
compgen
- 리눅스에서 수행 가능한 모든 명령어를 출력
compgen -c : 리눅스에서 수행 가능한 모든 명령어를 나열(출력)
compgen -a : 모든 alias (모든 별칭이 붙여진 명령어) 들을 나열
compgen -A function : 모든 함수들을 나열
compgen -b : 모든 built-in 명령어들을 나열
cf) built-in command 란? : bash 에서 이미 정의해 놓은 함수들 (shell 내부에 있는 함수 )
---
그 외 "compgen 옵션" 형태 => 기타 명령어들을 모두 나열
alias
- 명령어(command) 또는 특정 디렉토리에 대한 별칭을 붙여줌
alias : 모든 별칭을 출력
alias new_cmd = command : 기존 명령어 command 에 새로운 별칭 new_cmd 를 붙여줌
unalias nickname : 별칭(alias)인 nickname 을 제거예제

Shell function (함수)
함수 선언형태1 - 한줄로 정의하기
function-name(){ body; } -
주의) { body } 에서 { 와 body 사이에 공백문자를 꼭 줘야함!
-
body 의 내용으로 여러 command 내용이 들어갈텐데, 각 command 마다 세미콜론 ";" 으로 구분지어줘야 한다.
함수 선언형태2 - 여러줄에 걸쳐서 정의하기
function-name(){
body
...
}- 세미콜론없이 함수를 정의하면 된다.
예제

함수의 특수한 파라미터 (Positional parameter)
bash 에 이미 정의된 특수한 파라미터들이 있다. (positional parameter)
- $n : 함수의 n번째 인자를 의미
=> $1 : 함수의 1번쨰 인자, $2 : 함수의 2번째 인자, ...
예제1

- $simplefunc red blue yello => 파라미터에 red, blue, yello 를 넘겨주자 $1, $2, $3 에 자동으로 매핑된다.
예제2

- 함수 f2를 호출시 1번째 인자로 "Hi" 를 넣어줌
(ls : cannot access 'Hi' => Hi 라는 파일이 없어서 파일에 담긴 목록을 못보여줌)
함수의 return 값
- 일반적인 함수처럼, 함수의 지역변수를 선언하고 리턴값으로 활용할 수 있다.
- 지역변수도 built-in 명령어이다.
- "$?" : 함수의 positional parameter (리눅스의 특수한 파라미터)
=> 직전의 명령어들의 최종 결과값(종료 상태 - exit status) 를 상징하는 변수
예제

-
$1 + $2 : 수식 연산(arithmetic operation)
-
지역변수 ret 을 선언하고 파라미터의 덧셈연산을 수행한 결과를 저장하고 return 한다.
-
$? 라는 postional parameter 는, 직전 명령어들의 최종 결과값 상태인 7을 저장한다
Exit status
- 명령어들과 process 들은 모두 종료상태 값이라는 것을 반환하게 되어있다.
ex) c++ 의 main 함수에서 return 0; 을 할때 0이 바로 종료상태 값이다.
"$?" : 종료상태 값을 저장하는 특수 파라미터
- 종료상태 값은 리눅스의 특수한 파라미터인 "$?" 에 저장된다.
- 종료상태값의 종류
- 0인 경우 : process (또는 명령어)가 정상적으로 종료되었음을 음리
- 0이 아닌 경우 : 반대로 비정상적으로 종료되었음을 의미
예제
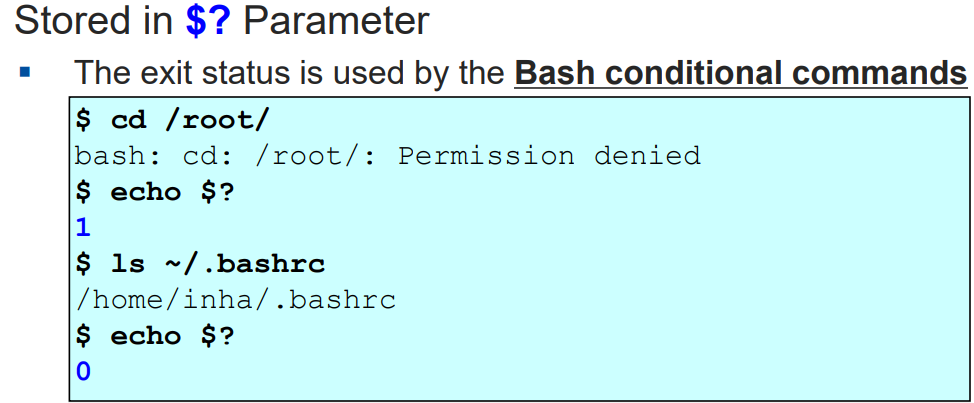
- root 권한이 없는데 root 디렉토리에 접근하려니 비정상적인 접근이 발생해서, $? 에 1이 저장된다.
(cf. 몰론 $? 에 1이 무조건 저장되는 것은 아니다. 0이 아닌 아무 숫자나 저장될 수 있음! )
- 반면 ls 명령어를 통한 정상적인 접근에 대해 $? 에 0이 저장된다.
여러 프로그램 간의 종료상태값 활용

main 함수에서 위와 같이 1을 리턴하는 것은, 나중에 이 프로그램을 다른 프로그램들과 연동해서 사용할 때 비정상인 것을 알려줄 수 있다.
Command lookup
-
Command lookup : 처리할 명령어들을 살펴보고, 일정한 순서에 따라서 처리하는 것
-
command lookup 을 하기전에 alias 에 대해 먼저 처리함
cf ) fork() 함수 : "once call - return twice" 특징을 가지는 특이한 함수
-
한번 호출될때 2번 리턴한다는 뜻
-
process 를 forking( = 복제) 하는 함수
- 현재 process 를 복제해서 새로운 child process 를 생성한다.
-
fork() 를 호출하면 커널이 2번 리턴함. 한번은 0, 다른 한번은 0이 아닌 양수을 리턴한다.
-
0 이 의미하는것 : 해당 process 가 child process 라는 것
-
0이 아닌 양수가 의미하는 것 : parent process(기존 process) 한테 너의 child process 를 복제했고, 그 parent process 의 pid 값을 리턴하는 것
-
cf) 프로세스의 pid 값 이란? : 프로세스 식별자(프로세스 ID 또는 PID) 로, 영 체제 커널이 사용되는 번호이다. PID를 통해 어떤 한 프로세스를 일시적으로 식별 할 수 있다.
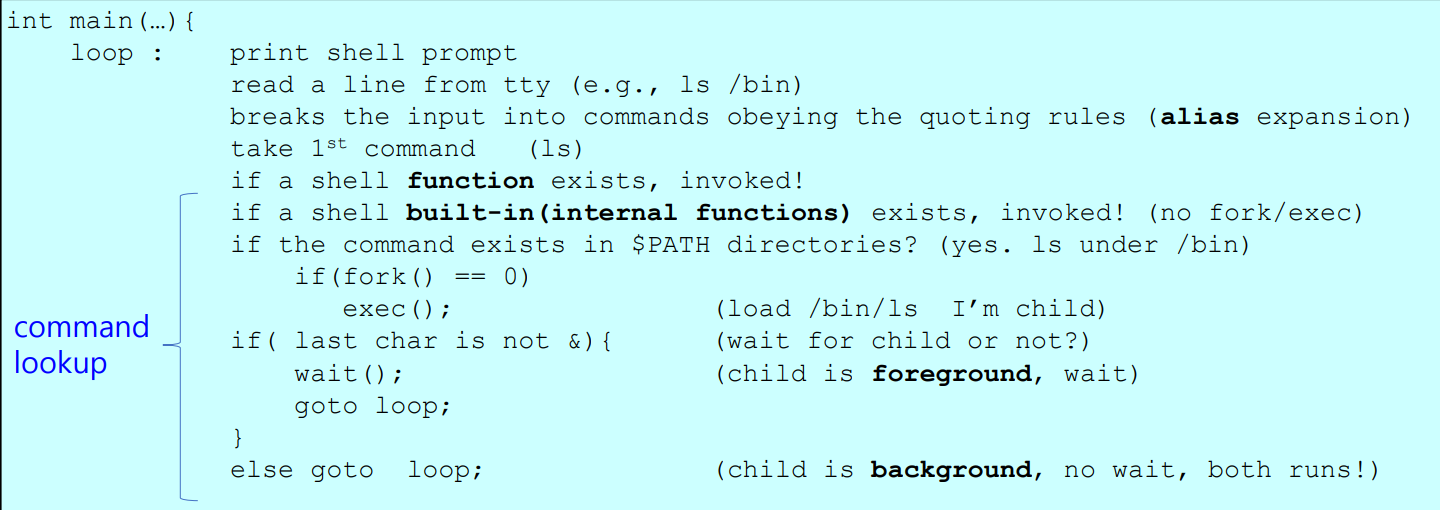
Simple shell - Command lookup 발생순서 (명령어들의 처리에 대한 순서 흐름)
- loop 가 의미하는것 : 반복문으로, 쉘에 커서가 깜빡깜빡 거리면서 명령어를 계속 반복적으로 입력받는 것을 기다리는 행위
1) function
- 아까 우리한 사용한 함수가 존재하는지 살펴보고 존재하면 호출(invoke)
2) built-in function
-
built-in 함수 (즉 리눅스에 이미 정의된 내부적인 함수(internal function)) 이 존재하면 해당 함수를 호출,
-
존재하지 않으면 해당 $PATH (환경변수) 디렉토리 안을 순회하면서
입력으로 받은 명령어 (위 예제에서는 ls) 가 존재하는지를 살펴본다.-
존재하면, fork 한다. fork() 함수가 리턴을 2번 수행할텐데, child process 일 경우 0을 리턴하는데, fork() 값이 0인지를 판단하고, child process 일 경우 exec() 을 호출한다.
- exec() 을 호출하면, 기존 프로세스(parent process) 는 중단되고 새로운 프로세스 (child process) 가 호출 및 실행된다.
-
존재하지 않으면 기존에 실행되던 process(parent process) 가 계속해서 실행된다. "&" 인 제어 연산자(control operator) 를 체크한다.
( * & == child process 의 쉘 )- 없다면, 이는 곧 child process가 존재한다는 의미이다. 따라서 child process 가 종료될 때 까지 기다린다(wait)
- 즉, ls 명령어가 실행되고 종료될 떄 까지 (ls 명령어로 출력문을 다 출력할 때 까지) 기다린다.
- 있다면, 이는 곧 child process 가 존재하지 않는다는 의미이므로 그냥 다시 loop 로 돌아가면 끝!
- 없다면, 이는 곧 child process가 존재한다는 의미이다. 따라서 child process 가 종료될 때 까지 기다린다(wait)
-
Built-in command
-
리눅스 bash에 이미 정의되어 있는 내부적인 함수(internal function)
-
쉘 사용자 입장에서보면, 일종의 command (명령어) 이다.
-
대표예시 : echo, pwd, cd 등등
-
fork 와 exec 과정을 포함하지 않는다 => 속도가 빠름!
-
특징 : 현재의 상테를 바꾸는 command 들을 built-in command 로 정의해 놓았다.
=> ex) cd : 현재 current working directory (현 작업 디렉토리) 를 바꾼다.
외부 명령어(External commands)
-
쉘 프로그램과 독립적으로 존재하는 디스크에 있는 utility
-
외부 명령어는 fork 와 exec 을 통해서 sub shell 에서 (child process) 에서 수행된다! => 실행속도가 느림
<=> built-in command 는 fork 와 exec 과정을 포함하지 않는다! -
사용자가 정의한 새로운 명령어는 외부 명령어에 해당된다.
"type" 명령어
- built-in command 이다. (=> fork/exec 과정을 포함하지 않아서 빠르다!)
- 해당 명령어의 타입을 알려줌
예제
$ type echo : 출력결과 => echo is a shell builtin
$ type cd : 출력결과 => cd is a shell builtin
$ type ls : 출력결과 => ls is aliased to 'ls-- color = auto'
$ type vi : 출력결과 => vi is /usr/bin/gcc명령어 종류의 우선순위
앞서 simple shell 에서 살펴본 로직에 따라서 명령어 종류에 따른 우선순위를 정리해보면 아래와 같다.
명령어 우선순위
1순위 ) alias
2순위 ) 키워드
3순위 ) function command
4순위 ) built-in command

$ alias kill = 'echo my alias kill' => kill 에다 새로운 별칭을 부여
$ kill(){ echp "my function kill"; } => 이미 kill 이라는 built-in command 가 있음에도 불구하고, 사용자가 kill 이라는 함수를 만듦 (새로운 외부 명령어 생성)
$ kill => 이런 상태에서 kill 을 출력하면, alias 가 앞서 살펴본 simple shell 에서 봤듯이 우선순위에 따라 가장 먼저 동작해서 별칭인 'echo my alias kill' 이 출력된다!
$ unalias kill => alias 다음으로 바로 우선순위가 높은 것은 function 이므로, unalias 이후로 kill 을 호출하면 함수 kill 이 호출된다. (함수의 kill 의 body 내용이 출력됨)
& (Background Job)
-
쉘은 control operator (제어 연산자) 인 & 가 있으면 기다리지 않는다!
(앞서 simple shell 에서 살펴본 내용) -
asynchronous commands (비동기 명령어 => 즉, 동시에 실행되지 않는 명령어로, 독립적으로 실행되는 명령어) 이다.

왼쪽 그림
그냥 ls 을 실행하면 & 가 없으므로 child process 가 ls 의 모든 출력문을 출력할때 까지 계속 기다린다.
오른쪽 그림
반면 "$ ls &" 를 보면 child process 가 실행되는 것을 기다리지 않고 그냥 바로 "$ touch test.c" 가 바로 실행되서 출력결과인 "[1] 3097" 이 먼저 출력되고, child process 의 출력결과인 "$ test.c" 가 출력된다.
Job Control (Job process 제어)
-
Background 에서 수행하고 있는 process ( = parent process) 를 job 이라고 부른다.
-
현재 수행중인 process 인 job 을 중단시키거나 재개(resume) 시키는 등의 job process 를 제어하고 컨트롤하는 것을 job control 이라고 한다.
명령어 "jobs" : 현재 수행중인 process 를 출력
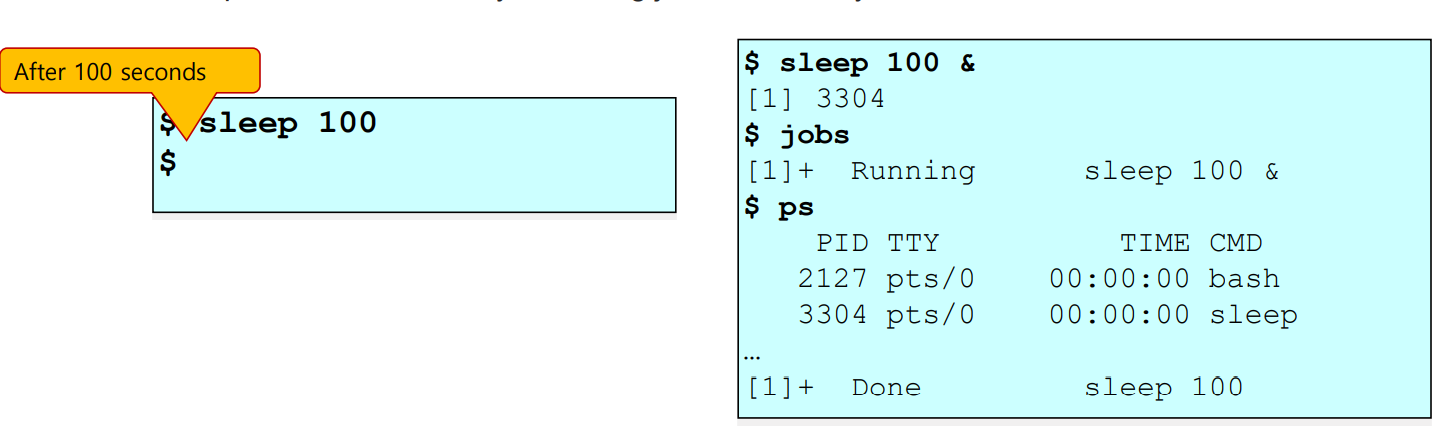
-
원래는 "$ sleep 100" 을 하면 child process 가 끝날때까지, 즉 100초를 계속 기다린다.
-
그런데 "$ sleep 100 &" 와 같이 & 제어 연산자를 붙여주면, 100초를 기다리지 않고 바로 "[1] 3304" 를 출력한다.
=> [1] 에서 1 : job number // 3304 : pid number (process id)
▪ Resume each suspended job jobspec in the background
- ps : 현 process 의 상태를 확인하는 명령어
job control
- "ctrl + Z" 와 같은 것들이 해당 ctrl + Z 는 현 프로세스를 중단시킨다. (Running state 를 Stopped 으로 바꿈)
job control 로 인해 중단된 process 를 다시 실행시키는 명령어 2가지
1) bg %job_number : backgroud process 로써 다시 재개(resume) 시킨다
2) fg %job_number : foreground process 로써 다시 재개시킨다

sleep 100 을 하면서 현재 process 가 (job number 가 1인 process) 중단(Stopped) 되었지만,
bg %1 을 통해 background porcess 로써 다시 실행시키고
현 프로세스의 state 를 확인해보면 Stopped 에서 Running state 로 바뀐것을 확인할 수 있다.
Command list
- 리눅스의 다양한 여러 명령어들을 조합해서 동시에 일렬로 명령어들을 실행 시킬 수 있다. (이때 각 명령어 구분을 위해 ';' 와 '&' 활용)
명령어 나열 방법
- case1) " ; " : 명령어들을 간단히 구분하는 용도라면 세미콜론을 사용
ex) $ date ; sleep 1 ; sleep 10 ; sleep 3 ; date- case2) " & " : parent 가 나열된 여러 child 들의 실행을 기다리지 않고 바로 실행되도록 하려면 & 을 쓰면 된다.
$ date & sleep 1 & sllep 3 & sleep 2 & date
=> "sleep 1" 과 "sleep 3" 과 "sleep 2" 와 "date" 명령어가
잠시 멈춰지는 Stopped 상태가 되지 않고 즉시 바로 실행된다.- case3) ; 와 & 를 동시에 사용할 수도 있다.
$ date ; sleep 1 & sleep 1 & sleep 1 ; date
위 실행문은 아래와 동일한 표현이다.
date
sleep 1 &
sleep 1 &
sleep 1
dateConditional Command list
-
명령어의 실행결과 상태(condition)를 체크하고 다른 명령어의 실행여부를 결정할 수 있는 것
-
연산자 "&&" 와 "||" 를 활용
-
형태
1) cmd1 && cmd2 : 명령어 cmd1 의 실행이 문제가 없다면 (실행에 성공했다면) 명령어 cmd2 를 실행
2) cmd1 || cmd2 : 반대로, 명령어 cmd1 의 실행에 실패한 경우 명령어 cmd2 를 실행
=> 명령어 cmd1 이 정상 실행 되었는지 판단 기준은
리턴되는 종료상태(exit status) 값을 가지고 판단한다.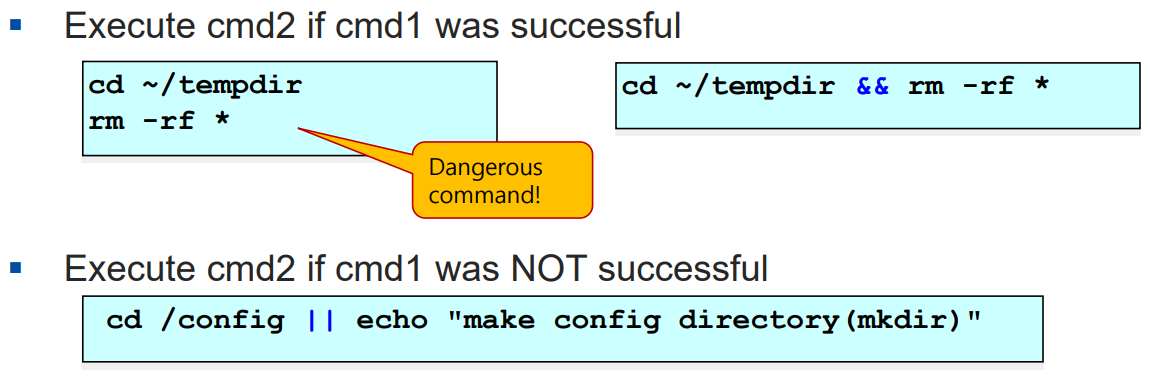
Command Group
- 명령어 그룹을 만들어서 아래와 같은 형태로 실행시킬 수도 있다.
형태 : (command1; command2; command3 ... )- 현 프로세스를 parent process 로 삼고 forking 을 진행해서 child process (= sub shell) 에서 command group 에 있는 명령어들을 별도로 실행한다.
예제
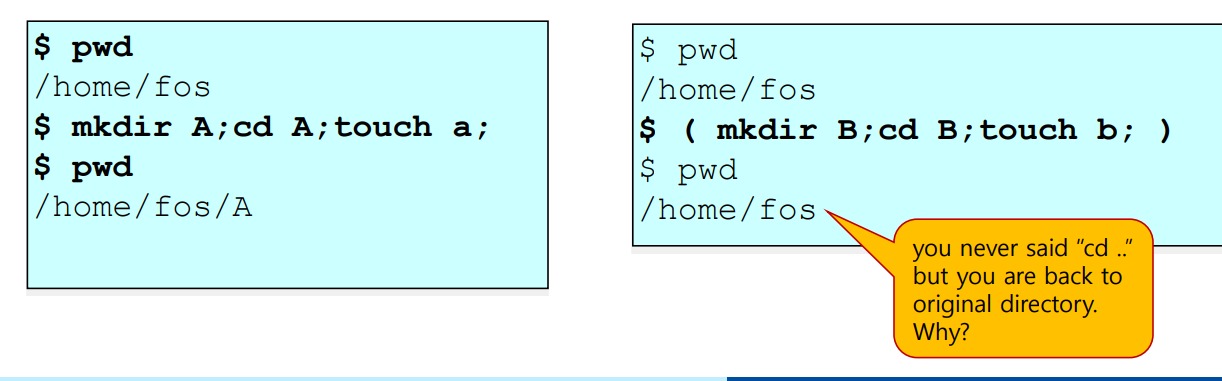
-
왼쪽그림의 경우는 command group 을 따로 만들지 않고 그냥 시킨것이다, 그냥 현 프로세스(그냥 shell) 에서 명령어들이 실행된다.
-
반면 오른쪽그림의 경우, command group 을 만들었기 떄문에 command group 에 있는 것들은 따로 sub shell 에서 수행된다.
이에 따라 pwd 로 출력을 해봐도 sub shell 에서 수행한 명령어 결과가 그냥 shell 에 내용이 반영되지 않았음을 확인할 수 있다!
File Descriptor (파일 해석기)
- 모든 파일은 파일 컨텐츠(contents. 내용물)와 meta data(파일의 속성정보) 로 구성 및 구분되어있다.
- 파일을 하나 생성하면, 파일의 c언어 코드(파일 contents) 외에 아래와 같은 meta data 정보들이 생성될 것이다.
파일의 meta data
cf) meta data 란 ? : '메타데이터(metadata)'란? '속성정보'라고도 불리는 메타데이터는 '데이터에 관한 구조화된 데이터', '다른 데이터를 설명해 주는 데이터'이다. - 콘텐츠의 위치와 내용, 작성자에 관한 정보, 권리 조건, 이용 조건, 이용 내력 등이 기록된다.
* 특정 파일의 meta data 정보들 종류
1.파일 이름
2.Identifier => 파일 식별자 (inode number)
3.파일 크기
4.파일 생성시간
5.파일 타입
6.location(위치) => 특정 디렉토리(파일)에 도달하기 위해선 포인터로 이동한다
7.pos (position) : offset => 파일 내용을 다룰 때, 연산을 수행하는위치명령어 "ls -i", "stat"
ls -i a : 파일 a의 inode number (파일 식별자 번호) 를 출력
stat a : 파일 a의 meta data 정보들을 모두 출력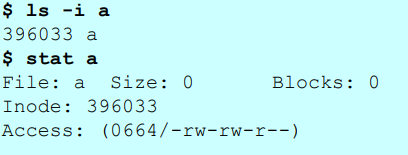
파일을 open 하는 과정 - 커널에 파일의 contents 를 올리는 과정
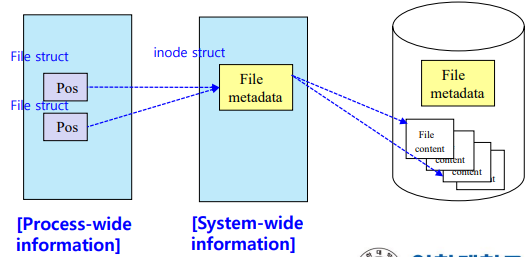
특징1) 파일의 meta data 를 먼저 확인한다.
- meta data 를 memory 로 부터 로딩해서 해당 파일의 기본정보를 파악하고, 파일의 contents 를 운영체제의 커널에 올리는 방식임
- 운영체제는 보통 파일에 대해 mutiple 유저를 지원한다. 즉, 다양한 여러 사람들이 한 파일에대해 공용으로 접근 및 공유할 수 있도록 한다.
특징2) 같은 파일을 여러 유저 및 process 가 open 하는 상황이 발생할 경우를 대비해서, meta data 를 구분함
- 1) System-wide information (inode struct 라는 메모리에 저장) : meta data 중에서 여러 process 가 공유하는 공통적인 정보 (= 변하지 않는 일정한 정보)
-
2) Process-wide information (file struct 라는 메모리에 저장) : 각 process 별로 유지해야 할 정보
-
각 file struct 메모리들은 들은 하나의 inode struct 메모리에 대해 포인터로써 가리키고 정보를 불러올 수 있다.
-
( 각 process 별로 다른 meta data 정보들. ex) Pos => 동일한 mp3 플레이어에서 재생하는 노래가 다를 것이다 )
-
특징3) 같은 파일에 대해 여러 유저가 접근 가능하므로, 여러 프로세스가 동일한 파일을 open 하는 경우가 발생할 것이다.
-
이때 파일을 여러명이 open 하고 각 프로세스가 수정한 각 파일 contents 들만 커널에 올라간다.
-
meta data 들은 커널에 올라가지 않는다.
-
각 프로세스별로 다른 정보를 지닌 meta data (process-wide information) 은 모두 동일한 하나의 meta data (System-wide information) 를 공유한다.
File descriptor table
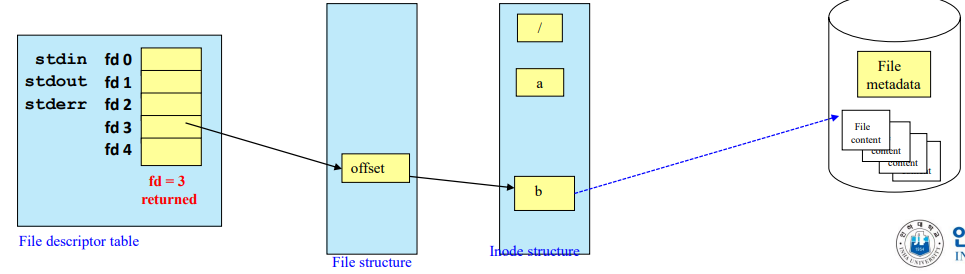
- 각 프로세스는 파일을 open 하기위해 file descriptor table 에 저장된 index 정보를 가지고 해당 프로세스에 속하는 파일에 대해 포인터를 활용해서 access 한다.
- file 을 open 하는 과정 : file descriptor table 의 특정 index => file struct
=> inode structure => 커널에 저장된 해당 file contents 에 access 할 수 있다.
- 포인터를 통해 계속해서 타고타고 이동한다.
- 해당 process 에 대한 file descriptor table 의 index 정수값만 알고있다면 파일을 open 할 수 있다!
Standard input / output

-
0,1,2번은 운영체제에서 미리 정의한 표준 입출력 및 에러 파일
-
process 가 생기면 file descriptor table 이 기본적으로 하나 생성되고 0,1,2 는 이미 다 그려진다.
-
0 : standard input (키보드로부터 입력받는 행위)
-
1 (1번파일) : standard output (화면에 출력하는 행위)
-
2 (2번파일) : standard error (화면에 에러 메시지가 출력되는 행위)
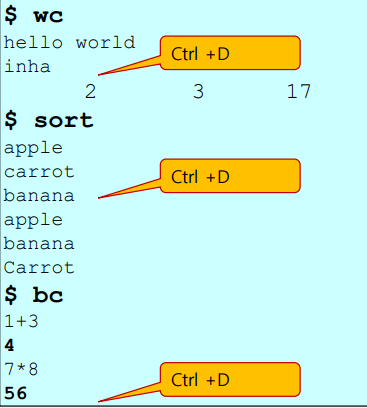
Commands with standard input (예시)
- wc (word count) : 문장 수, 단어 수, byte 수를 출력
- sort: 각 한줄한줄씩 정렬을 수행
- bc (basic calculator) : 계산기 역할 수행
- ctrl + D : EOF(파일의 끝) 을 의미. 즉 입력이 끝났음을 의미 (종료시킴)
Standard Input Redirection
-
바로 위의 예제들은 wc, sort, bc 명령어들을 수행할때 사용자로 부터 직접 input 값들을 받아왔었다. 즉, standard input 인 0번을 사용하고 있었던 것이다.
(ex. wc 명령어 수행시 인풋값으로 "hello world" 와 "inha" 를 사용자로부터 받아옴) -
이렇게 input(입력 값) 을 받는 인풋 공급처를 사용자가 아닌, 파일로부터 받아올 수가 있다.
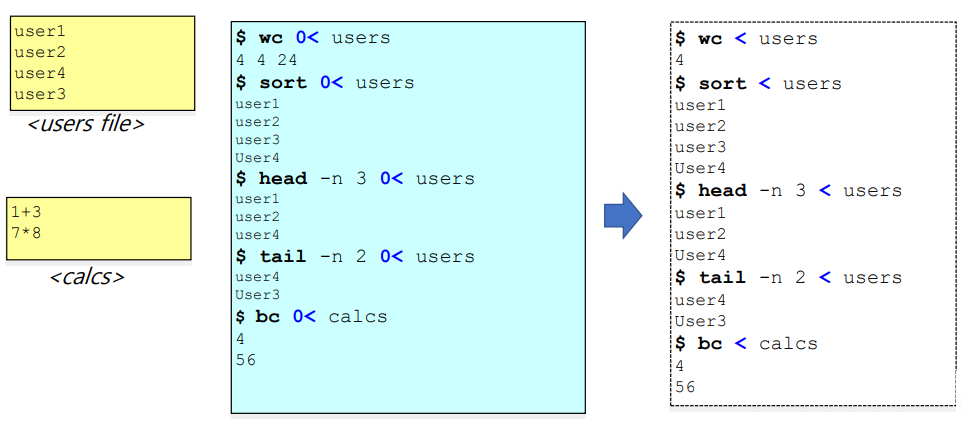
- 형태 : $ 명령어 0< 파일명
cf) "0<" 에서 0을 생략가능. 즉 형태가 "$ 명령어 < 파일명" 도 가능
=> 해당 명령어를 사용자(키보드) 로 부터 직접 입력을 받는 것이 아니라,
파일에 저장된 내용으로 부터 입렫을 받고 명령어를 수행하는 것
ex1) $ wc 0< users : users 라는 파일로 0번(standard input = 사용자로 부터 인풋을 받아오는 것) 을 대체해서
파일 users 로 부터 input 을 받아오라는 의미
=> "$ wc < users" 와 같이 0을 생략 가능하다.
ex2) $ sort 0< users : 마찬가지로 해석 가능. standard input 을 대신해서
input 을 파일로 부터 받아오라는 것
Standard Output Redirection
- standoutput 을 화면이 아닌 특정 파일에 출력하고 싶다면 "1>" 으로 출력되는 경로를 파일로 바꿀 수 있다.
(즉, 명령어 수행결과를 화면이 아닌 파일에 출력(저장)할 수 있다)
- 형태1 : $ 명령어 "출력문" 1> 파일명
=> 기존 파일의 내용을 새롭게 덮어씌우고(삭제 = overwrite), "출력문" 으로 파일 내용을 새롭게 쓴다.
- 형태2 : $ 명령어 "출력문" 1>> 파일명
=> 기존 파일의 내용을 삭제시키지 않고, "출력문" 을 파일의 내용으로 추가한다. (append)
- cf) "1>" 와 "1>>" 에서 1을 생략하고 그냥 ">", ">>" 로 표현가능!
ex)
$ echo "hello world" > log.txt : log.txt 파일에 "hello world" 라는 내용을
새롭게 덮어씌운다 (기존 파일의 내용은 모두 삭제시키고 쓴다)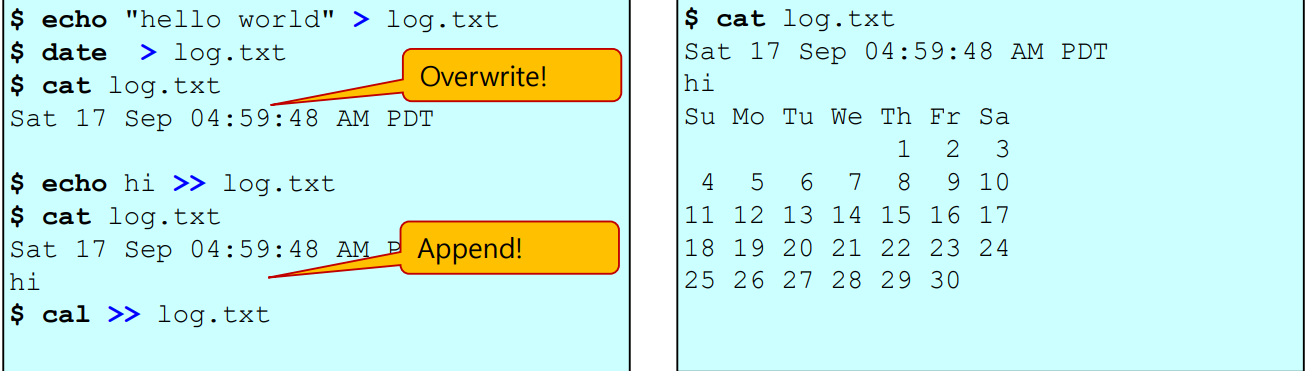
Standout Error Redirection
-
"2>" 를 사용
-
마찬가지로 2를 생략하고 ">" 로 사용가능
-
명령문의 실행결과로 에러가 발생할 경우만 에러메시지가 파일에 저장되고,
정상 실행될 경우 (즉, 에러 발생x 경우) 는 실행결과가 파일이 아닌 화면에 출력된다.
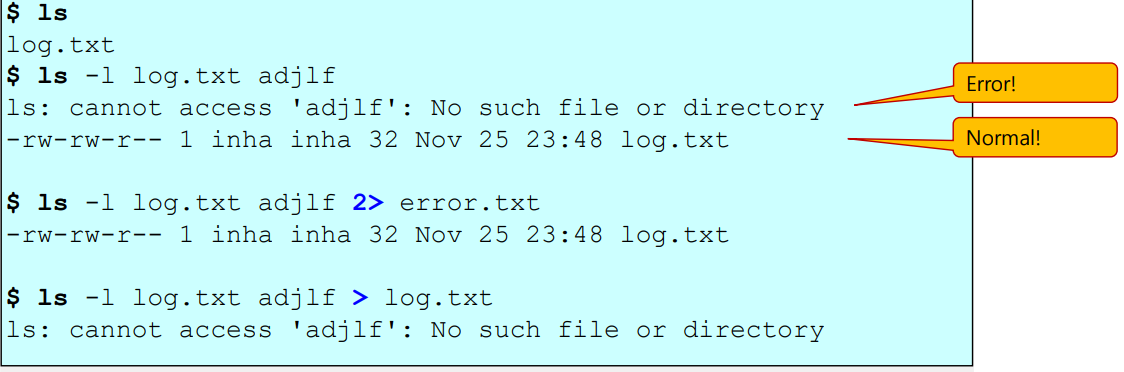
Combination of Redirections1 : redirection 다중으로 사용하기
- ">" 와 "2>" 를 동시에 사용하기
=> 2번을 실행할떄, 에러메시지와 정상메시지를 각각 다른 파일에다 출력 및 저장시키려고 할때 활용
- "&>"
=> 에러메시지인지 아닌지를 구분하지 않고 명령어 실행결과 출력문을 동일한 파일에 쓰고 (저장하고) 싶은 경우
blackhole - /dev/null 파일
- /dev/null 파일 : "null" 이라는 파일 => 블랙홀(blackhole) 과 같은 기능. 명령어의 실행결과에 대한 모든 출력(output) 을 이 파일에 넣으면 모두 소멸된다 (사라짐)
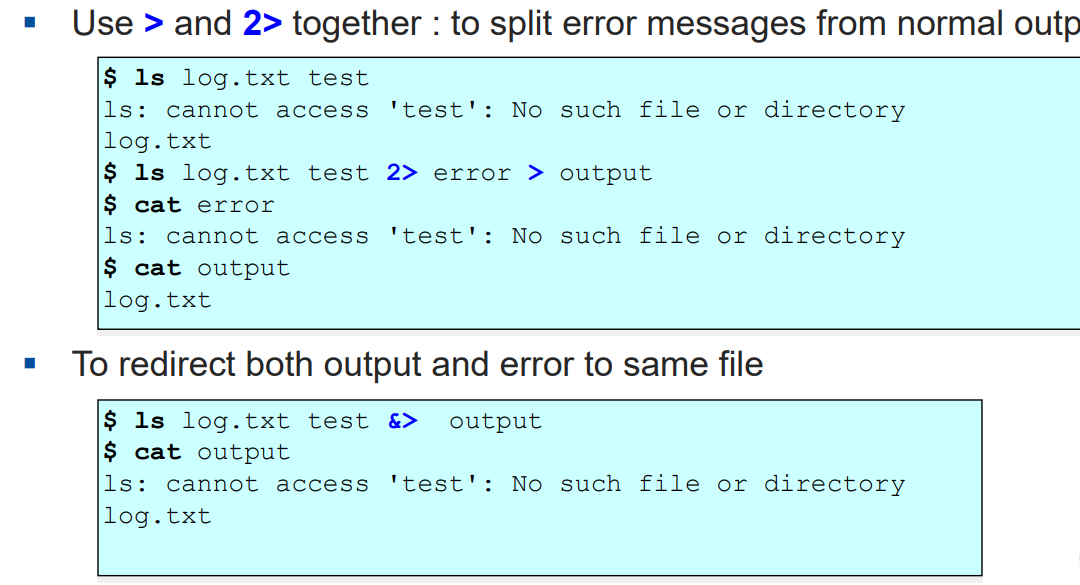
$ ls log.txt test &> /dev/null : ls 명령어의 실행 출력결과를 모두 삭제시켜버림Combination of Redirections2 : redirection 다중으로 사용하기
standard input 과 standard output 을 동시에 파일 경로를 지정할 수 있다.
$ bc < infile > outfile : infile 파일로부터 input 을 읽어와서 outfile 파일에다
명령어 bc 의 수행결과를 출력해준다.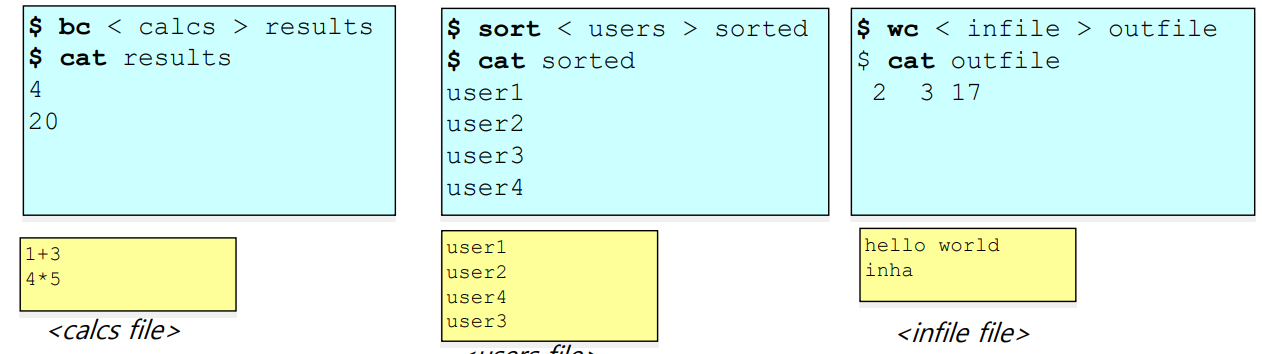
Pipe ( "|" )
- 어떤 명령어1의 standard output 을 명령어2의 standard input 으로 바꾸는 것을 연결해주는 역할을 파이프 "|" 가 수행한다.
ex) $ who | wc -l
=> 명령어 who 의 출력결과(standard output) 을
명령어 wc -l 를 실행할 떄 필요한 입력 값(standard input) 의 값으로 부여해준다.내부적구조
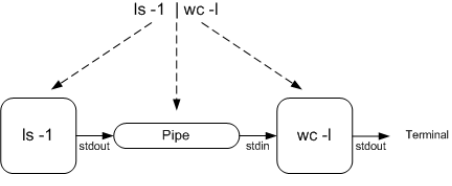
예제
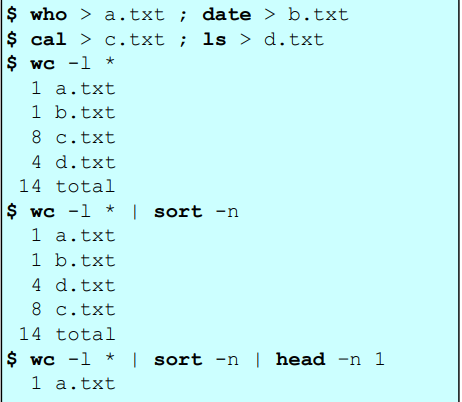
who > a.txt ; data > b.txt
cal > c.txt ; ls > d.txt
=> output redirection 을 통해 a,b,c,d 텍스트 파일 4개를 생성하고 명령어 출력결과를 각 파일에 저장함
$ wc -l * | sort - n : word count 의 출력결과를 sort 함수에 인풋으로 넣어서 정렬시킴Filter
- 필요한 것만 걸러주는 명령어
- standard input 와 standard output 을 사용하지 않는 명령어들
=> 대표 명령어 : grep, tail, wc, sort, awk, sed
( cf) standard input 와 output 을 사용하지 않는 명령어들이 있다. 예를들어 cp (copy) 명령어는 복사를 하지, 인풋도 별도로 받지 않고 출력하는 아웃풋도 없다. 이러한 명령어들을 제외한 명령어들이 바로 filter 이다 )
=> pipe 에 많이 활용되는 명령어들을 filter command 라고 부른다.
형태 : Filter 명령어1 | 명령어2 | 명령어3 | ...
- filter 가 아닌 명령어들 ex) : mkdir, rmdir, cd, cp, mv, rm
예제
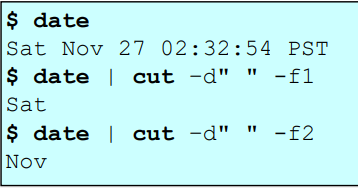
- cut : 어떤 파일로부터 내가 원하는 문자열이나 필드를 추출하는 filter 명령어
=> date 명령어로 출력되는 아웃풋 문자열 중에서 cut 명령어가 딱 필요한 부분만 잘라서 필터링을 해주는 것을 볼 수 있다.
예제2
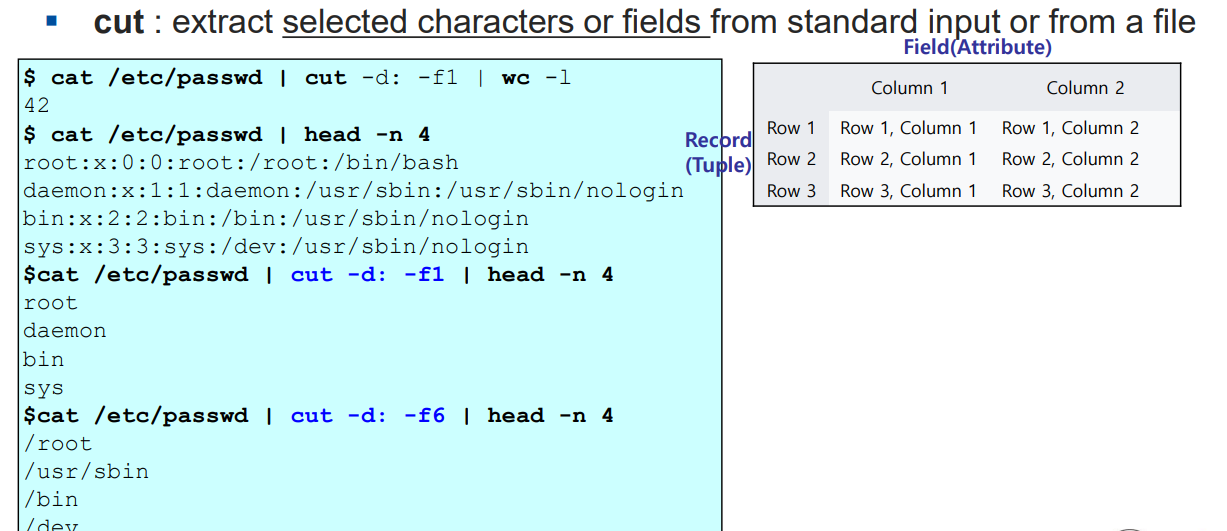
예제3
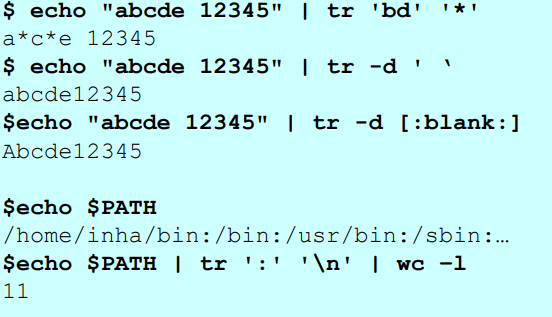
- tr 명령어 : 특정 문자를 다른 문자로 대체하거나 삭제시킴
- 형태1: $ echo "문자열1" | tr '문자1' '문자2'
=> 문자열1의 문자들 중에서 문자1을 2로 대체함
- 형태2: $ echo "문자열1" | tr -d '문자1'
=> 문자열1의 문자들 중에서 문자1을 삭제함
$ echo "abcde 12345" | tr 'bd' '*' => 문자 'b' 와 'd' 를 별표 '*' 로 대체해라!
=> 출력결과 : a*c*e 12345
$ echo "abcde 12345" | tr ' ' => 공백문자를 삭제함
=> 출력결과 : abcde12345예제
AWK (Aho, Weinberger and Kernighan)
형태 : pattern + awk + action
=> 해석 : 이러한 조건(pattern) 을 만족했을때, action 을 취해라!

예제
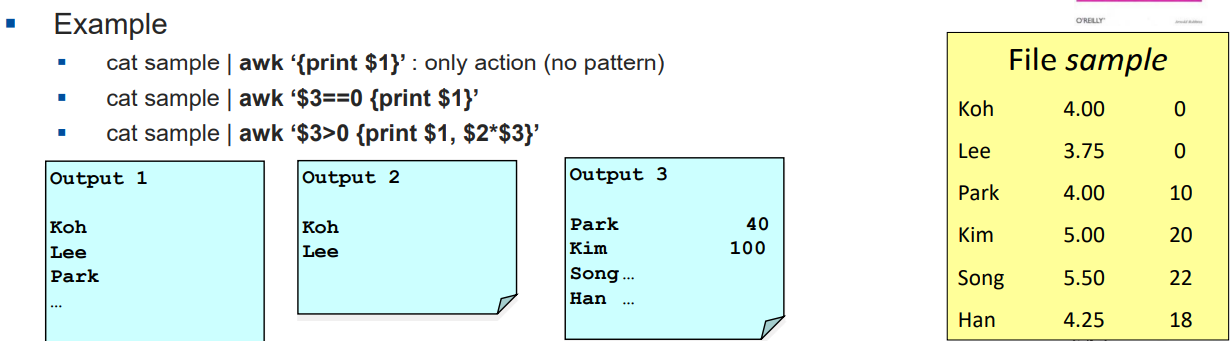
cat sample | awk '%3==0 {print $1}'
=> 3번쨰 필드가 0일떄만 1번째 인자를 출력해라!
cat sample | awk '$3>0 {print $1,$2*$3};
=> 3번쨰 필드가 0보다 클 때, 1번째필드를 출력하고,
(2번째필드) x (3번째필드) 곱하기 결과를 출력해라!Awk 구성요소
1) 변수(variable)
- NF (The "N"umber of "F"ields) : 필드의 숫자
- NR (The "N"umber of input "R"ecords seen) : record(튜플의 번호) 의 숫자
2) printf + 서식문자 (printf format conversion)
- %c : char형, %d : 10진수 숫자, %o : 8진수 숫자, %f, %s, ...
예제

cat sample | awk 'NR'!=2 {print NR, $1, $2*$3, NF}'
=> 튜플의 넘버가 2가 아닐때 출력
cat sample | awk '$3>0{printf("pay for %s is %.3f\n", $1, $3*$2)}'
=> 3번쨰 필드의 값이 0보다 클떄만 printf() 문 실행3) 물결표시 "~" + 인자1
=> 인자1을 포함하고 있는지를 판단한다. (조건문으로써 활용)
cat sample | awk '$1~"Son"{print $2*$3,$1}'
=> 첫번쨰 인자가 "Son" 이라는 문자열을 포함하고 있다면 print 문을 실행