본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스 SW 개론 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Array-Oriented Programming
- 반복문없이 배열 자체에서 단 한방에 연산을 시켜주는 vectorization 연산
ex) sqrt(x^2 + y^2) 구하기 : 수많은 배열 데이터에 대해 각각 x^2 + y^2 에 루트를 씌운값을 단한번에 구하기
-
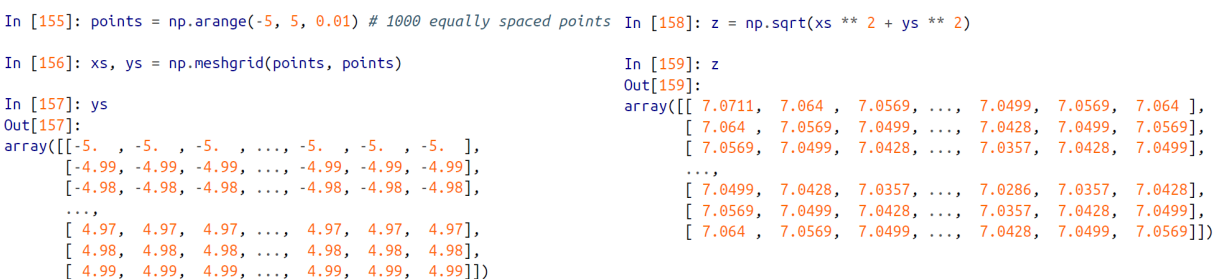
points = np.arange(-5, 5, 0.01) : points 라는 변수로 -5 ~ 5범위에서 0.01의 간격으로 값을 1000개 저장
-
xs, ys = np,meshgrid(points, points) : 앞서구한 points 변수에 담긴 1000개의 값에 대한 쌍을 구함. 즉 1000x1000 형태의 쌍이 나오고, 각 쌍을 xs 와 ys 에 넣어준다.
- 그러면 1000x1000 형식의 포인트가 각각 xs 와 ys 에 들어가게된다.
-
xs 에는 ys 가 transpose 된 결과가 들어가있다.
-
z = np.sqrt(xs ** 2 + ys ** 2) : sqrt 함수를 이런식으로 배열을 다 적용하면 x^2 + y^2 에 루트를 씌운값을 단 한번에 연산을 적용해서 구할수 있다.
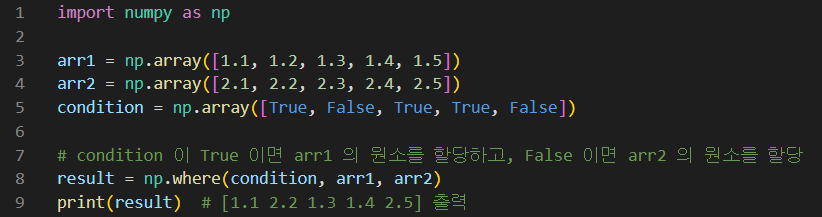
np.where()
- where() 함수를 이용하면 if-else 문을 단 한줄로 표현가능하다.
- 형태 : result = np.where(조건, arr1, arr2)
예시1
예시2
- arr 를 순환하며 해당 원소가 양수인(0보다 큰) 경우 2로 설정해주고, 음수이면 그대로 냅둔다.
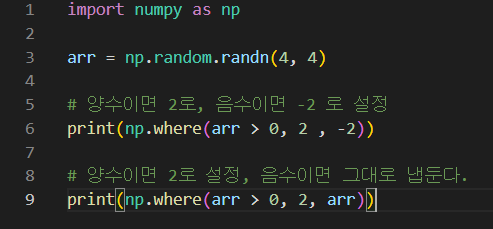
결과
수학&통계 관련함수
np.mean(arr) 또는 arr.mean() : 배열의 평균
- np.mean(arr) : 배열 arr 에 대한 평균을 구함

- axis 옵션
- arr.mean(axis = 1) : 각 행에 대한 평균을 구함
- arr.mean(axis = 0) : 각 컬럼(열)에 대한 평균을 구함

np.sum(arr) 또는 arr.sum() : 배열의 합계
- axis 옵션
- arr.sum(axis = 1) : 각 행에 대한 합계을 구함
- arr.sum(axis = 0) : 각 컬럼(열)에 대한 합계을 구함

arr.cursum() : 배열의 누적합
1차원배열인 경우 : 한 인덱스씩 넘어갈때마다 누적해서 해당 인덱스에 더해줌
ex) 아래처럼 0열에는 0열값, 1열에는 0열+1열값, 2열에는 0열+1열+2열값,... 으로 누적되는 방식

arr.cumprod : 배열의 누적곱
- cursum 과 cumprod 둘 다 마찬가지로 axis 옵션에 할당된 값이 0인가, 1인가에 따라서 각 행의 누적곱 or 각 열의 누적곱을 구할 수 있다.

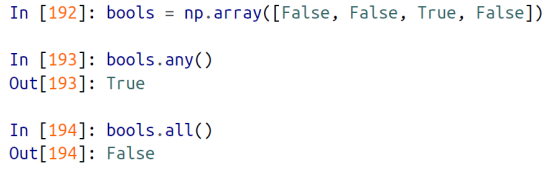
Boolean 타입의 배열을 위한 함수들
- any() : True가 배열에 단 한개라도 있으면 True 를 리턴
- all() : 배열의 모든 원소가 True 이여야 True 를 리턴함. 그게 아니면 False 리턴
Sort 함수
- arr.sort( ) : 오름차순 정렬

- arr.sort(1) : axis = 1 로 설정한것. 즉, row(행)에 대해 정렬을 한다.
- arr.sort(0) : 컬럼(열)에 대해 정렬을 한다.

np.unique(arr) : 중복제거
np.unique(arr) :중복을 제거하고 유일하게 한 값만 남긴다.
- unique 함수는 기본적으로 sort 함수의 기능도 포함하고 있다. 즉 중복을 모두 제거한 후 남은 원소들에 대해 오름차순한 결과를 리턴한다.

np.in1d()
- 특정 membership 에 해당하는 값들이 존재하는지 여부를 파악하는 함수

2, 3, 6이라는 맴버가 values 라는 배열에 존재하면 True 를, 아니면 False 를 출력
=> 그래서 보듯이, 2 3 6 에만 해당하는 값에만 True 가 할당된 모습을 볼 수 있다.
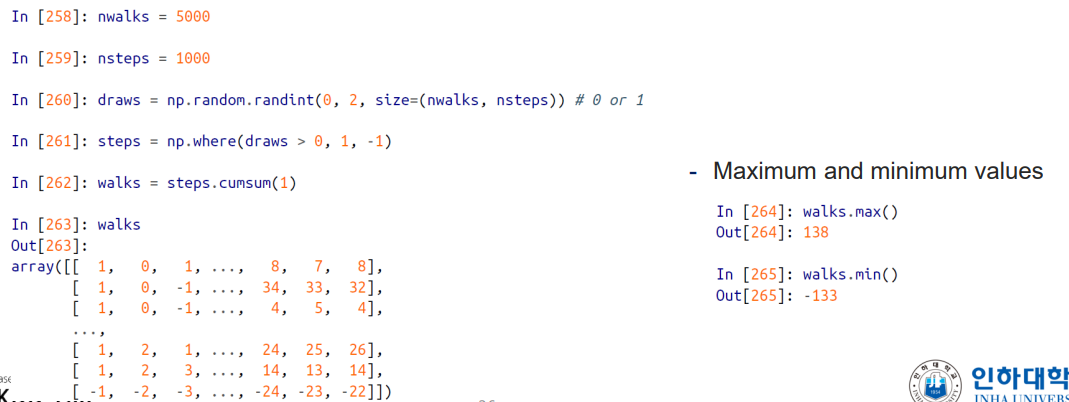
Random Walk
1 또는 -1 중에서 택해서 1000번을 출력함
-
draws = np.random.randint(0, 2, size=nsteps)
=> 0과 1값을 1000번 출력해서 drwas 배열에 저장 -
steps = np.where(draws > 0, 1 , -1)
=> draws 배열의 원소의 값이 0또는 1이므로, draws > 0 이라는 조건문을 통해서 현재 draws 배열에서 조회하는 원소의 값이 1이면 1을 출력하고, 0이면 -1이 출력하도록 함
=> 결과적으로 steps 배열은 1과 -1로 이루어진 1000개의 값을 가지는 1차원 배열이 된다.
- walk = steps.cumsum() : 이러한 1차원 배열에 cumsum 을 하면 계속 올라갔다 내려갔다 하는것이 walk 배열에 누적이 된다.

argmax()
- 누적합 부분에 대해서 통계적인 처리도 가능하다.
ex) np.abs(walk) >= 10 : 첫 지점으로부터 10칸 이동한 지점을 모두 찾고 싶을때, 즉 위로 10칸 또는 아래로 10칸을 간 경우를 찾고 싶은 경우로 walk 배열을 abs() 함수를 통해서 절댓값으로 변환해주고, 해당 절댓값들이 10보다 큰 경우를 다 찾아주면 된다.
다 찾고나서 argmax() 함수를 적용하면 10보다 큰 경우만 True 로, 아닌경우는 False 를 출력하게 된다. 그래서 맨처음에 나오는 10보다 큰 경우를 출력할 수가 있게되어서, 결국엔 맨 처음에 10번쨰 위치로 도달한 인덱스가 출력된다.

=> 즉 argmax() 를 통해 처음으로 10보다 큰 인덱스 위치값을 출력할 수 있다.
결과값이 37이라는 것은 곧 37번째 걸음을 걸을때 맨처음 위치에서 10 만큼 떨어진 곳에 발을 내딛었다는 것을 알 수 있게된다.