서론
Spring Data JPA나 QueryDSL을 쓰면서 @Query, .update(), .delete() 같은 쿼리를 작성해 본 적이 있을 것이다.
처음엔 익숙한 SQL처럼 보여서 편하지만, 이러한 벌크 연산들은 영속성 컨텍스트를 무시한다는 치명적인 특징을 가지고 있다.
이 글에서는 JPQL과 QueryDSL 모두에서 공통으로 발생하는 벌크 연산의 위험성에 대해 설명한다.
영속성 컨텍스트란?
JPA는 EntityManager를 통해 엔티티를 1차 캐시에 저장하고, 상태를 추적한다.
이걸 통해 JPA는 변경 감지(dirty checking), 지연 로딩, 캐시 재사용 같은 기능을 제공한다.
Member member = em.find(Member.class, 1L); // 영속 상태
member.setAge(30); // 변경 감지
이런 구조가 바로 JPA의 핵심이자, 가장 큰 장점이다.
JPQL과 QueryDSL은 영속성 컨텍스트를 항상 거칠까?
많은 사람들이 오해하는 부분이 있다.
"JPQL이나 QueryDSL은 JPA 위에서 작동하니까 당연히 영속성 컨텍스트를 거치겠지?"
→ 절반은 맞고, 절반은 틀리다.
많은 개발자의 착각: JPQL이나 QueryDSL이면 괜찮다?
Spring Data JPA를 사용할 때 흔히 쓰는 @Query나,
QueryDSL의 .update(), .delete() 같은 메서드는 결국 JPA의 JPQL을 바탕으로 동작한다.
그래서 많은 개발자들이 다음과 같이 생각합니다:
"JPQL이나 QueryDSL은 JPA 기반이니까 영속성 컨텍스트를 당연히 거치겠지?"
하지만 현실은 다르다.
JPQL과 QueryDSL의 진실
| 쿼리 종류 | 예시 | 영속성 컨텍스트 반영 여부 |
|---|---|---|
| 조회 (SELECT) | @Query("SELECT m FROM Member m"), selectFrom().fetch() | 거침 |
| 수정 (UPDATE) | @Query("UPDATE Member m SET m.age = 30"), .update().execute() | 무시함 |
| 삭제 (DELETE) | @Query("DELETE FROM Member m"), .delete().execute() | 무시함 |
즉 아래와 같이 동작이 수행된다.
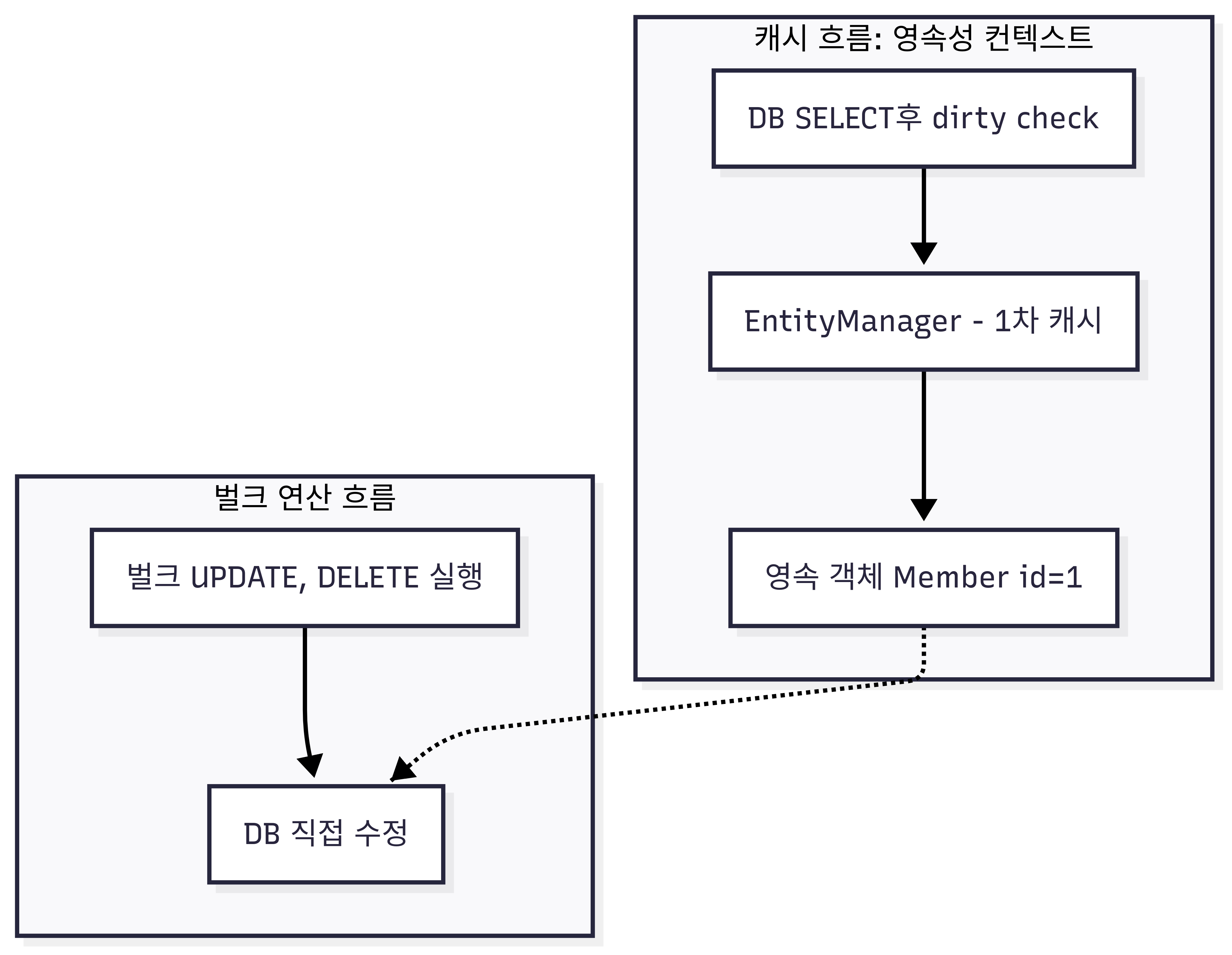
벌크 연산의 함정
다음은 QueryDSL과 JPQL에서 사용하는 전형적인 벌크 연산이다.
QueryDSL 예시
queryFactory
.update(member)
.set(member.age, 30)
.where(member.name.eq("홍길동"))
.execute();JPQL 예시
@Modifying
@Query("UPDATE Member m SET m.age = 30 WHERE m.name = :name")
int updateAge(@Param("name") String name);이 코드를 실행하면:
DB에는 바로 반영된다
그러나 영속성 컨텍스트는 갱신되지 않는다
즉, 이미 findById() 등으로 로딩한 객체는 이전 값 그대로 유지
실제 사례
@Transactional
public void update() {
Member member = memberRepository.findByName("홍길동"); // 영속 상태
memberRepository.updateAge("홍길동"); // DB만 수정
System.out.println(member.getAge()); // 여전히 예전 값 (dirty checking 안 됨)
}벌크 연산은 EntityManager의 1차 캐시를 무시하기 때문에,
DB와 애플리케이션 메모리 간의 정합성이 깨질 수 있다.
해결 방법
| 방법 | 설명 |
|---|---|
em.flush(); em.clear(); | 수동으로 캐시 초기화 |
@Modifying(clearAutomatically = true) | Spring Data JPA에서 자동 clear 처리 |
| 변경 감지 방식 사용 | member.setAge(...) 후 트랜잭션 커밋에 맡기기 |
변경 감지를 사용하는 방식이 더 안전하다
@Transactional
public void update() {
Member member = memberRepository.findById(1L).get(); // 영속 상태
member.setAge(30); // 변경 감지
}-
타입 안전
-
트랜잭션 내에서 정합성 유지
-
캐시 일관성 보장
-
JPA의 철학에 맞는 코드
jpa를 사용한다면 dirty check를 그냥 사용하자..
안그러면 오류난다.
문득 영속성 컨텍스트에 저장되는 객체들이 너무 많아지면 안되지 않나 라는 생각이 들었다.
JPA로 몇 개까지 안전하게 조회할 수 있을까?
JPA는 em.find()나 JPQL을 통해 조회된 모든 엔티티를 영속성 컨텍스트(1차 캐시)에 유지한다..
이는 변경 감지, 트랜잭션 일관성 유지 등 많은 장점을 제공하지만, 대량 데이터를 한 번에 조회할 경우 메모리 문제가 발생할 수 있다.
얼마나 조회할 수 있을까?
JPA는 조회 개수에 제한이 있는 것은 아니지만, JVM의 힙 메모리 한도에 따라 실질적인 한계가 존재한다.
예를 들어:
- JVM 힙 메모리: 2GB
- 엔티티 하나당 평균 메모리: 약 1KB
→ 대략적으로 200만 개까지는 이론적으로 조회 가능
→ 하지만 현실적으로는 10만 개 이상부터 위험 구간에 진입한다.
실무 기준 참고치
| 조회 개수 범위 | 안정성 | 권장 처리 방식 |
|---|---|---|
| ~ 10,000건 | 안정 | 기본 트랜잭션 처리 |
| ~ 100,000건 | 경계 | flush() + clear() 필요 |
| 1,000,000건 이상 | 위험 | JPA 대신 jOOQ, JDBC, Streaming 등 사용 권장 |
왜 문제가 되는가?
JPA는 다음과 같은 데이터들을 메모리에 유지합니다:
- 엔티티 객체 자체
- 변경 감지용 스냅샷
- 연관 관계 프록시 객체
- 1차 캐시, 쓰기 지연 SQL 저장소 등
→ 트랜잭션이 길어질수록 메모리를 과도하게 사용하게 됩니다.
대량 처리 시 해결책
flush() + clear() 주기적 사용
for (int i = 0; i < members.size(); i++) {
em.persist(members.get(i));
if (i % 1000 == 0) {
em.flush(); // DB 반영
em.clear(); // 캐시 비우기
}
}