
본 포스트팅은 인하대학교 컴퓨터공학과 시스템 프로그래밍 수업자료에 기반하고 있습니다. 개발 포스팅과 달리 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Hyper-threading
- piplining 의 순서를 잘 짜서, 물리적으로는 코어가 하나인데 마치 여러개인 것처럼 보이게하는 하드웨어 기술
- thread : 앞서 말한 쓰레드가 아니라, 하드웨어에서의 쓰레드이다.
=> 물리적인 실제 코어 하나당 가상화를 진행해서 2개인것처럼 보이게한다.
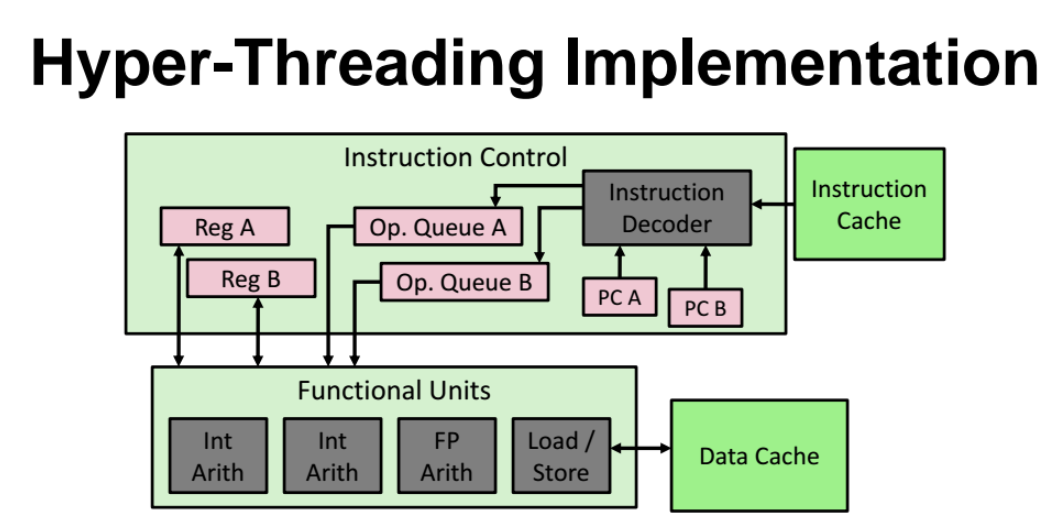
Hyper-threading 구현
-
Instruction Cache(메모리, 디스크, 캐시 등등) 에서 명령어(instruction) 을 가져온다.
-
instuction decoder 를 통해 무슨 instruction 인지 해석해낸다.
-
큐에다 넣고 실행한다.
-
Function Unit : 실제 계산을 해주는 녀석들. => 128비트까지 명령어들을 동시에 수행 가능하다. 많은 instruction set 을 가져와서 independent 하던 명령어들을 동시 수행함.
=> 이랬더니 마치 코어가 2개인것처럼 수행
Out-of-Order Porcessor Structure
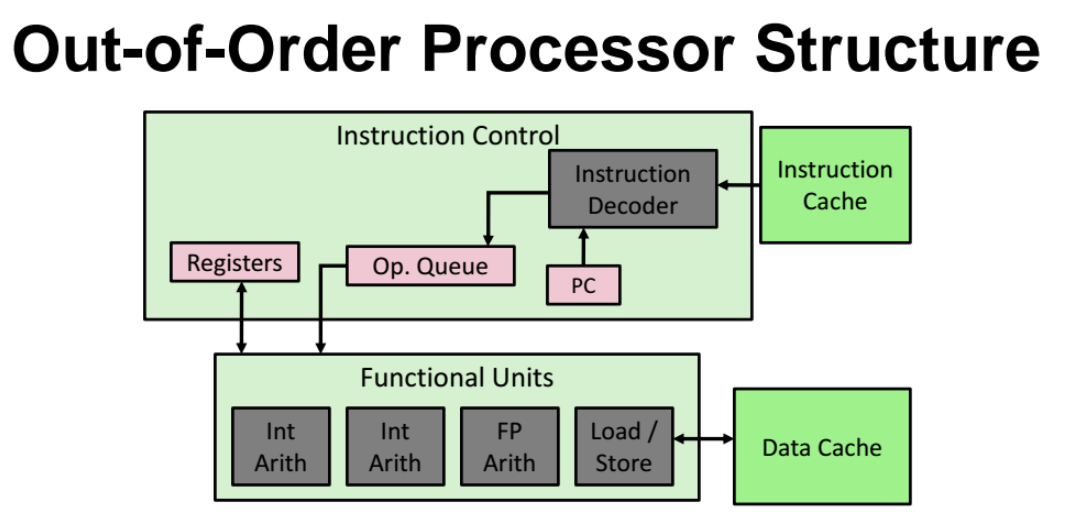
- 프로그래머가 부여한 명령어 실행순서가 있는데, CPU 가 봤을때 순서를 바꿔도 실행 결과값이 안바뀌는 것을 보장할 수 있을때, 실행하는 순서가 프로그래머가 지정한 프로그램의 명령어 실행순서와 다른 경우
=> 가능하다면 순서를 살짝씩 바꿔서 더 빨리 실행할 수 있게한다.
- Parellel하게 명령어들을 동시에 수행 가능
예시 : Parallel Summation
-
등차수열로써 1 ~ n 까지의 합을 구하는데, Parallel 하게 구하는 것이다.
( => n x (n-1)/2 결과값이 나올거임) -
t개의 쓰레드가 있는경우, 각 쓰레드는 n/t 개수만큼 프로세스를 할당받는다.
psum-mutex


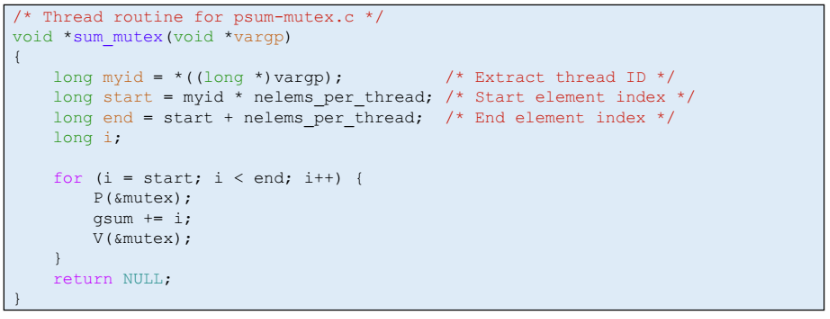
- 각 쓰레드는 start index 부터 end index 까지 모든 원소들 전역변수 gsum에다 더한다. 그리고 P V 로 감싸줬다.
성능분석

- 자원(코어)을 더 썼는데도 실행시간이 더 늘어났다. => P V 떄문이다. Sychornization 은 정말 시간이 오래잡아먹는 연산이다.
성능 개선하기 : psum-array

-
각 쓰레드마다 본인만의 psum 이라는 배열을 만들어서 본인의 배열에다가 값을 더해주는 방식이다.
-
앞선 방식은 쓰레드가 몇개있던지 global 변수라서 다 같이 공유했었는데 지금은 쓰레드 개수만큼 각가 자기꺼에다 더해주도록 폭을 넓혀줬다.
아까와 달리 P V를 없애서 Sychornization 을 없애줬다.
=> 장점1) 캐시 miss rate 줄어들어서 성능 향상됨
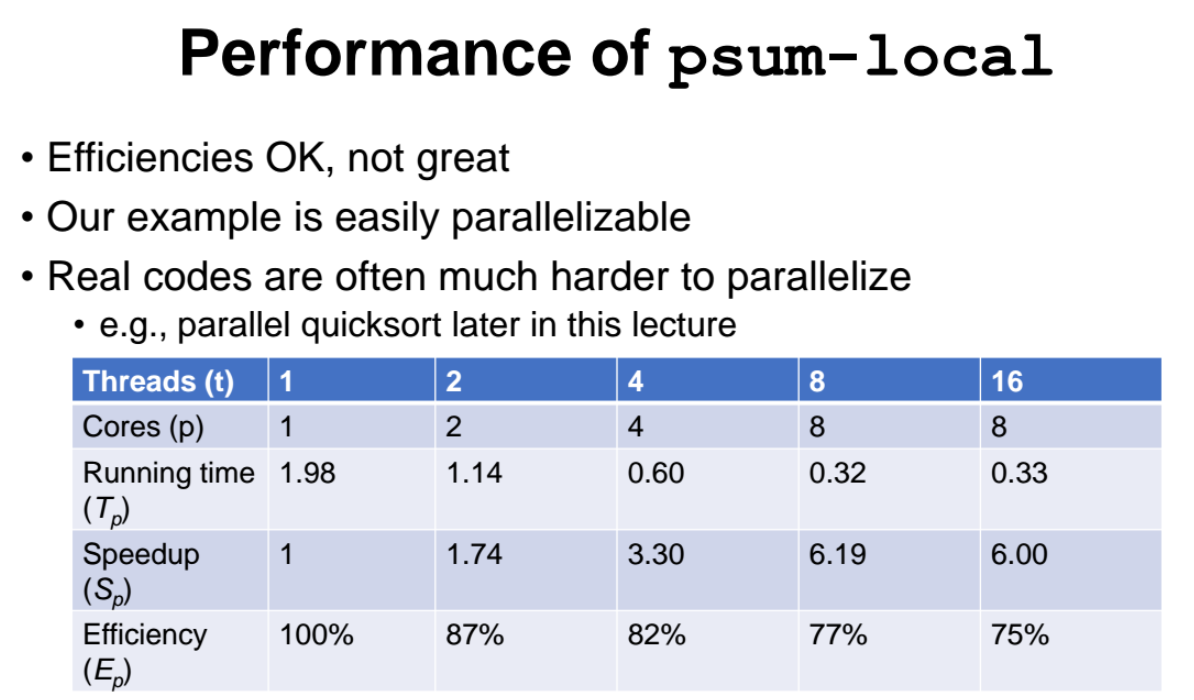
psum-local

- 성능을 더 향상시킬 수 있다.
- inner loop(for문) 안에서 psum 배열에 바로 element 들을 더해주는 것이 아니라, 지역변수 sum 에다가 더해준다. for문을 다 돌리고나서 psum 에다 결과값을 할당해주는 방식이다. (code motion 방식)
Parallel Program 의 성능분석 지표
- Speedup
- 얼마나 빨라졌는가
- T1 : 쓰레드 1개 사용했을때 걸린시간 / Tp : 쓰레드 p개 사용했을떄 걸린시간
2.Efficiency
- resource(쓰레드)를 p개(Sp) 줬을때 얼마나 빨라지는가의 수치.
- 그냥 얼마나 빨라졌는가이다.

앞서 살핀 3가지 방식의 코드에 대한 SppedUp과 Efficiency 지표를 가지고 성능을 비교해보자.
- 쓰레드를 1,2,4,8,16개를 사용했을떄에 대한 실행시간들이다.
Amdahl’s Law
- T : Total sequential time
- p : 소프트웨어에 parallize 가 되는 비율
- k : Speedup factor
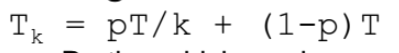
- pT : Sequential Time 에다 parallize 가 되는 비율을 곱해주고 k로 나눠준다.
- 1-p : parallize 가 안되는 Sequential Time
=> parallize 가 되는부분은 k배 빨라지고, 안되는 부분 Sequential time 시간만큼 걸리며 수행될것이다. 이 둘을 더하는 것이다.

- 90퍼가 parallize 되는것이고, 나머지 10퍼가 안되는것이다.
- 9개의 요소가 SpeedUp 되는 요소들이다.
QuickSort
- pivot 을 선택하고, 왼쪽은 pivot 보다 작은값, 오른쪽은 pivot 보다 큰 값으로 옮기기만 하면된다.

- 재귀함수
- base : pivot 중간지점
- 함수는 pararillize 할 수 없으므로, 특정 개수를 정해놓고 남은 element 개수가 그것보다 작으면 Quicksort 를 호출시키게한다.
( = nthread 보다 남은개수 n이 더 작으면 quicksort 를 호출)
