운영체제 : 운영체제의 등장배경

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂

-
OS 란 컴퓨터 머신과 다양한 애플리케이션 프로그램 사이의 인터페이스 역할을하는 소프트웨어이다.
-
OS 의 역할은 실행중인 다양한 프로그램들에게 시스템 리소스를 동적으로 분배해주는 역할이다.
- 이때 시스템 리소스란, 메모리, CPU, 다양한 I/O 디바이스등이 해당한다. 이들에 대한 관리와 스캐줄링하는 것이 메인 기능이다.
- 메모리, CPU, 다양한 I/O 디바이스 들이 동일한 공유자원을 건들 수 있으므로 동기화 작업이 필요하다.
-
또한 편리함과 효율적인 자원관리가 OS의 기본 목표이다. 또한 OS 라는것은 다양한 이유로 진화하는데, 어떤 새로운 시스템이 들어왔을 떄 다른 서비스의 어떠한 방해도 없이 개발할 수 있고, 추가할 수 있는 설계구조를 지원해야한다.

OS 의 역할은 크게 2가지로 나뉜다.
- 유저 인터페이스로써의 OS
- 자원 관리자로써의 OS
유저 인터페이스로써의 OS
OS 라는 것은 당연히 multi program 을 지원하기 위해서 편리한 인터페이스를 제공해야한다. 유저의 입장에서 봤을 때 컴퓨터 시스템의 내부구조는 추상화 되어있어야 한다. 즉, 유저가 OS 라는것이 어떻게 구성되어 있는지를 잘 몰라도, 편리한 인터페이스가 제공되기 때문에 카톡, 네이버, 구글링등 기능을 편하게 사용할 수 있는것이다.
그러나 개발자 입장에서는 라이브러리 API 라는것을 알고있다. ABI 수준까지 깊게 알고있어야한다. ABI 란 바이너리 수준의 OS 인터페이스이다. 예를들어서 우리가 소스코드로 프로그래밍하고 컴파일해서 실행할때 같은 x86 이지만, 윈도우에서 실행되던 것이 리눅스에서는 실행되지 않을것이다. 컴파일러가 바이러니 수준에서 호환시켜줘야 가능한것이다.
자원 관리자로써의 OS
컴퓨터라는 것은 리소스(CPU, 메모리, I/O 디바이스, bus) 의 집합인데, CPU 에서 프로그램이 돌다가 메모리에 접근할 필요가 있다. 또 Bus 를 타고 메인 메모리에서 데이터를 가져오는 플로우이다. 이런 과정을 효율적으로 관리하는게 바로 OS 라는 것이다.
OS 는 프로세서에게 현 프로그램을 실행하다가 다른 프로그램을 수행하도록 지시할 수 있고, 또는 리소스에 대한 사용도 지시할 수 있다. 이렇게 OS 가 리소스에 대한 관리를 관장하는 역할을 수행한다.

OS 가 계속 진화하는 원인은 3가지가 있다.
-
새로운 하드웨어 타입의 계속되는 등장 => 자원을 관리하는 리소스 매니저의 역할이 있는데, 하드웨어가 바뀜에 따라 새로운 리소스가 들어오던지, 기존의 리소스가 빠질 수도 있는것이다. 이에 대응하기 위해 OS 가 진화한다.
-
새로운 서비스들의 계속되는 등장 => 여러 애플리케이션에서 공통적으로 했던 작업을 OS 영역으로 집어넣을 수 있다.
-
벼그, 오류 => OS 에서 발생하는 버그, 오류등으로 인해 진화해야한다.

OS 진화의 역사를 알아보자. 옛날에는 하드웨어가 완전 비싼 고가의 자원이였다. 이 당대의 목표는 System utilization 을 최대한 높이는 것 이었다. 즉 특정 시간동안에 자원(특히 CPU) 을 몇 퍼센트 활용했는지에 대한 것이다.
시간이 지남에따라 하드웨어의 속도가 빨라지고 가격이 많이 저렴해졌다. 이떄는 처리량, 즉 단위시간 당 처리되는 작업의 수 가 중요해졌다. 또한 반환시간이 중요해졌다. 즉 사람이 컴퓨터에게 요청하고나서 응답을 반환받는데까지 걸리는 시간이 짧아야한다.

우선 첫번쨰는 Serial Processing (순차 처리) 시기이다. 순차 처리라는 것은 말그대로 모든 activity 가 순차적으로 이루어지던 시기다.
그 당시 컴퓨터의 CPU 는 진공관이고, 메모리는 마그네틱 코어이다. 또 그 당시 애니악 컴퓨터의 가격은 50만불로, 현대 시대의 가격으로 따졌을때 700만불이다. 그만큼 국가의 소중한 자산이였고, utilization(활용률) 을 반드시 높여야했고, 이게 그 당시의 큰 관건이였다.
그러나 이 당시에는 OS 라는 것이 존재하지 않았고, 인간이 직접 하드웨어를 관리해야했다. 하드웨어에게 요청하면 결과를 OS 가 처리하고 받는것이 아닌, 인간이 직접 받고 관리해야했다. 이러한 과정이 순차적으로 이어졌다는 것이다.
- job to job transition : job (프로그램) 과 job 사이에 전환이 굉장히 수동적이고 인간이 직접 개입하던 시기였다.
인간이 직접 하다보니, 공통적으로 필요한 것들에 대한 처리(컴파일, 디버그 등) 가 필요해졌다. 그를위해 등장한것이 바로 라이브러리이다.

이러한 순차적 처리에 대한 문제점이 2가지가 있다.
-
Setup Time : 디바이스들간의 상호작용, 즉 job to job transition 을 인간이 직접 개입했기 때문에 처리 시간(setup time) 이 굉장히 오래걸렸다.
-
scheduling time : 국가적인 비싼 자원을 사용하려면 인증을 받고 사용해야한다. 그래서 컴퓨터를 사용하려는 사람들에게 각각 사용 시간 할당량을 부여했다. 이렇게 시간을 스캐쥴링 했다는 것이다. 이 방식의 문제점은 A 라는 사람이 컴퓨터를 가지고 작업을 실행하다가 원하는 결과가 본인이 부여받은 시간내로 안나오면 컷 당하고 다시 와야하는 번거로움이 있었다. 이로인해 낭비되고 시간이 많았다.
=> 이러한 문제를 극복하도록 OS 가 등장했다.

앞선 문제들을 극복하도록 OS 가 등장했다. 초기 컴퓨터는 매우 비쌌기 때문에, processor utilization (프로세스 활용률) 을 최대화 시키는 것이 중요해졌다. 앞서 살펴봤던 scheduling 이나 setup time 으로 인해 낭비되는 시간이 발생하게 되었다.
그러니 이 시대의 목표는 아래와 같이 나올 수밖에 없었다.
- Simple Batch System : 비슷한 job 들을 묶는것이다. 그러면 중복되는 작업을 또 하는 상황을 방지할 수 있으니 setup time 을 줄일 수 있게된다. 즉, 성격이 비슷한 작업들을 한 묶음으로 모아두고 일괄적으로 처리한다는 것이다.
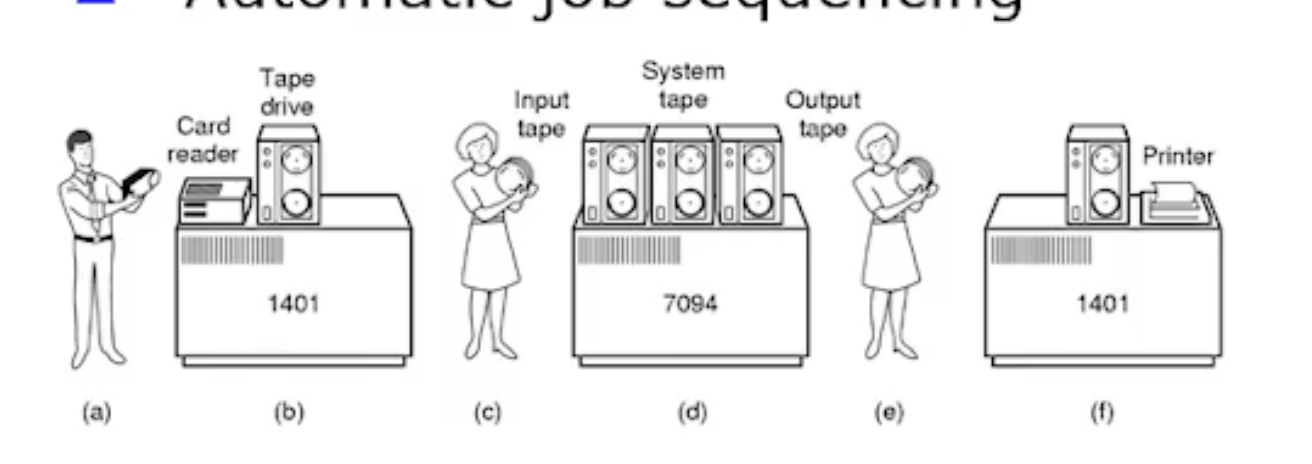
위 그림은 이 시기에 해당하는 IBM 컴퓨터 모습이다. 일괄 처리를 위해 프로그램 정보를 담고있는 card 를 인간이 입력하면 해당 프로그램이 컴퓨터에 전달되어야한다. 그를 위해 우선 입력된 card 에 기반하여 프로그램이 batching (묶음화) 된다. Tape Drive 를 가지고 7094 가 처리를 한다. 즉 1401 과 별개의 I/O 시스템 이라는것이다.
=> 이렇세 setup time 도 줄이고, 이 작업들을 자동화해서 job to job transition 을 없애자는 것이 목표가 된다.

이 시기에 만든 최초의 OS 의 이름을 IBSYS 라고 지었다.
또 이때의 OS 를 batch OS (또는 batch monitor) 라고 부른다. 일괄처리하는 OS, 즉 job 에 대한 자동화를 수행하는 OS 라는것이다.
또한 초기의 OS 를 만들다보니 2가지 특징이 필요했다.
- OS 라는 것이 job to job transition 을 없애고 job 들을 관리하는 새로운 프로그램이지 않은가? 이 프로그램은 항상 메모리에 있어야지 다른 job 들을 꺼내오고 관리할것이다. 이러한 것에대해 필요성을 인식한 시기이다. 정리하자면
OS, 즉 monitor 가 항상 메모리에 머물러있어야 한다는 것이다.그래서 Resident monitor 라는 용어도 쓰이는것이다.

- 그리고 메모리는 OS 영역과 애플리케이션 영역으로 분리되어야한다. 커널이, 즉 monitor 가 메모리에 있다가 tape 로 부터 자원을 하나 읽고, 그 프로그램을 읽어서 user program area 에 집어넣는것이다. 즉 메모리에 로딩을 한 것이다. 그러고 Control 이 유저한테 넘어가면 거기서부터 쭉 job 이 실행되는것이다. 그리고 작업이 끝나면 다시 Controller 이 monitor 한테 와야한다. monitor 가 자동화를 위해 또 다음 작업을 transition 해야하기 때문이다. 그리고 그 결과는 printer 같은 디바이스에 나오게된다.

이떄 이런 job 을 sequencing 하려면, 자동화하기 위해서 별도의 뛰어난 job control 을 위한 language 가 필요하다. 그게 바로 JCL(job control langauge) 이다. 예를들어 bash shell script 를 보면 자동화하는데 많이 사용되며, 다양한 명령어들을 쭉 나열해서 순서대로 수행하도록 하는것이다. 이러한 bash 처럼 그 당시에 job 들의 호출 순서를 정의하기 위한 JCL 이 필요했다.
또한 job 를 읽어오려면 당연히 디바이스에 접근할 수 있는 디바이스 드라이버 같은 것들이 필요했다. 또 이 당시에 초기 형태의 interrput 를 지원한다. 그래서 interrput processing 하기위한 기능들로 구성되어있었다.

이렇게 Serial Processing 에서 job to job transition 을 없애기위헤서 batching system, 즉 일괄 처리의 필요성을 느끼고 automatic job sequencing (자동화) 를 지원하는 monitor 가 등장했었다. 그러나 여기서도 해결해야할 문제점이 발생했다.
-
메모리 보호 : 유저들이 접근하면 안되는 메모리 영역에 접근하게 되면서 crash 가 발생하는 등의 메모리 측면의 문제가 발생한다. 아무튼 monitor 의 대부분은 메인 메모리에 있는데 유저 프로그램이 실행할 때 그 monitor 에 포함되는 영역을 유저가 건들면 안된다. 만약에 건들면 예외가 발생한다.
-
I/O Proection : I/O 디바이스들을 망가뜨리는 사례도 많다. 예를들어 아무 card 마음대로 접근해서 다른 job 들을 읽어버리는 등의 문제가 발생한다. I/O 디바이스들은 유저 레밸에서 직접적으로 접근하지말고, 커널한테 요청하는 것이다. 즉 만약 유저 프로그램이 I/O 를 쓰고 싶다면 직접적으로 접근하지 못하고, 커널을 통해 요청을 날려야한다. 요청을 날린것을 monitor가, 즉 운영체제가 처리하고 결과를 반환하는 방식의 필요성을 이 당시에 느꼈다.
-
dual mode : 듀얼 모드, 즉 2개의 모드가 필요하다는 것을 느끼게된다. 커널 모드와 유저 모드로 구분짓는것이다. 유저 모드일때는 메모리나 I/O 에 대한 접근이 일부 제한되도록한다.

-
CPU Protection : 그 당시 유저 프로그램을 수행하다보면 무한 루프를 돌때가있다. 이러면 특정 CPU 가 자원을 계속 독점할 수 있는것이다. 여기서말하는 CPU Protection 이란 보호하자는 것이 아니라, 독점을 막자는 것이다. 독점을 하는것인지를 알려면 특정 CPU 의 자원 사용률을 계산해야한다. (계산을했을때 사용률이 엄청 크다면 독점하는 것이다) 이를 위해 시스템 타이머가 필요해진 것이다. 그래서 CPU 들의 자원 사용률 최대치 limit 를 정해놓고, 그 값을 넘어서면 중단시키는 등의 기법이 필요해진것이다. 또 시스템 타이머도 유저가 접근하면 안된다. 만약 유저들이 시스템 타이머를 접근할 수 있다면 특정 유저가 시스템 타이머를 조작해서 자원을 독점할 수 있기 때문이다. 따라서 이 또한 커널모드로 커널만이 자원에 접근 가능하도록 해야한다.
-
interrput : 당연히 시스템 타이머라는것이 외부 디바이스에서 들어오면 초기 수준에 대한 interrput 메커니즘을 지원해야한다. 아래처럼 프로그램 A 를 수행하다가 interrput 가 발생하면 interrput 핸들러에서 커널로 가는것이다. 그 다음에는 자원을 독점하는지 판단하도록 자원 사용률을 계산하고, 타임아웃(시간이 오바 되었는지)을 체크해야한다.
아래 그림을 다시 정리해보자면, 카운팅할 변수를 하나 만든다. 예를들어 여기서는 cnt 라고 하겠다. 이 cnt 변수는 특정 유저가 자원을 독점하는 상황을 방지하도록 타임아웃을 체크하는것이다. 아무튼 프로그램 A 를 실행하면서 계속 cnt 변수값을 증가시킨다. 그러다 cnt 값이 10 이상으로 너무 커지면 독점하고 있다고 판단해서 (time out ) kernal 로 넘어가고 적절히 조치를 취하는것이다. 이 당시에는 이런식으로 시스템 타이머가 동작했다.


또한 I/O Controller 의 필요성을 느끼게 되었다. 그 당시에는 CPU 가 I/O 디바이스에 직접 접근해서, 또는 Polling I/O 하다보니까 utilitzation (이용률)이 굉장히 떨어졌다. 따라서 interrput 가 필요해졌다. interrput 를 지원한다는 것은 CPU 를 대신해서 Controller 가 프로세서도 가지고, 레지스터도 가지고, 버퍼도 가져서, 어떤 CPU 가 요청이 오면 디바이스에 대해 처리하고, 완료되면 interrput 를 발생하는 것이였다. 그 시간동안에 CPU 는 다른 유용한 작업을 하러 갈 수 있는것이다. 이런식으로 I/O Controller 가 진화했다.
Controller 를 이용하게 되면서 CPU 는 기다리지 않고 다른 작업을 동시에 할 수 있다고 했었다. 여기서 깊이 한번 따져볼 차례이다. C++ 과 같은 프로그램 코드에서 (1) 변수 a 가 있고 (2) if문 안에 변수 a값에 따라서 실행되는 것이 코드 부분이 있을때, (1) 과 (2) 는 상호의존적이다. 즉 (1) 이 실행되어야지 (2) 가 정상 수행될 수 있는 순차적인 플로우로, (2)는 (1) 에 의존적이다.
디스크에 변수 a가 있을텐데, 이 데이터가 read 되어야지 그 다음 단계인 if 문을 수행할 수 있다. 즉 의존적이다. 반면 의존적이지 않은 코드도 나올수있다. 예를들어서 print 문이 2개가 있을때, 서로에게 영향을 미치지 않고 의존적이지도 않다.
이렇게 CPU 가 처리하다가, 디바이스가 처리하는 결과까지 CPU 가 기다려야 할 필요성이 있는 상황이 있을수있고, 반대로 필요없는 상황도 있다.
- synchornous I/O : 실행결과가 file I/O 가 끝날때까지 기다려야하는 상황을 synchornous I/O 라고한다. 즉 CPU 가 디바이스의 I/O 결과에 의존적인 상황이다.
- Asynchornous I/O : 반대로 의존적이지 않은 상황이다.
=> 상황을 요약해보면, I/O 종류에 따라서, 즉 어떤 I/O 가 오는가에 따라서 (프로그램 의존성에 따라서) 현대 시대와 같은 multi programming 없는 시절에 synchornous 문제가 발생한다.
이를 해결하기 위해 multi programming 을 지원하도록한다. CPU 가 현 프로그램이 synchornous 문제로 인해서 바로 실행시키지 못하고 기다려야 하는 상황에 놓이게되면, CPU 가 그를 계속 기다리면서 놀고있는것이 아니라 다른 프로그램 수행하러 가는것이다.


앞서 말했듯이 simple batch system 에서는 synchornous I/O 상황에서 CPU 가 놀게되면 utilization 이 떨어진다. 따라서 CPU utilization 을 높이기위해, CPU 가 다른 프로세스(job) 들을 수행할 수 있도록 한다.
아직 수행중인 (완료되지 않은, 즉 active 상태의) 여러개의 프로세스(jo) 들을 메모리에 올려놓고, 디스크에서 데이터를 꺼내와야 진도를 가는것이 가능한 경우라면 다른 프로세스에게 그 작업을 떠넘기는것이다. synchornous I/O 도 overlapping 해서 병행적으로 사용할 수 있다.
- job 스캐줄링 : job1 이 중단됐다면 job2 한테 줄지, 아니면 job3 한테 줄지 선택사항이 발생한다. job2 할지 job3 는 어떤 정책에 의해 바뀔수있다. 그게 현대적인 의미의 CPU 스캐줄링이된다.
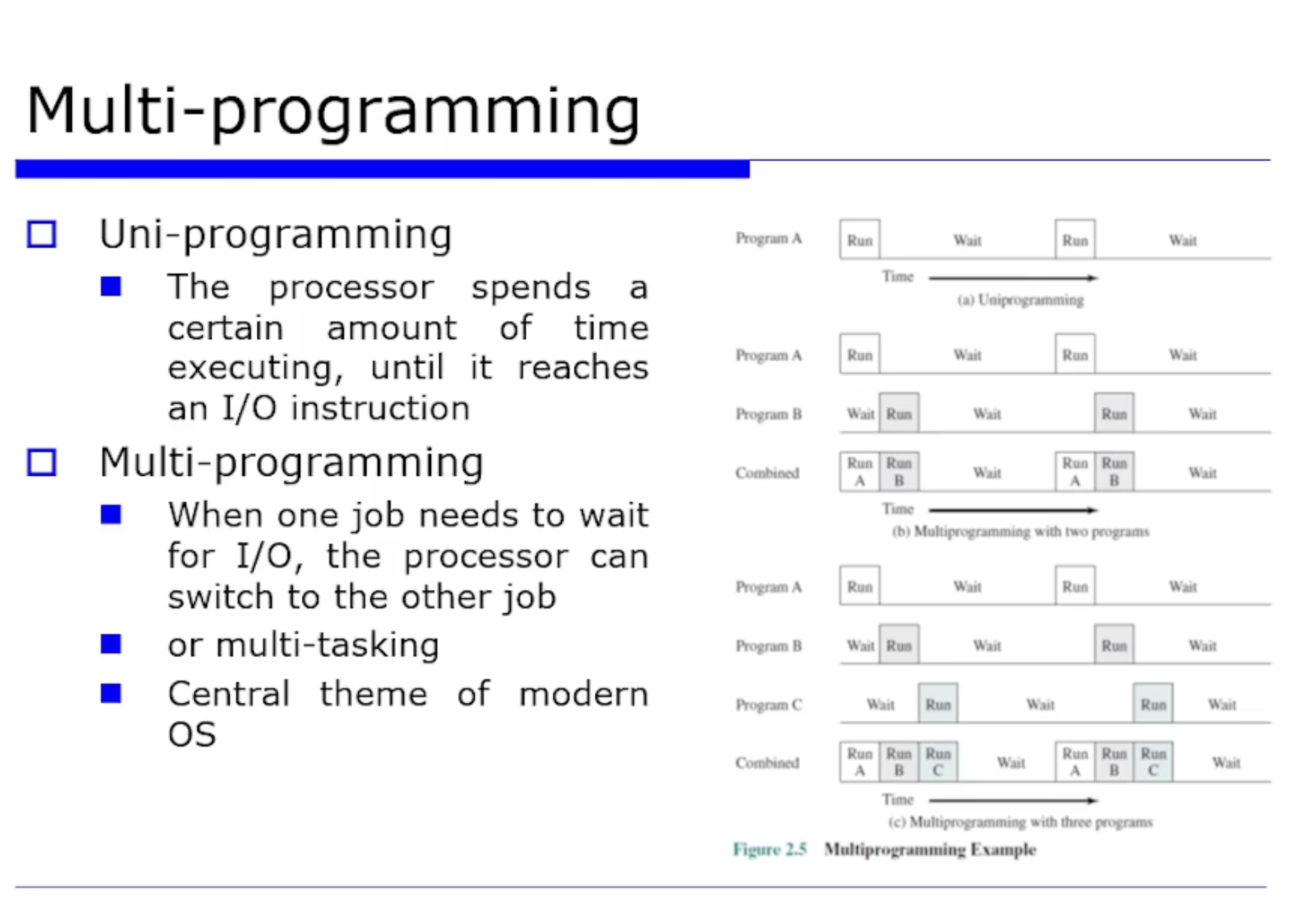
uni programming : 메모리에 Actice 한 job 이 딱 1개만 올라가있는것
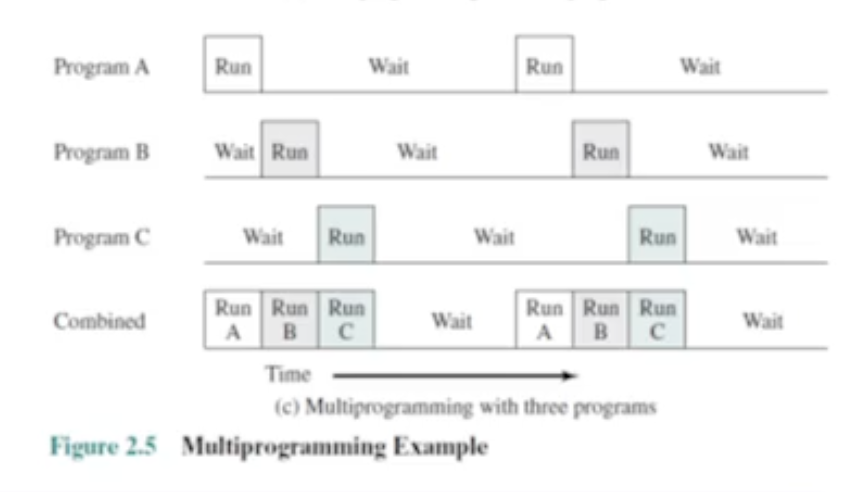
프로그램 A 가 수행다가 I/O 요청을 보낸경우, synchornous 문제로 인해 더 이상 진도를 못나가면 프로그램 B 에게 CPU 를 넘겨준다. 그러면 이 I/O 가 작업되면서 CPU 도 동시에 병행성을 확보한채로 진행 가능하다.
이렇게 mutlti programming 의 정도가 증가할수록 utilitzation 이 증가한다. 하지만 주의할점은 너무 증가하면 오히려 utilitzation 이 떨어질 수 있다. (이에 관한것은 virtual memory 를 나중에 배울때 다룬다.) 그래서 최적의 mutlti programming 정도를 찾아서 utilitzation 을 최적화하는것이 중요하다.

이러한 multi programming 에도 문제가 발생한다. uni programming 시절에는 시작주소가 항상 고정되어있었다. 따라서 CPU 가 어딘가에 다녀와도 항상 동일한 시작주소에서 프로그램이 시작된다.
-
relocation 문제 : multi programming 에서는 active 한 job 들을 메모리에 여러개 올릴텐데, 특정 job 프로그램이 만들어질떄와 실행될 떄에 시점에 어디에 올라갈지 위치를 모른다. 위치는 monitor 가 결정하기 때문이다. 프로그래머는 전형적으로 미리 메인 메모리에 어떻게 다른 프로그램(job)들이 올라가있는지 모른다.
-
Memory Protection : job 이 여러개 존재함으로써 Memory Protection 문제도 발생한다. 기존에는 user area 와 monitor area 2개의 boundary 만 있었다면, 이제는 여러개의 active 한 job 들이 있어서 boundary 가 더 강화되었다. job A 가 죽었는데, 그 원인이 job B 때문인지 C 때문인지, 누구 때문인지를 모른다. 즉 어떤 문제인지 인식하기가 힘듫다.
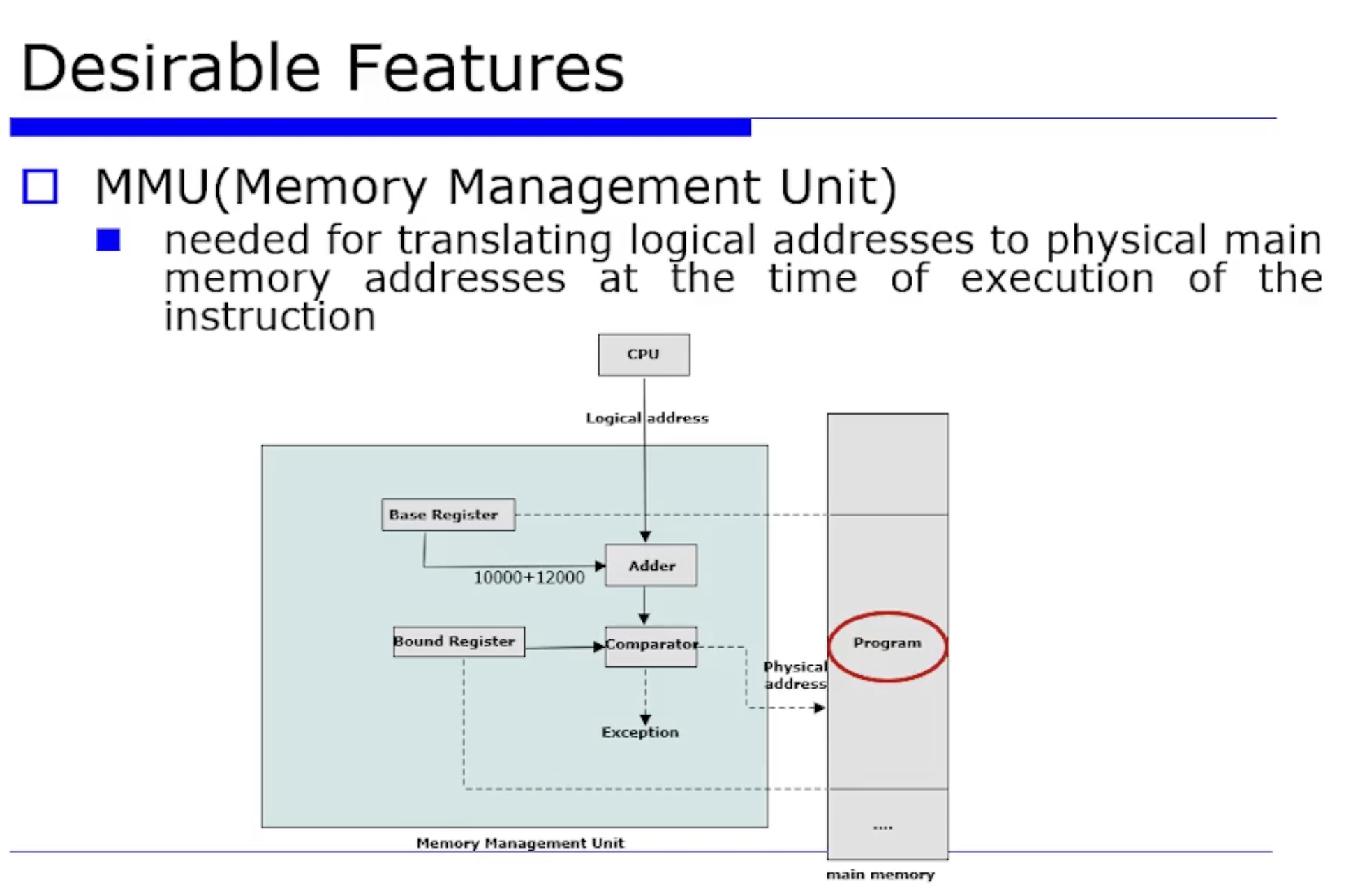
위 문제를 해결하기 위해 초창기에는 MMU 라는 방식을 도입한다.
