
😄인덱스란?
인덱스란?
데이터베이스와 관련한 CRUD작업을 할 때, 특정한 조건에 해당하는 로우를 찾아서 수행하는 경우가 많습니다. 이 때 별도의 설정을 하지 않고, 칼럼을 찾는다면 일반적으로 각 테이블의 모든 행을 탐색하는 Full Table Scan을 수행합니다. 이 때 시간복잡도는 당연하게 O(n)이 걸립니다.
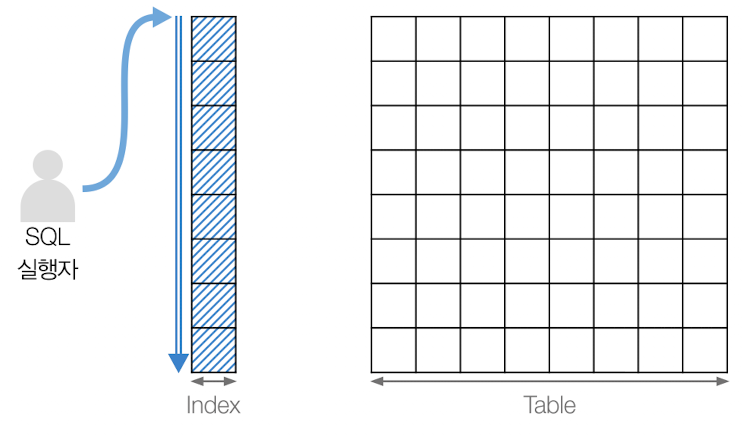
이 때 속도의 개선을 하기 위해서 사용자가 선택한 조건에 해당하는 정보와 테이블의 로우를 매핑하는 자료구조를 만들어서 관리하는데, 이것을 인덱스라고합니다.
해시테이블 기반의 인덱스
해시테이블은 기본적으로 해시 함수를 기반으로 생성되며, 키:값구조로 만들어집니다.
- 인덱스에서 해시 함수는 주어진 조건 즉 인덱싱하려는 칼럼을 버킷의 주소로 바꾸어줍니다.
- 이 조건의 칼럼: 버킷의 주소 형식의 인덱싱 테이블이 형성됩니다.
ex) 해시 테이블 예시
| 컬럼 값 (department_id) | 버킷 주소 (Hash 값) |
|---|---|
| 101 | 0x1A2B |
| 202 | 0x1A3C |
| 303 | 0x1A4D |
| 404 | 0x1A5E |
버킷 테이블 예시
| 버킷 주소 (Hash 값) | ID | Name | Department_ID | Position |
|---|---|---|---|---|
| 0x1A2B | 1 | Alice | 101 | Manager |
| 0x1A3C | 2 | Bob | 202 | Engineer |
| 0x1A4D | 3 | Charlie | 303 | Analyst |
| 0x1A5E | 4 | Diana | 404 | HR Specialist |
위의 형성된 해시 테이블을 통해서 O(1)시간로 매우 빠른 시간에 접근이 가능합니다.
그렇다면 일반적인 관계형 db에서 해시 테이블을 통해서 인덱스를 형성하는게 맞지 않을까요?
- 해시테이블로 형성된 인덱스 구조는 일반적으로 다음과 같은 문제점이 있습니다.
- 범위 지정의 where문이 올 때 이 내부의 값을 일일히 찾아야합니다.
- 해시 테이블은 =연산에 유리한 형태로 형성되어 있으므로, 범위지정의 연산에서 매우 취약합니다.
- 해시테이블의 형성시 해시 충돌이 발생된다면, 시간복잡도는 o(1)이 아닐 수 있습니다.
- 또한 충돌시, Open-addressing, Closed-Addressing등의 추가적인 연산을 수행해야합니다.
- 범위 지정의 where문이 올 때 이 내부의 값을 일일히 찾아야합니다.
이러한 이유로 일반적인 관계형 db(mysql,MariaDB,PostgreSQL, Oracle)에서는 b-tree기반의 b+tree를 사용합니다.
b+tree기반의 인덱스
b+tree는 일반적으로 아래와 같은 b-tree기반으로 만들어져 있습니다.
[40]
/ \
[10, 20] [50, 60]
/ | \ / | \
[5] [15] [30] [45] [55] [70, 80, 90]b-tree는 다음과 같은 특징을 같습니다.
- 왼쪽과 오른쪽 자식들의 깊이가 balanced되는 방향으로 insert, remove가 수행됩니다.
- 하나의 노드에 여러 데이터가 들어갈 수 있습니다.
- 각 노드내에 들어가 있는 데이터 순서대로 위와 같이 정렬이 되어있습니다.
- 왼쪽 자식의 데이터는 본인 보다 작은 데이터가 들어가고, 오른쪽 자식의 데이터는 본인 보다 큰 데이터가 들어갑니다.
- 따라서 범위지정의
where연산시 빠르게 수행할 수 있습니다.
b+tree
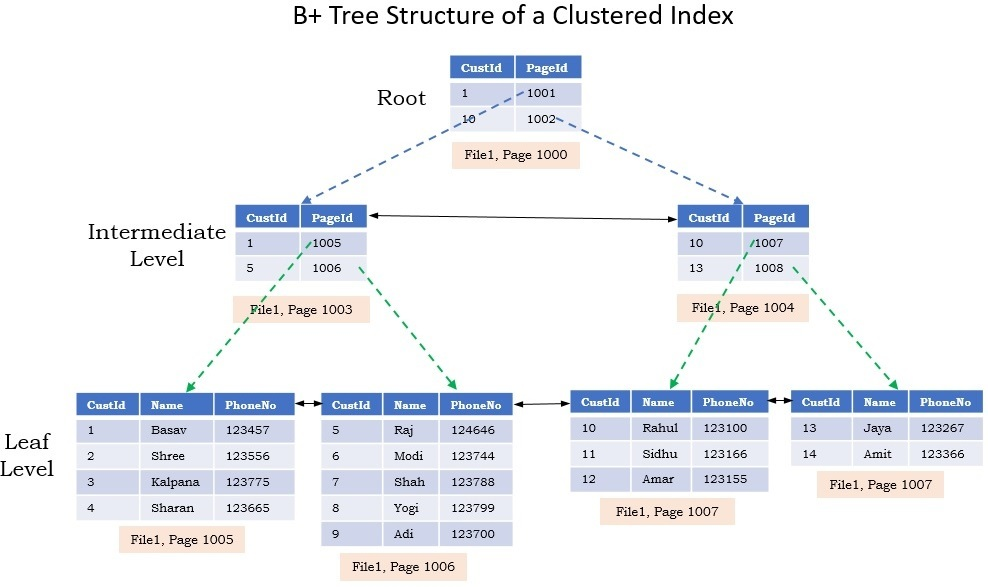
이미지 출처: https://engineerinsight.tistory.com/184#%F0%9F%92%8B%C2%A0B-Tree%20%EC%9D%B8%EB%8D%B1%EC%8A%A4-1
- b+tree는 b-tree와 달리 리프노드에만 데이터가 들어가고, 루트노드와, 중간의 노드들에는 해당 위치를 찾는 데이터의 키만 찾는 것입니다.
- 또한 b+tree의 리프노드는 이중 연결리스트로 연결되어 있습니다.
- 이를 통해서 효율적인 범위 탐색이 가능합니다.
select * from member where between memer.age 30 and 90연산시- 아래의 리프노드에만 데이터가 저장되어 있고, 해당 데이터가 정렬이 되어 있으므로, age가 30인 위치를 찾아서 바로 옆 노드로 이동하면서 탐색하면 됩니다.
- 하지만 b-tree구조에서는 중간 노드에 있을 수도 있으므로, 범위 연산의 수행이 b+tree보다는 번거로울 것입니다.
여기서 페이지란?
일반적으로 디스크와 메모리 간 데이터 전송은 외부 단편화 문제로 인해 프로세스 전체를 한 번에 메모리에 올리지 않고, 프로세스를 작은 단위로 나누어 필요한 부분만 로드합니다. 이때 사용하는 단위를 페이지(Page)라고 합니다.
위에서 언급된 "페이지"는 실제로 메모리에 로드되고 검색되는 단위를 의미합니다. 데이터베이스에서도 페이지 단위로 입출력(IO) 작업이 이루어지며, 페이지 크기에 따라 성능이 크게 영향을 받습니다. 페이지 크기가 적절하지 않으면 IO 작업이 비효율적이 될 수 있으므로(페이지를 한번 더 로드해야하므로), 성능 최적화를 위해 페이지 크기 설정이 중요합니다.
🆙Mysql InnoDB에서의 인덱스
PK 인덱스 구조
기본적으로 mysql InnoDB에서 PK역시 인덱스를 따릅니다.
즉 아래와 같은 구조를 따릅니다.
| id (Primary Key) | name | department_id | salary |
|---|---|---|---|
| 10 | Alice | 101 | 5000 |
| 20 | Bob | 102 | 4500 |
| 30 | Charlie | 103 | 5500 |
| 40 | Diana | 104 | 6000 |
| 50 | Eve | 101 | 6500 |
| 60 | Frank | 102 | 7000 |
| 70 | Grace | 103 | 7500 |
| 80 | Henry | 104 | 8000 |
| 90 | Irene | 105 | 8500 |
일 때,
위의 테이블은 아래와 같은 pk키를 키로 하는 b+tree를 만듭니다.
[40]
/ \
[20] [60, 80]
/ \ / | \
[10] [30] [50] [70] [90]
↔ ↔ ↔ ↔ ↔이 트리는 아래와 같은 리프노드의 데이터를 가집니다.
1. 첫 번째 리프 노드:
- [10, Alice, 101, 5000]
- [20, Bob, 102, 4500]
2. 두 번째 리프 노드:
- [30, Charlie, 103, 5500]
- [40, Diana, 104, 6000]
3. 세 번째 리프 노드:
- [50, Eve, 101, 6500]
- [60, Frank, 102, 7000]
4. 네 번째 리프 노드:
- [70, Grace, 103, 7500]
- [80, Henry, 104, 8000]
5. 다섯 번째 리프 노드:
- [90, Irene, 105, 8500]
이를 통해서 findById등의 작업을 수행시, 훨씬 빠른 작업을 수행할 수 있습니다.
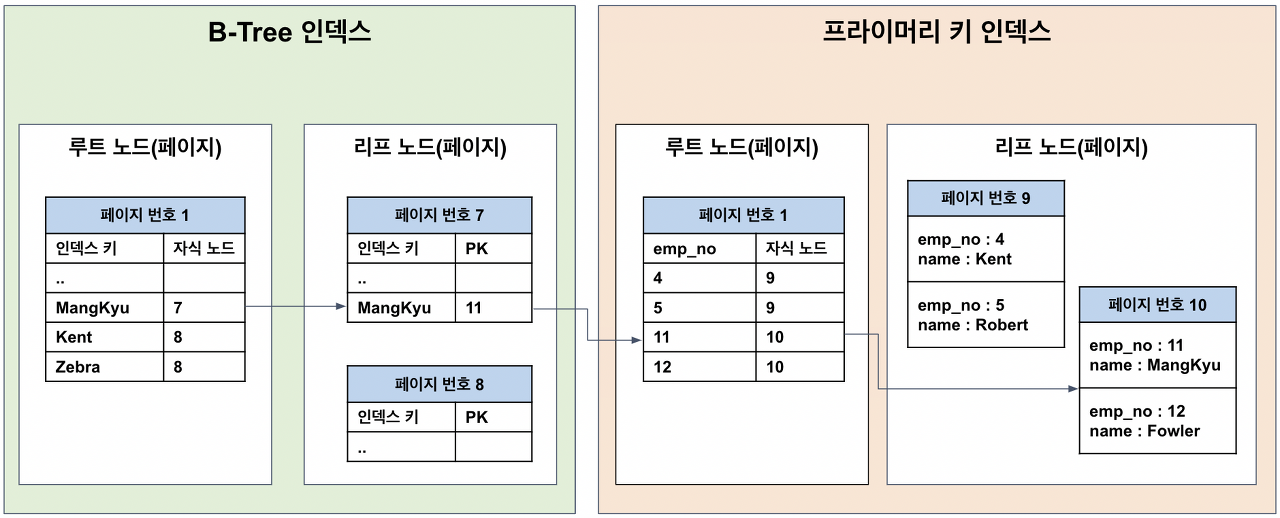
PK기반의 인덱스 구조
mysql의 InnoDb는 아래와 같이 PK기반의 인덱스 구조 즉 클러스터링 구조(PK를 기준으로 유사한 값들이 함께 조회되는 경우가 많다는 점에서)를 통해서 인덱싱을 수행합니다.
출처: https://mangkyu.tistory.com/286
즉 우리가 age=30인 로우를 인덱스를 이용해서 찾을 때는 다음과 같은 과정을 따릅니다.
1. age=30에 해당하는 PK를 찾는다
2. 해당 PK에 해당하는 로우 즉 테이터들을 찾는다.
그렇다면 왜 굳이 mysql의 InnoDB는 PK기반의 인덱스구조를 이용할까요?
-
실제 개발을 하다보면 PK기반으로의 조회가 많아지는데, 이 때 훨씬 빠르게 조회할 수 있습니다.
-
서브 인덱스와의 협력에서 매우 효과적으로 사용가능하기 때문입니다.
- id값은 모든 데이터베이스에 존재하며, 고유하기 때문에 서브 인덱스와 연관시키기 쉽습니다.
- 또한 만약 서브 인덱스만으로 그 때, 그 때 리프 노드내에서 페이지에 모든 정보를 넣어둔다면 비효율적인 데이터 사용을 하는 것일 것입니다.
- 이 문제를 데이터 페이징과, PK페이징으로 나누어서 문제를 해결하였습니다.
그러나 PK를 사용하는것이 항상 효율적인 것은 아닙니다.
- Insert,Update시 PK의 정렬이 필요하므로 추가적으로 들어가는 cost가 필요합니다.
- 또한 PK의 수가 커지고 로우가 커지면 인덱스의 수 또한 커지므로 보조 인덱스와의 사용시 오버헤드가 발생할 수 있습니다.
하지만, 이러한 단점에도 불구하고
PK 기반 클러스터링 인덱스는 읽기 성능을 크게 향상시키며,
대부분의 읽기 중심 워크로드에서는 이러한 추가 비용이 상쇄됩니다.
효율적인 PK 설계를 통해 이러한 문제를 최소화할 수 있습니다.
index의 장,단점
장점
- where문을 통해서 해당 조건인 로우를 찾을 때 훨씬 빠르게 접근 할 수 있습니다.-> O(logn)
- 범위지정의 조건 연산시에 각 조건에 해당하는 로우의 레코드에 빠르게 접근 할 수 있음(아닌 경우도 존재함)
단점
- 결국 index 테이블들의 b+tree를 만들어 관리하므로, 저장공간을 사용하는 것이므로, 자원을 사용하는 것입니다.
- 로우가 너무 적은 경우는 full-scan을 하는것이 나을 수 있습니다.
- update,insert등의 수정 연산시 오버헤드가 발생합니다.
Mysql 스캔 방식
Mysql은
Index Range ScanIndex Full ScanLoose Index Scan방식으로 인덱스를 스캔합니다.
Index Range Scan
- 일반적으로 범위가 명확한 경우에 사용하는 스캔 방식입니다.
예: WHERE column BETWEEN A AND B
동작 방식은 아래와 같습니다.
1. Column A에 해당하는 리프노드를 찾습니다.
2. 해당 리프노드부터,B까지의 리프노드의 인덱스를 읽습니다.
3. 이 때 각 리프노드와 대응되는 데이터가 저장되어 있는 레코드의 주소에 대한 접근이 Random Access로 접근 됩니다.
[인덱스 값]
salary: 5200 -> 레코드 주소: page_3, slot_10
salary: 6000 -> 레코드 주소: page_8, slot_5
salary: 7000 -> 레코드 주소: page_2, slot_3디스크 헤드가 물리적으로 random IO로써 여러 위치를 이동하니 오버헤드가 발생할 수 있습니다.
따라서 데이터 레코드 비율이 전체 데이터의 20-25% 이상일 경우 풀 테이블 스캔이 더 효율적일 수 있습니다.
예시: Index Range Scan과 랜덤 IO 발생
데이터 상황
- 전체 로우: 10만 건
- 조건:
salary > 5000 - 조건에 해당하는 데이터: 3만 건 (전체 데이터의 30%)
쿼리
SELECT * FROM member WHERE salary > 5000;
## Full Table Scan실행 방식
-
Index Range Scan: salary > 5000에 해당하는 인덱스를 탐색합니다.
조건에 맞는 레코드의 물리적 주소(데이터 페이지 위치)를 얻습니다. -
랜덤 IO 발생
- 인덱스를 통해 찾은 각 레코드 주소를 기반으로 데이터가 저장된 물리적 레코드에 접근합니다.
- 이 과정에서 디스크의 여러 위치를 비연속적으로 읽게 되며, 랜덤 IO가 발생합니다.
-
오버헤드
- 30%라는 넓은 범위의 데이터를 처리해야 하기 때문에, 랜덤 IO가 반복적으로 발생하며 성능 저하와 오버헤드가 커집니다.
결론
조건에 해당하는 데이터 비율이 30%로 높은 경우, Index Range Scan은 랜덤 IO의 오버헤드로 인해 비효율적입니다.
이러한 경우, 풀 테이블 스캔(Full Table Scan)을 사용하여 순차 IO로 데이터를 읽는 것이 더 효율적일 수 있습니다.
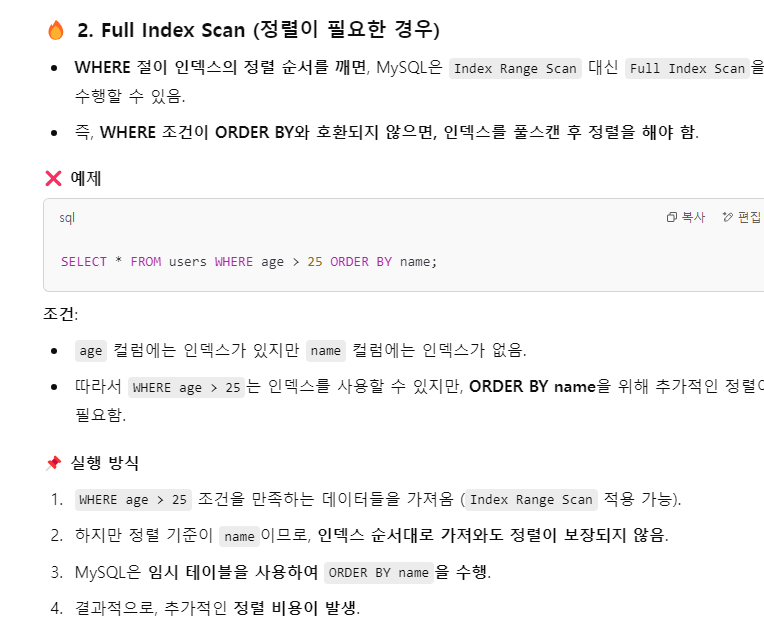
Full Index Scan
Full Index Scan은 전체의 인덱스를 스캔하는 과정을 의미합니다.
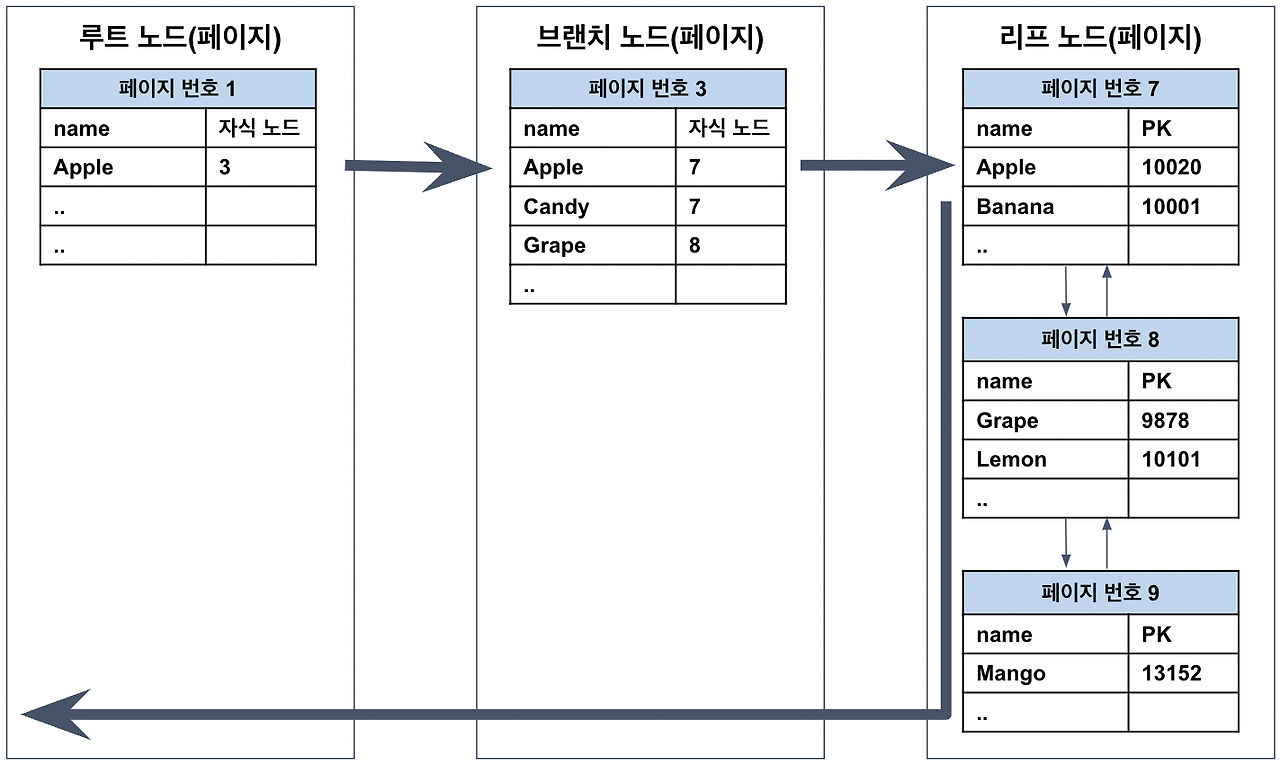
출처: https://mangkyu.tistory.com/286
인덱스가 두개이상의 조건으로 정렬되고, 찾으려는 조건이 후순위의 조건이면, 해당 조건의 데이터를 찾기 위해서 모든 인덱스를 돌아야 할 것 입니다.
-> 이러한 경우는 풀 테이블 스캔보다 빠를 뿐이지 실제 인덱스를 사용한다고 말하기도 어렵습니다.
Loose Index Scan
인덱스를 듬성듬성 읽는 스캔하는 방식을 의미하며, GROUP BY나 MIN() 또는 MAX()와 같은 집합 함수를 사용하는 쿼리를 최적화할 때 사용되며, 중간에 불필요한 인덱스는 무시하고 넘어갑니다.
예시
CREATE TABLE employees (
id INT PRIMARY KEY,
department VARCHAR(50),
salary INT
);
-- 인덱스 생성
CREATE INDEX idx_department_salary ON employees (department, salary);department,salary를 기준으로 인덱스를 생성합니다.
SELECT department, MAX(salary)
FROM employees
GROUP BY department;이 쿼리를 실행시, 중간값의 salary는 건너뛰고 가장 큰 값만을 탐색합니다. 이를 통해서 훨씬 빠른 스캔을 가능하게 합니다.
🧐인덱스를 적용한 프로젝트 코드 리팩토링
페이징 기법에 대한 고려
- 원래 리팩토링을 위해서 페이징 기법을 사용하려고 했으나, 현재의 비즈니스 로직과 맞지 않음을 공부하는 과정에서 알게 되었다.
- 페이징 기법은 게시판에서 전체 데이터를 그때 그때 보여주는 게 아닌, 게시판에 보여지는 데이터의 갯수만 서버단에서 클라이언트단으로 넘겨줌으로써 (이 때 넘겨주는 데이터 리스트의 단위를 페이지라고 한다), 훨씬 나은 성능을 제공하는 기법이다.
- 따라서 현재 최적화하려는 findTop3Videos의 경우와는 다르다.
- findTop3Videos 메서드는 시작 페이지에서만 상위 조회수 3개의 비디오를 보여주는 경우이므로, 위처럼 페이지 단위의 리스트를 클라이언트 단으로 넘겨줄 이유가 없음을 알게 되었다.
인덱스 도입
Spring Data JPA에서는 단순한 SQL의 OrderBy와 Limit의 기능을
findTop3ByOrderByCountDesc()처럼 Top이 Limit의 기능을, OrderBy를 OrderByCountDesc를 통해서 이름을 정의함으로써 기능을 만들 수 있다.
findTop3ByOrderByCountDesc()은 다음과 같은 쿼리를 만든다.
Select * From videos order by count desc limit 3이 쿼리 내에서는 우선 정렬을 하고, 상위 3개의 결과를 반환하는데, MySQL 옵티마이저는
정렬 시 indexing이 안 되어있으면 버퍼에 데이터를 넣어두고 정렬하는 filesort를 사용한다.
하지만 인덱싱을 활용하면 sort를 거치지 않고, 결과를 반환하기에 더 빠른 결과를 가져올 수 있다.
현재 count에 대한 인덱싱이 되어 있지 않아, 레코드 수가 많아지면 정렬 과정을 거쳐야 하므로 느려질 수밖에 없다.
따라서 count에 대해서 인덱스를 적용해보고자 한다.
인덱싱 성능 테스트
video table에서 count를 인덱싱 적용한 것이다.
성능 테스트는SHOW PROFILES;를 통해서 쿼리문 수행 시간을 비교할 것이다.
인덱싱 적용
인덱싱 적용 코드
@Entity
@Getter
@Table(indexes = @Index(name="idx_count", columnList = "count"))
public class Videos {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "video_id")
private Long id;
@Column(length = 2048)
private String url;
private String title;
@Column(length = 2048)
private String thumbnail_url;
private Long price;
@Column(name = "video_rank")
// 추가 필드 생략
}@Index 속성
| 속성 | 설명 |
|---|---|
name | 인덱스 이름. 데이터베이스에서 인덱스를 식별할 때 사용. |
columnList | 인덱스를 적용할 컬럼들. 여러 컬럼을 콤마로 구분하여 설정 가능. |
unique | true로 설정하면 인덱스를 유니크 인덱스로 생성. 기본값은 false. |
총 갯수가 1000개일 때
인덱싱 적용 전
인덱싱 적용 후
쿼리 성능이
0.00104→0.00033으로 향상됨을 확인.
총 갯수가 10000개일 때
인덱싱 적용 전
인덱싱 적용 후
인덱스 적용 전
0.009398에서 적용 후0.00033으로
속도가 매우 향상됨을 확인.
총 갯수가 100000개일 때
인덱싱 적용 전
인덱싱 적용 후
0.056sec → 0.00037sec로 정렬 속도가 크게 개선.
인덱스 적용 전에는 MySQL이 테이블의 모든 데이터를 읽고 정렬한 후, 상위 3개의 결과를 반환.
반면 인덱스를 적용하면, 정렬 없이 range index scan을 사용하여 쿼리를 훨씬 빠르게 수행.
조건에 맞는 로우의 갯수가 많아지면?
데이터가 1000개일 때
쿼리
SELECT * FROM videos ORDER BY count DESC LIMIT 300;조건에 맞는 로우의 갯수가 많아질 때의 결과 분석
적용 전
적용 후
성능 상 큰 차이가 나지 않음을 확인.
결과에 대한 고찰
조건에 맞는 로우의 갯수가 전체 데이터 비율 중 적은 경우
- 조건에 맞는 로우의 비율이 전체 데이터의 20~25% 이하일 때 인덱스 사용이 효율적이다.
- 데이터의 규모가 커질수록 성능 이점이 더욱 커지며, 정렬의 비용이 감소한다.
조건에 맞는 로우의 갯수가 전체 데이터 비율 중 많은 경우
- 조건에 맞는 로우의 비율이 20~25%를 초과하면, 인덱스 사용의 성능 차이가 크지 않거나 오히려 느릴 수 있다.
- 이 경우, 공간상의 이점을 위해 인덱스를 사용하지 않는 것이 더 적합하다.
원인 분석
-
랜덤 IO 발생
- 인덱스를 통해 찾은 각 레코드 주소를 기반으로 데이터를 접근하는 과정에서 랜덤 IO가 발생한다.
- 디스크의 비연속적 위치를 읽게 되어 성능 저하를 초래한다.
-
오버헤드 증가
- 데이터 범위가 넓어질수록 랜덤 IO가 반복적으로 발생하여 성능 저하와 오버헤드 증가를 유발한다.
-
순차 접근의 효율성
- 조건에 맞는 데이터가 많을 경우, 인덱스를 사용하는 것보다 순차적으로 데이터를 읽는 방식이 더 빠르고 효율적이다.
결론
- 인덱
스 사용의 적합성은 데이터 비율과 크기에 따라 달라진다.- 데이터의 일부만 접근하는 경우에는 인덱스 사용이 성능에 큰 도움이 된다.
- 그러나 조건에 맞는 데이터가 전체 데이터의 상당 부분을 차지하면, 인덱스 사용은 큰 이점을 제공하지 않는다.
✨전체 결론
b+tree구조인 인덱스를 사용하면 조건문을 이용하는 조회 작업시 빠르게 접근 할 수 있다. 또한 mysql은 PK기반의 클러스터링 인덱스를 사용해서 다른 인덱스와 결합해서 인덱스로부터 실제 데이터를 빠르게 찾는다.
그러나 이러한 인덱스도 일반적으로 사용하는 range Index scan의 경우 해당 조건에 맞는 조회 레코드가 너무 많을 시 레코드 주소에 접근할 때, Random IO가 발생해서 오버헤드가 발생할 수 있다. 또한 인덱스 내부의 페이지의 크기또한 제한되어있으므로, 인덱스 설계시 Trade-Off를 생각하고 설계를 해야할 것 같다.
참고

