매일메일에서 트랜잭션 아웃박스 패턴에 대해서 공부하던 중
검색 시스템과 관련해서, 메시징 큐를 이용해서 구현에 대해서 명확한 이해가 잘되지 않았다.
그래서 레디스, ElasticSearch를 이용해서 간단한 메시징 시스템을 구현해보고자 한다.
⭐ElasticSearch 개념
기본 구조
ElasticSearch는 기본적으로 기본적으로 검색 엔진에서 주로 사용한다.
우리가 일반적인 Mysql에서 검색을 한다고 생각해보면 아래와 같은 sql문을 통해서 수행할 것이다.
select * from table1 where contents Like ”%???%”;
해당 구문을 이용하면 ???가 들어간 문서를 찾기 위해서 테이블 전체를 찾아서 Full table scan을 한다.
빠른 응답을 제공 해야 하는 검색 시스템에서, 관련이 없는 문서까지 찾는다면 시간이 훨씬 오래 걸릴 것이다.
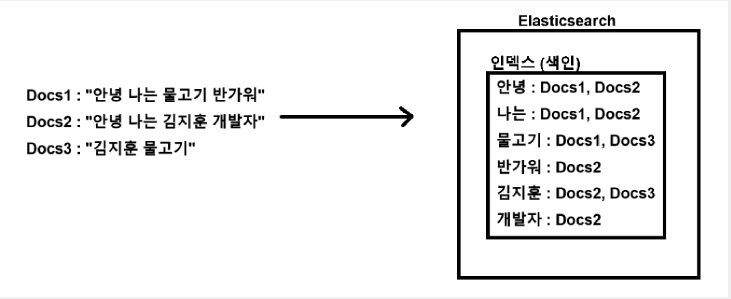
이러한 문제를 인덱스를 통해서 단어 단위의 키와 문서들을 Value로 하는 테이블을 만들어서 해결한다. 여기서 말하는 인덱스는 mysql에서의 index 느낌이 아니라, 단어를 통해서 문서를 빠르게 찾을 수 있는 색인의 느낌이다.
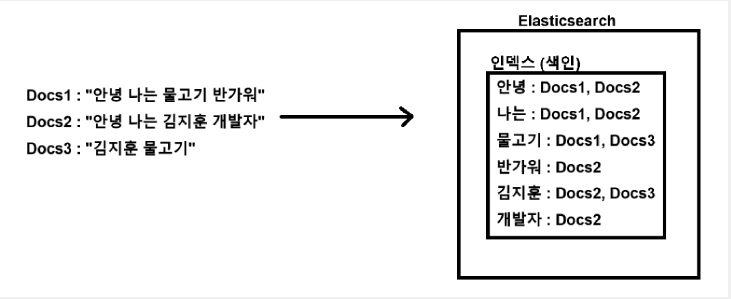
출처: https://www.devyummi.com/page?id=67b49edf870f64428a0fc3b3
어떻게 인덱스를 만들까?
들어온 문서를 인덱스로 만드는 과정은 크게 전처리→형태소 분석→후처리 과정을 거친다.
- 전처리 단계: 특수문자를 제거하거나, 중복 공백을 제거하는 등의 형태소를 분석하기전에 노이즈를 제거하는 역할을 한다.
- 형태소 분석: 문장을 단어 단위로 쪼개고, 요구사항에 맞춰서, 더욱 쪼갤 수 있다.
- 동화를 입력했는데 운동화도 찾아지는 것, run을 입력했는데 running이 찾아지는 등의 대표적인 예시가 존재한다.
- 후 처리 단계 : 전체 중복 제거, 위치정보 부여(문서,문장내에서 어느 위치에 있는지를 나타냄),실제 인덱스 생성등을 이용해서 테이블을 만든다.
전처리나, 후처리에서 모두 대소문자 처리가 가능하다.
다른 DB와 달리 이 인덱스를 만드는 과정이 강력하므로, 검색을 이용할 때는 ElasticSearch를 이용하는 경우가 많다.
전체 구조
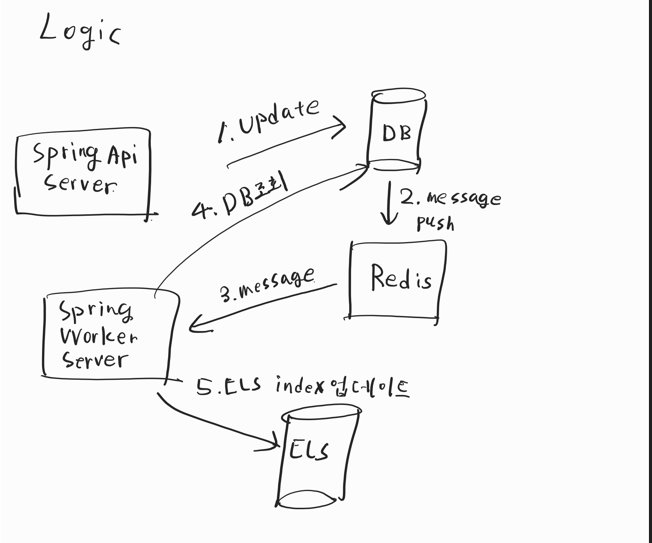
ELS, Redis Spring server를 이용한 상품의 등록 및 검색 시스템의 전체적인 구조는 위와 같이 나타낼 수 있다.
다음과 같은 과정을 거친다.
- Api Server로부터 update 및 등록의 연산 수행시 우선 Api서버와 연동된 db에 업데이트를 수행한다.
- Redis서버의 채널 update된 상품의 정보를 넣어둔다.(publish)
- Spring Worker Server는 Listener를 통해서 메시지를 받는다.
- 메시지에서 update된 상품을 조회한다.
- 후에 ELS의 index를 업데이트한다.
또한 Redis를 이용하면, 자주 검색되는 정보를 ELS에 가는 대신에, Redis에 저장해두고 훨씬 빠르게 접근이 가능하게 설정이 가능하다.
레디스는 아래와 같이 pub/sub구조로 사용할 수 있다.
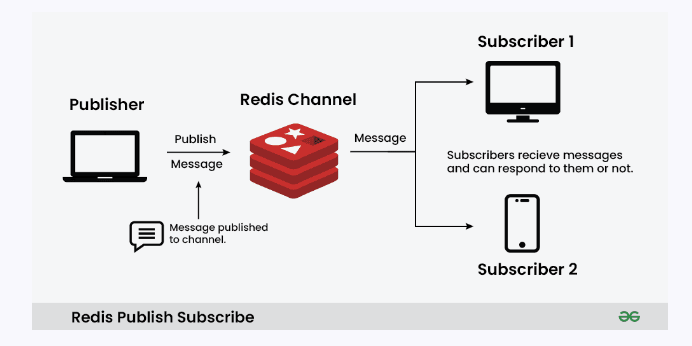
Pub/Sub의 경우 현재 실시간으로 구독중인 Subscriber에 대해서 메시지를 전달해준다.
즉 큐의 방식과 달리 쌓이는 것이 아니라, 즉각 즉각 바로 메시지를 전달한다.
pub/sub 구조를 이용해서 한번 검색어를 업데이트하고, 찾는 로직을 작성해보자.
😊Pub/Sub를 이용한 키워드 update 및 find구현
1. 상품을 DB에 등록하는 로직
@RestController
@RequiredArgsConstructor
@RequestMapping("/product")
public class Controller {
private final ProductService service;
@PostMapping("/insert")
public String requestMethodName(@RequestBody ProductDto dto) {
return service.insert(dto).getName();
}
}@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductRepository repository;
public Product insert(ProductDto dto) {
return repository.save(Product.builder().name(dto.getName()).category(dto.getCategory())
.description(dto.getDescription()).price(dto.getPrice()).build());
}
}
public interface ProductRepository extends JpaRepository<Product, Long> {
}@Entity
@Builder
@AllArgsConstructor
@Data
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name; // 상품명
private String description; // 상품 설명
@Column(nullable = false)
private int price; // 가격
private int stock; // 재고 수량
private String category; // 카테고리명
}- /product/insert를 호출할 때, db에 product를 저장하는 로직이다.
- product에서 상품명을 redis에 등록해서, els에서 사용하려고한다.
2. redis 관련 메시지 로직
우선 docker에 redis를 설치한다.
(docker진짜 너무 편하다.. 한 문장으로 해결되다니)
메시지를 발행할 발행 파트를 먼저 구현해보자.
발행하는 redisconfig는 아래와 같이 구현이 가능하다.
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
@Primary // StringRedisTemplate과 겹치더라
public RedisTemplate<String, String> redisTemplate() {
RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}
여기서 중요한 포인트는 set…Serilaizer 이다. reids내의 모든 데이터는 byte형태로 처리하므로, String형태의 keyword를 넘길 때 역직렬화를 해줘야한다.
이를 위의 setValueSerializer ,setKeySerializer 가 도와준다.
Publish 파트의 RedisTemplate을 기반으로 아래와 같은 publish 로직을 짤 수 있다.
@Service
@Slf4j
@RequiredArgsConstructor
public class MessageService {
private final RedisTemplate template;
public void publishMessage(String keyword) {
template.convertAndSend("keyword-update", keyword);
log.info("Redis 메시지 발신: " + keyword);
}
}이를 통해서 redis의 채널을 "keyword-update”로 설정하고 keyword를 발행할 수 있다.
이제 수신 측의 코드를 작성해보자.
@Configuration
public class RedisSubscriberConfig {
@Bean
public RedisMessageListenerContainer redisMessageListenerContainer(
RedisConnectionFactory connectionFactory, KeywordSubscriber keywordSubscriber) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.addMessageListener(keywordSubscriber, new ChannelTopic("keyword-update"));
return container;
}
@Bean
public ChannelTopic topic() {
return new ChannelTopic("keyword-update");
}
}
위 코드를 통해서 RedisMessageListenerContainer 가 빈으로 등록되고,
container.addMessageListener 를 통해서 redis의 해당 채널을 구독한다.
이후 pub파트에서 convertAndSend 를 통해서 메시지를 발행하면,
메시지 리스너가 이를 받아서, keywordSubscriber 의 onMessage()를 호출한다.
@Slf4j
public class KeywordSubscriber implements MessageListener {
/**
* @param message
* @param pattern
*/
@Override
public void onMessage(Message message, byte[] pattern) {
String keyword = new String(message.getBody(), StandardCharsets.UTF_8);
log.info("Redis 메시지 수신: " + keyword);
// 이곳에서 Elasticsearch 검색 등 원하는 작업 수행
}
}
3. ELS관련 설정
마찬가지로 docker에 els를 설치하자

이 이후 docker로 els를 실행하는데 개발환경이니까 보안은 그냥 해제하자
spring data elasticsearch도 있다…(개꿀)
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
els의 documet와 ELSRepository를 정의하자
@Document(indexName = "product")--> 인덱스 이름 선언
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class ProductDocument {
@Id
private Long id;
@Field(type = FieldType.Text) // 분석기 적용: matchQuery, like 검색 가능
private String name;
@Field(type = FieldType.Text)
private String description;
@Field(type = FieldType.Integer)
private int price;
@Field(type = FieldType.Integer)
private int stock;
@Field(type = FieldType.Keyword)
private String category;
}public interface ProductELSRepository extends ElasticsearchRepository<ProductDocument, Long> {
List<ProductDocument> findByNameContaining(String keyword);
}
@Field(type = FieldType.Text) 가 붙은 칼럼에 대해서 Elastic Search 리포지토리내에서 인덱스 테이블들을 자동으로 생성해준다.
FieldType.Keyword 가 붙어있으면 하나의 단어를 키워드로 보고 단어를 더쪼개지 않고 인덱스를 생성한다.
즉 카테고리가 중식 이라면 중+식이 아니라 중식: doc1이런식으로 저장이 된다.
물론 성능 향상을 위해서는 nori 분석기 세팅도 사용할 수 있다고 한다.
이 인터페이스는 기본적으로 data jpa와 마찬가지로, 기본 CRUD를 제공한다.
productELSRepository.save(doc); // 저장
productELSRepository.findById(1L); // ID로 조회
productELSRepository.findAll(); // 전체 조회
productELSRepository.deleteById(1L); // 삭제
productELSRepository.existsById(1L); // 존재 여부
productELSRepository.saveAll(List<ProductDocument>) // 여러 개 저장즉 mysql과 연동해서 사용하던 data jpa와 다르지 않게 사용이 가능하다.
정말 spring-data가 너무 편리하게 잘되어있다는 것을 다시 한번 체감한다.
기존의 ProductService에 이제 elsRepository에 productDocument를 저장하는 로직은 아래와 같다.
public void syncAll(ProductDto dto) {
elsRepository.save(ProductDocument.builder().category(dto.getCategory())
.description(dto.getDescription()).name(dto.getName()).price(dto.getPrice())
.build());
}save후 내부를 살펴보니,
{
"took" : 83,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "product",
"_id" : "P9ZH0JUBnO-JeiiNDnsK",
"_score" : 1.0,
"_source" : {
"_class" : "com.example.els.global.ProductDocument",
"name" : "짜장면",
"description" : "중국음식중 근본",
"price" : 5000,
"stock" : 0,
"category" : "음식"
}
}
]
}잘 저장되어있음을 알 수 있다.
json에서 확인할수는 없지만, 실제 els 내부에서의
역인덱스 테이블에는
짜장: "P9ZH0JUBnO-JeiiNDnsK"
형식으로 keyword: id 형태로 들어가있다.
4.키워드를 통해서 찾는 로직
이제 product의 name을 통해서 product를 찾는 로직을 작성하자
@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductRepository repository;
private final ProductELSRepository elsRepository;
public Product insert(ProductDto dto) {
Product product =
repository.save(Product.builder().name(dto.getName()).category(dto.getCategory())
.description(dto.getDescription()).price(dto.getPrice()).build());
syncAll(dto);
return product;
}
public void syncAll(ProductDto dto) {
elsRepository.save(ProductDocument.builder().category(dto.getCategory())
.description(dto.getDescription()).name(dto.getName()).price(dto.getPrice())
.build());
}
public List<Product> findBykeyword(String keyword) {
// TODO Auto-generated method stub
List<ProductDocument> nameContains = elsRepository.findByNameContaining(keyword);
List<Product> list = nameContains.stream()
.map(doc -> Product.builder().category(doc.getCategory())
.description(doc.getDescription()).name(doc.getName()).price(doc.getPrice())
.stock(doc.getStock()).build())
.toList();
return list;
}
}stream을 활용하면 위처럼 빠르고 깔끔하게 작성이 가능해서, dto로 부터 결과값을 반환할 때 자주 사용한다.
주의
@Document가 붙은 elasticsearch의 문서의 id는 반드시 String 으로 해야한다.
(문서내의 id가 String 형이니까)
@AllArgsConstructor
@Builder
public class ProductDocument {
@Id
private String id;
@Field(type = FieldType.Text) // 분석기 적용: matchQuery, like 검색 가능
private String name;
@Field(type = FieldType.Text)
private String description;
@Field(type = FieldType.Integer)
private int price;
@Field(type = FieldType.Integer)
private int stock;
@Field(type = FieldType.Keyword)
private String category;
}
http://localhost:8080/product/findByKeyword?keyword=짜장
을 실행 시 아래처럼 결과를 잘 반환하는 것을 볼 수 있다.

🚇Pub/Sub방식의 이점 및 한계
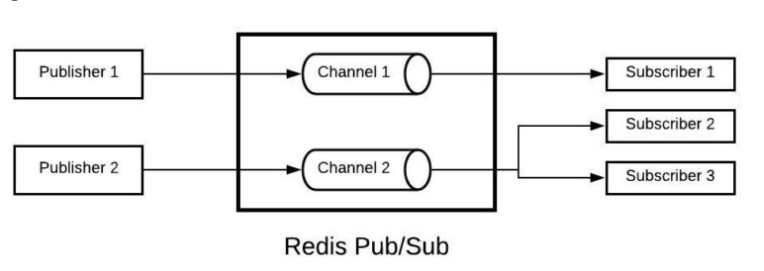
✍️ Redis Pub/Sub를 이용한 메시지 전달
Redis의 채널 기반 Pub/Sub 방식을 이용하면,
즉각적이고 빠른 메시지 전달이 가능하다.
왜냐하면 Kafka나 RabbitMQ와 같은 큐 기반 시스템은 메시지를 큐에 저장(enqueue)한 뒤,
소비자가 이를 꺼내서(dequeue) 처리하는 구조인 반면,
Redis Pub/Sub은 메시지를 저장하지 않고,
구독 중인 클라이언트에게 즉시 브로드캐스트하는 구조이기 때문이다.
⚠️ 그러나 단점도 존재한다
Redis Pub/Sub는 메시지를 저장하지 않기 때문에,
보존성(durability)과 신뢰성(reliability)이 중요한 서비스에서는 사용이 어렵다고 판단된다.
예를 들어, 구독자가 일시적으로 연결이 끊겼거나 처리 지연이 발생한 경우,
해당 메시지는 소실될 수 있다.
✅ 적합한 사용 사례
따라서 실시간 반응성이 중요하고, 메시지 유실에 관대한 시나리오에서 사용하면 효과적이다. 예를 들면:
- 유저가 어떤 이벤트를 발생시킴 (
좋아요,댓글,DM,경매 낙찰됨등) - 서버가 Redis Pub/Sub 채널에
"유저에게 알림"메시지를 발행 - 프론트엔드(웹/앱)는 웹소켓을 열고, 백엔드에서 Redis Pub/Sub 메시지를 수신
- 메시지를 수신하면 사용자 브라우저 또는 앱에 푸시 알림 표시
이러한 구조는 채팅, 알림, 실시간 피드 업데이트 등에서 매우 빠른 반응 속도를 제공할 수 있다.
🙋♂️ 검색어 Update/Select에는 적합할까?
내가 구현한 기능이 검색어를 업데이트하거나 조회하는 기능이라면,
이처럼 메시지가 소실될 수 있는 Redis Pub/Sub 방식은 적합하지 않을 수 있다.
- 데이터의 정확한 저장과 조회가 중요한 로직에서는 메시지를 잃어버리는 리스크가 있는 Pub/Sub보다는 큐 기반 또는 DB 연동 방식이 더 안전하고 신뢰할 수 있다.
Redis에서는 이를 위해서 데이터를 저장해둘 수 있는 Stream을 제공한다.
😂 Redis Stream
구조
Redis Stream은 기본적으로 Kafaka,Rabbimq와 마찬가지로 메시지를 보관해서, 어플리케이션단에서 비동기 처리를 위해서 사용된다.
다른 메시징 큐를 사용하는 구조들과의 차이점은, 시간을 기준으로 메시지 ID를 생성하기 때문에 메시지의 순서가 자연스럽게 보장되고, 특정 시점 이후의 메시지를 정확하게 조회하거나 재처리할 수 있다는 점이다.
Stream Key: product-update-stream
├── [ID: 1701140000000-0]
│ ├── productId: 101
│ └── action: "update"
├── [ID: 1701140000001-0]
│ ├── productId: 102
│ └── action: "delete"
├── [ID: 1701140000002-0]
│ ├── productId: 103
│ └── action: "update"위처럼 각 시간 별로 데이터들이 들어가 있어서 과거의 데이터 까지 볼수 있는등의 이점을 가질 수 있다. 또한 각 시간을 id로 하고 내부에는 Map의 형태로 데이터를 저장한다.
Redis stream에는 크게 두가지의 특징이 있다.
- append-only의 특징을 가진 시계열 데이터 처리
- 추가만 되므로, 수정, 삭제가 되지 않는다.
- 삭제를 하기 위해서는
XDEL을 통해서 직접 삭제하거나, MAXLEN을 통해서 메시지의 갯수를 제한해서 삭제하는 방법이 있다.
- 기록된 데이터 소비(메시징 시스템)
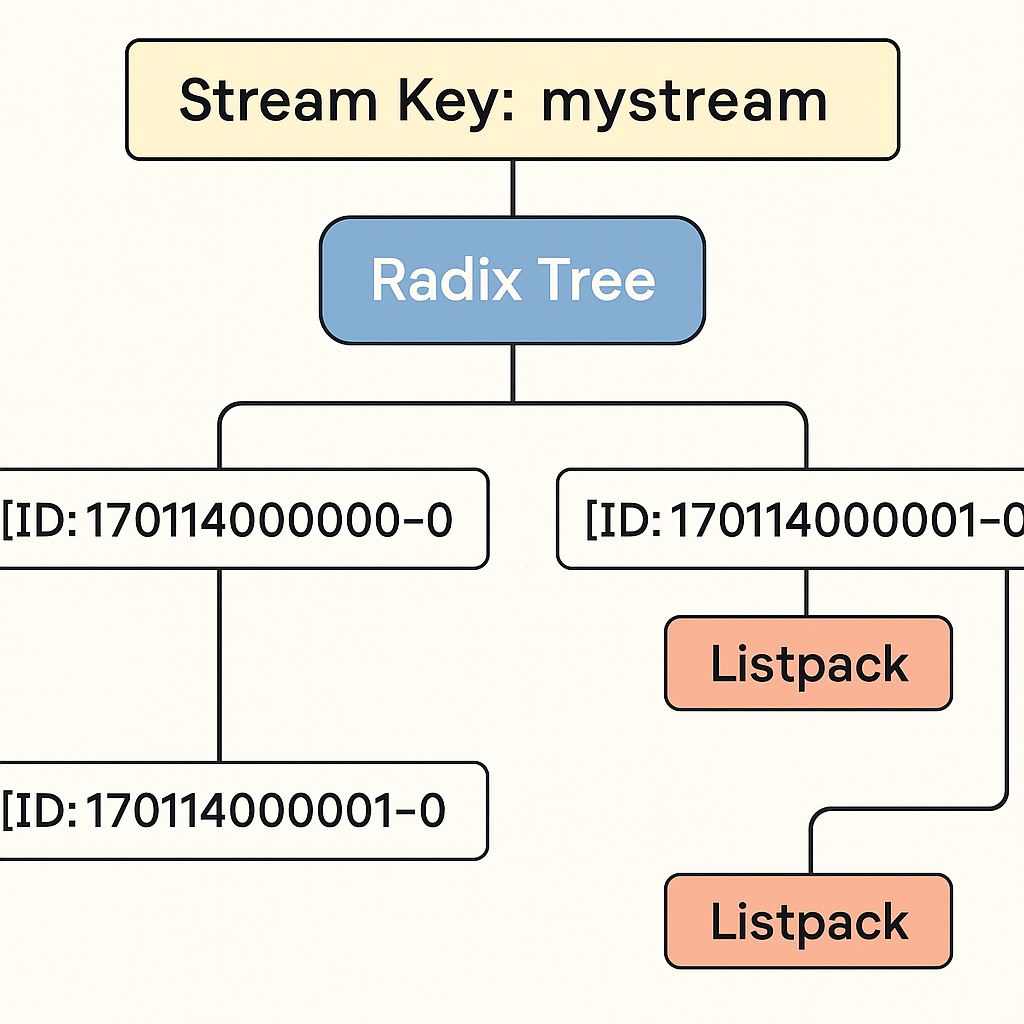
HashMap 기반 listpack으로 필드:밸류 를 넣어둔다.
명령어
| 명령어 | 설명 | 예시 |
|---|---|---|
XADD | Stream에 메시지 추가 | XADD mystream * user han action like |
XRANGE | 특정 범위의 메시지 조회 | XRANGE mystream - + |
XREVRANGE | 메시지를 뒤에서부터 조회 | XREVRANGE mystream + - COUNT 3 |
XREAD | 새 메시지 읽기 (비그룹) | XREAD STREAMS mystream 0 |
XGROUP CREATE | Consumer Group 생성 | XGROUP CREATE mystream group1 $ |
XREADGROUP | 그룹으로 메시지 읽기 | XREADGROUP GROUP group1 consumer1 STREAMS mystream > |
XACK | 메시지 처리 완료(acknowledge) | XACK mystream group1 1701140000000-0 |
XPENDING | 아직 처리되지 않은 메시지 확인 | XPENDING mystream group1 |
XCLAIM | 다른 Consumer의 메시지 가져오기 | XCLAIM mystream group1 consumer2 0 170114000 |
Group Consumer
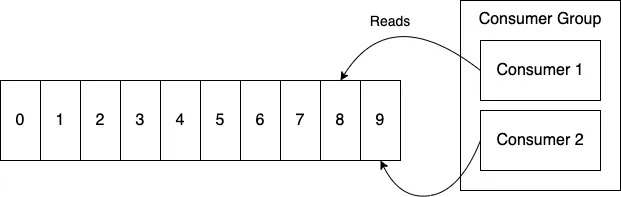
메시지를 받는 쪽에서 Consumer Group을 지정할 수 있고, 그 안에서 Consumer들을 나눌 수 있다.
각 Consumer를 나눠서 읽는다면 다음과 같은 일이 가능하다.
- 순서가 상관없는 일이라면 병렬적으로 메시지를 처리할 수 있다. ➡ 이를 통해 처리 속도를 높일 수 있으며, 각 Consumer가 서로 다른 메시지를 동시에 처리함으로써 시스템 전체의 처리량(Throughput)을 극대화할 수 있다. 예를 들어 주문 이벤트, 로그 적재, 비동기 알림 등은 순서보다는 빠른 처리가 중요하므로 여러 Consumer를 통해 병렬로 분산 처리하면 훨씬 효율적이다.
이 문장이 의미하는 것은 순서가 상관 있는 동기적인 일이라면, 서비스에 있어서 주의해야한다는 의미이기도 하다.
👌Pub/Sub→ Redis Stream으로 리팩토링
기존에 사용하던 Redis의 Publish/Subscribe 구조보다 Stream방식이 검색어의 update작업시, 활용하기 적합하다고 생각한다.
따라서 리팩토링을 진행해보자
Produce
public class MessageServiceByStream {
private final RedisTemplate<String, String> redisTemplate;
private static final String STREAM_KEY = "product-update-stream";
public void publishMessage(Long productId, String action) {
Map<String, String> message = Map.of(
"productId", productId.toString(),
"action", action // "update", "delete" 등
);
log.info("Redis Stream Message 발행 "+productId);
redisTemplate.opsForStream().add(STREAM_KEY, message);
}
}pub/sub 구조에서는 convertAndSend 를 통해서 redis에 채널을 만들고 keyword를 넣었다.
Redis Stream은 위에서도 설명했다싶이 데이터는 Map의 형태로 저장된다.
따라서 위처럼 stream key와 map으로 정의된 message를 정의한다.
opsForStream()를 통해서 Redis Steam 명령어인 XADD를 실행해서 Stream의 끝에 메시지가 저장된다.
(append-only)
timestamp-sequence를 통해서 고유한 id또한 생성된다.
Stream Key: product-update-stream
├── [1701181234567-0]
│ ├── productId: 123
│ └── action: insert Consumer
@Component
@RequiredArgsConstructor
@Slf4j
public class ProductIndexingConsumer {
private final RedisTemplate redisTemplate;
private final ProductRepository productRepository;
private final ProductELSRepository elsRepository;
private static final String STREAM_KEY = "product-update-stream";
private static final String GROUP = "product-group";
private static final String CONSUMER = "consumer-1";
@PostConstruct
public void init() {
try {
redisTemplate.opsForStream().createGroup(STREAM_KEY, GROUP);
} catch (Exception ignored) {
}
new Thread(this::consume).start();
}
public void consume() {
while (true) {
List<MapRecord<String, Object, Object>> records =
redisTemplate.opsForStream().read(Consumer.from(GROUP, CONSUMER),
StreamReadOptions.empty().block(Duration.ofSeconds(2)),
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed()));
for (MapRecord<String, Object, Object> record : records) {
Map<Object, Object> data = record.getValue();
String productIdStr = data.get("productId").toString();
log.info("Redis Stream 수신: " + productIdStr);
String action = data.get("action").toString();
Long productId = Long.valueOf(productIdStr);
// 메시지에 따라 ELS 처리
switch (action) {
case "insert":
case "update":
productRepository.findById(productId).ifPresent(product -> {
elsRepository.save(ProductDocument.builder().name(product.getName())
.category(product.getCategory())
.description(product.getDescription()).price(product.getPrice())
.stock(product.getStock()).build());
});
break;
case "delete":
break;
}
// ack
redisTemplate.opsForStream().acknowledge(STREAM_KEY, GROUP, record.getId());
}
}
}
}
Consumer파트를 보면 Pub/Sub방식과 Stream방식의 차이를 알 수 있다.
- Push vs Pull
pub/Sub 방식은 메시지가 채널에 들어오면 바로 나가서 Subscribe한 어플리케이션에 대해서 바로 메시지를 push해주고 messageListener의 onMessage 가 바로 실행된다.
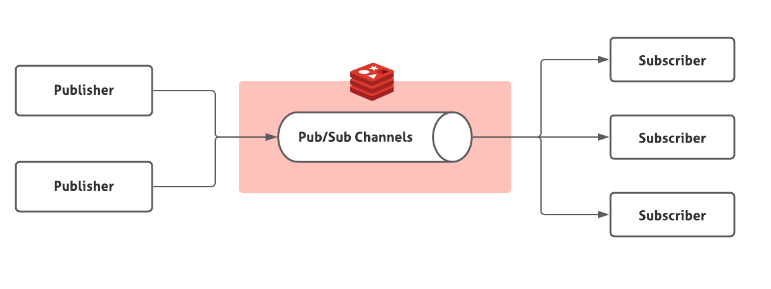
따라서 Subscriber는 MessageListener의 onMessage의 구현과 redisMessageListenerContainer 을 빈으로 등록해서 message를 받고 실행할 수 있는 것이다.
하지만 Stream은 Pull 방식으로 각 Consumer가 message를 직접 가지고 와야한다.
따라서 일정 간격으로 message가 왔는지를 확인하고, 왔으면, 소비가 안된 메시지에 대해서, 탐색을 한다.
아래의 메시지를 가져오는 코드를 한번 자세히 살펴보자
- Message 읽어오기
List<MapRecord<String, Object, Object>> records =
redisTemplate.opsForStream().read(
Consumer.from(GROUP, CONSUMER), // 1
StreamReadOptions.empty().block(Duration.ofSeconds(2)), // 2
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed()) // 3
);Redis Stream내부에 저장된 메시지 하나를 저장해둔 Map을 MapRecord 를 통해서 가져올 수 있다.
Consumer.from(GROUP, CONSUMER)은 Consumer Group 기반으로 메시지를 읽겠다는 의미이다.- 이를 통해 Redis Stream에서 메시지를 어떤 그룹으로 나누어 처리할지 설정할 수 있다.
- 일반적으로 Consumer Group은 어플리케이션 단위, Consumer는 스레드나 인스턴스 단위로 나누어 구성한다.
- Stream 읽을 때 사용할 옵션 설정한다. (여기서는 메시지가 없으면 2초 대기한다.)
- 어느 스트림을 읽을지를 지정하는데,
- 앞의 파라미터를 통해서 어떤 스트림을 읽을지를 정하고, 두번째 파라미터를 통해서 어느 메시지 부터읽을지를 정한다.
- 위에서는 이전까지 읽은 마지막 메시지 이후부터 읽겠다는 뜻이다.
MapRecord 는 <Stream Key,Message Id,Value> 형태로 저장해두어서, 위에서 말한 Redis Stream을 효과적으로 표현이 가능하다. Value는 String 형태로 들어가게 되며 이는
Map<Object, Object> data = record.getValue(); 를 통해서 Map의 형태로 가져와서 우리가 원하는 작업을 할 수 있다.
결과
위처럼 insert시 아래와 같이 message가 발행되고, 이를 cosumer측에서 수신 후

productdb에서 id를 기반으로 product를 찾고 , els에 post요청을 보내게된다.

결과적으로 아이폰만 입력해도 잘 반환됨을 알 수 있다.
🙌정리
Update와 Select 연산을 동시에 같은 서버와 DB에서 처리하게 되면,
검색어 처리나 푸시 알림처럼 많은 연산이 발생하는 서비스에서는 서버 부하가 심해질 수 있다.
이를 해결하기 위해, 각각의 기능을 다른 어플리케이션과 DB로 분리하는 MSA(Microservice Architecture) 구조를 채택한다.
이후 비동기 처리를 위해 메시지 브로커를 사용하는데,
Redis Pub/Sub 또는 Redis Stream 방식 중 서비스 특성에 맞게 선택할 수 있다.
Redis Pub/Sub은 Push 기반으로, 메시지를 채널을 통해 실시간으로 구독자에게 전달하지만,
메시지를 저장하지 않기 때문에 구독자가 없거나 처리 지연이 발생하면 유실될 수 있다.
👉 따라서 실시간 알림, 채팅, 즉각적인 반응이 중요한 서비스에 적합하다.
반면 Redis Stream은 고유한 ID를 가진 시계열 기반 메시지를 저장하고,
메시지 유실 없이 순차 처리와 병렬 처리를 모두 지원한다.
👉 그래서 시간 기반 데이터 처리, 실시간 검색어 추천, 이벤트 로그 수집 등
데이터 보존이 중요한 시나리오에 더 적합하다.
출처
https://oliveyoung.tech/2024-11-15/inventory-changed-stocks-function-with-redis-stream/

ㄷㄷ 퀄 미쳤네요 아무것도 모르는데 읽혀요. 잘 보고 갑니다