본 포스트팅은 인하대학교 컴퓨터공학과 시스템 프로그래밍 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Performance impact of cache
캐시의 성능을 아래 Maxtix Multiplication 예제를 보면서 분석해보자.
Matrix Multiplication

nxn 짜리 정사각형 행렬 2개를 곱하는 상황이다. 3중 for 문을 돌리는데, 내부에서 반복문을 돌리는 순서를 바꾸는 것이다. 순서에 따라 어떻게 성능이 달라지는지 살펴보자.
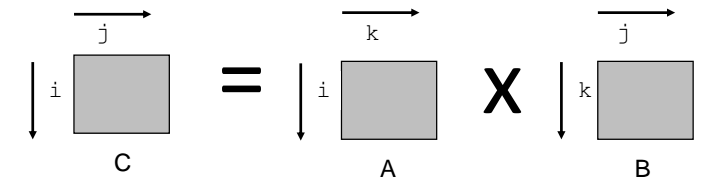
변수 k 쪽에서 inner product (내부 곱) 을 진행한다.

우리는 다음과 상황을 상황을 가정한다.
-
캐시의 line Block 의 사이즈는 32 바이트이다. 즉 8바이트 짜리인 double 이 4개가 있는 것이다. 즉 캐시에 4개밖에 못들어간다.
-
행렬의 차원 n은 엄청나게 크다고 가정한다.
-
캐시가 아무리 크더라도 행렬 곱 결과의 row 를 완전히 못담는다.
( = miss 가 무조건 발생한다)
=> 이러한 상황일때 miss 가 얼마나 발생하는지 miss rate 를 살펴보자.

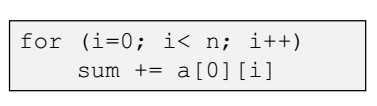
-
행렬의 데이터 저장방식은 row-major 순서로 저장한다. 즉 첫번쨰 row 를 저장하고, 그 다음 2번쨰 row 를 저장하고, 3번째 row 를 저장하고, ... 이런 방식으로 row 를 중심으로 순차적으로 데이터를 저장한다는 의미이다.
위와 같은 반복문을 사용하면 row-major 방식으로 저장하게 된다.
=> 이 방식이, 즉 row-major 방식으로 저장했다는 것이 캐시의 성능을 결정한다.
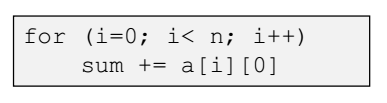
- 반면 column major 방식은 위와 같은 반복문으로 이루어질 것이다.
위와 같은 방식을 다시 보면, row-major 방식은 각 row 에서 가로 방향으로 column 들을 쭉 이어가는 것이다. 반면 column-major 방식은 세로 방향으로 이어가는 것이다.
가로로 이어가는 방식(row-major) 는 앞서 가정한 것에 따라서, 캐시가 행렬 nxn 에서 n보다 작다. row 를 한줄한줄 읽어갈때마다 한번 캐시에 담아오는데 miss 가 발생한다.
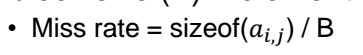
캐시를 line Block 사이즈 B 만큼 읽어왔는데 n보다 작기떄문에 그 중 한번 무조건 miss 가 난다.
반면 세로로 이어가는 방식(column-major) 무조건 miss rate 이 1이다.
1. Matrix Muptiplication : ijk
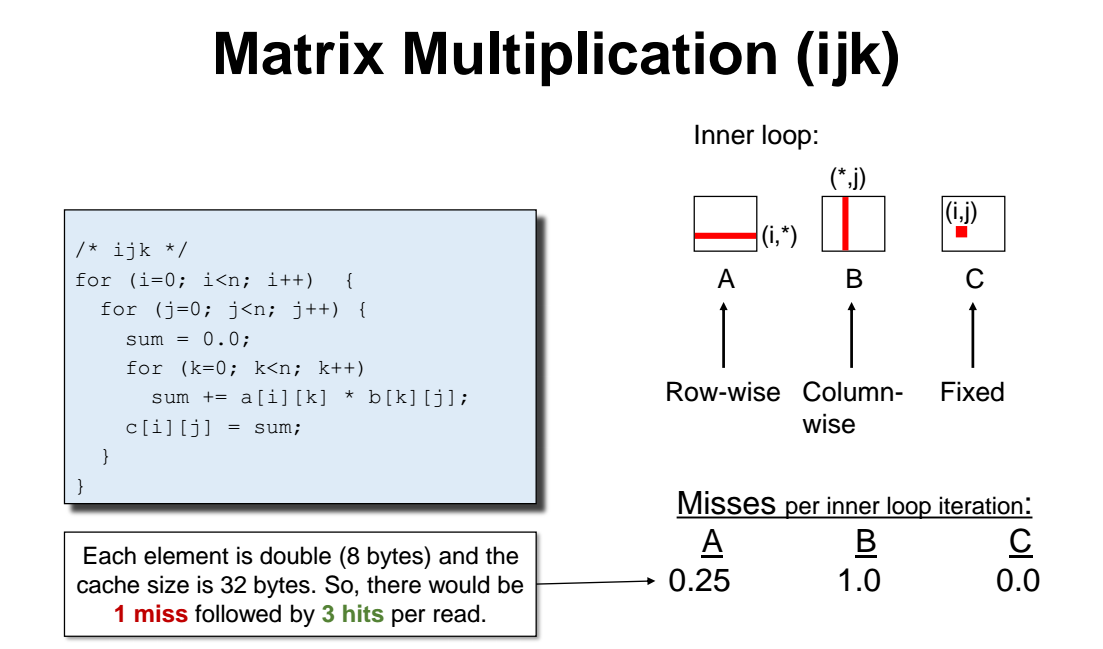
A와 B를 곱해서 결과 C 를 도출한다. 행렬의 곱을 생각하보면 (선형대수때 배운거) A의 한 row 줄과 B의 한 column 줄을 읽어오면서 각 element 에 대해 inner product (곱셈) 을 하면 행렬의 (i, j) 좌표에 들어갈 결과가 나온다.
앞서 설명했듯이, 데이터를 row-major 방식으로 저장해놨기 떄문에 캐시에서 한줄(row)를 읽어왔을때 miss 한번이 나오고, 그 외에는 모두 hit 이 발생할 것이다.
=> 이 과정을 모든 줄(row) 에 대해 한줄한줄 반복한다.
=> 그런데 아까 block size 가 double 형 4개가 들어갔다고 했었다. 이 4개중에 1개에 대해서 miss 가 발생하고, 나머지 3개에 대해 hit 이 발생하는것이다. 따라서 miss rate 은 1/4 (= 0.25) 인것이다.
2. jik
- 이번엔 ijk 가 아닌 jik 로 순서를 변경해보자.
즉 i와 j를 바꿨는데, row를 먼저하는가 column 먼저하는가에 상관없이 똑같은 miss rate 이 발생할것이다. (성능에 차이가 없다)

2. kij
이번엔 k를 가장 앞으로 두었다.
이러면 A를 고정시켜두고, B와 C를 하나하나씩 읽어오는 것이다.
=> 아웃풋(결과값) 자체는 변함없으나, 반복문의 순환 순서를 바꾼것이다.
- B는 row-major 방식으로 데이터를 access하므로 miss rate 이 1/4 이된다.
C도 마찬가지이다.
=> 아웃풋은 동일한데, 반복문의 순환 순서를 바꿔줬더니 성능이 4배 좋아졌다. (miss rate 이 하나가 1/4 로 줄어들었기 때문)

ikj
- 직전꺼랑 달라진것 없음. B 먼저 하냐 C 먼저 하냐의 차이임.

눈치가 빠르다면 알겠지만, for문 바깥의 2개는 중요하지 않다. 맨 안의 inner product 가 성능을 결정한다.
jki
row-major 구도로 저장해놓고 column-major 방식으로 접근한다. miss rate 이 엄청 올라감. A, C 양쪽다 hit 을 단 한번도 못한다.

kji
위와 동일한 원리

Matrix Multiplication 요약
- 직접 돌아갈 가장 끝에있는 dimension 이 캐시의 locality 를 활용할 수 있어야한다.

- blocking 이라는 것에 대해 알아보자. 앞서 살펴본 row-major 보다 miss rate 이 훨씬 줄어드는 방법이다.

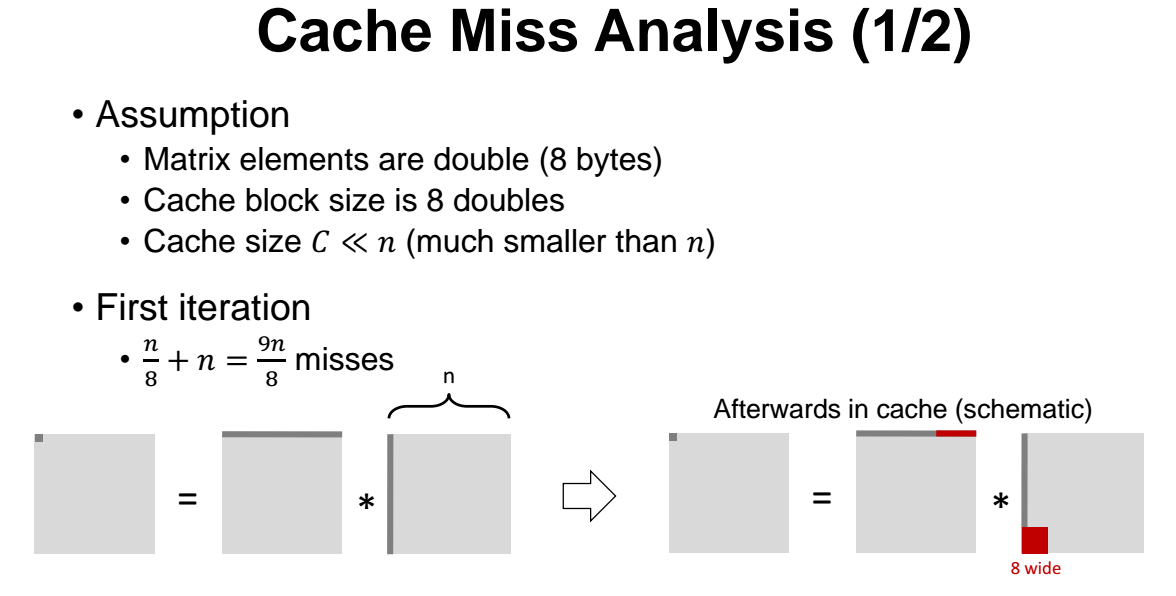
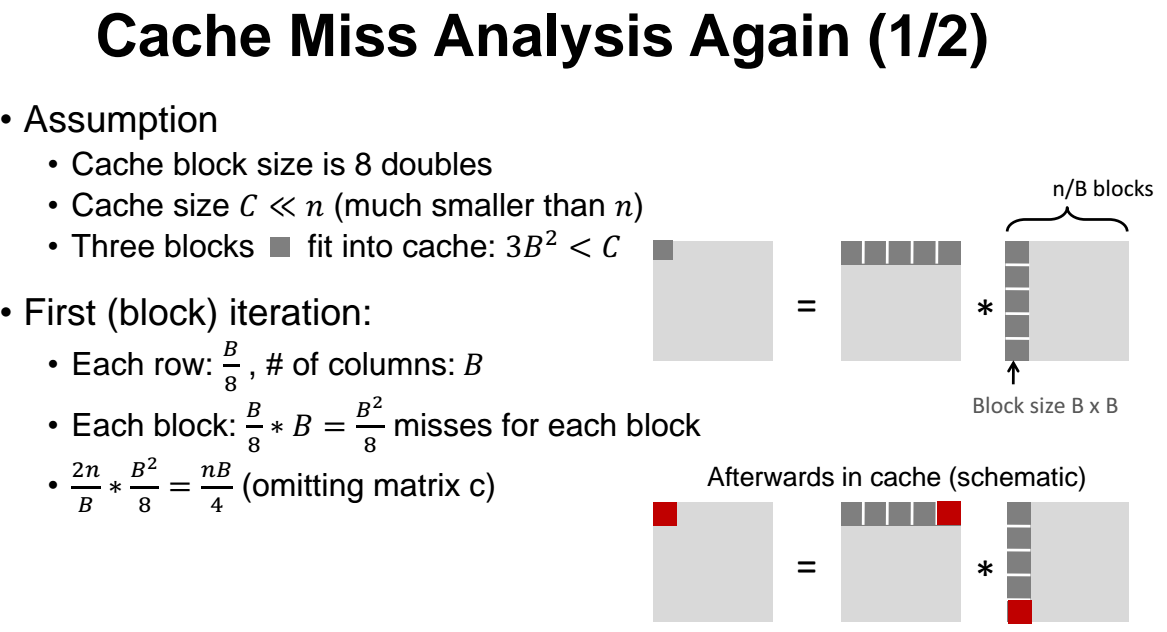
- 우리는 아래처럼 조건들을 가정한다.
1) element 들은 double 타입이다.
2) 캐시의 block size 는 8 이다.
3) 캐시의 사이즈는 n 보다 훨씬작다.
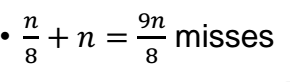
캐시에서 데이터를 8개씩 읽어넣는다. 그래서 여기서 miss 개수는 n/8 이다. 나머지 7번은 모두 hit 가 발생할 것이기 떄문이다.
아무튼 8개를 읽어와서 miss 한번 해주고 나머지는 모두 hit 되는것이다.
따라서 총 miss 의 개수는 n/8 이고, 그리고 두번째꺼는 세로로 읽어오므로 miss rate 이 1 x n = n 이다. 따라서 총 miss 개수는 9/8 x n 이 된다.
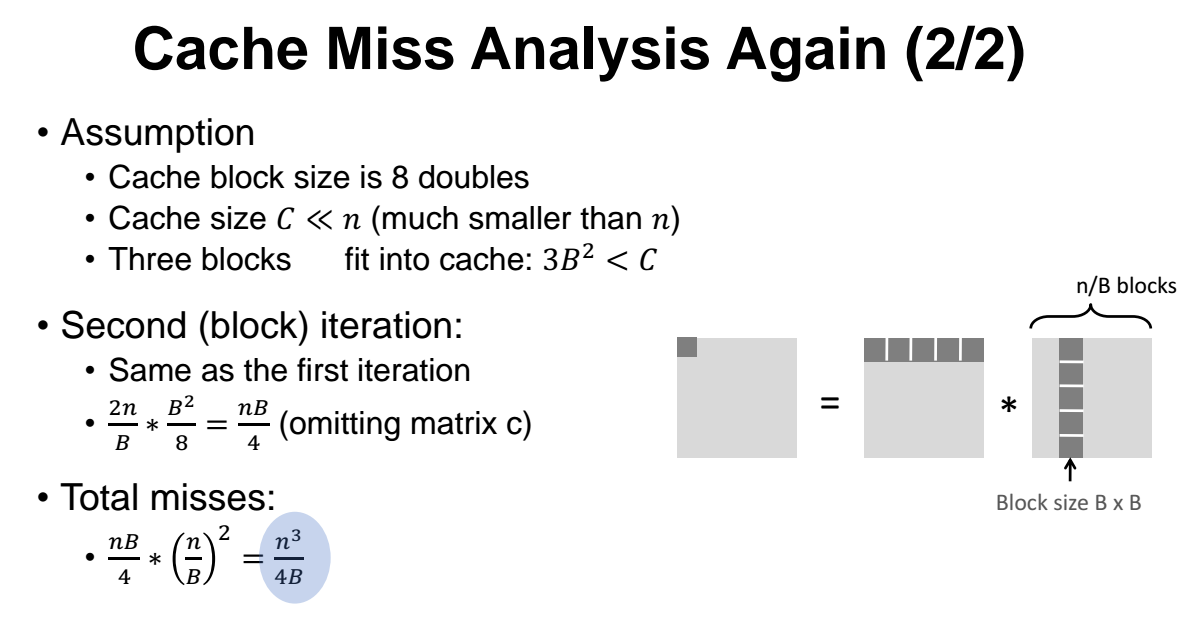
A 와 B 에서 (C는 제외) 나오는 총 miss 개수는
( 9/8 x n ) x n^2 = 9/8 x n^3 이 된다.
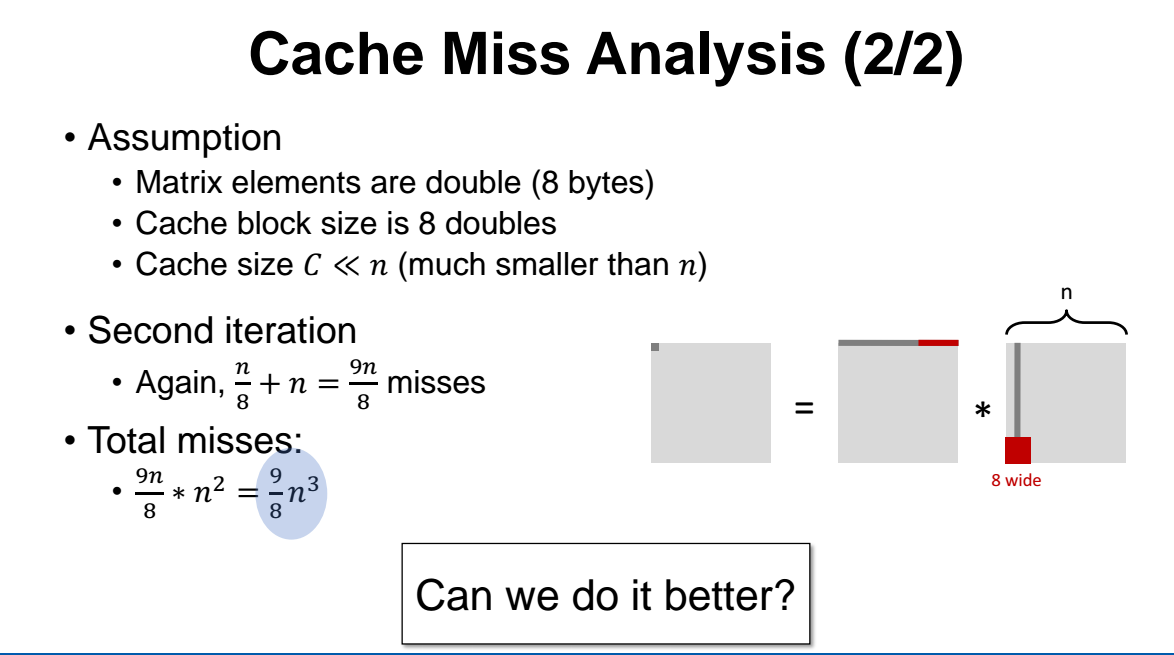
그런데 이것보다 성능을 더 개선할 수 있을까?
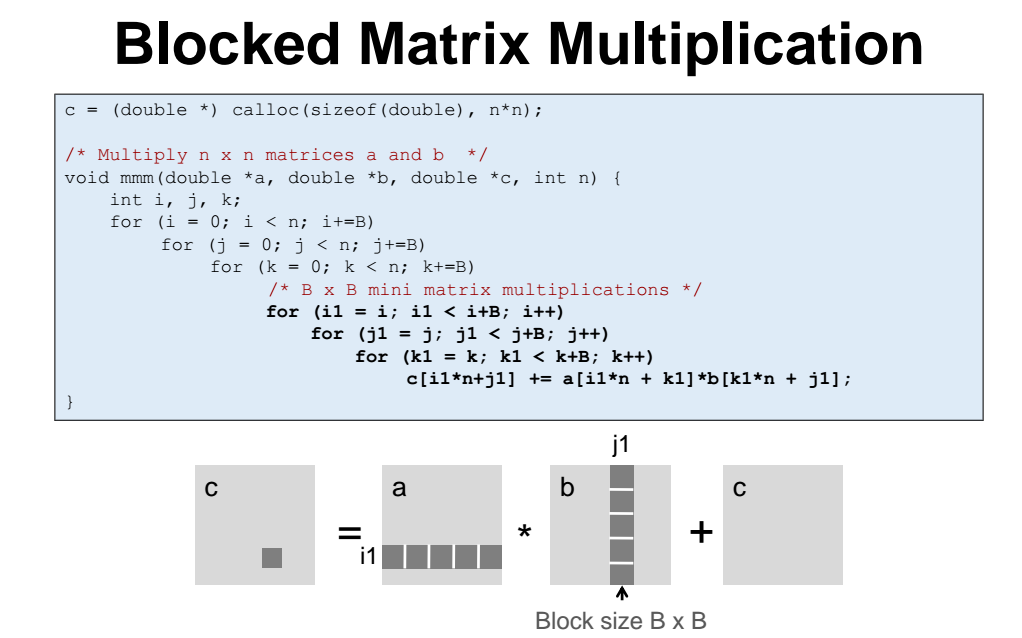
Blocked Matrix Multiplication
아래처럼 blocking 하면 된다.