해당 글은 Dev원영님의 유튜브를 보고 쓴 글입니다!
도입
다량의 데이터를 처리하기 위해서는 서버의 스케일 아웃이 필연적이다. 서버가 많아짐에 따라, db등의 데이터를 저장해두는 공간 또한 늘어난다. 그에 따라서 각 서버들과 데이터 베이스의 연결 관계는 아래와 같이 복잡해질 수 있다.
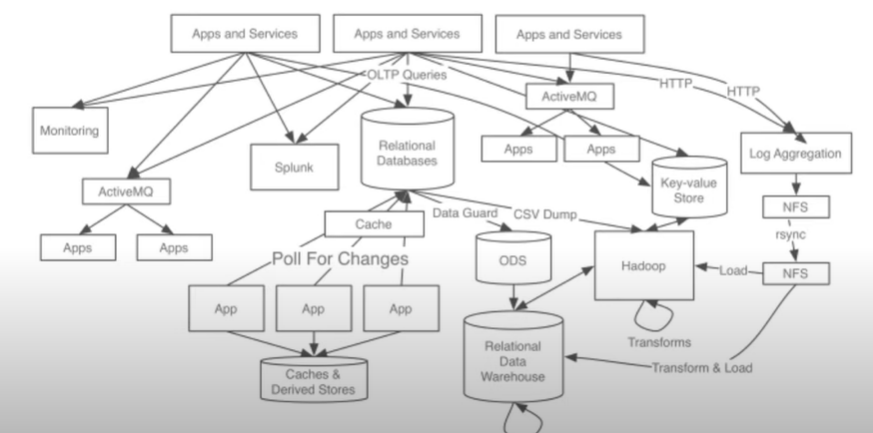
이렇게 복잡해진 연결관계는 다음과 같은 문제점을 야기한다.
- 서버들에서 동시에 요청이 들어오는 경우, 데이터베이스에 과부하가 발생할 수 있다.
- 트래픽이 급증하면 데이터베이스의 처리 능력에 병목이 발생하고, 이에 따라 서비스 전체의 응답 속도가 느려질 수 있다.
- 서비스가 확장될수록 서버-DB 간의 직접 연결 수가 증가하여, 관리와 유지보수가 복잡해진다.
- 데이터의 일관성과 동기화가 어려워지고, 특정 서버나 DB에 장애가 발생할 경우 시스템 전체에 영향을 줄 수 있다.
Kafka 도입의 필요성
이러한 문제들을 해결하기 위해 메시지 큐 시스템의 도입이 필요하며, 대표적인 솔루션으로 Apache Kafka가 있다.
Kafka는 서버와 데이터베이스 사이에 중간 계층(Message Broker) 역할을 수행함으로써 다음과 같은 이점을 제공한다.
- 서버와 데이터베이스의 결합도를 낮춰 유연성을 확보할 수 있다.
- 비동기 처리로 데이터베이스 부하를 줄이고, 트래픽 급증 시에도 안정적인 서비스 제공이 가능하다.
- 데이터를 여러 소비자(Consumer)가 동시에 읽어도 독립적으로 처리할 수 있어 확장성과 장애 대응력이 향상된다.
- 이벤트 기반 아키텍처 구현에 적합하여 실시간 처리 시스템 구축에 활용 가능하다.
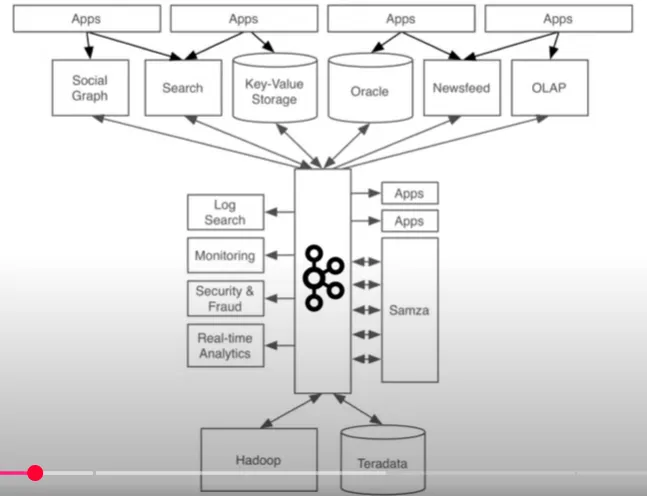
토픽
Kafka에서는 데이터를 보내는 애플리케이션을 Producer, 데이터를 받는 애플리케이션을 Consumer라고 한다.
Producer는 Kafka에 데이터를 토픽(Topic) 단위로 전달하며, 각 토픽은 의미에 따라 이름을 붙여 구분할 수 있다.
Consumer는 특정 토픽에 쌓인 데이터를 오프셋(Offset)이라는 기준에 따라 순차적으로 소비한다. 오프셋은 Consumer가 현재까지 읽은 메시지의 위치를 나타낸다.
Kafka의 각 토픽은 여러 개의 파티션(Partition)으로 분할되어 데이터를 저장하고 관리한다. 각 파티션은 독립적인 큐처럼 동작하며, 한 파티션 안에서는 먼저 들어간 데이터가 먼저 소비되는 FIFO(First In First Out) 방식으로 처리된다.
하지만 Kafka는 토픽 전체 수준에서는 순서를 보장하지 않는다. 즉, 여러 파티션에 분산된 메시지들은 FIFO가 적용되지 않는다. 정확한 순서가 필요한 경우, 반드시 동일한 Key를 사용하여 같은 파티션에 메시지를 보내야 한다.
또한 Kafka에서는 메시지가 소비되더라도 바로 삭제되지 않는다.
- 컨슈머 그룹의 오프셋만 이동할 뿐, 데이터는 여전히 Kafka에 남아 다른 컨슈머 그룹에서 재사용할 수 있다.
auto.offset.reset=earliest설정을 사용하면, 새로운 컨슈머 그룹은 가장 처음부터 데이터 재처리가 가능하다.
토픽의 데이터 삭제 여부는 Retention 설정에 따라 결정된다.
- 토픽별로 보관 기간 (retention.ms) 또는 디스크 사용량 (retention.bytes) 기준으로 데이터가 자동 삭제된다.
파티션과 키 (Partition & Key)
한 토픽에 2개 이상의 파티션이 존재하는 경우, Producer가 전송하는 메시지가 어떤 파티션으로 들어갈지를 결정해야 한다.
- Key가 없는 경우: Kafka 2.4 이후의 기본 파티셔너는 Sticky Partitioner 방식을 사용한다. → 동일한 배치(batch)는 같은 파티션에 보내고, 특정 조건에 따라 파티션이 변경된다. → 즉, Round Robin 방식은 사용되지 않는다.
- Key가 있는 경우: Key 값을 기준으로 Hash 연산을 통해 항상 같은 파티션으로 메시지가 전달된다. → 이는 같은 Key의 데이터 순서 보장과 일관성 유지가 필요한 경우 유용하다.
따라서 순서(FIFO)가 중요한 상황에서는 반드시 Key를 지정하여 같은 파티션에 메시지를 보내야 한다.

파티션 수 변경 시 주의사항
- 파티션 수는 늘릴 수 있지만, 줄일 수는 없다.
- 파티션을 늘리더라도 기존 데이터의 파티션은 변경되지 않고, 새로 추가된 파티션에만 메시지가 분산된다.
- 파티션 수가 서비스 성능, 병렬성, 순서 보장에 직접적인 영향을 미치므로, 초기 설계 시 신중한 결정이 필수다.
Broker,Replication,ISR
Broker
- Broker는 Kafka의 핵심 구성 요소로, 메시지 데이터를 저장하고 관리하는 서버이다.
- 하나의 서버→ 하나의 브로커
- 여러 개의 Broker가 모여 Kafka 클러스터를 구성한다.
- Producer는 Broker에 메시지를 보내고, Consumer는 Broker로부터 메시지를 읽어간다.
- 각각의 Broker는 특정 토픽의 일부 파티션을 담당하고 있다.
- 클러스터 내에 Broker가 여러 대일 경우, 각 Broker는 특정 파티션의 데이터를 분산해서 저장한다.
Replication
- Replication은 Kafka의 데이터 신뢰성과 가용성을 보장하는 메커니즘이다.
- 각 파티션은 하나의 리더(Leader)와 여러 개의 팔로워(Follower) 복제본으로 구성된다.
- 리더 파티션은 읽기와 쓰기 작업을 처리하고, 팔로워는 리더의 데이터를 복제하여 장애 상황에 대비한다.
- replication.factor 값을 통해 복제 개수를 지정할 수 있다. (예: replication.factor=3 → 총 3개의 복제본)
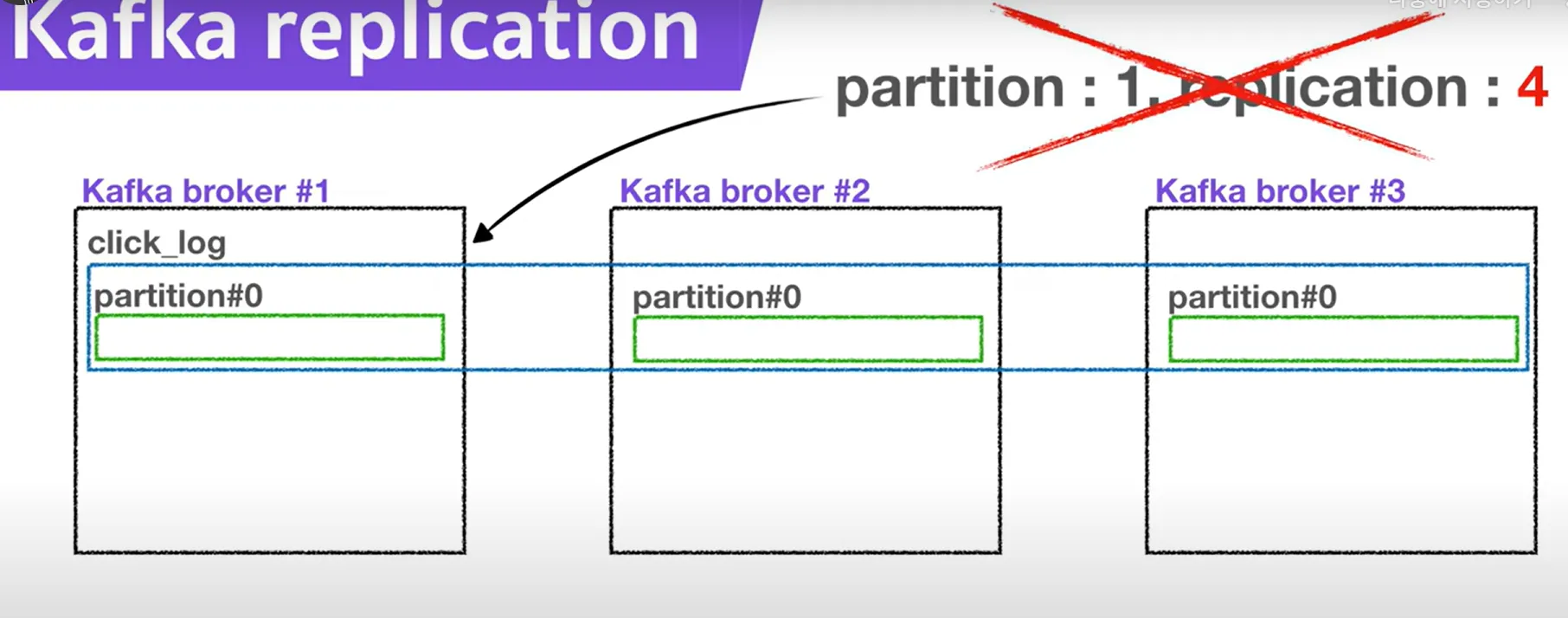
ISR (In-Sync Replicas)
- ISR (In-Sync Replicas)는 현재 리더와 동일한 데이터를 유지하고 있는 팔로워 복제본 목록이다.
- ISR에 포함된 팔로워는 리더와 일정 시간 내에 데이터 동기화가 완료된 상태를 의미한다.
- 만약 팔로워가 리더의 데이터를 따라가지 못하면 ISR에서 제외된다.
- Kafka는 ISR에 포함된 복제본 중 하나를 장애 시 새로운 리더로 자동 선출한다.
- ISR 메커니즘 덕분에 Kafka는 장애 복구와 데이터 일관성을 안정적으로 유지할 수 있다.
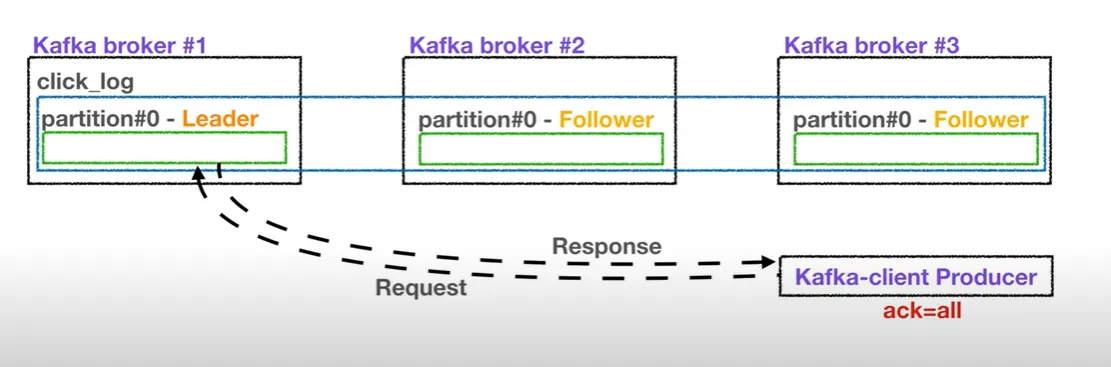
ACK (Acknowledgment)
- ACK (Acknowledgment)는 Producer가 메시지를 전송한 후, Broker로부터 받는 응답 방식을 의미한다.
- Kafka에서는 acks 설정을 통해 Producer가 메시지 전송 성공 여부를 확인하는 수준을 조절할 수 있다.
| acks 설정 값 | 의미 | 신뢰성 | 속도 |
|---|---|---|---|
| acks=0 | Producer는 Broker의 응답을 기다리지 않고 바로 성공으로 처리 | 낮음 | 빠름 |
| acks=1 | Leader Broker가 메시지를 받으면 성공으로 간주 | 보통 | 보통 |
| acks=all (or -1) | ISR에 있는 모든 Follower가 데이터를 복제해야 성공으로 처리 | 매우 높음 | 느림 |
- 신뢰성이 중요한 금융, 결제 시스템에서는
acks=all이 사용되며, 속도가 중요한 경우acks=1또는acks=0이 사용된다. acks=all과 함께 min.insync.replicas 설정을 통해 최소 동기화 복제본 수도 함께 설정해야 데이터 안전성을 보장할 수 있다.
파티셔너 (Partitioner)
파티셔너란?
- Kafka에서 Producer가 보낸 메시지를 어떤 파티션에 넣을지 결정하는 역할을 한다.
- 하나의 토픽은 여러 개의 파티션으로 구성될 수 있기 때문에, Producer는 반드시 파티셔너를 통해 메시지를 특정 파티션에 할당해야 한다.
2. 파티셔너의 동작 방식
| 상황 | 파티셔닝 방법 |
|---|---|
| Key가 있는 경우 | Key의 Hash 값을 기반으로 특정 파티션으로 고정 |
| Key가 없는 경우 | Kafka 2.4 이후 → Sticky Partitioner 사용같은 배치(Batch)는 동일 파티션 → 이후 다른 파티션으로 변경 |
3. Key가 있을 때
- 같은 Key의 메시지는 반드시 같은 파티션으로 들어간다.
- 예시: 같은 유저 ID, 같은 주문 ID 등
4. Key가 없을 때
- Kafka 2.4 버전부터는 Sticky Partitioner가 기본값이다.
- Sticky Partitioner는 한 파티션에 여러 메시지를 일정 시간 또는 일정 개수까지 묶어서 보낸 뒤 다른 파티션으로 넘어간다.
- 과거 버전처럼 Round Robin 방식으로 하나씩 번갈아 보내지 않는다.
5. 파티션 수와 관계
- 파티션 수가 늘어나면 Hash 값 → (파티션 수 % Hash 값) 공식에 따라 할당 파티션이 변할 수 있다.
- 따라서 파티션 수는 초기 설계 시 신중히 결정해야 한다.
- 파티션은 늘릴 수 있지만, 줄일 수 없다.
6. 커스텀 파티셔너
- 필요에 따라 Custom Partitioner를 구현할 수 있다.
- 비즈니스 규칙(예: VIP 고객은 특정 파티션)에 따라 파티션을 제어 가능하다.
컨슈머 랙 (Consumer Lag)
1. 컨슈머 랙이란?
- 컨슈머 랙(Consumer Lag)은 Kafka의 특정 파티션에서 마지막으로 생산된 메시지(Producer가 보낸 메시지)와 Consumer가 마지막으로 읽은 메시지(offset) 간의 차이를 의미한다.
- 쉽게 말해 아직 소비되지 않은 메시지의 개수이다.
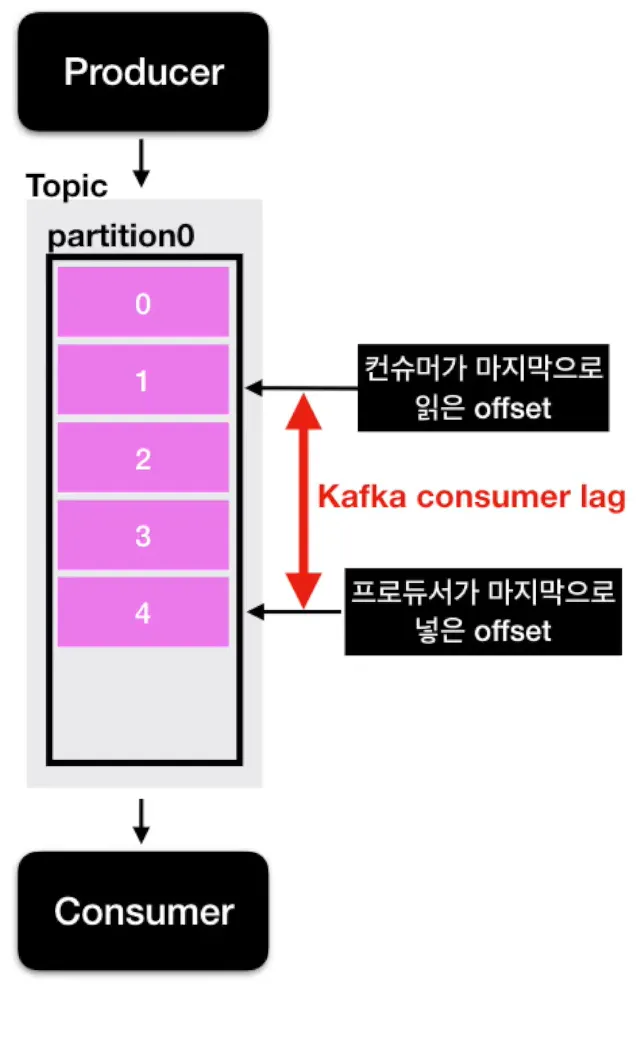
2. 왜 중요한가?
- Consumer Lag이 크면 → 데이터 처리 지연, 서비스 지연 가능성이 높아진다.
- 실시간성이 중요한 시스템(예: 실시간 분석, 알림 서비스)에서는 Lag이 0 또는 매우 작아야 한다.
3. Consumer Lag 계산 방법
Lag = Latest Offset - Current Committed Offset
| 파티션 | 최신 오프셋 | 현재 오프셋 | Lag |
|---|---|---|---|
| 0 | 1200 | 1195 | 5 |
Kafka Burrow
1. Kafka Burrow란?
- Kafka Burrow는 Consumer Lag을 모니터링하고 Health Check를 자동으로 평가하는 오픈소스 Kafka 모니터링 시스템이다.
- LinkedIn에서 개발했다.
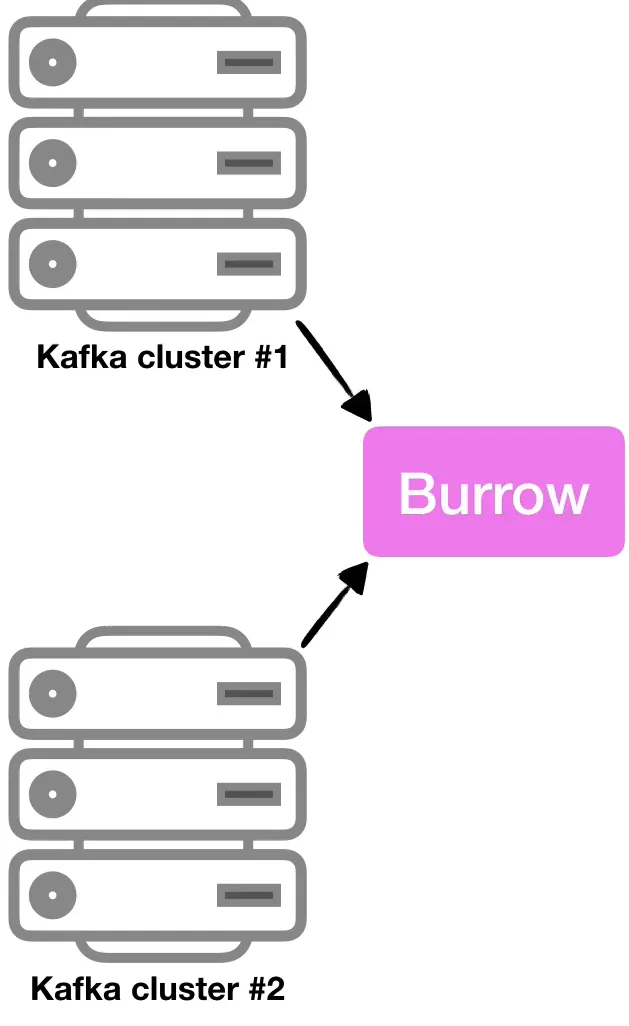
2. Burrow의 역할
- 단순히 현재 Lag만 보여주는 것이 아니라, 시간에 따른 Lag의 변화 추세까지 분석한다.
- Consumer Group의 상태를 다음과 같이 자동 분류한다:
- Sliding Window를 통해서 가능함
- OK: 정상적으로 Lag 없이 소비 중
- WARN: Lag이 일시적으로 증가
- STOP: Lag이 계속 쌓이고 소비가 멈춤
- STALL: 컨슈머의 오프셋이 오래동안 정체됨
3. Burrow 장점
- Lag 변화까지 감지 → 동적으로 연동된다.
- REST API 제공 → Prometheus, Grafana 등과 연동 가능
- 설정만 하면 Kafka 클러스터 내 모든 Consumer Group 자동 모니터링

와 내용 너무 좋은데요? KAFKA 마스터 했습니다