운영체제 : I/O 디바이스의 오버뷰

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
I/O Device Overview
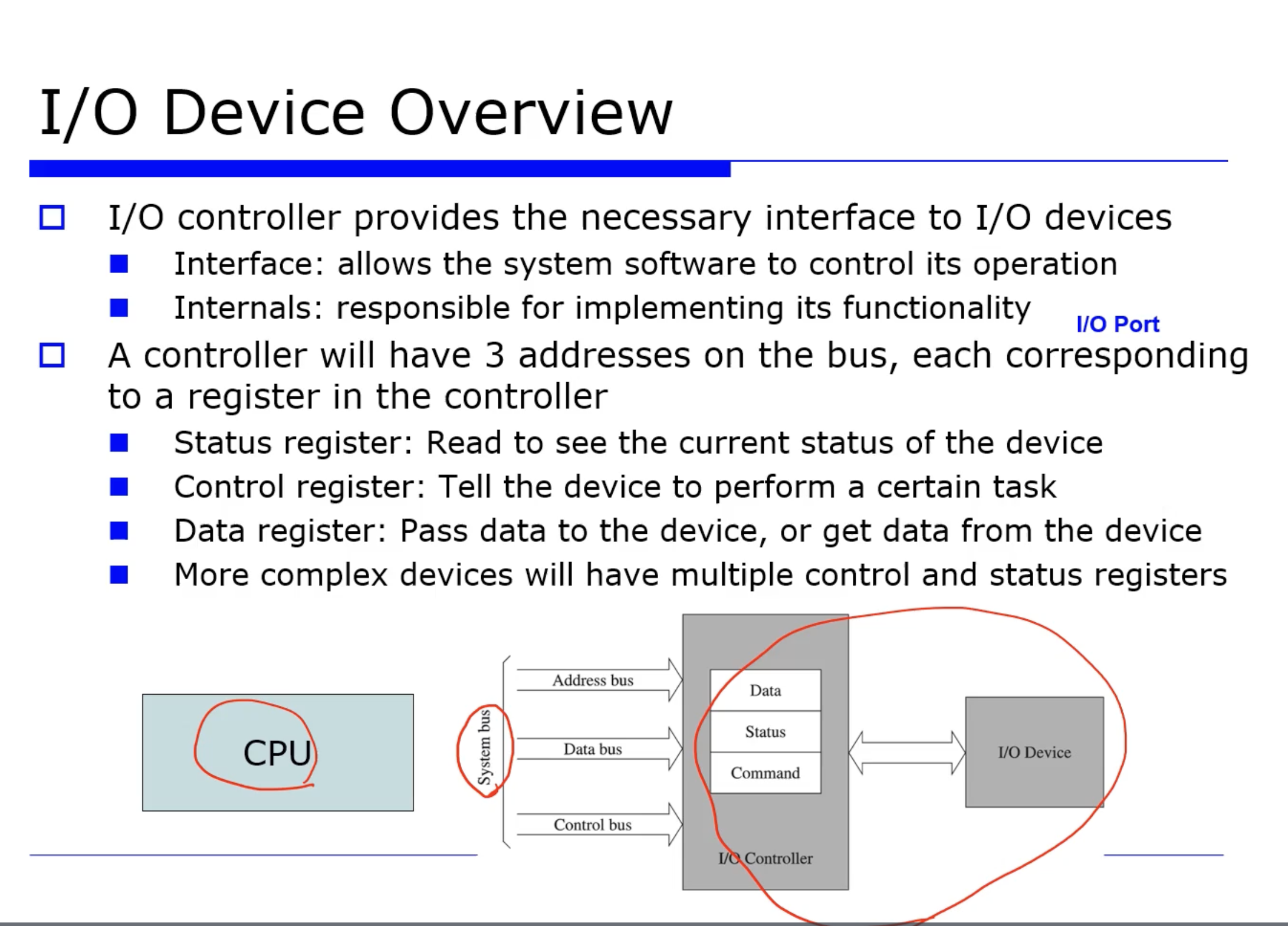
CPU 가 어떻게 I/O 디바이스들과 통신하는지 살펴보자. CPU 가 다양한 I/O 디바이스들을 접근하기 위해선 우선 System bus 를 거치게 된다.
System bus
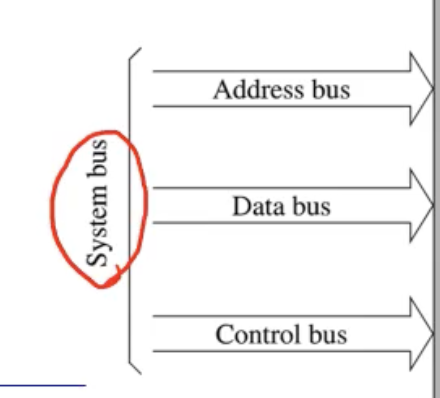
System bus 는 예전에 살펴본것과 같이, 데이터 전송을 위한 하드웨어 라인이다. 이 또한 어떻게보면 컴퓨터 시스템의 중요한 자원이라고도 할 수 있다.
보통 System bus 는 Address bus, Data bus, Control bus 로 세분화된다.
- Address bus : source (출발지) 와 destination (목적지) 를 지정하는 버스
- Data bus : 실제 데이터 전송을 위한 버스
- Control bus : 하드웨어 I/O 디바이스의 operation 를 보면 Load, Store, Write 등의 연산을 진행한다. 어떤 I/O 디바이스에 어떤 명령을 내리거나, 데이터를 가져오거나, Read/Write 하는 연산들이 있다.
I/O Controller
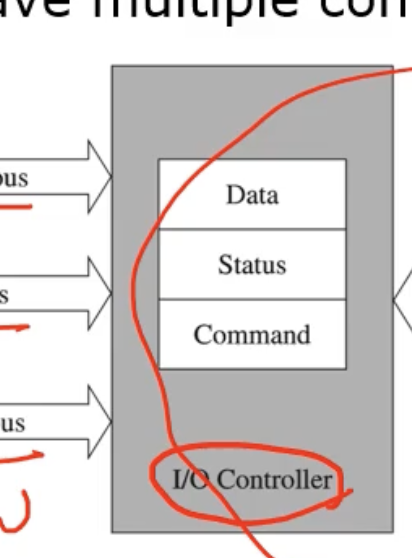
=> 이렇게 명령어를 위한 3개의 bus 를 통해 I/O 디바이스를 전달하는데, 우리가 주목해야 할 것은 I/O Controller 라는 것이다.
보통은 옛날의 컴퓨터 시스템은 CPU 가 system bus 같은것이 없이 직접 자기가 I/O 디바이스에 접근해서 연산을 수행했었다. 이렇게 되면 I/O 디바이스의 시작과 끝을 관장하게(=주관하게) 되서, 실제 idle 한 상태가 되므로 CPU 가 유연하게 다른 작업을 할 수 없게된다. 따라서 CPU 와 I/O 디바이스의 통신의 중간에다 I/O Controller 를 배치했다. CPU 대신에 연산을 진행하고 상호작용하는 능력을 가진 하드웨어인 I/O Controller 를 도입하게 되었다.
I/O Controller 가 인터페이스 역할을 하게 되면서, CPU 의 utilization (활용률) 이 증가한다!
=> 이렇게 되면 CPU 가 I/O Controller 에다 다양한 레지스터를 배치했다. I/O Controller 안에다 Data 레지스터, Status 레지스터 (디바이스의 상태정보를 나타내는 레지스터), Command 레지스터(명령어를 담고있는 레지스터) 등을 이 안에다 두고, I/O Controller 가 인터페이스 역할을 하도록 했다.
- I/O Controller 가 I/O 디바이스와 CPU 대신에 상호작용할때, CPU 는 다른 작업을 진행할 수 있게 됨으로써 활용률 증가하게 되었다.
I/O 디바이스는 다양한 종류의 디바이스가 있고, 기능이나 functionality 등은 I/O Controller 내부구현에 따라서 잘 동작한다.
또 CPU 로 부터 system bus 를 통해 address, data, control 등을 전달받아서 동작하는 것이다.
I/O Port 레지스터
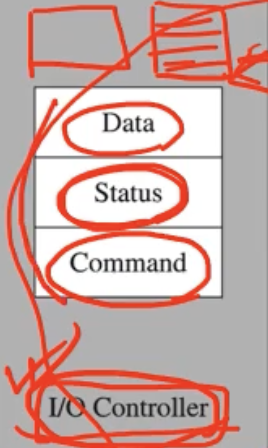
I/O Controller 라는 것은 3개의 Data, Status, Command 에 대한 주소를 제공하고 있다. 보통 이렇게 I/O Controller 에 있는 3개의 레지스터들, 즉 주소가 제공되는 것들을 I/O Port 레지스터라고 통칭해서 부른다.
즉 I/O 디바이스를 제어한다는 것은 이 I/O Controller 에 정의되어 있는 데이터를 읽고쓰기위한 레지스터나 로컬 메모리에 있는 주소와, 그 주소에 있는 연산의 타입 등을 분석하게 되는 것이다.
I/O Address Space

앞서 컴퓨터의 구성요소를 CPU, 메모리, I/O 디바이스들로 생각하고, 그 구성요소들 간의 통신은 system bus 를 통해 이루어진다고 살펴봤다. 각 구성요소 간에 통신을 하려면 당연히 각 구성요소의 어떤 source 와 destination, 즉 주소를 알아야한다. 마치 CPU 에서 메모리를 접근할때는 Memory Address Space 를 사용하듯이, I/O 디바이스들과 통신하려면 주소를 알아야한다. 이런 I/O 디바이스들을 위한 주소를 I/O Address Space 라고 한다.
I/O Address Space 종류
이런 I/O 디바이스들을 위한 주소를 I/O Address Space 는 2가지 구현방식으로 나뉜다. Memory Address Space 와 동일한 주소 체계를 하는 것과, 완전히 별개의 주소 체계를 사용하는 방식이있다.
-
Port-mapped I/O : Memory Address Space 와는 완전히 별도로 분리된 address space 를 가지고 있는 것. 즉, 각 디바이스마다 별도의 Port 레지스터들을 별도의 주소로 매핑하는 것이다. 이 떄문에 main memory 와 독립되었다(isloated) 라고 표현한다. 또 당연히 디바이스마다 I/O address range 를 가지고, 거기에 디버이스를 매핑한다.
- 이렇게 매핑후 추가적인 I/O 명령어들은 I/O address 를 trigger 해서 접근한다. 이러면 별도의 명령어가 추가된다는 단점이 있어서 instruction set 을 단순하게 유지시키려고 하는 아키텍처들이 있다.
-
Memory-mapped I/O : 새로운 명령어 추가없이, 기존 Memory Address 를 같이 사용하는 기법. 즉 Memory Address Space 에서 일부 공간을 배타적으로 I/O address space 로 사용하는 것이다. 그 공간에 I/O 디바이스들과 주소를 매핑해놓고, 같은 메모리 주소체계 상에서 이 I/O address space 를 매핑해서 사용하는 방식이다.
- 단점 : 실제 메모리 공간을 일부 사용할 수 없다는 단점이있다. 공간적인 자원 낭비가 있는것이다.
=> 컴퓨터 시스템은 이 2가지 방식을 모두 제공하는 방식으로 진화하게 되었다.

앞서서 지금까지 I/O 디바이스를 위한 address space 를 살펴봤고, Port Mapped I/O, Memory-mapped I/O 가 있다고 했었다. I/O 디바이스들을 위한 주소체계를 알아봤으니, 지금부터 I/O 통신방법을 알아보자. I/O 통신을 위해 대표적인 3가지 방식을 알아보자.
Programmed I/O
가장 단순한 I/O 통신 방식이다. CPU 에서 어떤 프로그램에 의해 프로그램이 동작하면서 I/O 디바이스에게 어떤 요청을 할것이다. 보통 명령어는 read 또는 write 가 대부분일것이다.
플로우
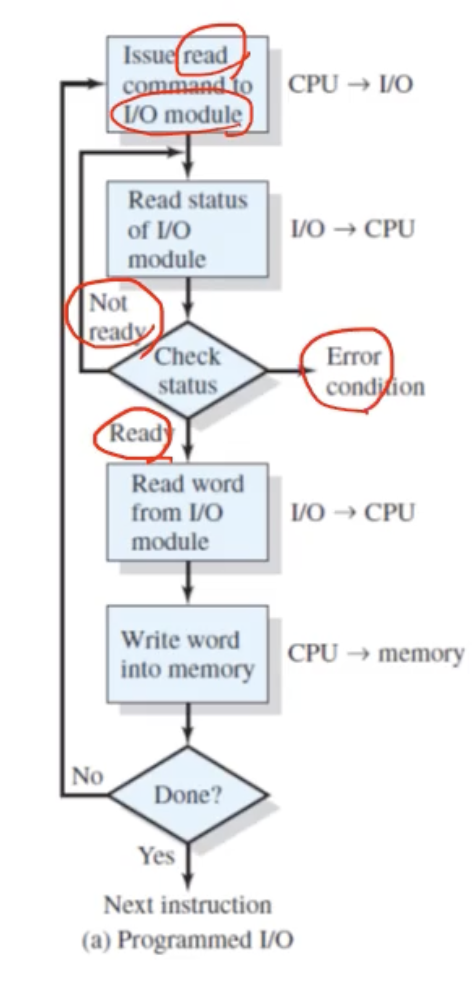
I/O 처리 방식의 흐름도를 알아보자.
- 이때 I/O 디바이스와 통신할때, I/O Controller 안에는 명령어(Command) 레지스터라는 것이 있다고 설명했었다. 그래서 CPU 단에서 I/O 요청을 하면 I/O Controller 의 명령어 레지스터단에다 명령어가 전달된다.
- I/O Controller 가 read 명령어가 전달되었다고 하자. 그러면 이제 I/O 디바이스를 작동시킬것이다.
- 그렇다면 디바이스가 작동할텐데, 현재 그 다비이스가 read 명령어에 대한 처리를 수행할 준비가 되었는지, 또는 안되었는지, 또는 에러가 발생하는지 등으로 다양한 경우의 수로 상황이 나뉠것이다. 이런 다양한 경우의 수에 대비하여, 아래 그림처럼 I/O 디바이스의 상태(status) 를 체크한다.
=> 더 자세히 말해보면, CPU 입장, 즉 프로그램 입장에서는 계속 그 상태(status) 레지스터를 보고 이 전반적인 I/O 디바이스들을 관리하기 위해서 I/O Controller 내부의 이 status 레지스터를 계속 확인해야하는 코드가 있는것이다. 반복문을 계속 돌면서 I/O Controller 의 status 레지스터의 값을 계속 체크하면서 I/O 디바이스에 대한 접근을 해도되는지 계속 확인하는 것이다.
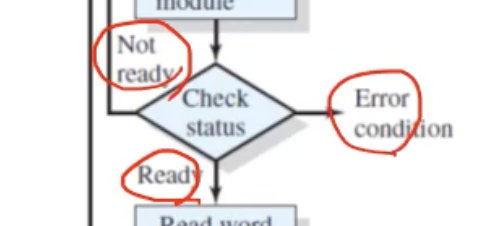
-
Ready 상태, 즉 I/O 디바이스를 실행시켜도 되는 상황이라면 I/O 디바이스로부터 데이터를 받아와서 I/O Controller 내부에 Data 레지스터 같은곳에 어떤 아웃풋 결과를 저장하게 된다.
-
I/O Controller 의 Data 레지스터의 결과값을 CPU 에게 전달해두고, CPU 는 해당 데이터를 읽어서 메모리에 카피해두는 이러한 일련의 과정을 동작한다.
=> Programmed I/O 는 프로그램이 어떤 I/O Controller 와의 통신을 통해서 디바이스의 동작 가능 유무를 확인하기 위해 status 레지스터를 계속 반복적으로 체크하는 방식이다.
cf) Programmed I/O 는 Polling I/O 라고도 부른다.

위 과정을 다시 한번 정리해보자.
-
호스트가 read 명령어를 I/O 모듈(= I/O Controller) 에게 전달한다.
-
I/O Controller 는 본인의 내부의 명령어 레지스터에 있는 명령어가 read 인지 write 인지 확인하고 그 명령어에 대해 수행한다.
-
호스트는 status 를 계속 체크하는 루프(반복문)을 계속 돌게된다. => busy waiting 의 특성을 띄게된다.
-
명령어 수행이 다 완료 되었다면, Controller 의 레지스터에 담긴 결과값을 호스트가 읽고 메모리에 카피해서 프로그램에서 해당 값을 활용한다.
- 정리 : 레이턴시(latency) 가 작다면, 즉 빠른 I/O 디바이스의 경우에는 이 통신방식을 활용하면 좋다. 반대로 느린 디바이스 일때는 I/O 에 대한 수행속도가 느리므로, CPU 가 I/O 디바이스에 대해 status 를 계속 체크하면서 busy waiting 을 하는 시간이 길어지므로 utilitzation (활용률) 측면에서 비효율적이다.
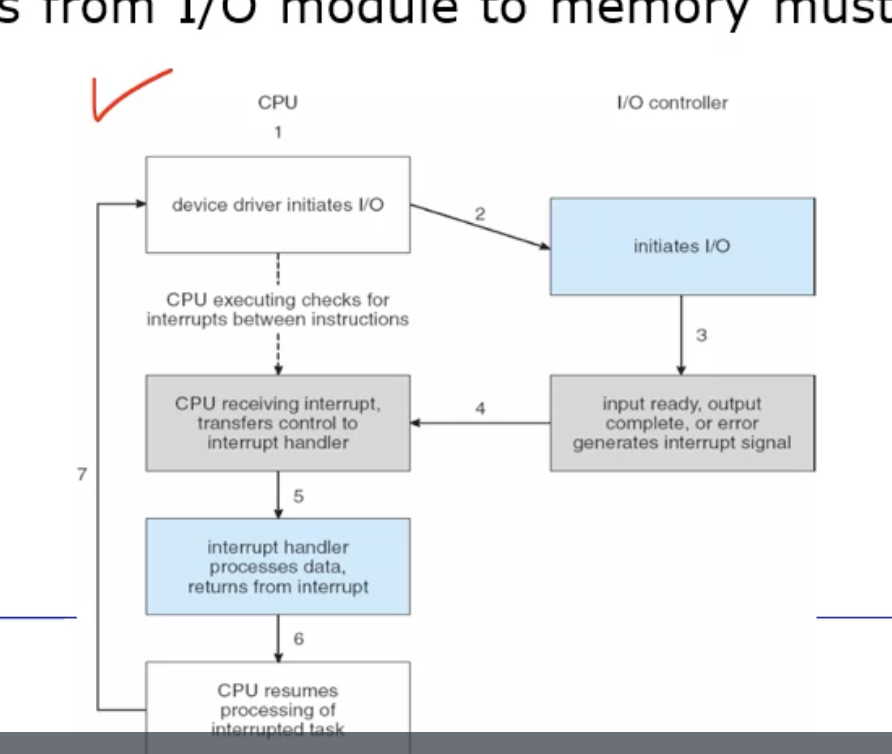
Interrput-Driven I/O
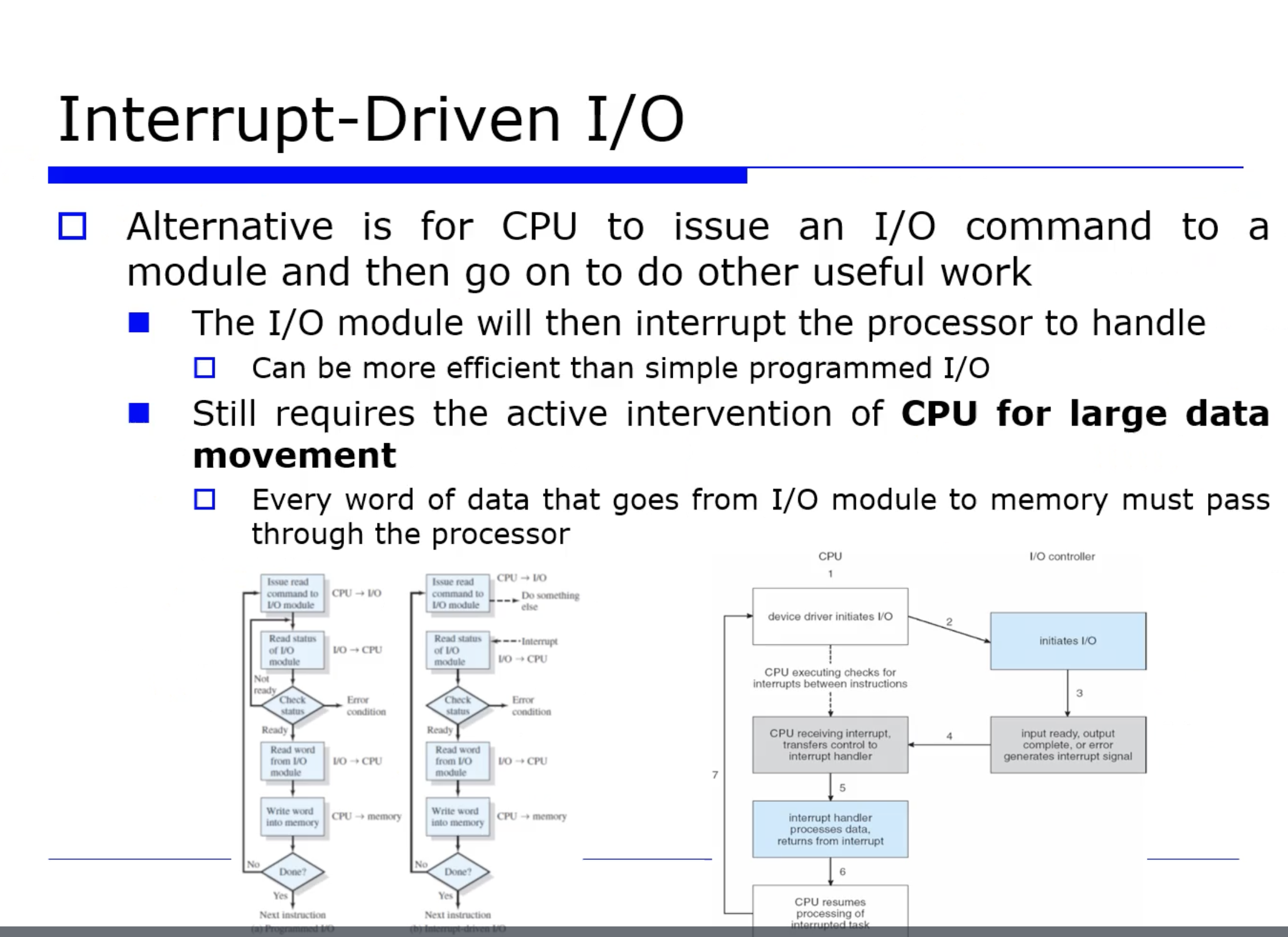
이런 Programmed I/O 의 busy waiting 문제를 해결하기 위해 Interrput-Driven I/O 통신방식을 적용할 수 있다.
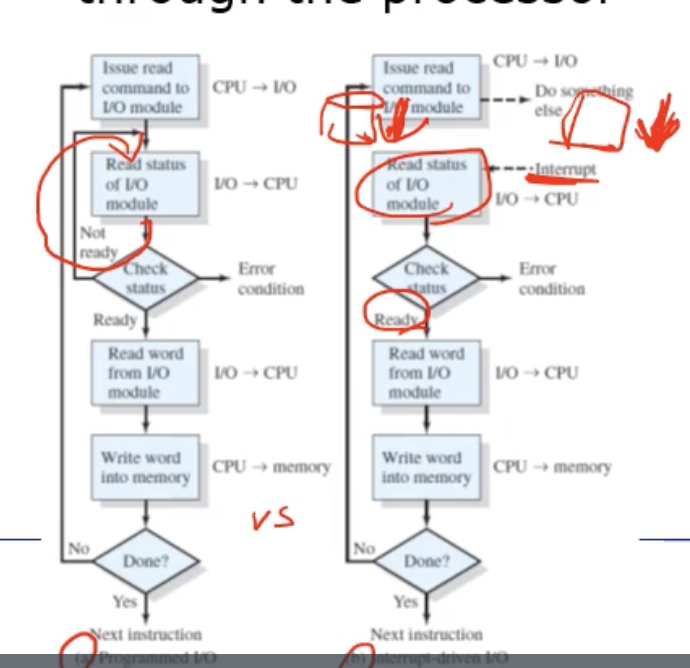
왼쪽 그림 (a) 는 Programmed I/O 방식이고, 오른쪽 그림 (b) 는 Interrput-Driven I/O 방식이다. 보듯이 Interrput-Driven I/O 방식은 busy waiting 을 하는 루프 부분이 없어졌다.
즉, 아까처럼 프로그램(CPU) 이 status 레지스터를 계속 관찰하기위해 반복하는 것이 아니라, CPU 가 어떤 I/O 명령어를 I/O Controller 에게 보내자마자, 곧바로 다른 유용한 작업을 하러 가는 방식이다.
interrput 활용
=> 프로그램(CPU) 에서 요청을 보내면 I/O Controller 에 의해서 I/O 디바이스는 바로 수행하고, 동시에 프로그램도 다른 작업을 수행하는 병행성의 특징을 보인다. 이로써 utilization 을 높일 수 있다.
그러면 이렇게 수행하는 도중에 I/O Controller 가 자기 할일이 끝나면 interrput 를 보낸다. interrput 를 보내면 동일하게 status 레지스터를 한번보고, 준비가 됐을테니까 원하는 공간으로 write 하는 방식으로 동작할것이다.
- 이렇게 I/O 모듈이 실제 작업이 다 끝나면 interrput 를 걸어서 핸들링할 수 있도록 하는 통신 방식을 Interrput-Driven I/O 라고한다. 이렇게 busy waiting 을 없애서 병행성을 높인다.
mode switch 비용 발생
- 단점 : char 디바이스에서 write 연산 단위가 word 단위라고하면, 계속 interrput 방식으로 요청했을 때 큰 용량의 데이터(large data) 에 대해서는 read 든, write 든 계속 interrput 를 유발시키면
mode switching 비용이 발생할 수 있다.
아래처럼 CPU 에 의해서 I/O 요청이 시작되면, I/O Controller 가 작업을 하다가 다 완료되거나 도중에 에러가 발생하면 interrput 을 발생할 것이다.
그래서 interrput handler routine 를 처리하기 위해서 커널모드로 들어가고, 다시 유저모드로 돌아와서 재개하는 것이다.
이렇게 유저모드 - 커널모드 - 유저모드 처럼 모드를 바꾸는 것을 mode switching 이라고 했는데, read, write 할 데이터가 굉장히 많을 경우에 mode switching 으로 인해 발생하는 오버해드를 무시할수 없다는것이다.
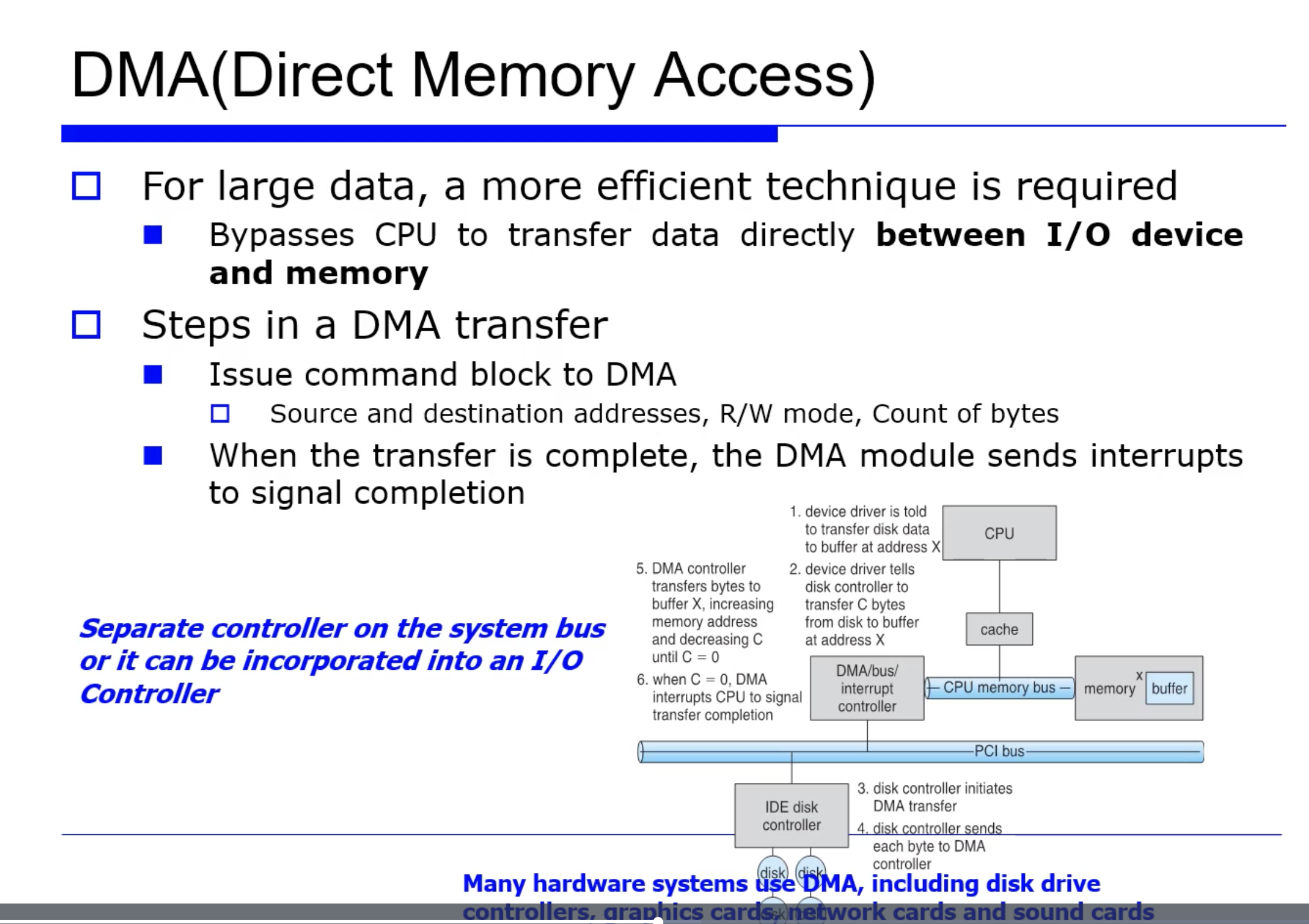
DMA
앞서 지금까지 char 연산을 대상으로 해서 한 word 의 연산을 수행할때의 Programmed I/O 와 Interrput-Driven I/O 방식으로 동작하는 과정에 대해 살펴봤다.
그런데 하드디스크 드라이브와 같은 대용량의 데이터(large data), 즉 블럭 단위의 연산을 하는 그런 하드 디바이스들에 대해서는 좀 더 효율적인 기법이 필요하다.
예를들어 음료수나 껌 같은것을 사려고 대형 마트까지는 안가지 않는가? 가까운 작은 동내슈퍼를 갈것이다.
이렇게 수행시간이 오래걸리는 디바이스들은 블럭 단위의 연산을 수행하는데, 이런 디바이스들을 블럭 디바이스라고 한다.
Interrput-Driven I/O 방식을 활용했을때는, 매 word 에 대한 연산이 끝날때마다 interrput 를 발생해서 mode switching 이 발생한다. 또 Programmed I/O 방식은 busy waiting 이 발생하게된다.
- 이런 부분을 더 개선시켜서, 각각의 블럭 단위로 카피한 다음에 최종적으로 다 끝나면 interrput 만 발생시키는 방식으로 CPU 개입을 최소하하는 방식이다.
이런 방식을 위해, I/O Controller 가 직접 그 메모리에 접근 가능해야할 것이다. 따라서 이를 Direct Memory Access 방식이라고 한다.
DMA transfer
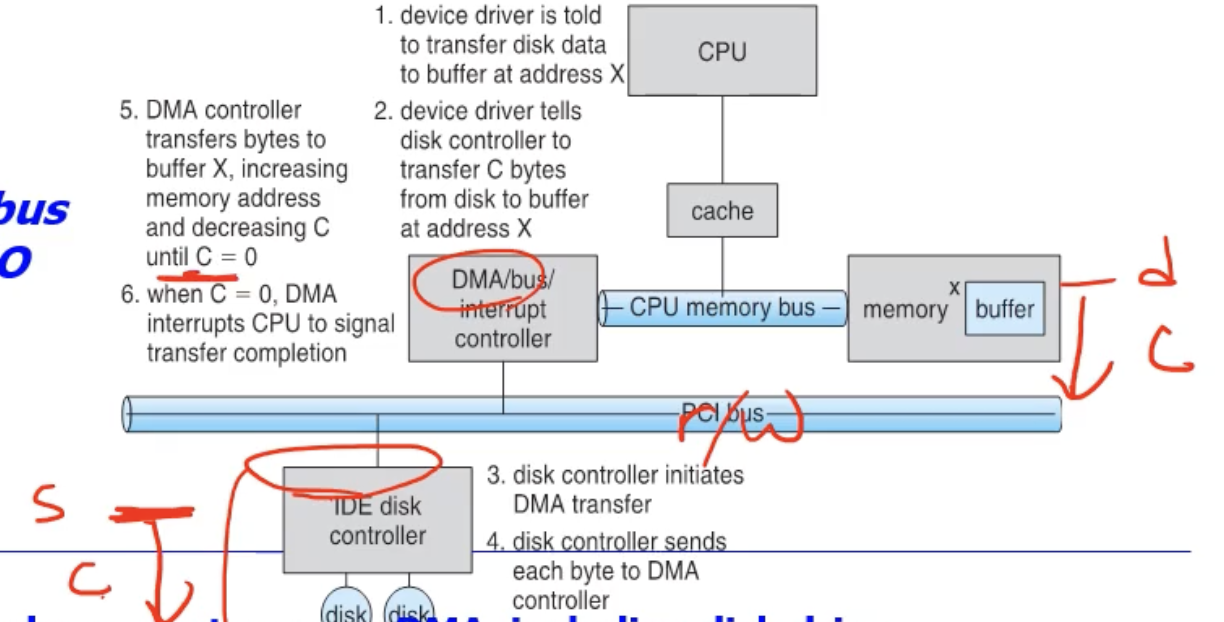
그래서 DMA 방식으로 transfer(통신) 할때는,
-
CPU 가 맨처음에 DMA Controller 에게 명령어의 집합인 Command Block 을 보낸다. 그 명령어 블럭이라는 것은, 하드디스크에게 특정 일부분을 카피해서 메모리에다 붙여넣는(read/write 하는) 명령을내리는것이다.
-
DMA Controller 가 개입을 해서, 명령어 블럭이 카피되면서 카운팅한다. 즉 C = 0 이 될때까지 계속 감소시킨다. C 가 0 이 되면 최종적으로 CPU 에게 interrput 를 날린다. 즉, 메모리에 다 카피하고나서 최종적으로 reporting 만 하는 방식이다.

이때 DMA Controller 는 system bus 상에서 I/O Controller 와 분리된 형태로써 구현되던지, 또는 I/O Controller 와 통합된 형태로 구현될 수도 있다. 이러한 다양한 형태로 구현되고 활용될 수 있어서, 블럭 단위 데이터에 대한 고속의 통신이 가능하다.
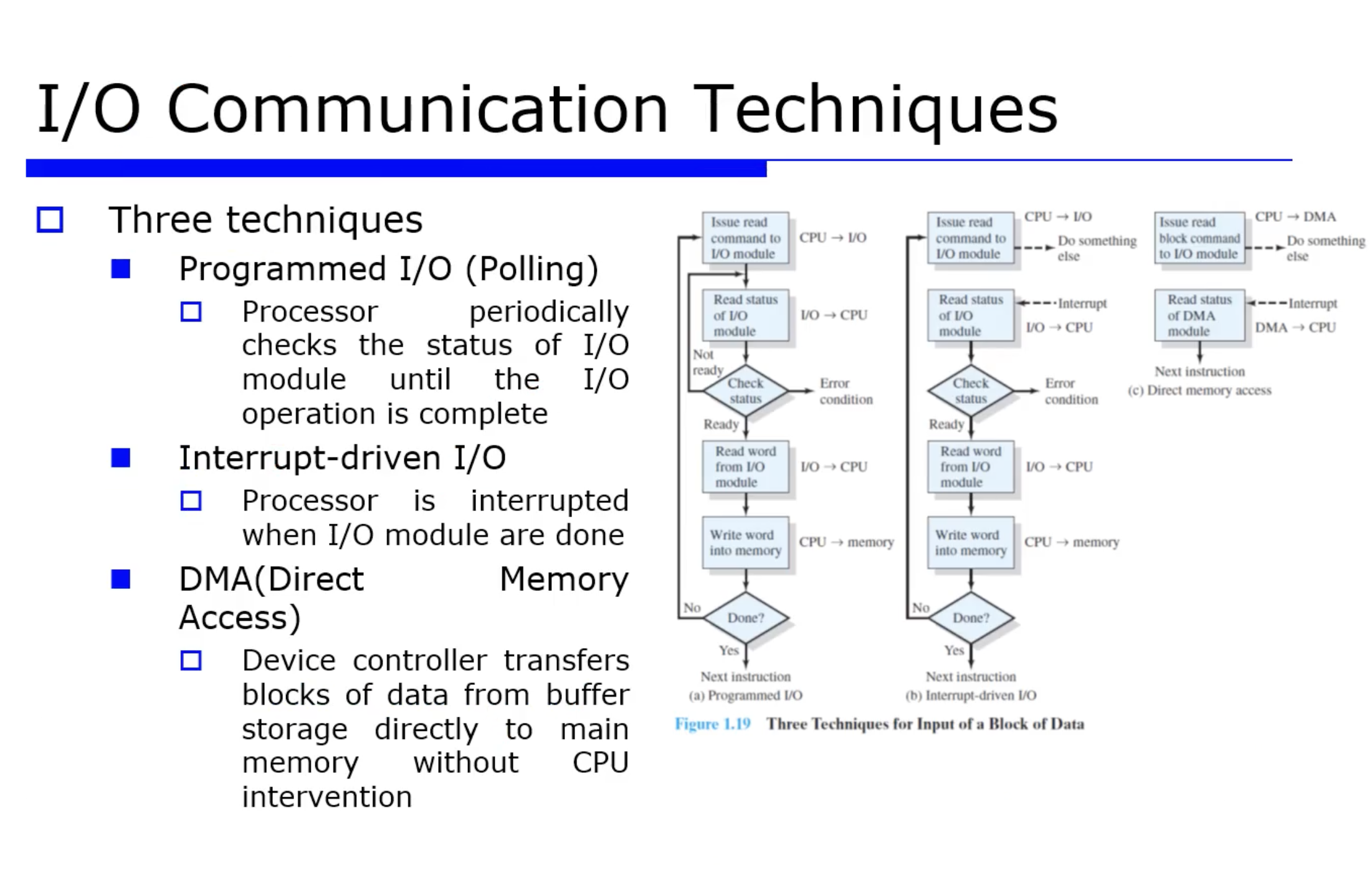
앞서 살펴본 3가지 통신 방식을 비교 및 정리해본 ppt 슬라이드다.
DMA 방식은 블럭단위의 명령어들을 주고, DMA Controller 가 CPU 의 개입없이 직접적으로 메모리로 다 블럭을 전송하고 완전히 끝나면 최종적으로 DMA Controller 가 interrput 를 CPU 에게 전달하는 방식이다.
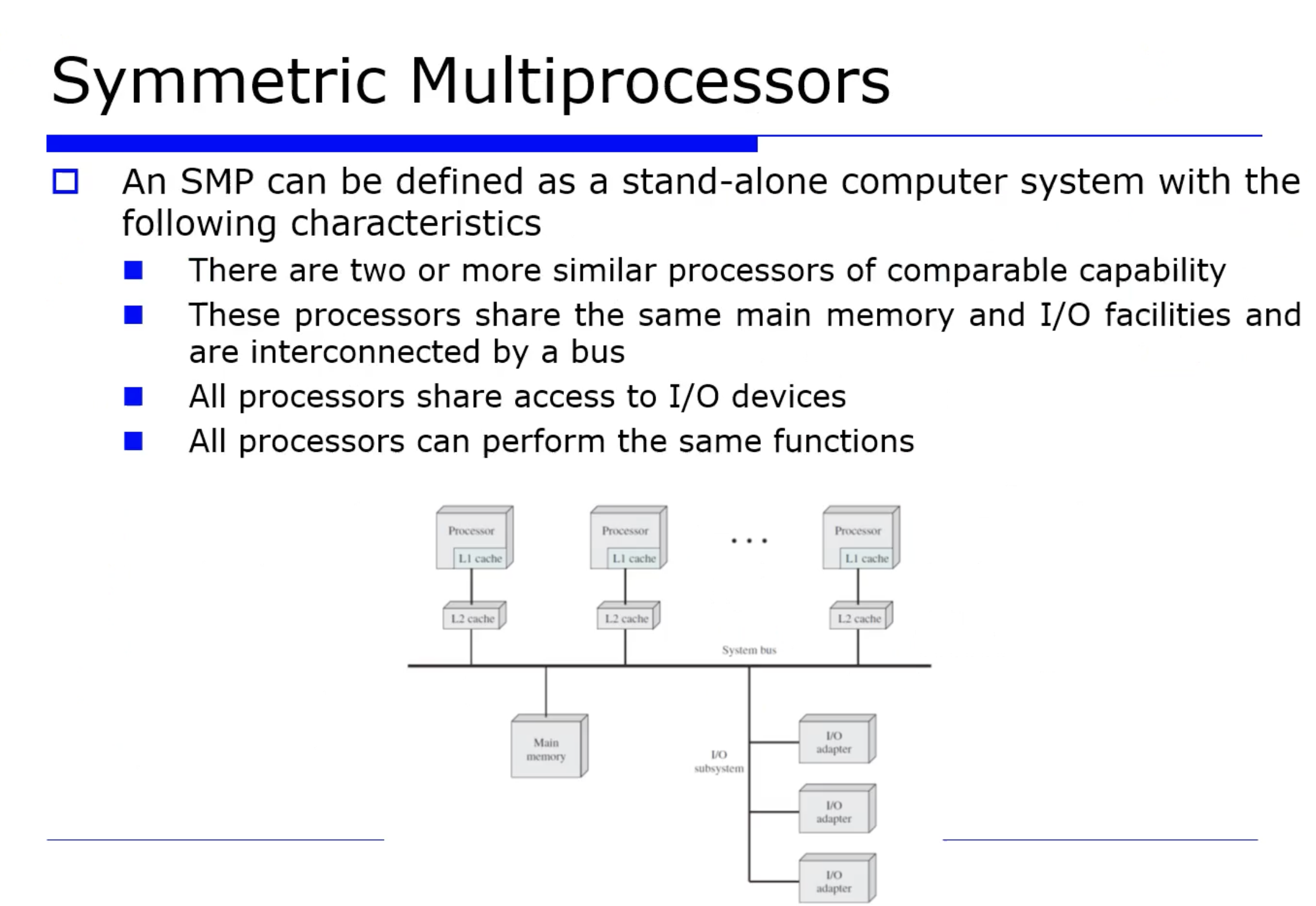
한 시스템에 한 프로세서(처리기) 를 가진것을 uni processor 라고하며, 다수의 프로세서를 가진 것은 multi proceessor 라고한다. (다중 처리기)
위 그림처럼 여러 프로세서를 한 시스템에 가지고 있으면 어떤점이 좋아지는가? main memory 를 shared memory 로써 함께 공유하고, 여러개의 I/O 디바이스들도 함께 공유하면서 단위 시간당 처리할 수 있는 작업 량이 많아진다.
에를들어 프로그램이 1, 2 가 있는데 동시에 병행적으로 수행할 수 있다. 또 다른 메모리나 I/O 디바이스들을 공유하면서 규모의 경제(?) 를 이룰 수 있고, 또한 오작동하다가 남은 프로세서로 fault-tolerant (오류에 관대하게) 하게 구현할 수 있기 때문에 신뢰성이 증가한다.
이렇게 multi processor 를 구현할 때 2가지 종류의 다중 처리기가있다. 하나는 대칭적(symmetric) multi processor 가 있다. (줄여서 SMP 이라고 부른다) 또 이와 반대 개념인 Asymmetic (비대칭적) multi processors 가 있다. 우리 교재에서는 SMP 를 설명하고 있다.
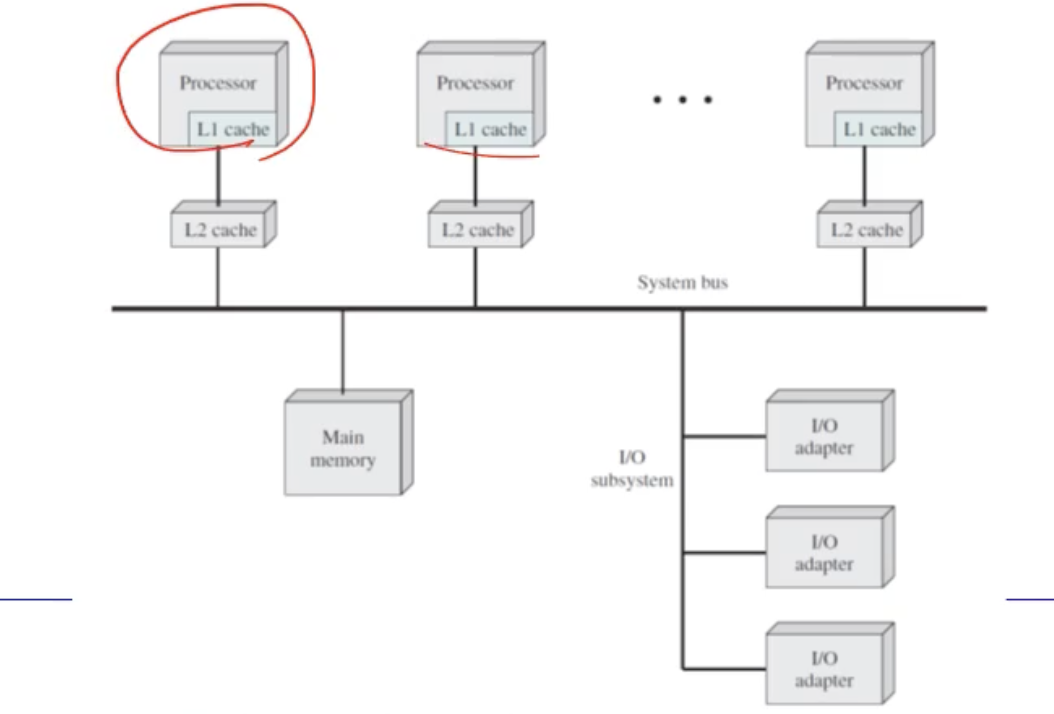
- 이떄 SMP 에서 가장 큰 특징은, 아래 그림처럼 각각의 프로세스가 대등한(동일한) 역할을 하는것이다.
=> 즉 SMP 란 동일한 프로세서들이 있어서, 모든 프로세서들이 대등한 역할을 수행하는 것이다.
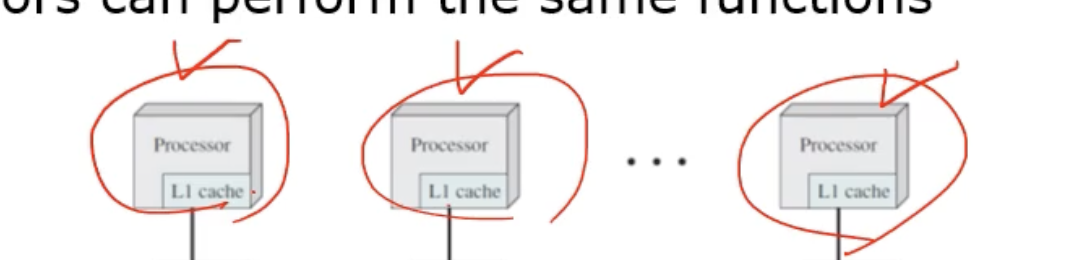
반면 비대칭적 multi processor 는 말그대로 역할이 동등하지 않은것이다.
SMP 에서 디바이스에 초점을 맞추면, 아래 그림처럼 전체 시스템에서 공유되는 어떤 디바이스들이 있을 것이고,
각 프로세서마다 어떤 로컬 디바이스가 있을것이다. 대표적으로 아래와 같은 시스템 타이머 같은 것들이다.

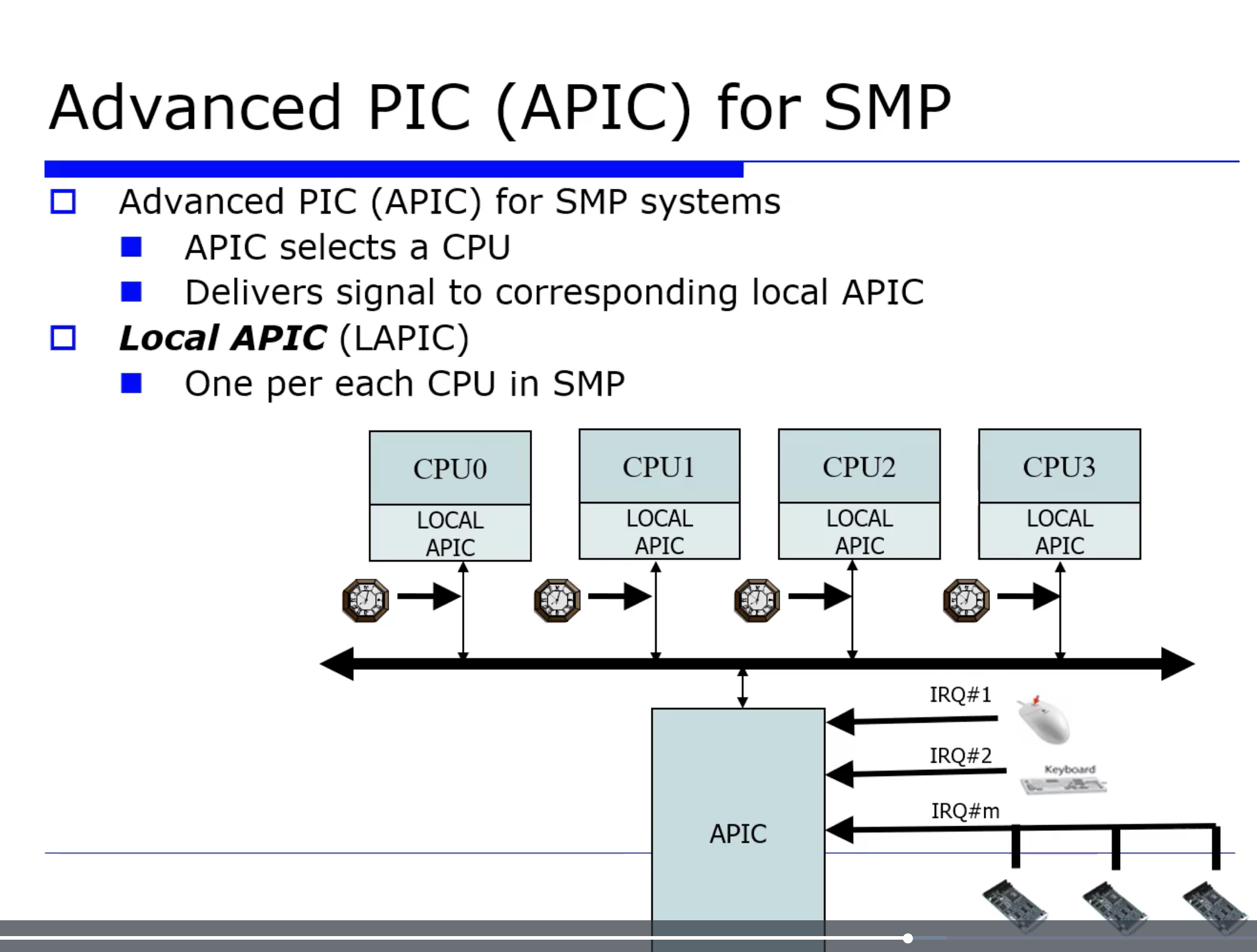
외부 디바이스에 대해 interrput 가 왔는지 보고 interrput 를 제어하는 것을 PIC 이라고했었다. 이런 PIC 의 역할은 interrput signal 을 벡터로 변환하는 역할을 한다고 했는데, 여기에 이어서 새로운 역할이 필요하다.
interrput 를 처리할 프로세서가 아래 그림처럼 여러개 있을수있다. 그러면 이 CPU 를 선택해야하는 어떤 개선된 형태의 PIC 인 APIC 이라는 형태로 진화하게 되었다. 즉, interrput singal 이 오면 공평하게 SMP 에서는 대등한 역할을 하길 원하므로 적절히 공평하게 처리할 수 있도록 하는 어떤 기능이 필요하다.

또 로컬 디바이스와 공유 디바이스로온 interrput 를 처리할 수 있는 local PIC 도 필요하다.
그 래서 최근에 이러한 multi processor 환경에서 interrput 처리를 위해서 외부 공유 디바이스로부터 온 signal 을 분배하기 위한 APIC 과, 그리고 각 CPU 에서 local 디바이스를 처리하기 위한 local PIC, local APIC 으로 세분화되어 발전해왔다.

이러한 프로세서는 multi processor 형태로 진화하다가 다양한 Heteroeneous Architecture 형태로 진화했다. 성능이나 기능에 따라서 다양한 스팩트럼을 가진 하드웨어가 출시되고있다.
