
본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스sw개론 수업자료에 기반하고 있습니다. 개발 포스팅과 달리 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Transformers pipelines
-
pipeline : 일련의 복잡한 process 들을 처리하는 객체
-
sentiment analysis : pipeline 이 수행 가능한 수많은 기능들 중 하나인 감정분석(sentiment analysis) 에 대해 알아보자.
주어진 텍스트를 가지고 감정을 분류(text classification) 하는 것이다.
- 긍정, 부정만 가지고 판단하겠다!

-
classifier = pipeline("sentiment-pipeline") : 감정분석을 위한 pipeline 객체생성
-
result = classifier("I hate you") : pipeline 객체에 감정분석을 원하는 문장을 입력해야한다.

보듯이 "I went to a resturant" 문장을 입력했더니 부정이라고 나온다. => pipeline 은 긍정, 부정밖에 모른다!
Extractive "Q"uestion "A"nswering

- 질의응답 QA 를 하는 pipeline 의 기능
- 질문 문자열을 입력으로 넣으면 그에대한 아웃풋으로 단답형 대답을 해준다.

- pipeline 객체의 인자로 "question-answering" 을 넣어주면 QA 를 해준다.
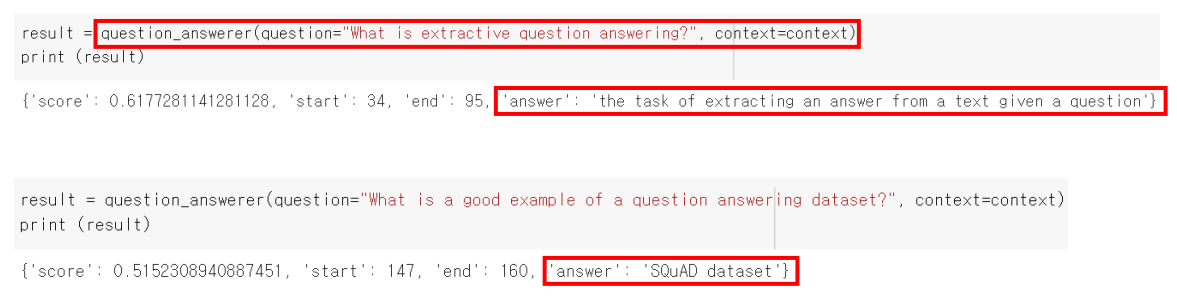
- question_answer(question = "질문 문장", context = "지문 문장")
cf) 완벽히 대답은 못함. 살짝 멍청한 모델임ㅠㅠ
Text generation
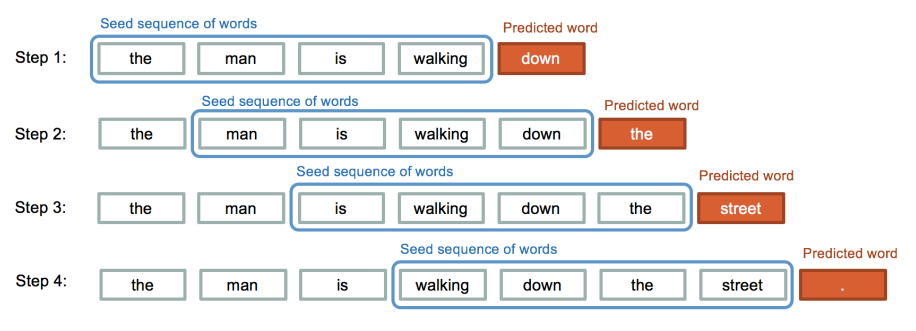
- 텍스트를 생성해준다. (글짓기 AI이다.)
예시처럼 the, man, is, walking 단어 4개를 넣어주면 그 다음으로 예측되는 단어인 "down" 을 AI가 자동으로 넣어준다.
=> 이런 방식으로 한 스탭에 한 단어씩을 계속 생성해나간다.

-
pipeline("text-generation") : 인자로 text-generation 이라는 문장을 넣어주면 된다.
-
동일한 인풋 문자열을 부여해도, 출력결과는 매번 달라진다. 즉 자동생성되는 단어가 매번 달라짐 (랜덤하게 생성된다!)

- do_sample 옵션 : do_sample 옵션에 False 를 부여하면 동일한 인풋을 부여하면 매번 같은 아웃풋 작문 결과가 작성된다.
Text summarization

- 긴 원문을 짧은 요약문으로 변환하는것
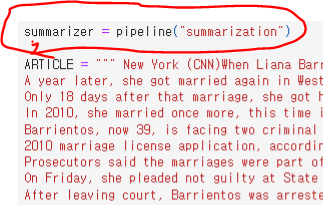
- 위처럼 인자로 "summarization" 을 넣어주면 된다.
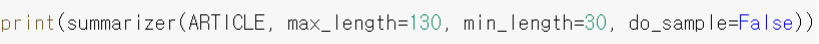
- 요약문을 생성하고자 하는 원문 을 인자로 넣어준다.
- min_length 옵션 : 요약문의 최소 길이를 지정하는 것
- 마찬가지로 do_sample 옵션에 False 를 지정해서 매번 같은 결과가 나오게 한다.
model 옵션

- pipeline 으로 text-generation 을 사용시, model 을 지정 가능하다.
NLP model training process
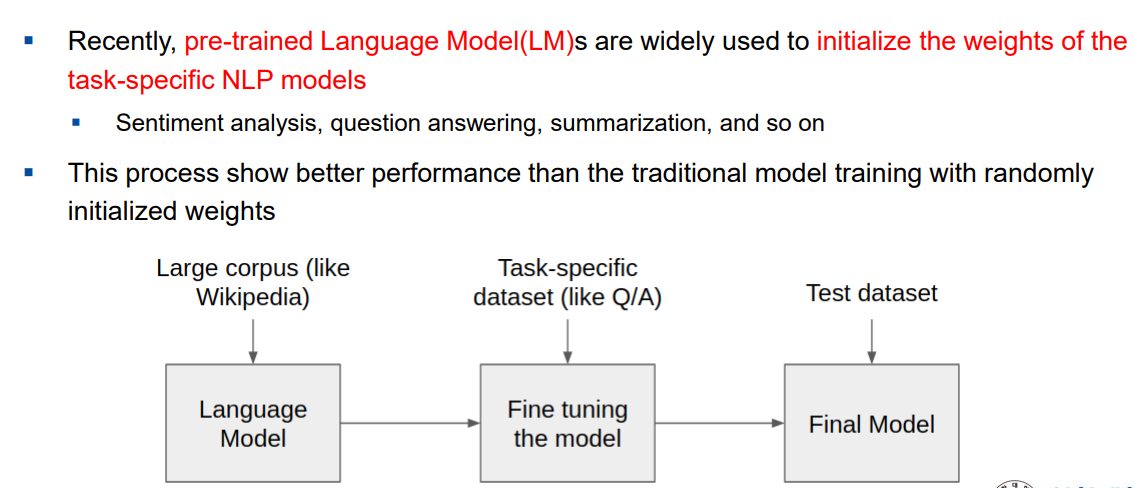
- NLP model : 사전 학습 모델(pre-trained Language Model) 을 활용. 어느정도 사전에 미리 학습된 모델을 가지고 우리가 원하는 세부적인 task 를 학습을 시키고, 학습이 다 되면 사용하는 것이다.
사용과정
- 주어진 dataset 을 가지고 모델을 사전 학습(pre-training) 을 시킨다.
- 사전 학습이 끝나면 기억을 하고 있는다.
- 그 상태에서 우리가 원하는 테스크를 진행시켜주면 된다.
- corpus = dataset
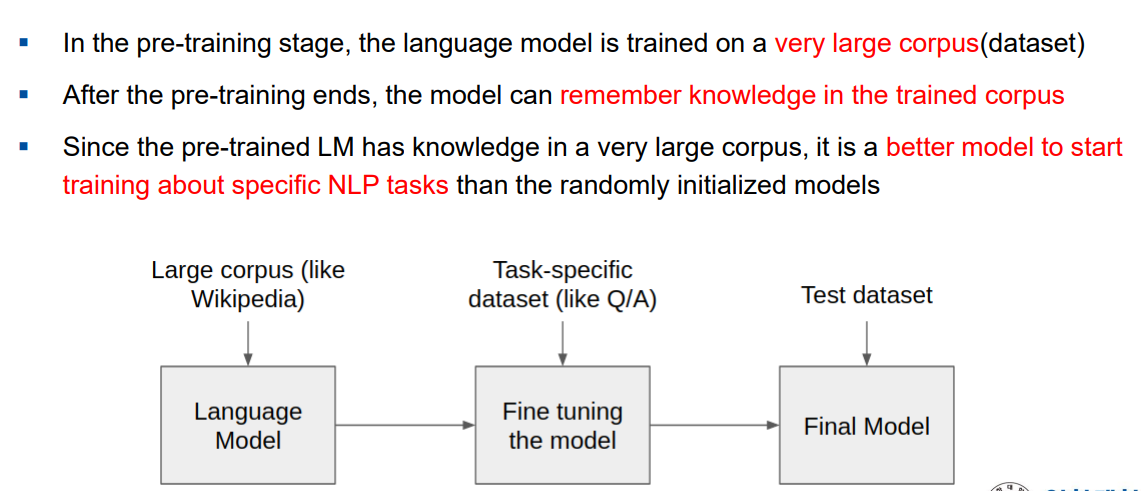
Pre-trained LM
- 사전학습 언어모델(Pre-trained Language Model)
- 주어진 입력에 대해 다음으로 올 단어가 무엇일지 확률분포를 예측해주는 모델
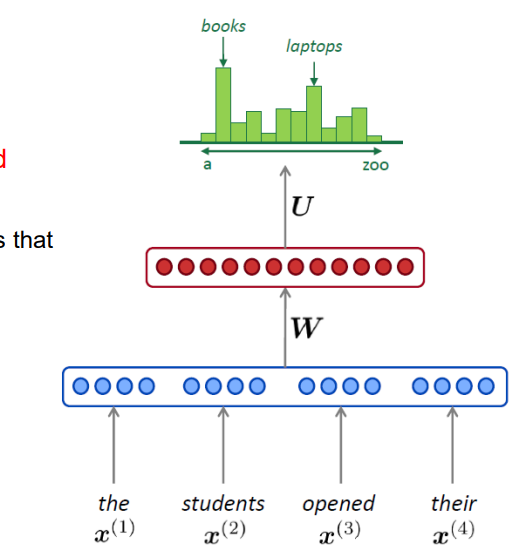
위 예제에서는 book 이 다음 단어로 올 확률이 가장 높다고 예측 및 판단해주는 것이다.
- vocab : 예측되는 모든 단어집합
-
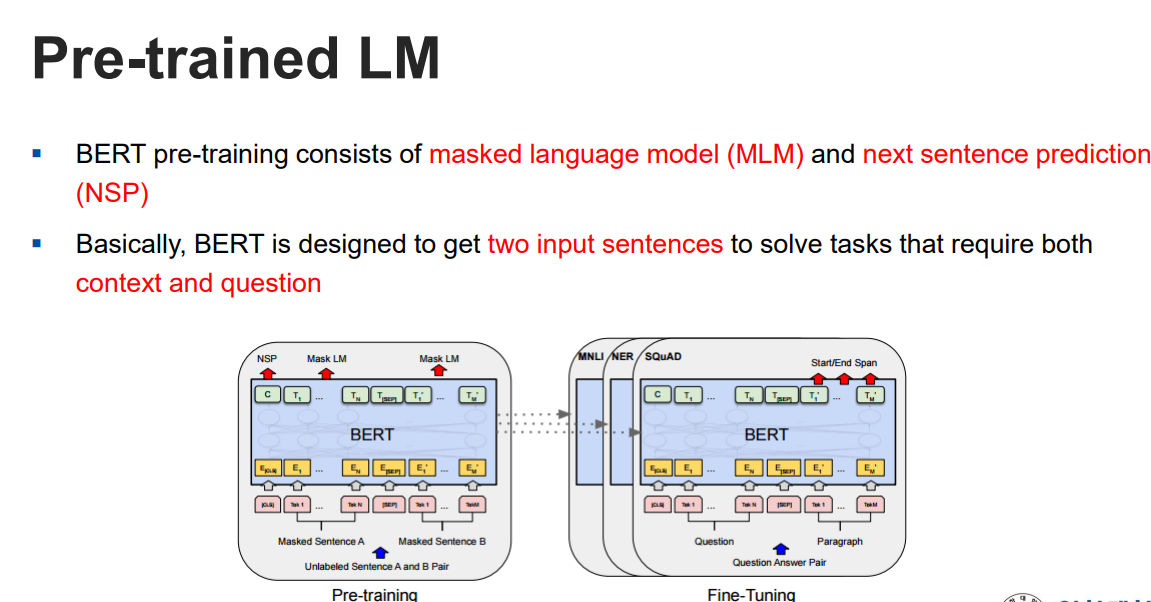
MLM
-
NSP
- MLM(Masked language Model) : 기존 language 모델(그냥 LM) 은 맨 마지막 단어를 보고 다음 단어를 예측하는 것이였다면, 이 모델은 다음 단어가 아닌 중간에 문맥상 적절하게 들어갈 단어를 예측하는 것이다.
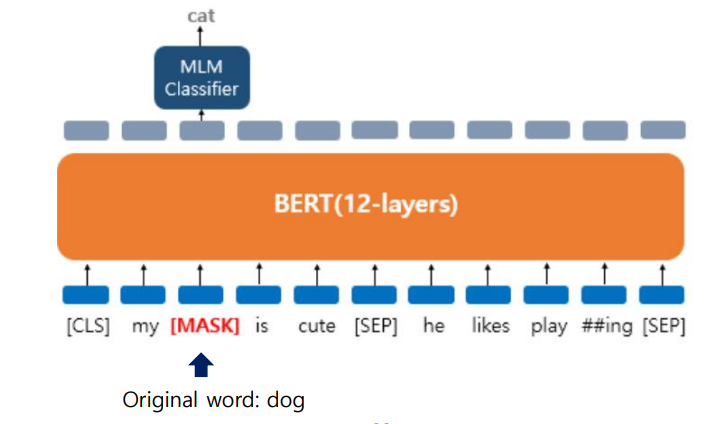
- NSP(Next sentence prediction) : 인풋으로 들어온 2개의 문장이 서로 이어지는 문장인지 아닌지를 판별 및 예측해줌
Base 기반의 감정분석
- Yelp dataset 을 기반으로 감정을 분석할 것이다.

불러온 dataset 을 출력해보면 아래와 같다.

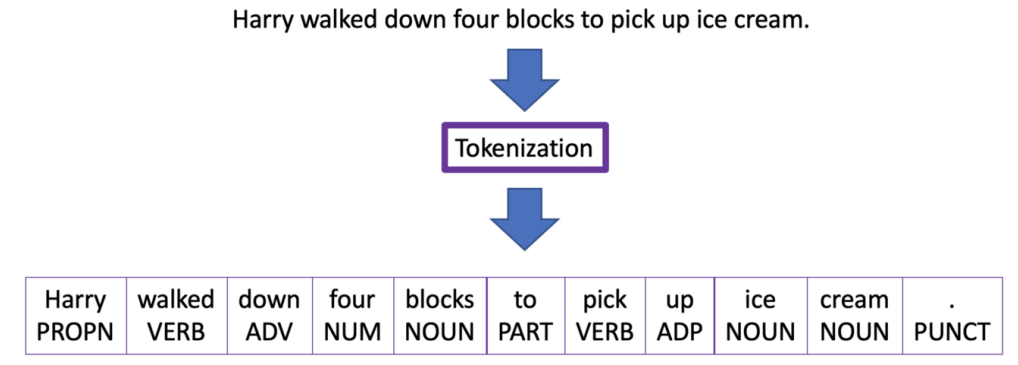
- tokenizer : word(단어) 또는 subword(접두사, 접미사 등) 을 잘개 짤라서 토큰화 시킨것
위 예제처럼 Harry walked ~~ 문장을 Tokenization 을 통해 잘개 쪼개서 리스트로 만들어줬다.
- Tokenization 방식은 모델마다 다르다.
Fine-tuning using a pre-trained LM


- AutoTokenizer 의 from_pretained 를 통해 사전학습된 bert-base-cased 라는 모델을 사용한다.

tokenizer(exmaples["text"], ~~~) : tokenizer 로 토큰화를 하는것. 즉 각 문장들이 단어별로 잘개잘개 쪼개져서 토큰화된다.


- dataset 의 크기가 너무 크니까, 조금만 적당량의 data들로 학습시키도록 데이터를 1000개만 들고왔다.

small_train_dataset[0]['input_ids'] : 사전에서 몇번째에 있는 단어인지 인덱스 값을 보유하고 있다.
=> tokenizer.convert_ids_to_tokens() : 인덱스 값들에 해당하는 단어들을 토큰으로 변환한다.
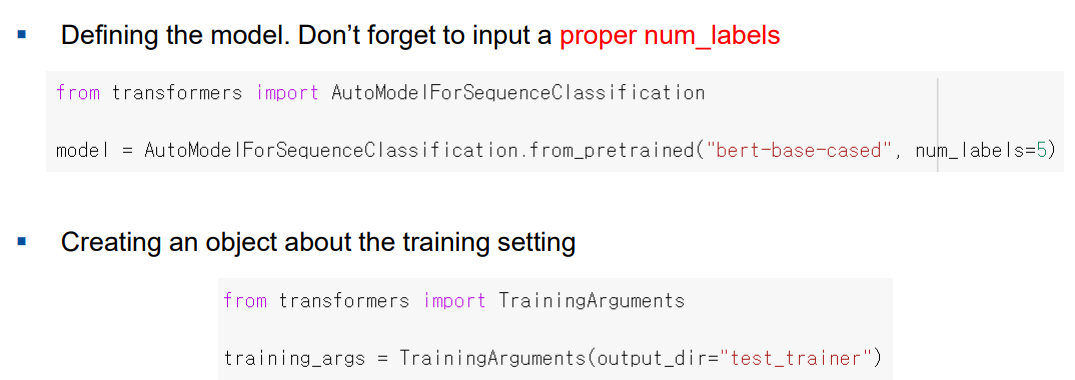
-
bert-base-cased : 기존 모델을 불러온다.
=> from_preptained 로 부터 기존 모델을 불러온다. -
num_labels : 몇개의 클래스에 대해서 분류할 것 인지 개수를 지정
-
TrainingArguments() : 학습에 관한 설정을 해주는 것

- 정확도 확인 (중요x!)

-
Trainer() 객체 : 학습해주는 객체
-
trainer.train() : 생성한 Trainer 객체로 훈련시킴
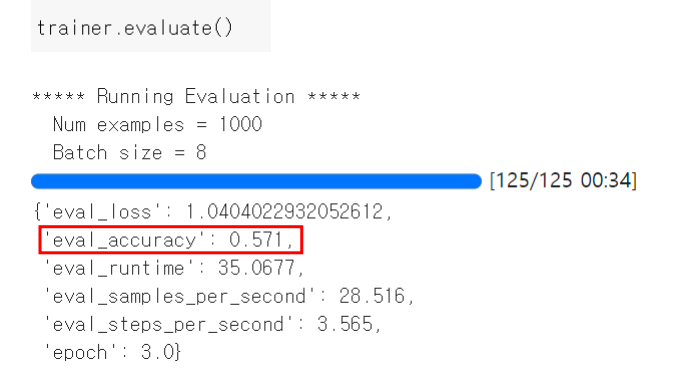
- trainer.evluate() : 성능 평가
