
0. 이 글을 쓰는 이유
이전 글에서 비관적 락(Pessimistic Lock)을 통해 동시성 문제를 해결해보았다.
단일 DB 환경이라면 비관적 락(Pessimistic Lock)을 사용해서 문제될게 없다.
하지만 분산 DB 환경이라면 비관적 락(Pessimistic Lock)을 통해 동시성 문제를 해결할 수 없다.
그래서 분산 DB 환경이라고 가정하고, 분산 락(Distributed Lock)을 통해 동시성 문제를
해결해본다. 이전 글을 보지 않더라도 이해할 수 있도록, 중복된 내용이 다소 포함되어 있다.
1. 현재 상황
1-1. 동시성 이슈
1-1-1. 모임 참여시 호출되는 메서드
@Transactional
public ClubParticipateResponse participateClub(Long clubId, Account loginAccount) {
Club findClub = clubRepository.findClubDetailByIdWithLock(clubId).orElseThrow(EntityNotFoundException::new);
List<Pet> findPets = petRepository.findPetsByAccountId(loginAccount.getId());
ClubParticipateResponse response = validator.participationValidate(findClub, findPets, loginAccount);
response.setClubId(findClub.getId());
if (!response.isEligible()) {
return response;
}
AccountClub accountClub = AccountClub.of(loginAccount, findClub);
accountClubRepository.save(accountClub);
findClub.addAccountClub(accountClub);
if (isFullClub(findClub)) {
findClub.updateStatus(ClubStatus.PERSONNEL_FULL);
}
return response;
}
---
@Override
public Optional<Club> findClubDetailById(Long clubId) {
AccountClub findAccountClub = queryFactory
.selectFrom(accountClub)
.innerJoin(accountClub.account, account).fetchJoin()
.innerJoin(accountClub.club, club).fetchJoin()
.innerJoin(club.eligiblePetSizeTypes).fetchJoin()
.leftJoin(club.eligibleBreeds).fetchJoin()
.where(club.id.eq(clubId))
.fetchFirst();
return Optional.ofNullable(findAccountClub.getClub());
}1-1-2. 데드락 발생
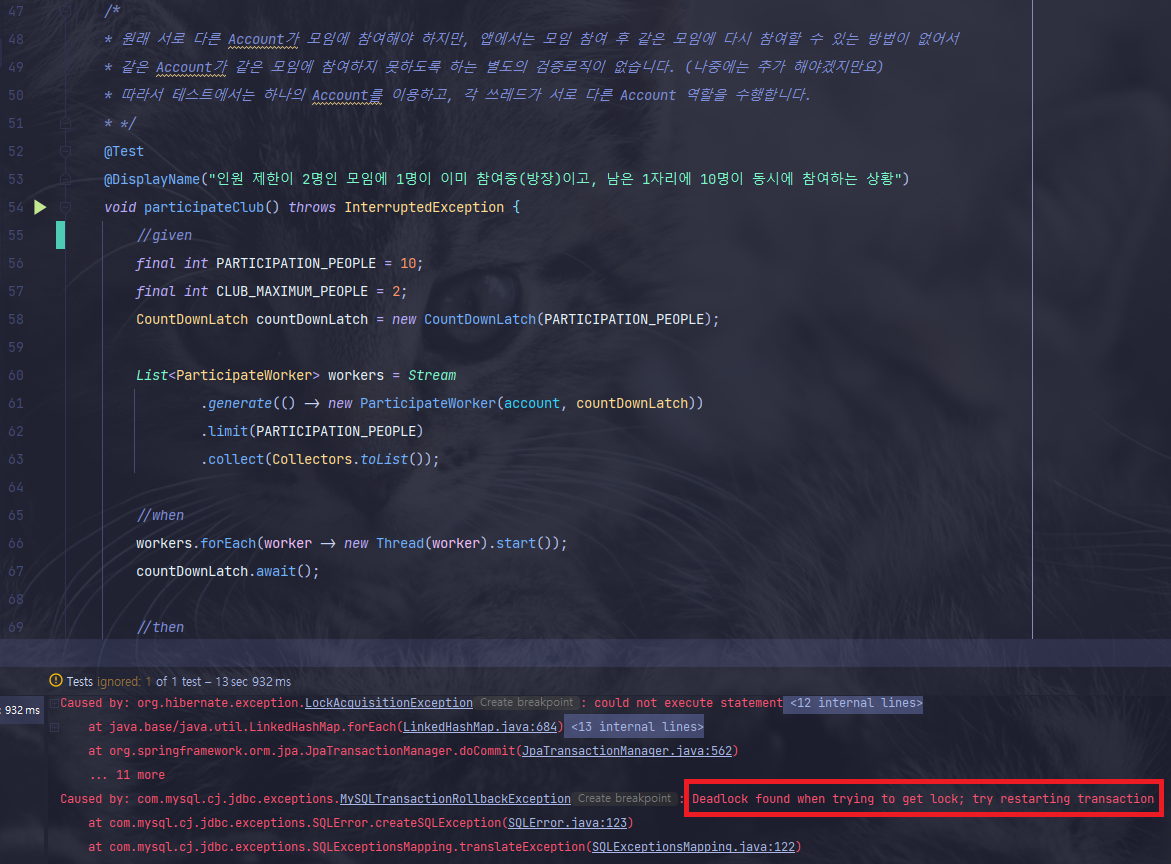
1-2. 비관적 락(Pessimistic Lock)을 통해 해결
@Override
public Optional<Club> findClubDetailById(Long clubId) {
AccountClub findAccountClub = queryFactory
.selectFrom(accountClub)
.innerJoin(accountClub.account, account).fetchJoin()
.innerJoin(accountClub.club, club).fetchJoin()
.innerJoin(club.eligiblePetSizeTypes).fetchJoin()
.leftJoin(club.eligibleBreeds).fetchJoin()
.where(club.id.eq(clubId))
.setLockMode(LockModeType.PESSIMISTIC_WRITE) // Lock 적용!
.fetchFirst();
return Optional.ofNullable(findAccountClub.getClub());
}- 비관적 락을 통해 데드락 및 동시성 문제를 해결했다.
1-3. 현재 서버 아키텍처
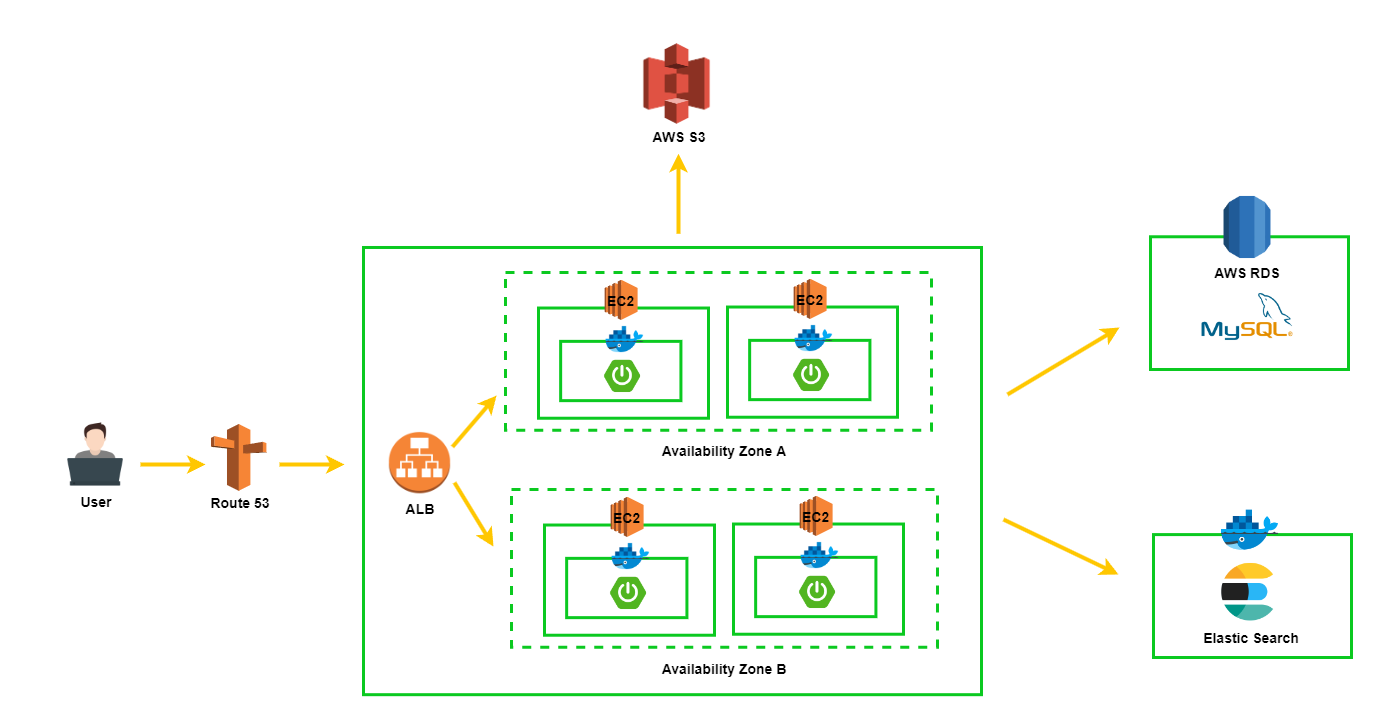
- 현재는 위 그림처럼 하나의 RDB만 존재한다.
- 그래서 비관적 락을 통해 문제를 해결할 수 있었다.
1-4. 만약 분산 DB 환경이라면?
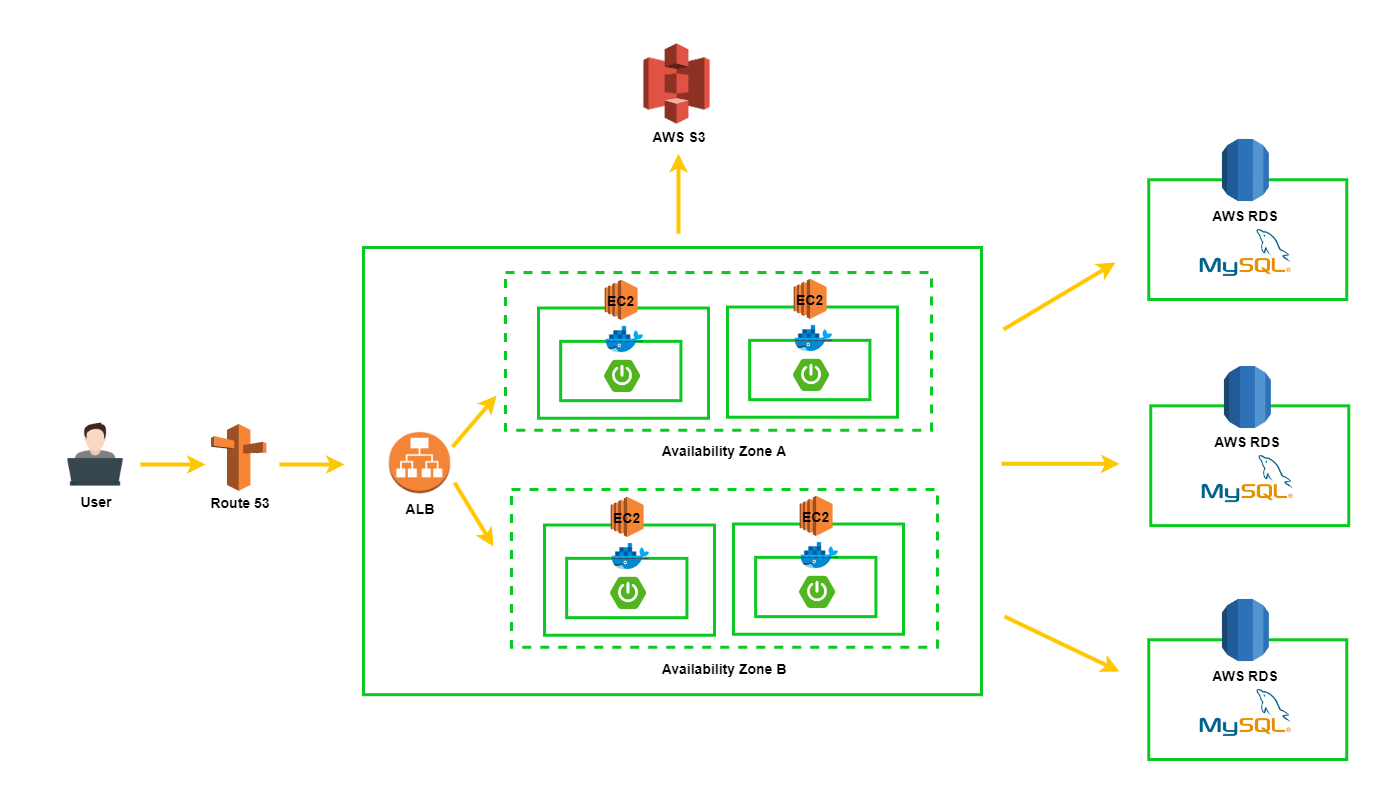
-
이처럼 여러 RDB가 분산되어 있는 환경이라면 비관적 락(Pessimistic Lock)으로도 동시성 문제를 해결할 수 없다는 것이다.
-
예로 모임 참여 요청이 들어와서 1번 DB의 데이터에 Lock을 걸어도, 또 다른 요청이 들어와서 2,3번 DB에 있는 데이터에 접근할 수 있기 때문이다.
-
이렇게 DB가 분산되어있는 환경이라면, DB로 가는 요청을 단일진입점으로 만들고 순차적으로 요청을 처리한다면 해결할 수 있지 않을까?
-
이럴 때 사용할 수 있는게 분산 락(Distributed Lock)이다.
-
참고로 당연한 얘기일 수 있지만 단일 DB환경에서도 분산 락(Distributed Lock)을 사용할 수 있다. 꼭 분산 DB 환경에서만 사용할 수 있는 개념이 아니라는 점을 이야기 하고 싶다.
2. 분산 락(Distributed Lock)이란?
-
분산 락(Distributed Lock)은 서로 다른 프로세스가 상호 배타적인 방식으로 공유 리소스와 함께 작동해야 하는 많은 환경에서 유용한 Lock이다. 참고 링크
-
많은 글들에서 서버가 분산되어 있는 경우 사용한다고 되어 있어서 조금 헷갈렸는데
락들에 대한 내 생각을 간단히 정리하면 아래와 같다.-
분산 서버 + 싱글 DB
- 낙관적 락(Optimistic Lock) OR 비관적 락(Pessimistic Lock) OR 분산 락(Distributed Lock) 사용 가능
- 이 경우 보통 제일 유연한 낙관적 락(Optimistic Lock) 사용
- 이전 글에서 처럼 데드락이 발생하는 경우 비관적 락(Pessimistic Lock)으로 해결
-
분산 서버 + 분산 DB
- 분산 락(Distributed Lock) 사용 가능
-
즉 분산락(Distributed Lock)은 애플리케이션 서버나, DB 서버가 분산되어 있을 때 사용하는 Lock 이라고 할 수 있다.
2-1. 일관성
- Redis의 분산 락은 일관성을 보장하지 못한다.
- 대부분의 비즈니스에서 데이터의 일관성이 깨지는 것은 치명적이다. 따라서 사용에 주의하자.
- 보다 자세한 내용을 알고싶다면 링크를 참고하자.
3. 분산락 구현 방법
3-1. 여러 방법들
분산 락(Distributed Lock)은 Lock 리소스 보안에 따라 크게 두 가지로 나눌 수 있다.
- 비동기 복제 기반 분산 시스템 ex) MySQL, Redis, Tair
- Paxos 기반 분산 합의 시스템 ex) ZooKeeper
1번 방법은 2번 방법에 비해 데이터 손실 위험이 있다. 그래서 TTL 메커니즘을 통해 세분화된 Lock을 제공한다. 다른건 잘 모르겠지만 Redis의 Redisson은 자체 TTL 메커니즘을 제공한다.
2번 방법은 합의 프로토콜을 통해 여러 데이터 복사본을 보장하고 높은 데이터 보안성을 제공한다. 일반적으로 세션 메커니즘을 사용하고, 오랜 기간 Lock을 가지고 있으며 데이터 손실 위험이 비교적 적다.
-
MySQL에서도 분산 락(Distributed Lock)을 구현할 수 있다. 이미 MySQL을 메인 RDB로 사용중이므로 Redis나 Zookeeper와 같은 추가 인프라 구축 비용 없이 분산락을 구현할 수 있는 장점이 있지만 DB가 분산되어 있는 경우라면 역시 사용할 수 없다.
-
1-4에서 이야기했듯이 리소스에 Lock을 가지고 있어도, 다른 DB의 같은 리소스에는 접근 가능하기 때문에, DB로 가는 요청을 단일 진입점으로 만들 수 있는 무언가가 필요하다.
-
구현방식이 간단하고 성능이 가장 좋으면서, 참고할 레퍼런스가 많은 Redis를 이용해서 분산 락(Distributed Lock)을 구현하고자 한다.
3-2. redis 자바 클라이언트
-
JAVA용 레디스 클라이언트 라이브러리는 Jedis, Lettuce, Redisson 등이 있다.
-
이 글에서는 redisson에서 쓴글이라 당연히 redisson이 좋다고 이야기 하긴 하지만
중요한점은 Lettuce와 Redisson이 제공하는 Lock 기능에 다른점이 있다.
3-2-1. Lettuce
-
Lettuce는 스핀락(Spin Lock)을 사용한다.
-
스핀락(Spin Lock)은 Lock이 없는 프로세스는 Lock을 획득하기 위해 무한루프를 돌게된다.
-
무한루프를 돌면서 CPU를 쓸데없이 낭비하게 되기 때문에, 성능 저하로 이어질 수 있다.
-
그럼 이런 쓸데없는것을 왜 만들었나 싶겠지만, 코어가 여러개인 경우 유용하다.
Lock을 얻기 위해 계속 무한루프를 돌다가, Lock을 얻으면 컨텍스트 스위칭 필요없이 바로 실행될 수 있기 때문이다. -
하지만 현재 상황에서는 해당하지 않는 이야기이므로 넘어가자. 중요한점은 성능 저하!
3-2-2. Redisson
-
스핀락(Spin Lock)을 사용하지 않고 pubsub 기능을 사용한다.
-
pubsub이란 마치 인터럽트처럼, Lock 획득을 기다리는 클라이언트에게 Lock 획득할 수 있다는 신호를 보내주는 것이다.
-
그래서 Lock 획득을 위해 무한루프를 돌 필요가 없다.
추가적으로 타임아웃 기능을 제공하고, Lua 스크립트를 사용한다는 장점이 있는데
이 내용은 해당 글을 참고하자.
또한 Redisson에서 제공하는 Lock은 굉장히 많다. Redisson Repository의 Wiki에 잘 정리되어 있다.
4. 분산락은 어떻게 동작할까?
자바기준으로 어떤 redis 자바 클라이언트를 사용하는지, redis 자바 클라이언트에서
제공하는 방법에따라 동작방식이 매우 다양하다.
따라서 일반적인 동작방식에 대해서만 간단히 알아보고, 필요한 내용은 문서를 참고하자.
- 기본적으로
SET명령과NX,PX옵션을 사용한다.
set {key} {value} NX PX 5000SET- 주어진 키에 값을 저장하는 명령어
NX옵션- DB에 이미 동일한 Key가 없는 경우에만 저장한다.
- 반환된 데이터가 “OK”인 경우 데이터 저장, “nil”인 경우 Key가 중복되어 데이터가 저장되지 않은 경우이다.
PX옵션- 지정한 밀리초 이후에 데이터가 자동으로 삭제된다.
5. 분산락(Distributed Lock) 구현
5-1. 의존성 추가
implementation 'org.redisson:redisson-spring-boot-starter:3.17.4'-
redisson 의존성을 추가한다.
-
추후에 Spring Data Redis를 사용할 예정이기 때문에, Spring Data Redis의 최신 버전인 2.7.2에 맞는 redission 3.17.4 버전을 추가한다.
5-2. 설정
@Configuration
public class RedissonConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port);
return Redisson.create(config);
}
}5-3. 구현
public ClubParticipateResponse participateClubWithDistributedLock(Long clubId, Account loginAccount) {
ClubParticipateResponse response;
RLock lock = redissonClient.getLock(PARTICIPATE_CLUB_LOCK_NAME); // 1
try {
if (FailureGetLock(lock)) { // 2
log.info("모임 참여 시 Lock 획득 실패");
throw new FailureGetLockException();
}
Club findClub = clubRepository.findClubDetailById(clubId).orElseThrow(EntityNotFoundException::new);
response = participateClub(loginAccount, findClub);
} catch (InterruptedException e) { // 3
throw new FailureGetLockException(e);
} finally {
lock.unlock(); // 4
}
return response;
}
private boolean FailureGetLock(RLock lock) throws InterruptedException {
return !lock.tryLock(WAIT_TIME, LEASE_TIME, TimeUnit.SECONDS); // 2
}
private ClubParticipateResponse participateClub(Account loginAccount, Club findClub) {
...
}-
participateClub()메서드는 1-1-1 코드와 같다. -
getLock()- Lock을 조회한다.
-
FailureGetLock()tryLock()메서드를 통해 Lock을 획득한다.- WAIT_TIME : Lock을 획득하기 위해 대기 하는 시간
- LEASE_TIME : Lock을 사용하는 시간, 해당 시간이 지나면 Lock을 반납한다.
- TiemeUnit.SECONNDS : 시간 단위를 초로 사용
-
InterruptedException- 쓰레드가 인터럽트 될 경우 해당 예외를 발생시키므로 예외처리가 필요하다.
-
lock.unlock()- Lock을 반납한다.
6. 테스트
6-1. 테스트 코드
/*
* 원래 서로 다른 Account가 모임에 참여해야 하지만, 앱에서는 모임 참여 후 같은 모임에 다시 참여할 수 있는 방법이 없어서
* 같은 Account가 같은 모임에 참여하지 못하도록 하는 별도의 검증로직이 없습니다. (나중에는 추가 해야겠지만요)
* 따라서 테스트에서는 하나의 Account를 이용하고, 각 쓰레드가 서로 다른 Account 역할을 수행합니다.
* */
@Test
@DisplayName("인원 제한이 2명인 모임에 1명이 이미 참여중(방장)이고, 남은 1자리에 10명이 동시에 참여하는 상황")
void participateClubTest() throws InterruptedException {
//given
final int PARTICIPATION_PEOPLE = 10;
final int CLUB_MAXIMUM_PEOPLE = 2;
CountDownLatch countDownLatch = new CountDownLatch(PARTICIPATION_PEOPLE);
List<ParticipateWorkerWithDistributedLock> workers = Stream
.generate(() -> new ParticipateWorkerWithDistributedLock(account, countDownLatch))
.limit(PARTICIPATION_PEOPLE)
.collect(Collectors.toList());
//when
workers.forEach(worker -> new Thread(worker).start());
countDownLatch.await();
//then
Club findClub = clubRepository.findById(CLUB_ID).get();
long participationAccountCount = findClub.getParticipants();
assertThat(participationAccountCount).isEqualTo(CLUB_MAXIMUM_PEOPLE);
}
private class ParticipateWorkerWithDistributedLock implements Runnable {
private Account account;
private CountDownLatch countDownLatch;
public ParticipateWorkerWithDistributedLock(Account account, CountDownLatch countDownLatch) {
this.account = account;
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
clubService.participateClubWithDistributedLock(CLUB_ID, account);
countDownLatch.countDown();
}
}-
테스트 코드는 이전과 같다.
-
인원제한인 2명인 모임에, 이미 1명(방장)이 참여중인 상황에서 10명이 동시에 참여 요청을 하는 테스트이다.
-
PARTICIPATION_PEOPLE값이 쓰레드의 개수를 의미하고, 각 10개의 쓰레드가 동시에 수행되면서 마치 동시에 요청이 온 것 처럼 테스트할 수 있다.
6-2. 테스트 결과
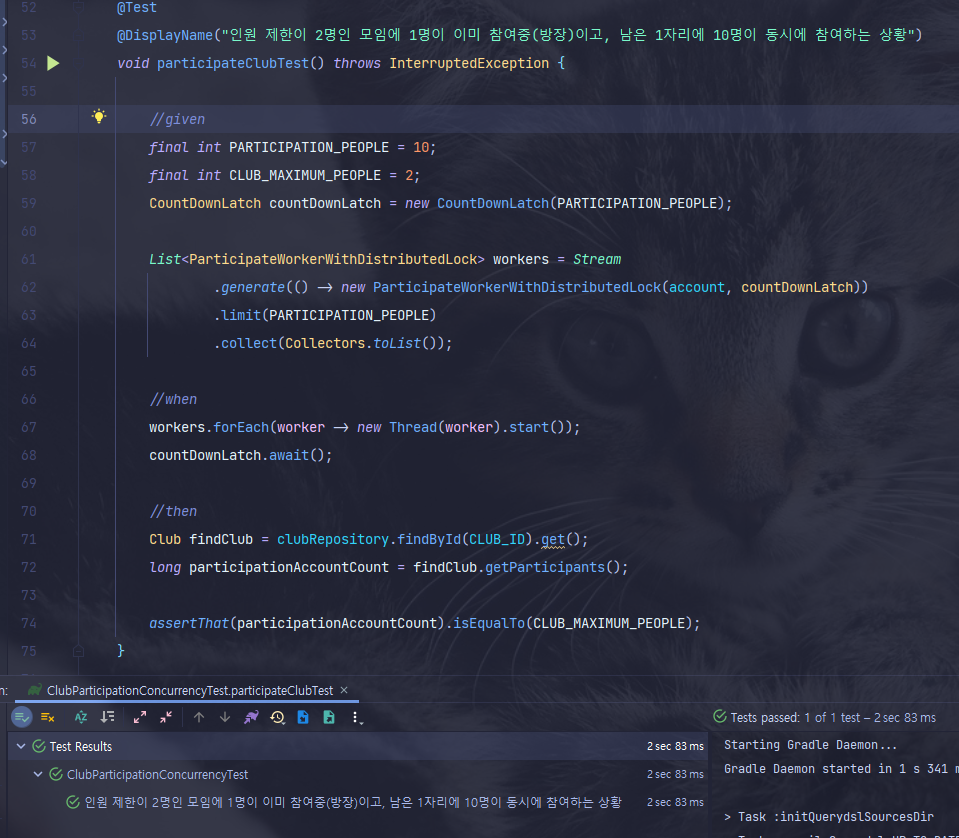

- 테스트도 통과하고, 실제로 DB에 2개의 데이터만 남아있는 걸 확인할 수 있다.
7. 마치며
동시성 이슈를 처리하기 위해 낙관적 락(Optimistic Lock)을 적용했다가, 처음으로 데드락을 만났다. 데드락이 발생한 이유를 알아보았고, 이를 해결하기위해 비관적 락(Pessimistic Ock)을 적용해서 해결할 수 있었다. 그리고 분산 DB 환경이라고 가정하고 Redis 분산 락(Distributed Lock)을 활용해보았다.
모두 마치고나서 든 생각은, Lock을 사용하는 방법은 매우 간단하다는 것이다.
정말 간단하게 잘 지원해주므로 누구나 쉽게 적용할 수 있다.
중요한 점은 Lock을 정말로 사용해야 하는 상황인지 판단하는 것과
어떤 Lock을 사용해서 해결해야 하는지 판단하는 능력인 것 같다.
이 글에선 분산락(Distributed Lock)을 정말 기본적인 형태로 구현했다.
만약에 여러 Redis 인스턴스를 띄워야 하는 경우라면 Redlock 이라는 키워드로
내용을 찾아보면 좋을 듯 하다. 또한 분산 락을 획득하는 과정은 횡단 관심사에 속한다.
즉 핵심 비즈니스 로직이 아니므로 AOP로 처리하는게 좋다. 참고할만한 링크는 아래 남겨두었다.
Ref

9개의 댓글

안녕하세요!! 너무 도움이 많이 되었습니다! 한 가지 궁금한게, 분산 서버 + 싱글 DB 환경에서도 낙관 락 사용이 가능하지 않을까요? 어쨌든 테이블에 Version이 반영된다면 다른 서버 간 트랜잭션에도 영향을 줄 수 있지 않을까 생각되었습니다..!


동시성 시리즈 잘 봤습니다 :)