
본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스 SW 개론 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
- Numpy 에서 문제 출제시, BroadCasting 하고 Fancy Indexing 만 시험에 출제하지 좋다!!!!! (by 교수님)
ndarray
- n차원 배열 객체
- 그냥 간단히 array 라고도 부른다.

ndarray 객체 생성하기
-
array(n차원 리스트) : n차원짜리 배열(행렬) 생성
-
arr2.ndim : 해당 배열(행렬)의 차원을 리턴 (2차원 배열일 경우 2를 리턴)
-
np.zeros : 인자값으로 받은 크기를 가지는 0으로 채워진 배열생성
-
np.empty(a, b, c) : a x b x c 짜리의 쓰레기값이 채워진 3차원짜리 배열 생성
-
np.arange(n) : 파이썬의 range() 함수의 numpy 버전이다. 즉, arange(n) 은 0 ~ n-1 사이의 정수 리스트를 생성

ndarray 배열의 타입 관련
-
dtype : array() 로 배열 객체를 생성시 dtype 옵션을 사용하면 배열의 타입을 지정해줄 수 있다.
-
astype : 배열의 타입 바꾸기(casting)
=> dtype 옵션을 활용해서, 다른 배열 객체의 타입을 dtype 으로 가져와서 astype() 의 인자값으로 할당할 수 있다.
dtype 예제
import numpy as np
arr1 = np.array([1,2,3], dtype = np.float64) # float형 배열 생성
arr2 = np.array([1,2,3], dtype = np.int32) # int형 배열 생성
print(arr1.dtype) # dtype('float64')astype 예제
import numpy as np
arr1 = np.array([1,2,3], dtype = np.float64) # float형 배열 생성
arr2 = np.array([1,2,3], dtype = np.int32) # int형 배열 생성
# int형 -> float형
arr = np.array([1,2,3,4,5])
new_arr = arr.astype(np.float64)
# string형 -> float형
new_arr2 = arr = np.array(['1.25', '-9.6', '420'], dtype = np.string_)
print(new_arr2)
# dtype 옵션을 활용해서 배열 타입 변환
new_arr2.astype(new_arr.dtype)
print(new_arr2.dtype)Vectorization 기능
-
numpy 기능중 하나이다.
-
대치연산을 한방에 진행함 => 두 배열끼리 매칭되는 원소들에 대해서 각각 따로 연산을 천천히 진행하는것이 아니라, 빠르게 한방에 연산을 진행해버리는 것
예를들어 아래와 같은 두 배열의 곱셈연산이 일어날떄, 6개의 원소에 대해 각 매칭되는 원소에 대해 곱셈을 총 6번 하는것이 아니라, 그냥 한번에 6번의 연산을 빠르게 진행하는 것

Broadcasting
-
numpy 의 Vectorization 기능 중 하나
-
배열의 크기 및 형태(shape) 가 다른 배열들끼리 연산을 가능하게 해주는 기능
-
크기 및 차원이 작은 배열과, 더 큰 배열간에 연산이 일어날때 크기 및 차원이 작은 배열쪽에서 더 큰 배열쪽에 맞춰서 동일하게 크기와 형태가 변형된다.
=> ex) 1x3 과 4x3 배열간에 연산이 일어날때 1x3 배열이 4x3 배열로 자동 변환되서 연산이 4x3 과 4x3 배열간에 일어나도록 한다,
print(arr * 4)
=> 둘은 배열과 스칼라로써 shape 가 다름에도 불구하고, 연산이 가능하다.import numpy as np
arr = np.random.randn(4, 3) # 4x3 형태의 랜덤값이 채워진 2차원 배열생성
print(arr.mean(0)) # 각 컬럼에 대한 평균을 리턴 => 1x3 형태의 배열객체를 리턴
demeaned = arr - arr.mean(0) # 4x3 배열에서 1x3 배열을 빼는 연산진행
print(demeaned) # => 크기가 다른 배열끼리 연산을 진행했음에도 불구하고, 에러가 발생하지 않고 연산이 진행된다.
# 연산 상세과정
# 1. 1x3 짜리 배열이 4x3 배열로 변환된다.
# => 배열(arr.mean(0)) 에 나머지 빈 행(2행, 3행, 4행) 에 1행에 있는 내용을 싹다 그대로 카피해준다.
# => 예를들어 arr.mean(0) = [1,2,3] 이라면 [[1,2,3], [1,2,3], [1,2,3], [1,2,3]] 이 생성된다.
# 2. 생성된 배열을 가지고 연산 (arr - arr.mean(0)) 을 수행한다.인덱싱과 슬라이싱
- 파이썬과 인덱싱과 슬라이싱과 거의 유사함

파이썬 인덱싱과 슬라이싱과의 "차이점"
-
배열의 특정 부분을 인덱싱 or 슬라이딩했을때 나온 조각은 원본 배열의 view 가 된다.
- view 란? : 데이터가 복사되는 것이 아닌, 해당 데이터가 변경되면 원본 데이터도 똑같이 반영(변경)되는 것
예제

-
원본배열 arr 로부터 부분 배열 arr_slice 를 추출해와서 arr_slice[1] = 12345 와 같이 값을 변경해주면, 원본배열 arr 의 해당 원소의 값(arr[6]) 도 값이 변경된다.
-
arr_slice[:] = 64 => arr_slice 배열의 모든 원소의 값들을 64로 변경
다차원 배열의 인덱싱, 슬라이싱
2차원배열
- 2차원 배열 arr2d 가 있을때, arr2d[3][4] : 3행 4열의 원소를 출력

다차원배열(3차원 이상의 배열)
- 3차원 이상의 다차원배열에서 인덱싱과 슬라이싱을 할때
마지막 인덱스를 생략하는 경우 상위 차원의 데이터를 포함하고 있는 한 차원이 낮은 배열을 리턴하게 된다.
예를들어 아래처럼 2 x 2 x 3 짜리의 3차원배열 arr3d를 선언하고
arr3d[0] 으로 인덱싱을하면 가장 상위차원인 2가 생략되고 2x3 형태의 배열이 출력된다.

예시
- arr3d[0] = 42 : 해당 2x3 배열의 데이터들이 모두 42로 바뀐다.
- arr3d[1, 0] : arr3d[1][0] 과 동일한 기능

슬라이싱과 인덱싱 한꺼번에 함께 쓰기
- 1,2차원 배열에서의 슬라이싱은, 파이썬 슬라이싱과 유사함
print(arr2d)
# 출력 : array([[1,2,3],
[4,5,6],
[7,8,9]])
print(arr2d[:2])
# 출력 : array([1,2,3]
[4,5,6])
arr2d[:2, 1:] = 0
# 출력 : array([[1,0,0],
[4,0,0],
[7,8,9]])Boolean 인덱싱
- Boolean 값으로 인덱싱이 가능하다.
기본셋팅

import numpy as np
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
data = np.random.randn(7, 4)
print(names == 'Bob') # vecotirized 대치연산 (비교연산) => array의 모든 원소들에 대해 'Bob' 문자열과 동일한지를 True 또는 False 로 리턴Boolean 값으로 인덱싱하기
# Boolean 값으로 인덱싱하기
# 배열에 인덱싱으로 Boolean 결과값을 할당 => True 가 있는 인덱스에 대해서만 데이터 조회
print(data[names == 'Bob']) # 이름이 Bob 인 경우에 데이터를 출력
# 슾라이싱 기능도 추가가능
print(data[names == 'Bob', 2: ])!= 연산자를 통해서도 인덱싱 가능
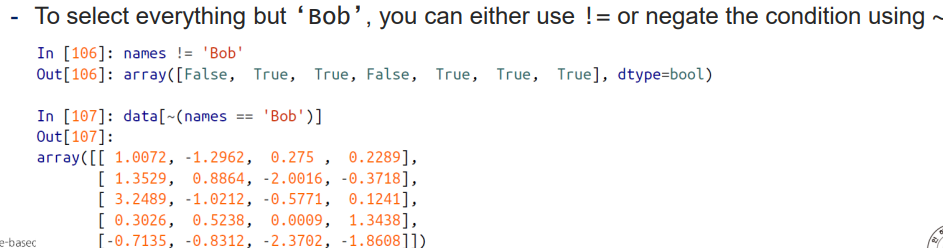
# != 연산자를 통해서도 인덱싱 가능
print(names != 'Bob')
print(data[names != 'Bob']) # Bob 과 다른 경우를 찾아서 인덱싱 가능하다."~" 활용하기

# Boolean 결과값에 "~" 을 붙여서 True 를 False 로, False 를 True 로 변환가능
print(data[~(names == 'Bob')])Boolean 값을 새로운 변수에 대입시켜서 활용가능

# Boolean 값을 새로운 변수에 대입시켜서 활용가능
cond = names == 'Bob' # names == 'Bob' 을 진행한 결과를 cond 리스트에 저장하고
print(data[~cond]) # 리스트에서 활용함. 이름이 Bob 이 아닌 경우에 데이터를 출력AND 나 OR 연산자 등을 활용해서도 다양한 Boolean 연산후 그 결과값을 인덱싱에 활용가능
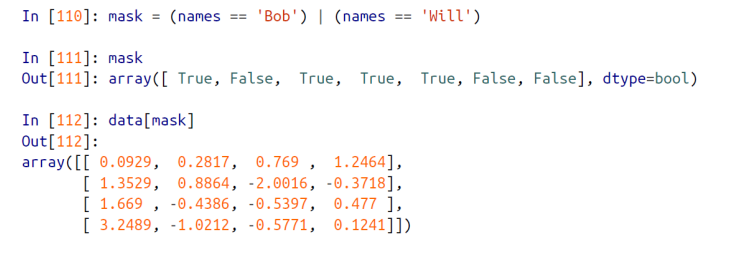
# AND 나 OR 연산자 등을 활용해서도 다양한 Boolean 연산후 그 결과값을 인덱싱에 활용가능
mask = (names == 'Bob') | (names == 'Will')
print(mask)
print(data[mask])조건식의 Boolean 결과값도 인덱싱에 활용가능
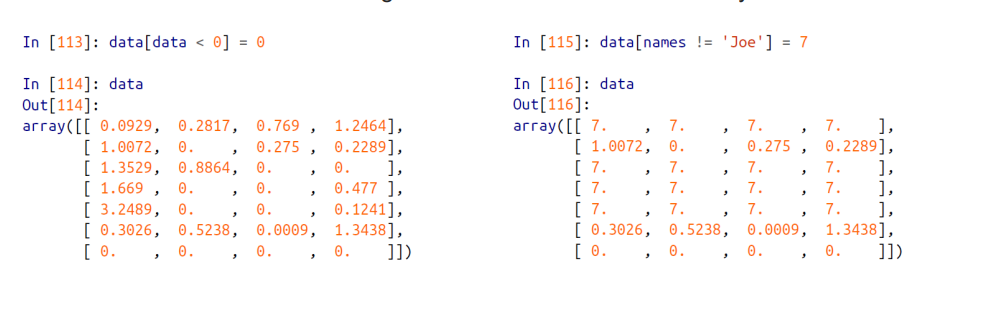
# 조건식의 Boolean 결과값도 인덱싱에 활용가능
data[data < 0] = 0 # 0보다 작은값들에 대해 모두 0으로 바꿈 (= 데이터들 중에 음수인 데이터들을 모두 0으로 바꿈)
data[names != 'Joe'] = 7 # names 가 Joe 가 아닌 인덱스들을 찾아서, 해당 인덱스의 모든 값들을 7로 바꿈Fancy Indexing
Numpy 에서 문제 출제시, BroadCasting 하고 Fancy Indexing 만 시험에 출제하지 좋다!!!!! (by 교수님)
- Fancy Indexing 이란 배열로 인덱싱을 하는것이다.
예를들어 아래처럼 for문을 돌려서 2차원 배열 원소를 채웠다고하자.
i번쨰 행에는 정수 i를 할당하는 방식으로, 8x4 짜리 2차원배열을 생성했다.

Row(행) 조회하기
그러고 아래처럼 Fancy Indexing을 활용해보자.
- arr[[4,3,0,6]] : 4행, 3행, 0행, 6행의 데이터들을 차례대로 출력(인덱싱)하는 것

(i, j) 데이터 조회 : i행 j열의 데이터 조회하기
- arr[[1,5,7,2], [0,3,1,2]] : (1,0)의 값(= 1행 0열의 데이터), (5, 3)의 값, (7, 1)의 값, (2, 2)의 값을 차례대로 출력된다.
=> 그래서 array([4, 23, 29, 10]) 이 출려되는 모습을 볼 수 있다.

특정 row들에 있는 데이터들의 column 순서를 변경시키고 싶은경우
- arr[ [1, 5, 7, 2] ] [ : , [0, 3, 1, 2] ]
=> 분석 : 우선 arr [ [1,5,7,2] ] 부분에서 1행, 5헹, 7행, 2행에 해당하는 행 데이터들을 가져온다. 가져온 각 행에대한 데이터간의 위치를 변환시켜보자. 해당 행 데이터들의 각각의 열의 위치를 변환시키고 싶은경우 " : , [변경시키고 싶은 배열] " 의 형태를 이 뒤에 넣어주면된다.
- 즉 1행, 5행, 7행, 2행의 각 데이터들의 열(column) 배치 순서가 0열-3열-1열-2열 순으로 변한다. 예를들어 5행의 데이터의 경우 20,21,22,23 이 있는데 열의 순서가 변해서 20,23,21,22 가 되는 것이다.

Transpose matrix(전치행렬) 배열로 만들어버리기
- "T" 속성 ex) arr.T => 배열 arr이 3x5였다면 5x3으로 변함
- np.dot() : 배열(행렬)들간의 곱셈연산을 진행

transpose() : 다차원 배열을 Transponse 하기
- 2x2x4 짜리 3차원 배열 arr에 대해 arr.transponse(1,0,2) 를 하면 0번쨰 축과 1번째 축을 바꿔준 것이다. 즉 전치(transpose)한 것이다.

swapaxes() : transpose 메소드와 마찬가지로 축을 바꿔줌
- 차이점 : tranpose() 는 해당 차원에 해당하는 모든 축을 튜플(tuple) 로 넣어줘야하지만, swapaxes() 는 축 변환을 원하는 2개의 인자만 넣어주면 된다.
아래 예제의 경우 2x2x4 배열에서 2와 4 부분의 축을 변경시켜주는 것이다. 그래서 2x4x2 형태의 배열이 출력된다.

Universal Functions
-
배열의 각각의 원소를 빠르게 처리해줄 수 있는 함수
-
줄여서 ufunc 라고도 부름
-
ndarray 배열 객체 안에있는 데이터를 원소별로 연산을 진행한다.
-
하나의 스칼라값을 인자로 받아서, 그 스칼라값을 배열의 모든 원소에 연동을 시켜서 한번에 대치연산을 진행한다.
-
이에 해당하는 함수는 Unary, Binary ufuncs 등이 있다.
Unary 함수 : sqrt() , exp( )
1개의 인자를 받아서 element-wise 연산을 수행하는 Universal 함수
- sqrt, exp 함수가 이에해당
- sqrt( arr ) : 배열 arr의 모든 원소에 루트값을 적용
- exp( arr ) : 배열 arr의 모든 원소에 지수함수를 적용. 예로 원소 1에 대해 exp 가 적용될떄 e^1 가 적용된다.
(이때 e = 2.71....)

Binary ufuncs
2개의 인자를 받는 Universal 함수
- 이에 해당하는 함수로 add( ), maximum( ), modf( ) 등이 있다.
np.maximum(x, y) : 배열 x와 y를 각 원소를 비교하고 더 큰값을 새로운 배열에 추가
아래 예제의 경우, 첫번째 원소를 보면 0.8626 이 -0.0119 보다 더 크므로 0.8636 이 추가된다. 이렇게 0번쨰 인덱스, 1번쨰 인덱스, .... 에 해당하는 데이터들을 비교하고 더 큰값을 가지고 새로운 배열을 구성한다.

modf(x) : 배열 x의 각 원소에 대해 정수부분과 소수부분 리턴

옵션 out (argument 옵션)
- universal 함수에는 out 이라는 옵션이 있다.
- out 이라는 argument 에 연산의 결과값을 저장할 수 있다.
- out 을 사용하려면 2개의 인자를 받아야한다.
- np.sqrt(arr, arr) : 첫번쨰 배열 arr 인자에 sqrt 를 적용한 결과를 2번쨰 인자값 배열 arr 에 적용하라는 의미
- 만일 그냥 np.sqrt(arr) 은 원본 arr 은 변하지 않고 루트를 씌운 배열 객체 결과가 출력된다.
- 그러나 이 경우는 np.sqrt(arr) 의 결과를 2번째 인자인 arr 에 저장하라는 의미가되서, arr 를 출력했을때 np.sqrt(arr) 이 적용된 결과가 출력된다.
=> 즉 arr 에 np.sqrt(arr) 를 할당하는 것과 동일하다.

Linear Algebra
- np.dot(arr1, arr2) : 두 행렬(배열)의 곱 또는 벡터의 내적을 리턴
- np.matmul(arr1, arr2) : 두 행렬의 곱을 리턴

numpy.linalg 모듈
다양한 선형대수 함수를 보유하고 있는 모듈
inv : 역행렬 구하는 함수
- int(matrix1) : 행렬 matrix1 의 역행렬을 리턴
qr : qr분해를 해주는 함수
- qr(matrix1) : 행렬 matrix1을 q 행렬과 r 행렬로 분해시켜줌

numpy.random 모듈
-
numpy 에서 난수를 생성해주는 모듈
-
그냥 단순하게 난수를 추출하는 기능에 이어서, 확률분포를 기반으로해서 랜덤값을 추출해주는게 가능하다.
-
np.random.normal(size=(4,4)) : 4x4 형태의 행렬(배열)을 정규분포로 랜덤값을 출력해준다.

- np.random.seed(1234) : 시드값으로 1234 을 부여.
=> numpy 는 시드값에 따라서 다른 랜덤값이 출력된다.

- np.random.RandomState(1234) : 랜덤값의 경우는 보통 global 변수(전역변수)로 사용하는데, global 변수를 피하고 싶은 경우는 이 함수를 사용하면 된다. 지역변수로 사용됨
