replication
replication 은 말 그대로 복제를 말합니다. 기본적으로 카프카는 파티션에 데이터를 저장합니다. 만약 운영중인 브로커가 다운된다면 해당 브로커에 있는 파티션은 사용할 수 없게 됩니다.
이를 방지하기 위해 카프카는 각 파티션을 복제(replication) 할 수 있는 기능을 제공합니다.
replication 만들기
카프카는 토픽을 생성할 때 또는 이미 생성된 토픽에 대하여 replication factor 라는 설정을 통해 복제본 개수를 지정할 수 있습니다.
kafka-topics.sh --create --topic --bootstrap-server localhost:9092 --partitions 3
위 command 처럼 replication factor 를 지정하지 않았다면 replication factor 는 기본값인 1로 설정되며 이 경우 복제본이 추가로 생성되지 않습니다.
kafka-topics.sh --create --topic --bootstrap-server localhost:9092 --replication-factor 2 --partitions 3
이 경우에는 replicatoin factor 가 2로 설정되어 복제본이 파티션 마다 하나씩 생성됩니다.
replication 분배
replication 은 브로커에 어떤식으로 배분될까요?
broker: 3, partition: 3, replication factor: 3 인 경우를 생각해봅시다.
브로커가 여러대로 구성된 경우, 카프카는 파티션과 복제본을 각 브로커에 밸런스있게 분배합니다.
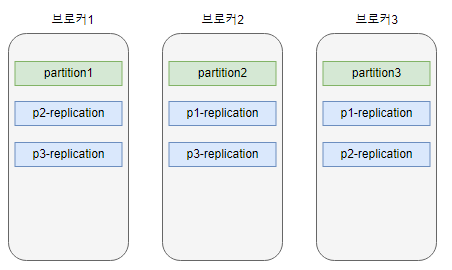
(p1-replicatoin 은 partition1 의 replication 을 의미합니다)
partition1 의 복제본은 브로커2와 3에 배정됩니다. 왜냐하면 브로커1에는 원본 파티션이 있기 때문입니다. broker1 이 down 되면 해당 브로커에 있는 데이터들은 모두 사용할 수 없으므로 원본과 복제본이 같은 브로커에 있다면 의미가 없습니다.
partition2, partition3 도 동일한 원리로 각 브로커에 분배됩니다.
refactor factor 가 broker 의 대수보다 크다면?
이 경우, 복제본이 각 브로커로 분배 되고도 남기 때문에 의미가 없습니다.
때문에 카프카는 replication factor 를 broker 대수보다 크게 설정하는 것을 허용하지 않고 있습니다.
ISR(In Sync Replica)
카프카에서는 원본 파티션을 리더 파티션, 복제본을 팔로워 파티션 이라고 부릅니다.
카프카는 이들을 합쳐 ISR 이라는 그룹으로 묶고 브로커에 장애가 생긴경우 ISR 단위로 리더-팔로워의 승격을 관리합니다.
ISR 에 대한 더 자세한 내용은 다음 포스팅에 작성하겠습니다.
