
현재 포스트는 블로그 테마 Haon Blog 로 이전되었습니다.이전된 글은 이곳 에서 읽을 수 있습니다. 🙂
시작에 앞서
여러 프로세스가 공유하는 동일한 자원을 동일자원이라고 하며, 또 그러한 여러 프로세스가 접근하여 생기는 경쟁 상황(race condition) 을 동시성 문제(Concurrency Problem) 이라고 합니다.
보통 스프링부트와 같은 멀티 쓰레드 기반의 환경에서 자주 발생하는 문제인데, 저도 최근 학습을 진행하다 직면하게 된 이슈입니다. 보통 동시간대에 대규모의 요청 및 트래픽을 처리하는 상황에 발생하는 문제이죠. 이는 무엇이며, 어떻게 해결할 수 있는것인지 자세하게 알아봅시다.
경쟁 상황(Race Condition)
[Redis] CS 와 함께 뜯어보며 이해하는 Redis : 내부 구조와 동작원리에 대해 에서도 설명했듯이, 멀티 쓰레드 환경에서는 충분히 경쟁상황이라는 것이 발생할 수 있다고 했습니다. race condition 이란 동시에 여러개의 프로세스가 하나의 공유자원(데이터)에 대해 접근하여 Read, Write 연산을 진행하면서 발생하는 경쟁 상황을 의미합니다.
그리고 이러한 상황을 동시성 이슈(Concurrency Problem) 이라고 하는 것이죠. 스프링 기반의 웹 애플라케이션은 이러한 동시성 이슈가 발생하지 않도록 별도의 처리가 필요할겁니다.
- 공유 자원 : 여러 프로세스가 공통으로 이용하는 변수, 메모리등을 의미
=> 공동으로 이용되기 때문에 누가 언제 데이터를 읽고 쓰는가에 따라 그 결과값이 달라질 수 있다.
- 경쟁 상황 : 2개 이상의 프로새스가 공유 자원을 동시에 읽거나 쓰는 상황
임계 구역(Critical Section)
이러한 동시성 이슈, 즉 여러 프로세스의 동기화에 관한 이슈는 임계구역(Critical Section) 영역에서 부터 시작합니다.
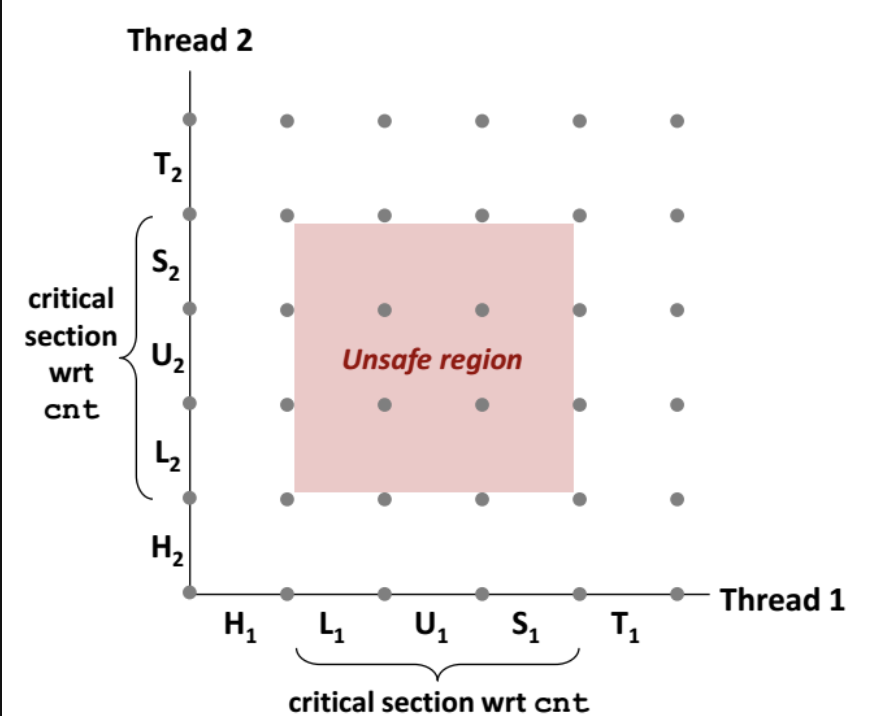
임계구역(Critical-Section)
임계구역(Critical-Section) 이란 둘 이상의 스레드가 동시에 접근해서는 안 되는 공유 자원에 접근하는 일부 코드내용을 말합니다.
각 프로세스는 본인만의 임계 구역(Critical Section) 이라는 부분의 코드 영역을 소유하고 있습니다. 한 프로세스에 대한 임계영역에 대해서는 본인(프로세스)만 진입하여 공유자원에 대해 연산을 진행할 수 있는것이 아니라, 다른 프로세스도 임계영역에 진입하여 공유자원에 대해 접근 및 연산이 진행가능합니다.
이떄 중요한것은 한 프로세스가 자신의 임계구역에서 수행하는 동안에는 다른 프로세스들은 그 프로세스에 대한 임계구역이 진입할 수 없다는 사실입니다. 즉, 동시에 두 프로세스는 그들의 임계 구역 안에서 실행할 수 없죠.
임계구역 문제 (Critical-Section Problem)
임계 구역 문제는 프로세스들이 데이터를 협력적으로 공유하기 위하여 자신들의 활동을 동기화할 때 사용할 수 있는 프로토콜을 설계하는 것입니다.
각 프로세스는 자신의 임계구역으로 진입하려면 진입 허가를 요청해야 하며, 이러한 요청을 구현하는 코드 부분을 진입 구역(entry section) 이라고 합니다. 또 임계구역 뒤에는 나머지 구역(remainder section)이라고 부릅니다.
경쟁 조건은 프로세스가 공유 자원(데이터) 에 대해 동시간대에 접근할 때 race condition 이 발생할 수 있다. 그리고 이러한 경쟁 조건으로 인해 공유 자원의 값이 손실될 수 있습니다.
- 임계구역은 공유자원에 조작될 수 있으며, 경쟁 조건이 발생할 수 있는 코드 영역입니다.
- 임계구역 문제는 데이터를 협력적으로 공유하기 위하여 자신의 호라동을 동기화하는 프로토콜을 설계하는 것입니다.
synchronized
스프링부트 프레임워크를 기준으로는, 동기화 환경을 제공하도록 synchronized 라는 키워드를 제공합니다. 예를들어 아래와 같이 진행할 경우, 하나의 프로세스 아래에선 여러 쓰레드에 대한 요청을 정상적으로 동기화시켜주죠.
// @Transactional
public synchronized RegisterRes registerCourse(int courseIdx) {
CourseEntity courseEntity = courseRespository.findCourseEntityByCourseIdx(courseIdx);
courseEntity.setCurrentCount(courseEntity.getCurrentCount() + 1);
if(courseEntity.isOverFlow()){
throw new RuntimeException("마감 되었습니다");
}
courseRespository.save(courseEntity);
return new RegisterRes(courseEntity.getCurrentCount());
}synchronized 를 이용하면, 현재 접근하고 있는 메소드에 하나의 쓰레드만 접근할 수 있도록 보장 및 동작합니다. 자바에서 지원하는 synchronized 는 현재 사데이터를 사용하고 있는 해당 쓰레드를 제외하고 나머지 제외 쓰레드들은 데이터 접근을 막아서, 쓰레드 하나씩 순차적으로 데이터에 접근할 수 있도록 해줍니다.
그러나 문제점은 애플리케이션을 단 하나만 띄운다면 전혀 무관하지만, 서버가 여러대일 경우 여러개의 인스턴스가 존재하는 것과 동일하기 떄문에 실질적인 운영 환경에서는 데이터의 정합성을 보장할 수 없습니다.
다중 프로세스(서버) 에서는 synchronized 으로도 동시성 이슈를 해결할 수 없다!
분산 락 (Distributed lock)
드디어 본격적으로 분산 락에 대해 설명을 드리네요. 분산락이란 경쟁 상황(Race Condition) 이 발생할때, 하나의 공유자원에 접근할때 데이터에 결함이 발생하지 않도록 원자성(atomic) 을 보장하는 기법입니다.
분산락을 구현하기 위해서 Redis 는 RedLock 이라는 알고리즘을 제안하며, 3가지 특성을 보장해야 한다고 말하고있죠.
- 오직 한 순간에 하나의 작업자만이 락(lock) 을 걸 수 있다.
- 락 이후, 어떠한 문제로 인해 락을 풀지 못하고, 종료된 경우라도 다른 작업자가 락을 획득할 수 있어야합니다.
- Redis 노드가 작동하는한, 모든 작업자는 락을 걸고 해체할 수 있어야합니다.
분산 락을 구현하기 위해서는 락에 대한 정보를 Redis에 저장하고 있어야합니다. 그리고 분산환경에서 여러대의 서버들은 공통된 Redis 를 바라보며, 자신이 임계영역(Critical Section) 에 접근할 수 있는지 확인합니다. 이렇게 분산 환경에서 원자성(atomic) 을 보장할 수 있게되죠.
이번 포스팅에서는 이 분산락이 발생하는 상황을 직접 발생시켜보고, 직접 분산락을 구현하며 어떻게 동시성 이슈를 해결할 수 있는지에 대해 설명하겠습니다.
동시성 이슈(Concurrency Issue) 상황 가정
저희는 다음과 같이 동시성 이슈가 발생하는 상황을 직접 만들어볼겁니다.
동시성 이슈가 발생하는 상황은 곧 짧은시간대에 대규모 트래픽(요청)이 오는 경우일 것이고, 대표적으로는 대학교 수강신청을 떠올리 수 있습니다.
저희는 동시간대에 몰리는 수강신청 상황을 가정해보고, 동일한 자원(수업)에 대해 수강신청하며 발생하는 동시성 문제를 직접 접해볼겁니다.
그리고 해당 애플리케이션에서 발생한 문제를 Redis 를 활용한 분산락으로 해결해보는 과정까지 모두 다루어보겠습니다.
- 인프라 서버 : 인스턴스가 2대를 띄운 상황을 가정
- MySQL 에 수업에 대한 더미데이터를 미리 채워놓은 상황. 또 인프라에 Redis 서버를 이미 띄운 상황입니다.
Course Entity
우선 수업에 대한 엔티티입니다. 수업명, 수강신청 제한수(countLimit), 현재까지의 수강신청 인원수(currentCount) 로 구성해줬습니다.
이때 실무과 동일한 정확한 수강신청 서비스를 개발하기 위해선 User 엔티티까지 만드는것이 맞으나, 저희는 수많은 쓰레드가 currentCount 값을 증가시키는 것만 간단히 확인하도록 하겠습니다. (이게 핵심은 아니므로)
@Entity
@Table(name = "Course")
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter @Setter @Builder
public class CourseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int courseIdx;
private String courseName;
private int countLimit;
private int currentCount;
public boolean isOverFlow() {
return currentCount > countLimit;
}
}
CourseController
컨트롤러에서는 아래와 같이 수업에 대한 Id 값, 즉 수업에 대한 ID 값을 입력받고 증가하는 것에 대해 처리해두었습니다.
@RestController
@RequestMapping("/course")
public class CourseController {
private final CourseService courseService;
@Autowired
public CourseController(CourseService courseService){
this.courseService = courseService;
}
@ResponseBody
@PostMapping("/registration/{courseIdx}")
public ResponseEntity<RegisterRes> registerCourse(@PathVariable("courseIdx") int courseIdx) throws InterruptedException{
RegisterRes registerRes = courseService.registerCourse(courseIdx);
return ResponseEntity.created(URI.create("/course/registration/"))
.body(registerRes);
}
}
EnableJpaRepositories
레포지토리는 아래와 같이 구성했으나, findCourseEntityByCourseIdx 메소드의 경우는 Spring Data JPA 에서 제공해주는 findById() 메소드를 사용해도 전혀 무관합니다.
@EnableJpaRepositories
public interface CourseRespository extends JpaRepository<CourseEntity, Integer> {
// @Lock(LockModeType.PESSIMISTIC_WRITE)
CourseEntity findCourseEntityByCourseIdx(int courseIdx);
}CourseService
서비스단입니다. 이때 앞서 CourseEntity 에서 정의한 isOverFlow 메소드를 통해 수강신청 인원이 초과했는지를 검증합니다. 또 @Transactional 어노테이션으로 트랜잭션으로 연산 단위를 묶었다는 점 인지하고 넘어갑시다.
@Service
public class CourseService {
private final CourseRespository courseRespository;
private final RedisLockRepository redisLockRepository;
@Autowired
public CourseService(CourseRespository courseRespository, RedisLockRepository redisLockRepository){
this.courseRespository = courseRespository;
this.redisLockRepository = redisLockRepository;
}
@Transactional
public RegisterRes registerCourse(int courseIdx) {
CourseEntity courseEntity = courseRespository.findCourseEntityByCourseIdx(courseIdx);
courseEntity.setCurrentCount(courseEntity.getCurrentCount() + 1);
if(courseEntity.isOverFlow()){
throw new RuntimeException("마감 되었습니다");
}
courseRespository.save(courseEntity);
return new RegisterRes(courseEntity.getCurrentCount());
}
}쓰레드 100개 생성 및 동시성 요청
Jmeter 로 동시간대에 100개의 요청을 생성하고, 동시간대에 요청을 보내도록 했습니다. 혹시 Jmeter 를 사용하는 방법이 궁금하신 분들은 JMeter 무작정 따라해보기(Windows) 와 [Spring] JMeter 사용법 - JMeter란?, 테스트 방법 를 참고하시면 되겠습니다.
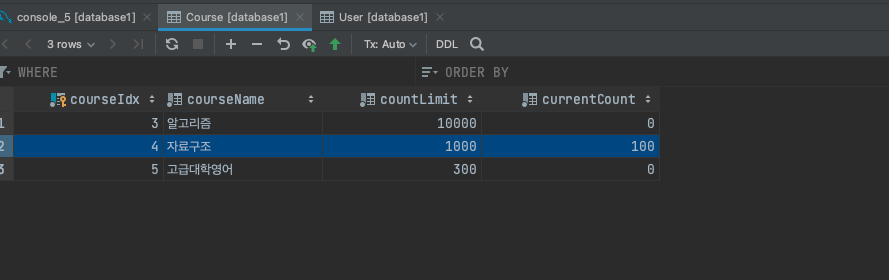
open /opt/homebrew/bin/Jmeter // Jmeter 실행RDB 에 저장해둔 수업 목록은 다음과 같고, 저희는 ID 값이 4인 자료구조 수업에 대해 쓰레드 100개를 생성하고 동시간대에 요청을 보내도록 하겠습니다.
Jmeter 에서 보낸 요청 환경구성은 아래와 같습니다.
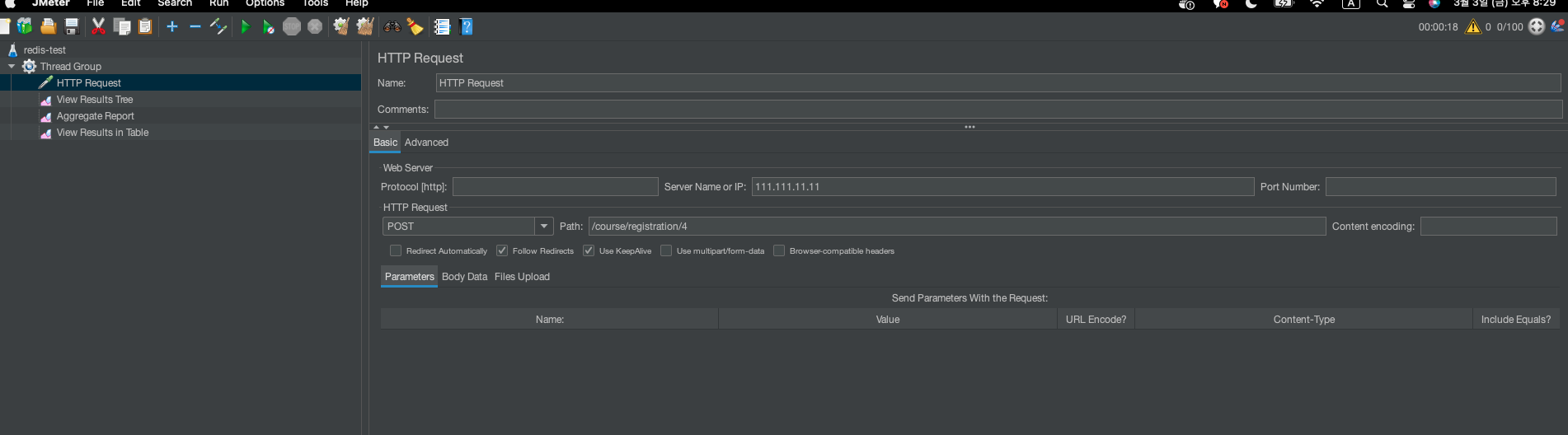
동시성 이슈 발생
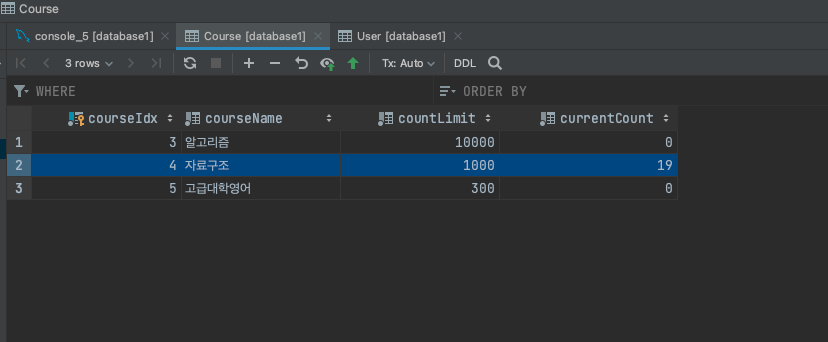
분명 100개의 요청을 보냈음에도 불구하고, currentCount 의 값이 100이 아닌 19밖에 되지 않았습니다. Race Condition 으로 인해 동기화 문제가 발생한 것입니다. 즉 동시성 이슈가 발생한 것이죠.
앞서 언급했듯이, 이 문제는 단일 서버가 아니기 때문에 synchornized 로도 해결할 수 없습니다. 두 애플리케이션은 각각 별개의 프로세스로 동작하고 있기 때문입니다.
락(Lock)에 대해
저희는 Redis Client 중에 Lettuce 로 발생한 동시성 이슈를 해결해볼겁니다. 그전에 락과 관련한 이론들에 대해 다시 짚고 넘어갑시다.
락(Lock)
락이란 데이터베이스에서 사용하는 개념으로, 트랜잭션 처리의 순차성을 보장하기 위한 기법 중 하나입니다. 트랜잭션이란 DB의 나누어지지 않는 최소한의 처리 단위이며, 이러한 DB의 특징을 atomic 하다고 하는데, 쉽게말해 한번에 하나의 행동이 되는 것을 보장한다는 의미입니다.
락을 획득한다는 것은 자원을 사용해도 된다는 의미이며, 다른 프로세스는 현재 락을 획득한 프로세스가 잠금을 건 자원에 대해 사용할 수 없음을 의미합니다. 이런식으로 순차성으로 보장하는 것이죠/
스핀 락(Spin Lock)
락을 걸지 못하면 무한루프를 돌면서 계속 락을 얻으려고 시도하는 동기화 기법입니다. 락을 얻지 못할경우, 쉬지않고 계속 락을 얻으려고 시도합니다. 이 떄문에 락을 얻을때가지 계속 요청을 보내며 대기하므로 서버에 많은 부하를 주죠.
Redis Client
스핀락은 서버에 많은 부하를 주죠. Redis Client 인 Redisson, Lettuce 은 스핀 락을 적절한 주기로 적당량을 보내면서, 서버에 가는 부하를 줄이는 방식입니다.
이는 서버 측에서 구독한 클라이언트에게 "락을 사용해도 된다" 라고 알림을 주어서, 락의 획득 여부를 일일이 클라이언트가 요청해서 확인하지 않아도 되게 하는 기법입니다. 이로써 순수 스핀락을 구현해서 락을 얻어내는 방식보다 부하를 훨씬 줄이는 셈이죠.
Lettuce & SETNX 를 활용한 분산락 구현
분산락을 해결하기 위해서 저희는 Redis Client로는 Lettuce를 활용하겠습니다. build.gradle 의 dependencies 에 아래를 추가해줍시다.
implementation 'org.springframework.boot:spring-boot-starter-cache'지금부터 살펴본 방식은 스핀락을 적절히 활용해서 쓰레드들이 순차적으로 락을 획득하는 방식입니다.
락을 획득한다는 것은 "락이 존재하지는지 확인한다", "존재하지 않는다면 락을 획득한다" 이 두 연산이 atomic 하게 이루어 져야 합니다. 레디스는 "값이 존재하지 않으면 세팅한다" 라는 SETNX 명령어를 지원합니다. 이 SETNX 를 이용하여 레디스에 값이 존재하지 않으면 세팅하게 하고, 값이 세팅 되었는지 여부를 리턴 값으로 받아 락을 획득하는데 성공합니다.
이 방식을 통해 애플리케이션에서 스핀 락(spin lock)을 구현할 수 있습니다. 즉, 레디스 서버에 지속적으로 SETNX 명령을 보내어 임계 영역(Critical Section) 진입 여부를 확인하는 기법이죠.
RedisRepository
앞서 Redis Client 로 Lettuce 에 대한 의존성을 주입해줬다면, redisTemplate 를 활용해서 락을 관리하는 스프링 빈을 구현합시다.
@Component
public class RedisLockRepository {
private RedisTemplate<String, String> redisTemplate;
public RedisLockRepository(final RedisTemplate<String, String> redisTemplate){
this.redisTemplate = redisTemplate;
}
// setIfAbsent() 를 활용해서 SETNX를 실행함. 이때 key는 Course Entity 에 대한 ID값으로, Value 를 "lock" 으로 설정한다.
public Boolean lock(final int key){
return redisTemplate.opsForValue()
.setIfAbsent(String.valueOf(key), "lock", Duration.ofMillis(3_000));
}
public Boolean unlock(final int key) {
return redisTemplate.delete(String.valueOf(key));
}
}CourseService 성능 개선
그리고 기존 CourseService 코드를 개선해서 분산 락을 적용해줍시다. while 문이 없었다면 스핀락 방식으로써 서버에 부하를 주었겠지만, 앞서 구현한 RedisLockRepository 를 활용해서 while 문을 활용해서 락을 획득할때마다 무한 반복을 돌도록 구현했습니다.
(몰론 스핀 락 방식을 어느정도 활용해서 서버에 조금은 부하가 가긴합니다.)
Redis 서버에 부하를 덜기위해 100ms 를 쉬어주고, Critical Section 에 진입후 수강신청에 대한 로직을 처리후 finally 블럭으로 락을 해제해줍니다. 이때 락을 해제해주지 않으면 다른 쓰레드에서 Critical Section 에 진입하므로 주의해줍시다.
또한 @Transactional 어노테이션을 제거한 모습을 볼 수 있습니다. Redis Client 는 @Transcational과 동시에 동작하지 않기 때문입니다.
@Service
public class CourseService {
private final CourseRespository courseRespository;
private final RedisLockRepository redisLockRepository;
@Autowired
public CourseService(CourseRespository courseRespository, RedisLockRepository redisLockRepository){
this.courseRespository = courseRespository;
this.redisLockRepository = redisLockRepository;
}
public RegisterRes registerCourse(int courseIdx) throws InterruptedException {
while (!redisLockRepository.lock(courseIdx)) {
Thread.sleep(100);
}
try {
CourseEntity courseEntity = courseRespository.findCourseEntityByCourseIdx(courseIdx);
courseEntity.setCurrentCount(courseEntity.getCurrentCount() + 1);
if (courseEntity.isOverFlow()) {
throw new RuntimeException("마감 되었습니다");
}
courseRespository.save(courseEntity);
return new RegisterRes(courseEntity.getCurrentCount());
} finally {
redisLockRepository.unlock(courseIdx);
}
}
} 실행결과
이렇게 분산 락을 적용시 정상적으로 동시성 이슈가 해결된 모습을 볼 수 있습니다!
Redisson
다음으로는 Redisson 를 활용해서 구현해보겠습니다. 이 방식은 앞선 Lettuce 를 활용한것과 달리, 스핀 락 방식을 전혀 활용한 방식을 직접 구현하지 않아도됩니다. 그저 의존성을 추가하고 간단히 적용하면 끝이죠.
Redisson은 pubsub 기능을 사용하여 스핀 락이 레디스에 주는 엄청난 트래픽을 줄였습니다. 락이 해제될 때마다 subscribe하는 클라이언트들에게 “너네는 이제 락 획득을 시도해도 된다” 라는 알림을 주어서 일일이 레디스에 요청을 보내 락의 획득가능여부를 체크하지 않아도 되도록 개선했습니다.
implementation 'org.redisson:redisson-spring-boot-starter:3.17.7'CourseService 리팩토링
RedissonClient 의 getLock() 으로 락을 획득하고, tryLock() 을 통해 락 획득을 시도합니다.
public CourseService(final CourseRespository courseRespository, RedissonClient redissonClient){
this.courseRespository = courseRespository;
this.redissonClient = redissonClient;
}
public RegisterRes registerCourse(Long courseIdx){
RLock lock = redissonClient.getLock(String.valueOf(courseIdx));
try{
boolean available = lock.tryLock(100 ,2, TimeUnit.SECONDS);
int newCourseIdx = Math.toIntExact(courseIdx);
if(!available){
throw new RuntimeException("Lock 획득 실패!");
}
// 비즈니스 로직
CourseEntity courseEntity = courseRespository.findCourseEntityByCourseIdx(newCourseIdx);
courseEntity.setCurrentCount(courseEntity.getCurrentCount() + 1);
if (courseEntity.isOverFlow()) {
throw new RuntimeException("마감 되었습니다");
}
courseRespository.save(courseEntity);
return new RegisterRes(courseEntity.getCurrentCount());
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
} 마치며
이로써 Redis 를 통한 분산락 구현방법을 알아보고, 이 방법으로 동시성 트래픽을 오차없이 처리하는 방법에 대해 알아봤습니다.
추후에는 데이터베이스 락, 낙관적/비관적 락등 다양한 이슈와 기법에 대해 다루어볼까합니다.
참고
자바에서 동시성을 해결하는 다양한 방법과 Redis의 분산락
분산 락을 사용하여, 동시성 문제 해결하기
Redis로 분산 락을 구현해 동시성 이슈를 해결해보자!
redis 설치 및 redisson을 이용한 분산락 구현
[OS] 프로세스 동기화(Process Synchronization)
락이란? 분산락, 스핀락의 개념
레디스와 분산 락(1/2) - 레디스를 활용한 분산 락과 안전하고 빠른 락의 구현
동시성 문제 해결하기 V3 - 분산 DB 환경에서 분산 락(Distributed Lock) 활용
분산락 (Distributed lock)



레디슨 락 직관적이고 쓰기 편해서 애용합니다. 포스트 잘 봤습니다 감사합니다!