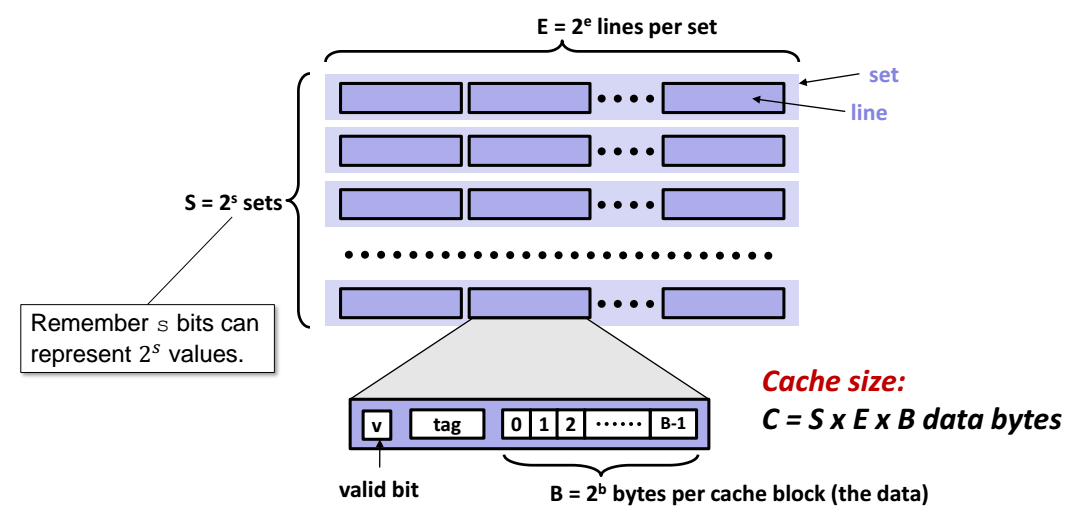
캐시의 최소단위인 line 의 구성성분을 더 자세히보면 아래와 같다.
- 1bit 짜리 valid bit
- tag
- 실제 데이터(meta data)가 들어가는 b 바이트짜리 크기의 영역

캐시의 특정 주소읽어오는 과정
캐시에서 어떤 특정 line 단위의 4byte 를 읽어오는 과정을 알아보자.
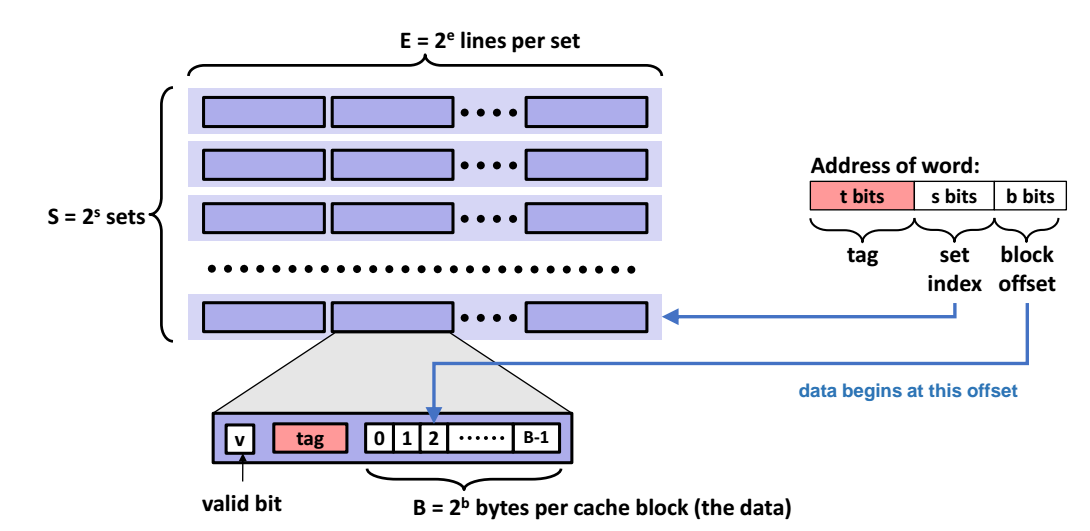
각 line 단위의 주소에 대한 구성성분은 크게 3자기로 tag, set index, block offset이 있다.
-
tag : 캐시의 각 line 단위마다 tag 가 있을텐데, 각 tag 는 각 주소에서 t 비트만큼을 차지하고 해당 line 을 찾는데 사용된다.
-
set index : 캐시의 S개의 행 중에서 몇번째 줄인지, 즉 몇번째 set 인지를 가리킨다.
-
block offset : line 안에서 meta data 를 저장하고 있는 B 바이트짜리 공간안에서 세부적으로 정확히 어떤 데이터를 가리키는지를 저장한다.
=> tag 와 set index 를 통해 몇행 몇열에 있는 line 단위를 접근해야 는지를 알아내고, 해당 line 단위안의 meta data 중에서 몇번째 데이터를 접근해야 하는지를 block offset 을 통해 접근할 수 있다.
(시험 출제!!! 꼭 기억해두자!)
예제 : Direct Mapped Cache
- Direct Mapped Cache 란? : E = 1 인 캐시. 즉, 열이 딱 한개인 캐시
아래와 같이 S개의 set 과 E = 1인 캐시에서 특정 주소에 접근하여 데이터를 얻어오는 과정을 알아보자.
- set offset 을 통해 set offset 에 저장된 값이 000...001 임을 확인하고 2번째 줄의 set 에 접근한다.
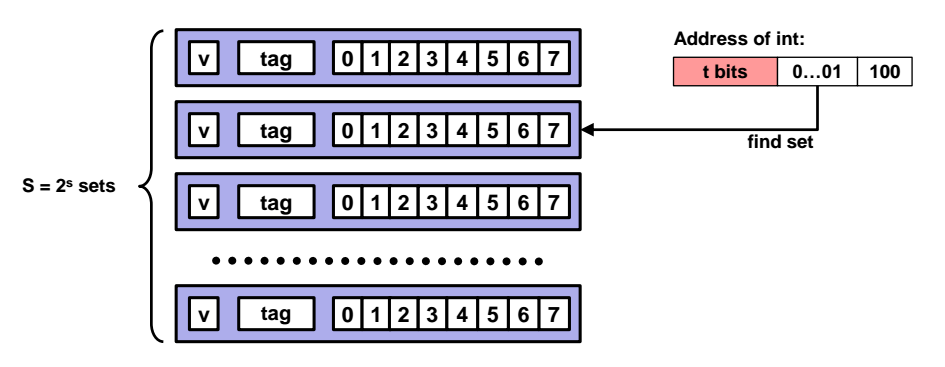
- 다음으로 tag 를 보긴하나, 사실상 tag 를 보는것이 의미가 없다. tag 를 보는 이유는 몇번째 열인지를 얻어내는 것인지, E=1 이기 때문에 열의 개수는 1개이기 떄문이다. 아무튼 tag 값을 확인하고 접근한다.
-
그래도 일단 valid 한지를 valid bit 를 통해 확인하고, tag 값이 안에 해당 line 단위에 저장되어있는 tag 의 값과 매칭되는지(값이 똑같은지)를 판별한다.
즉, 해당 line 단위에 저장된 valid bit 와 tag 값을 추출해내서 검증 과정을 통해 내가 찾으려는 line 단위가 맞는지를 판별하는 과정이다.
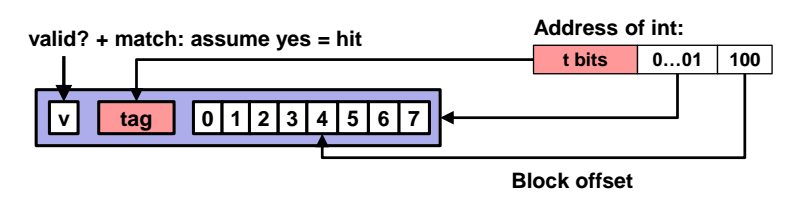
- block offset 에 저장된 값을 통해 meta data 중에서 정확히 원하는 인덱스에 접근한다. 아래처럼 예시의 경우 "100 (2진수)" 값이 저장되어 있는데, 시작주소에서 4 바이트만큼 이동해서 최종적으로 원하는 데이터값이 4를 추출해내는 것이다. 그리고 이 데이터값 4를 리턴하면 끝이다!
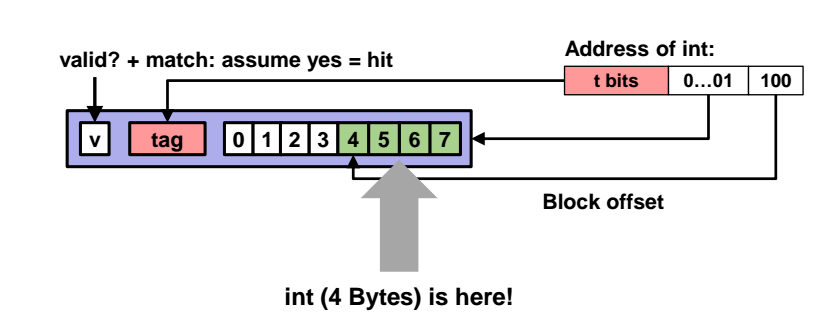
캐시의 메모리 데이터값 교환
캐시는 공간이 작아서 데이터를 적게 보유할 수 있어서 사용했던 공간을 활용해 데이터를 계속 바꿀 수 있어야한다. 그러면 언제 캐시의 특정 공간의 데이터를 바꿀까?
앞선 과정을 통해 데이터를 삽입할 위치를 찾기위해 set 까지 제대로 찾아갔다면, valid bit 와 tag 를 확인할 것이다.
-
이때 tag 값은 정확하지만 valid bit 의 값을 확인했더니 유효하지 않은 값이라고 판별되면 내가 기존에 사용했던 위치인데 오래된 데이터가 저장된 것이다. 그래서 그냥 그 공간에 저장된 오래된 데이터를 새로운 데이터로 덮어씌우면 된다.
-
반대로 valid bit 은 유효하나 tag 값이 불일치한다면, 새롭게 삽입될 데이터의 공간 위치에 다른 사람이 쓰고있는 이미 다른 데이터가 저장되어있는 것이다. 따라서 그 데이터를 어떻게 처리해주고 나의 새로운 데이터를 넣어주면 된다.
예시
-
Cache Hit : 캐시 메모리가 찾는 데이터가 존재했을 때를 나타낸다.
-
Cache Miss : 캐시 메모리에 찾는 데이터가 존재하지 않음을 나태낸다.
=> cache miss 가 발생하면, 메모리 저장소로부터 필요한 데이터를 찾아 캐시 메모리에 로드한다.
메모리(Memory) 로 부터 데이터를 읽어와서 캐시에 저장하는 흐름을 알아보자.
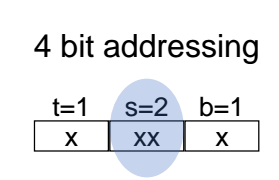
우선 위와 같이 4bit 짜리 공간에다 tag, set offset, block offset 값을 넣어두는 방식이다.
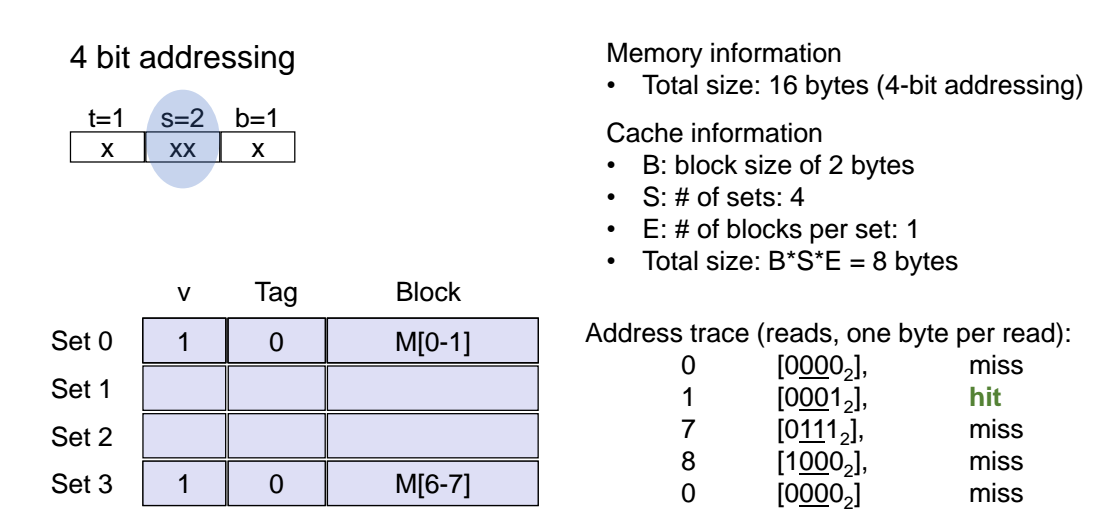
-
0000 이라는 주소를 가지고 read 하고 싶다면, 4자리 숫자 0000 중에서 가운대 2개의 숫자를 가지고 몇번쨰 set 에 접근할 것인지를 판단해주면 된다. 즉, 이 경우는 set offset 값이 00 으로, set 0(첫번째 set)에 접근하면 된다.
-
첫번쨰 set 을 확인해보니 valid bit 의 값이 비어있고, tag 값이 0이다. 즉 valid한(유효한) 상태이며, tag 값이 비어있어서 miss 이다!
(ppt 슬라이드 쇼가 안되서 그런건데, set 0 을 보면 완전히 초기에 빈 상태라고 가정해보자)아무튼 set 0 에다 valid 값을 1을 넣어주고 Tag 값을 0을 넣어준다. 그리고 M[0] 을 넣어준다.
-
0001 에서 가운대 2개의 숫자 00을 을 통해 set 0 에 접근한다. 직전에 set 0 에다가 valid 값에 1을, Tag 값에 0을 넣어줬었다. 이번에는 valid 값이 1인것으로 확인했고, Tag 값도 0으로 동일한 것을 확인했으니, Byte Offset 값이 1이므로 M[1] 에 있는 값을 가져오면 된다.
-
이번에는 set offset 값이 3이므로 set 3 에 접근한다. 그런데 set 3 은 valid bit 과 tag 값이 모두 비어있으므로, 일단 valid bit 에 1을, tag 에 0을 넣어둔다. 그리고 miss 가 발생하긴한다. 그리고 byte offset 값이 1이므로 M[6], M[7] 의 값을 가져온다.
-
1000 을 보면 set offset 값이 0이고, tag 값이 1이고, block offset 값이 0이다. 따라서 set 0 에 접근을 하는데, 기존에 set 0 에 저장되어있떤 tag 값은 0이고 현재 tag 의 값은 1이다. 즉, 두 tag 의 값이 다르다. 따라서 miss 가 되고 tag의 값이 0에서 1로 바뀐다.
-
마지막으로 0000 을 보면 set 0 에 접근을 하는데, 기존 tag의 값은 1이고 현재 tag의 값은 0으로 서로 다르다. 따라서 tag의 값이 0으로 바뀐다.
결과적으로 아래와 같은 캐시 메모리가 생성되었다.
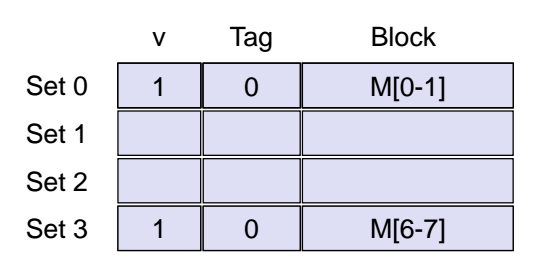
N-way Set Associative Cache
E 가 E = N 일때 N-way Set Associative Cache 라고 부른다.
예를들어 E =2 인 경우 2-way Set Associative Cache 이고,
E = 4 인 경우 2-way Set Associative Cache 라고 부른다.
2-way Set Associative Cache
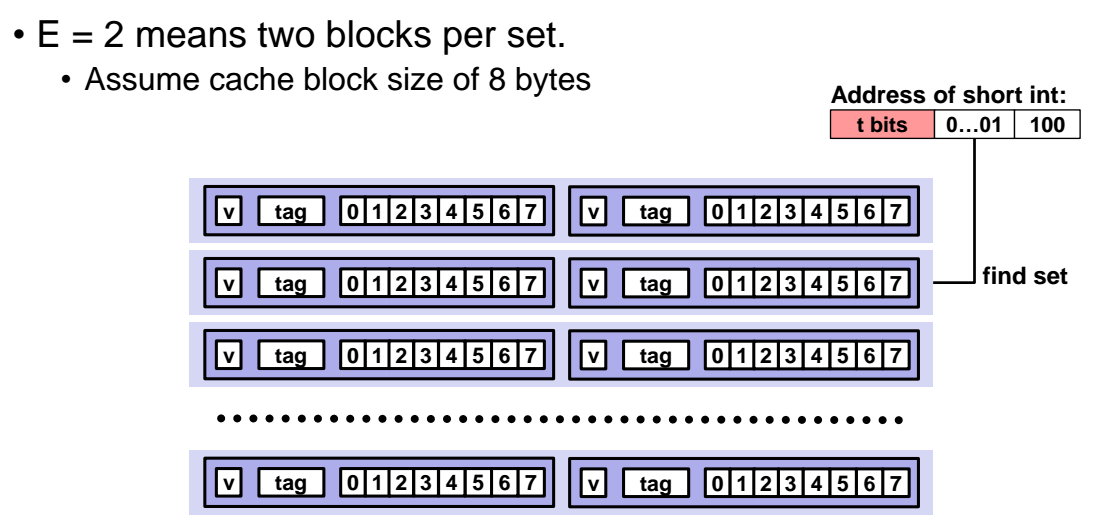
E =2 인 경우에 대해 살펴보자.
set offset 값인 0...01 을 통해 2번째 줄로 왔을떄 2번쨰 줄에는 2개의 line 단위가 존재할 것이다. 이 둘 중에서 어떤 것을 선택해야할지 판별할떄, 각 line 단위에 들어있는 tag 값 2개를 모두 현재 tag 값 0과 비교해봐야한다.
case1) 둘 중 하나가 tag 값이 동일하면서 valid 하다면, 해당 tag 값을 가지는 line 단위가 우리가 찾던 line 단위로 여기서 데이터를 추출하면된다.
case2) 비교해봤더니 두 line 단위 모두 tag 값이 다른경우
=> 또 2가지 경우로 나뉠것이다. 타인이 해당 두 공간을 모두 쓰고있거나, 또는 내가 옛날에 해당 공간을 사용했었는데 오래된 데이터라서 valid bit 값이 0인 경우이다.
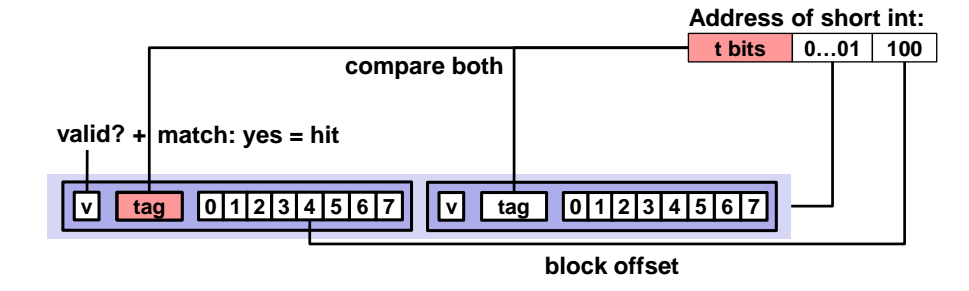
만일 case1에 해당한다면 byte offset 값 가지고 원하는 인덱스에 있는 데이터를 추출해내면 된다.
=> 특정 set offset 을 통해 특정 set 에 접근하고, tag 값이 일치하고 valid 가 유효하다면 hit 이 발생하는데, byte offset 값인 100 (=4) 를 통해, 인덱스 4번째 부터 시작해서 타입이 short int (2byte) 이므로 데이터 2개를 읽어온다.
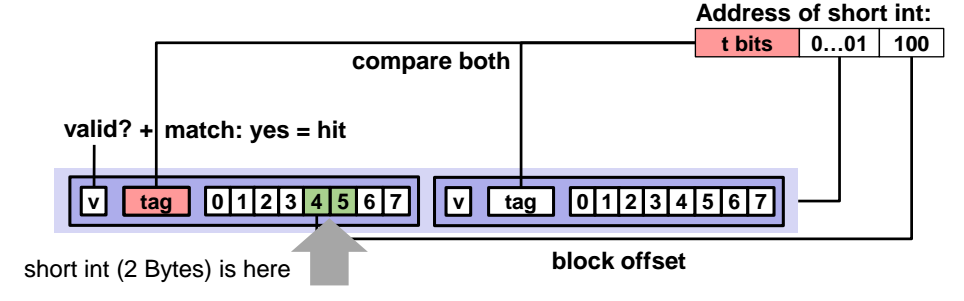
- 만일 valid 한데, 모든 line의 tag 값이 다 다르다면 누군가의 다른 데이터가 차지하고 있다는 뜻이된다. 그럼 두 line 중에서 하나를 골라서 tag 값을 현재 tag 값으로 교체할것이다.
이때 어떤 line 과 교체되어야 하는가? => 둘 중 아무 line 가 교체되는 것이 아니라, 더 자주쓰인 tag 와 교체해준다. (시스템이 자동으로)
예시
아까와 동일하게 주소값이 4bit 인데, 이 중에서 tag 에 2bit 를 할당해줘야한다. 각 set에 들어있는 line 단위가 2개가 되었기 때문이다.
반면 set offset 가 2에서 1bit 로 줄어들었다.

-
0000 : set offset 이 0이고, tag 가 00이다. set 0에 접근했는데 set 0은 모두 다 비어있으므로 miss가 발생한다. 아무튼 set 0에 valid = 1, tag = 00 으로 초기화주고, block offset = 0 이므로 0번째 인덱스부터 시작해서 데이터 2개를 할당해 놓는다.
-
0001 : set offset이 0이고, tag 가 00이다. set 0 접근하는데 직전에 valid = 1, tag = 00 을 저장해놨으므로 hit 이 발생한다.
-
0111 : set offset 이 1이고, tag 가 01이다. set 1에 접근하는데 비어있으므로 valid = 1, tag = 01 로 초기화해준다. 그리고 데이터 2개를 가져다 놓는다.
-
1000 : set offset 이 0 이고, tag 가 10이다. set 1 에 접근하는데 tag = 01 과 매칭되는 tag 값을 가진 것이 존재하지 않으므로 miss 가 발생하면서, set 1 에 새롭게 valid = 1, tag = 10 을 초기화해준다.
-
0000 : set offset 이 0이고, tag 가 00이다. set 0 에서 hit 이 발생한다.
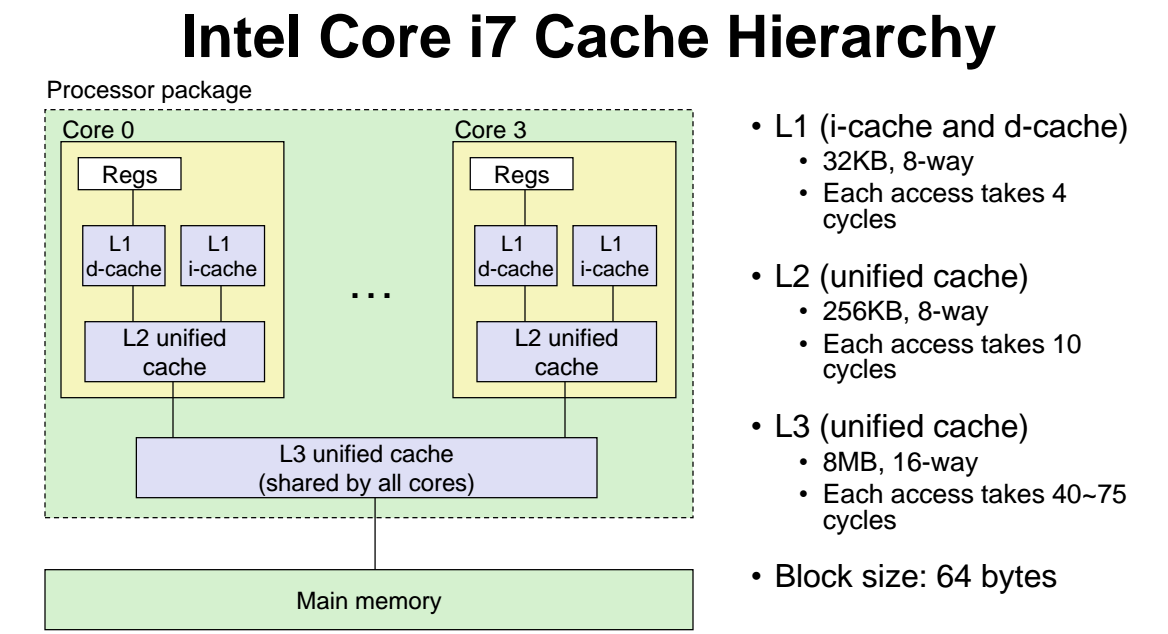
인텔 i7 의 Cache 계층구조
아래처럼 CPU칩 안에 코어가 여러개 존재한다. 각 코어는 자신만의 Register 와 L1, L2, L3 캐시를 보유하고있다. ( CPU 구조마다 다 구성성분이 다른데, 이는 i7 기준이다 )
-
이떄 L1 캐시는 d-cache 는 data cache 로 구분되며, i-cache 는 instruction cache 로써 각각 데이터와 명령어를 저장하고 있다. 즉, 인텔의 CPU 칩 코어는 명령어를 저장하는 캐시와 데이터를 저장하는 캐시가 따로 존재한다.
-
2개의 캐시 i-cache, d-cache 는 L2 unified cache 에 연결되어있다.
-
L2 까지는 각 코어마다 각자 가지고 있는 cache 이다.
그러나 L3 는 CPU 에 있는 모든 코어들이 공유하는 cache 이다, 즉, 각 코어마다 가지고 있는것이 아니다. -
이러한 L3 가 memory 와 직접 통신하는 캐시이다.
Cache 성능분석을 위한 단위
-
Miss Rate
- 전체적으로 메모리를 access 하는 것에 대비하여 데이터 몇개가 캐시에 없어서 메모리에서 가져와야 했는가의 비율
( Fraction of memory references not found in cache) - L1, L2 를 miss rate 이 굉장히 낮다.(3~10%)
- 전체적으로 메모리를 access 하는 것에 대비하여 데이터 몇개가 캐시에 없어서 메모리에서 가져와야 했는가의 비율
-
Hit Time
- 아무 제약없이 바로 hit 해서 데이터를 가져오는데 걸리는 시간.
- 즉 valid 도 딱 알맞고, tag 도 딱 맞아서 한번에 데이터를 가져오는데 걸리는 시간을 의미한다.
=> 또 다시말해, hit time 보다 데이터를 더 빨리가져올 수 없다.
-
Miss Penalty
- 데이터를 못 가져온 경우 L3 까지 가거나 또는 Main memory 까지가서 데이터를 가져오는 경우 꽤나 오랜 시간이 걸린다. 50~200 사이클이나 기다려야함
Hit Rate 에 따른 성능
- hit rate 가 2% 만 높아지더라도, 성능이 2배로 높아진다.
=> hit 발생비율을 어떻게든 조금이라도 높여야 성능이 아주 좋아짐!
