Data Analysis About Bitcoin Transaction
2021-1 Information Security
Gu San | Yang Yue
https://github.com/MountainNine/bitcoin_fraud_detection
Introduction
Blockchain is an intelligent P2P network that uses a decentralized database to identify, disseminate, and record information, also known as the Internet of Value. As such blockchain-based cryptocurrencies become known, their demand is increasing even more. However, as the demand, the number of frauds using cryptocurrency is increasing. In this paper, we will look at previous Bitcoin fraud cases and fraud detection tools. Then, we will look at the distribution of user data based on the transaction data. To the end, we analyze the data.
Previous Incidents
1. Value overflow event(August 2010)
Essentially, when running the code, if the output is too large to overflow in the summation, then the code that checks Bitcoin transactions will be invalid. The hacker used this to create the block and added two transactions of 92 billion BTC. This is an early example of a cryptocurrency "hard fork", and this is one of the few cases where hackers directly attacked blockchain technology.
2. Bitfinex (August 2016)
This is the second largest exchange hacking after the MtGox hot wallet was stolen. Ironically, the upgrade designed to improve security has loopholes and was exploited by hackers. Bitfinex uses the software provided by BitGo to establish a multi-signature system to authorize transactions. It is unclear how hackers can easily bypass the need for multiple keys, but the most commonly accepted assumption is that the system on the Bitfinex server is improperly installed. The hacker stole 120,000 BTC, which was worth 72 million U.S. dollars at the time.
3. Coinrail and Bithumb (June 2018)
In June 2018, the hot wallets of two South Korean exchanges were attacked. Among them, Coinrail lost 5,300 BTC (worth 40 million U.S. dollars), and Bithumb lost 31 million U.S. dollars.
Existing Tools
1. PARSIQ
PARSIQ is the first blockchain automation platform that allows users to set up "smart triggers" using ParsiQL, its advanced blockchain streaming language. Smart trigger can interact with events on the blockchain. PARSIQ also uses a tool called Mempool, which is a digital asset early warning system. If a major event occurs, such as a large number of digital assets entering the exchange, users will be the first to see it in Mempool.
2. Coral
Coral is using blockchain to provide predictive analysis scores to help protect consumers of cryptocurrencies. Coral continuously builds a database of malicious or suspicious phishing scams and related addresses. Coral is integrated into most wallets and user trading interfaces, which means it can warn ICO investors before providing encrypted files to reckless ICO websites.
Dataset
1. Reading Transaction Dataset File
The transaction dataset file’s size is 26.8 GB, so it is hard to read the file. First, we split the file with file split program. Obviously, split files were broken, but we found that they have the same json format for each line. So we split the file for 100 lines with Windows command, and created 46 split files.
2. Transaction Construction
1) Merkleroot
Merkel root The root of the Merkel tree is the root node of the tree, which is the result of multiple hash calculations of all node pairs in the tree. The block header must include the valid Merkel root calculated from all transaction hashes in the block.
Merkel tree To generate a complete Merkle tree, you need to recursively hash the pair of hash nodes, and insert the newly generated hash node into the Merkle tree until there is only one hash node, which is the root of the Merkle tree. In Bitcoin, leaf nodes come from transactions in a single block.
2) Nonce
Headings The changing number at the end of the sentence is called a nonce (random number).
Nonce is used to change the output of the encryption function.
There is also a Nonce value in the block header, which records the number of hash recalculations. The Nonce value of the 100,000th block is 274148111, that is, after 274 million calculations, a valid Hash is obtained, and the block can be added to the blockchain.
Random number
The random number is a 32-bit (4 byte) field in the Bitcoin block. After the value is set, the hash value of the block can be calculated. The hash value starts with multiple 0s. The values of other fields in the block are unchanged because they have certain meanings.
Excess random number
As the difficulty increases, miners usually fail to find a block after cycling the random value 400 million times. Because the coinbase script can store 2 to 100 bytes of data, miners began to use this storage space as an excess nonce space, allowing them to use a larger range of block header hash values to find valid blocks.
3) Previousblockhash
Hash of the previous block.
4) Hash
content
The Hash of each block is calculated for the "block header" (Head)
algorithm
SHA256 is the Hash algorithm of the blockchain
condition
Only Hash that meets the conditions will be accepted by the blockchain. This condition is particularly harsh, so that most hashes do not meet the requirements and must be recalculated.
length
The hash length of the blockchain is 256 bits
Corollary 1: The Hash of each block is different, and the block can be identified by Hash.
Corollary 2: If the content of a block changes, its Hash will definitely change.
5) Nextblockhash
Hash of the next block.
6) Vin(input) Vout(output)
In every vin, there is a txid field
For every vout, there are 1 field value, field n, and field scriptPubKey.
Value is the amount of money transferred to the other party, and n is the number in the output (that is, the field vout in the corresponding vin when the UTXO is spent next time).
scriptPubKey is the public key of the other party.
There are two fields in scriptSig, asm and hex, asm is assembly (assembly, or the meaning of assembly), and hex is its hexadecimal expression.
Script Engine
Simply looking at the scriptPubKey is incomprehensible. We need to splice the scriptPubKey with the next scriptSig of the transaction that will cost it.
scriptPubKey represents the public key information of the payee; the vin in the next transaction that will spend this UTXO must have the previous information of the private key corresponding to the public key, that is, scriptSig.
The two parts are spliced together, with scriptSig in front and scriptPubKey in back (note: scriptPubKey is the current transaction, scriptSig is the next transaction, which will cost this UTXO).
Among them, the contents of the two parts of signature and pub key are similar to the asm part in vin above. Because the string is too long, it is omitted here and replaced by.
The above string of things is a script, a simple DSL language (about what is DSL, Baidu's own).
This string of scripts is thrown into the Script Engine for execution, and the execution result is TRUE/FALSE, indicating whether the person is eligible to spend the money, or whether the transaction is valid.
Processing
1. Transaction Count
Every line has nTx, which saves the number of transactions, and medianTime, which the transaction occured. We saved every nTx value and medianTime. At the result, we knew total transaction count of January 2019 is 9,222,178 counts. Following code express how to save transaction count per day.
def save_transaction():
median_list = []
nTx = []
for i in range(1, 47):
file_name = "D:\\download\coin\coin{}.json".format(i)
with open(file_name, 'r') as file_data:
line = file_data.readline()
while line:
data = json.loads(line)
median_list.append(data['mediantime'])
nTx.append(data['nTx'])
line = file_data.readline()
file_data.close()
print("coin{} Clear".format(i))
df_transaction = pd.DataFrame({'medianTime': median_list, 'nTx': nTx})
df_transaction.to_csv('./transaction.csv', sep=',', na_rep='NaN')
def show_transaction():
data = pd.read_csv("transaction.csv")
data['medianTime'] = pd.to_datetime(data['medianTime'], unit='s')
df = data.groupby(by=data['medianTime'].dt.date).sum()
y = df.get('nTx')
plt.bar(df.index, y)
plt.show()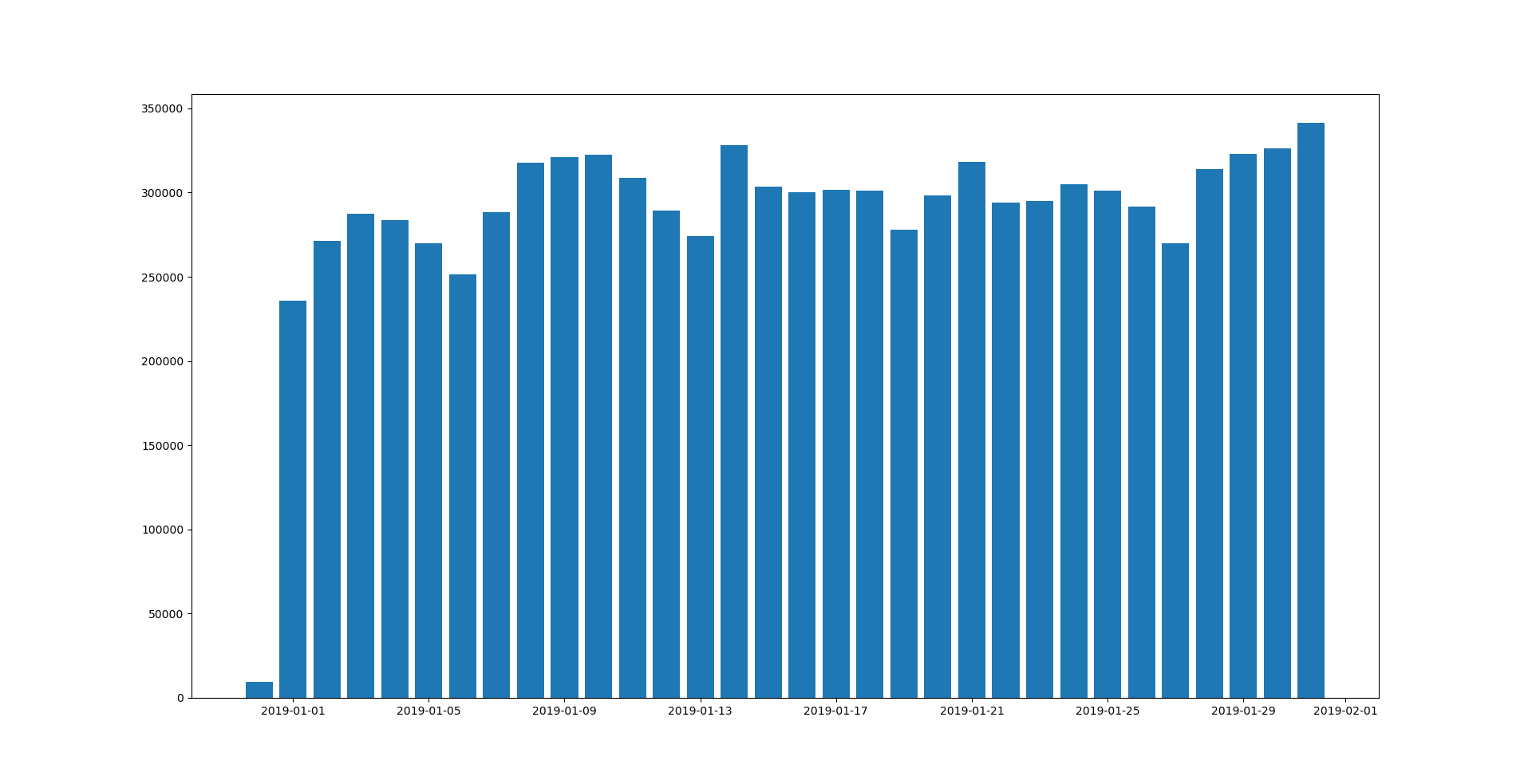
2. Address Count
In tx(transaction) array of each line, there are addresses that receive Bitcoin, and values of Bitcoin. We extracted those addresses and values, and transaction counts per address in each tx array, and saved to csv file for next processing. Total unique wallet address count of January 2019 is 10,541,781 counts. Following code express to save unique wallet address.
def get_address():
sum_nTx = 0
address = set()
for i in range(1, 47):
file_name = "D:\\download\coin\coin{}.json".format(i)
with open(file_name, 'r') as file_data:
line = file_data.readline()
while line:
data = json.loads(line)
for tx in data['tx']:
for vout in tx['vout']:
if vout['scriptPubKey']['type'] not in ('nulldata', 'nonstandard'):
address.update(vout['scriptPubKey']['addresses'])
line = file_data.readline()
file_data.close()
print("coin{} Clear.".format(i))
text_file = open('address.txt', 'w')
for a in address:
text_file.write(a + "\n")
text_file.close()3. Abusing Address
There are abusing addresses because of ransomware, fraud, etc. We crawled those abusing users, and compared with previous address data. About 500 addresses are abusing address. Following code represents how we crawled those users, and following graph represents the distribution of abusing address and not abusing address with transaction count and sum of value per address.
def get_abuse_address():
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time
import numpy as np
abuse_addresses = set()
for i in range(1, 2248):
page = requests.get("https://www.bitcoinabuse.com/reports?page={}".format(i))
soup = BeautifulSoup(page.content, "html.parser")
for s in soup.select("div.col-xl-4 a"):
abuse_addresses.append(s.contents[0])
print("{} passed.".format(i))
time.sleep(1)
df = pd.DataFrame(abuse_addresses)
df_address = pd.read_csv('users_new.csv', index_col=False)
common_address = pd.merge(df, df_address, how='inner', left_on=0, right_on='address')
df_address['is_fraud'] = np.where(df_address['address'].isin(common_address['address']), 1, 0)
df_address.to_csv('users_new_2.csv', index=None)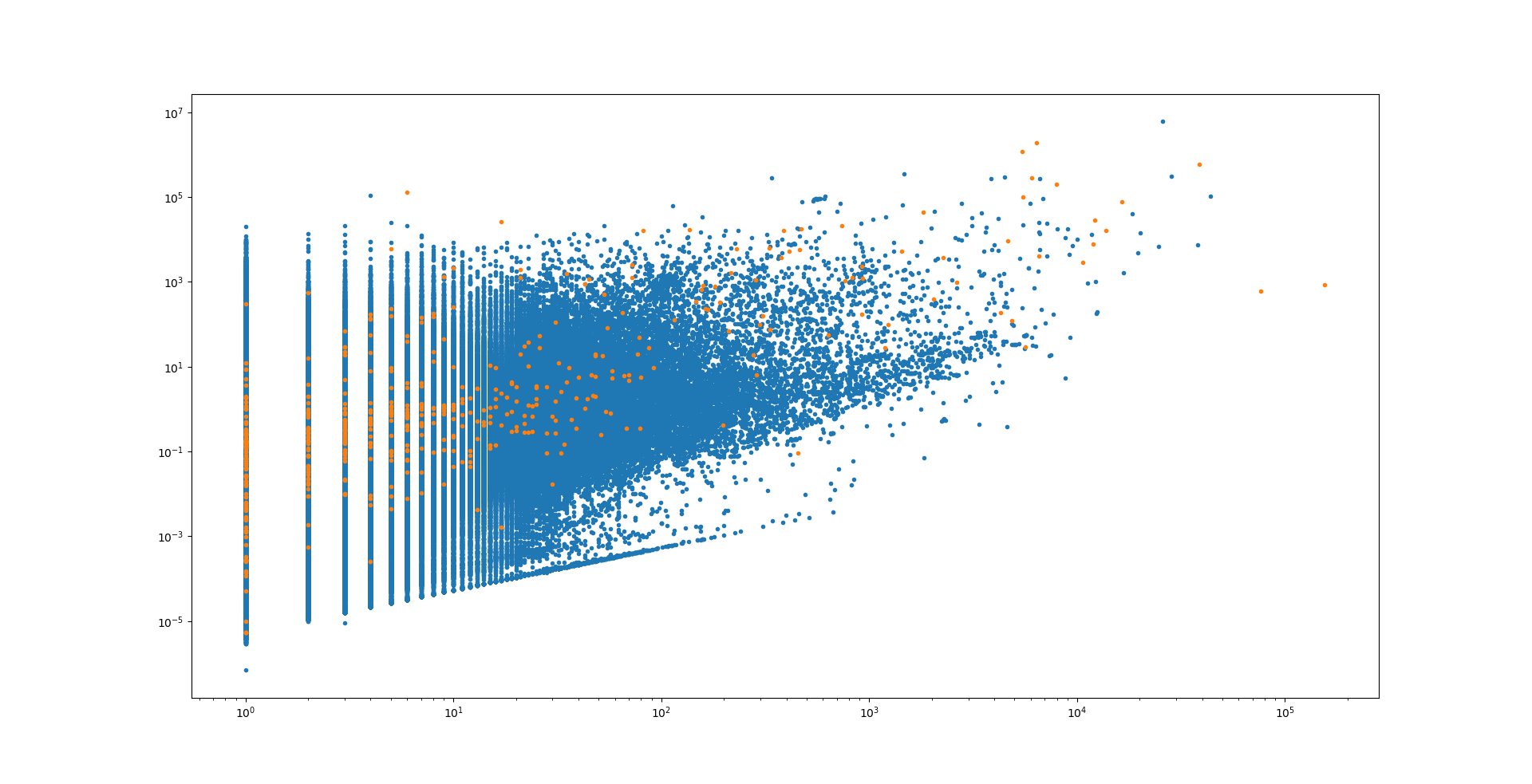
Clustering
We clustered above graph with Gaussian Mixture Model. Gaussian mixture model is a probabilistic model that assumes all the data points are generated from a mixture of a finite number of Gaussian distributions with unknown parameters. Following code and graph is the clustered graph with Gaussian mixture model(n=9).
def gaussian_mixture():
from sklearn.mixture import GaussianMixture
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import time
df = pd.read_csv('users_new_3.csv', index_col=False)
list_gm = pd.DataFrame(map(list, zip(df['count'], df['sum'])))
gm = GaussianMixture(n_components=9, random_state=0).fit_predict(list_gm)
plt.scatter(list_gm[0], list_gm[1], s=9, c=gm)
plt.xscale('log')
plt.yscale('log')
plt.show()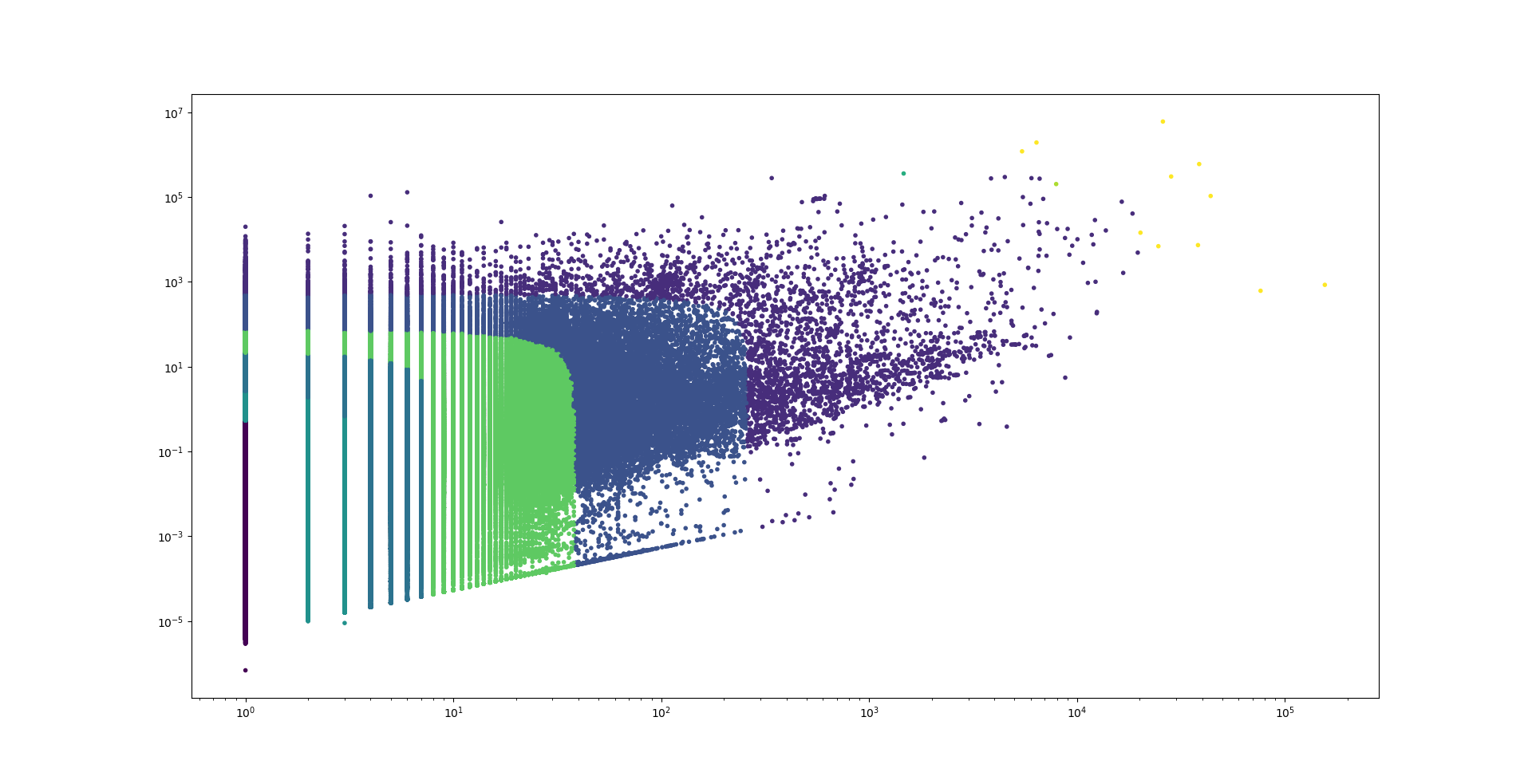
purple and yellow clusters tend to have a high proportion of abusing address. It seems the higher transaction count or the higher the value, the higher the probability of fraud.
Conclusion
In this paper, we have investigated the incident about Bitcoin fraud and existing fraud detection tools, Bitcoin transaction of January 2019, and abusing address. Then we have analyzed the distribution of address data with Gaussian Mixture Model Clustering.
We tried to cluster with DBSCAN(Density-based spatial clustering of applications with noise), but it had a memory shortage problem, and the clustering result didn’t appear. We will find the outlier based on density on next study.
