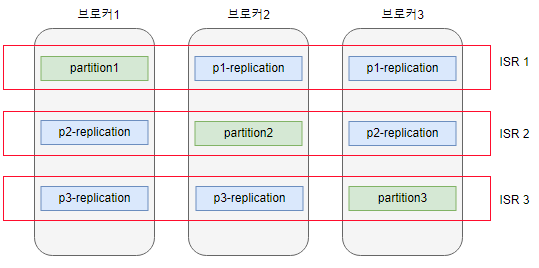
ISR(In-Sync-Replica)
카프카는 리더 파티션(=원본) 과 팔로워 파티션(=복제본) 을 ISR(In-Sync-Replica) 이라는 그룹으로 묶고 브로커에 장애가 생긴경우 리더-팔로워 간의 승격을 ISR 단위로 관리합니다.
- 리더 파티션: 원본 파티션을 의미하며, 데이터의 컨슘/프로듀스 는 리더 파티션을 통해 이루어 집니다.
- 팔로워 파티션: 원본 파티션의 복제본을 의미하며, 리더파티션의 데이터를 복제하여 저장합니다.
만약, 브로커에 장애가 발생하여 원본파티션을 사용할 수 없다면 카프카는 팔로워 파티션 중 하나를 리더 파티션으로 승격합니다.
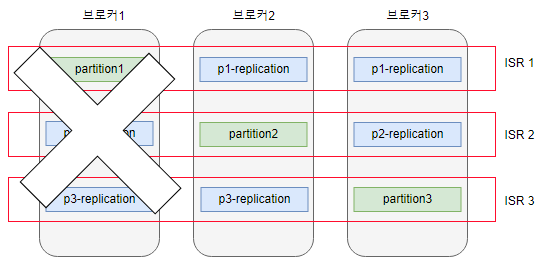
이 경우, partition1-replication 중 하나가 리더파티션의 역할을 맡게 됩니다.
카프카는 ISR 을 통해 브로커에 장애가 발생하더라도 고가용성을 유지할 수 있습니다.
ISR 관리
이러한 고가용성을 위해서 ISR 내 모든 팔로워가 데이터의 복제를 문제없이 수행하고 있어야 합니다.
이를 위해 리더 파티션은 ISR 내 팔로워 파티션을 감시하고 만약 복제를 제대로 수행하지 못하고 있는 팔로워가 있다면 ISR 에서 제외하고 이를 Out of Sync 라고 부릅니다.
리더는 Out of Sync 를 어떻게 판단할 수 있을까요?
- replica.lag.max.message
리더와 팔로워에 저장된 데이터 offset 의 차이가 해당 설정보다 크다면 ISR 에서 제외합니다.
이 설정은 순간적으로 데이터 처리량이 많아지면 offset 차이가 커지기 때문에 팔로워가 정상이더라도 ISR 에서 추방당할 가능성이 있습니다. 따라서 현재 해당 설정은 삭제되었습니다.
- replica.lag.times.max.ms
카프카 복제는 팔로워가 리더에게 일정 주기마다 데이터를 요청하는 pull 방식으로 동작합니다.
팔로워의 데이터 복제 요청이 해당 시간 내에 수행되지 않으면 ISR 에서 제외합니다.
기본적으로 ISR 에 속해 있어야만 리더로 선출될 수 있지만unclean.leader.election.enable=true 로 설정한다면 Out of Sync 상태에 있는 파티션도 리더로 선출될 수 있습니다.
이 경우, 데이터 유실 가능성이 높기 때문에 데이터의 특성에 따라 판단해야 합니다.
파티션 장애 ~ 복구 과정
파티션에 장애가 발생해 복구되기 까지의 과정을 알아보겠습니다.
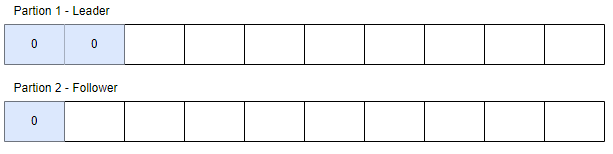
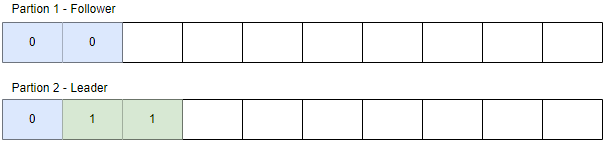
현재 파티션1 은 리더, 파티션2 는 팔로워 이고, 데이터 복제가 완전히 이루어지지 않은 상태입니다.
참고로, 이때 숫자 0 은 리더 에포크(Leader Epoch) 를 의미합니다.
리더 에포크란(Leader Epoch)?
0부터 시작해 리더 파티션이 바뀔때 마다 1씩 증가하는 값으로
장애가 발생했던 파티션 복구시 리더와의 데이터 싱크를 맞추기 위해 사용됩니다.

이 상태에서 파티션1에 장애가 발생하여 ISR 그룹에 있던 파티션2가 리더로 선출되었습니다.
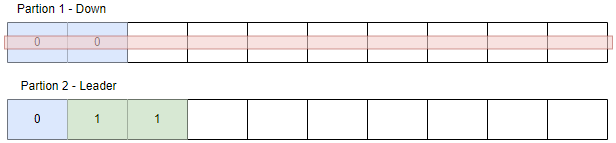
파티션2에는 2개의 데이터가 더 들어왔고 리더가 바뀌었으니 리더 에포크 값은 1 입니다.
파티션1이 다시 살아났고 데이터 복구를 위해 리더 파티션에 리더 에포크 요청(Leader Epoch Request)을 보냅니다.
이 요청에는 자기 자신의 마지막 리더 에포크 번호가 포함되어 있습니다. (해당 시나리오 에서는 0 이 되겠네요)

리더 파티션은 요청으로 받은 리더 에포크 번호의 마지막 offset 을 응답으로 반환합니다.
파티션1은 해당 응답을 기반으로 데이터를 삭제를 진행합니다.
여기서는 리더 파티션이 가지고 있는 0번 리더 에포크의 마지막 offset 이 0 이므로 파티션1은 0번 offset 이후의 데이터를 모두 삭제합니다.

이후 파티션1은 데이터 복제를 다시 시작합니다.
여기까지 ISR 에 대하여 알아보았습니다.
기존 하이 워터마크(High Watermark) 기반 데이터 복구의 문제점, 리더 에포크의 등장 이유 등 좀 더 자세한 내용에 대해서는 아래 레퍼런스를 읽어보면 도움이 될 것 같습니다.
