REVIEW

- Optimal Policy 를 위한 과정
- 주어진 MDP를 이용해 Transition Probability와 reward function을 구함
GOAL
- 목적함수를 사용하여 리워드의 총합을 최대화하는 policy를 찾기
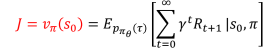
- 최적의 state값 또는 action 값 함수 기반하여 optimal policy 찾기
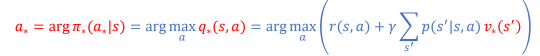
즉, 최적의 state value와 state를 찾으면 최적의 policy를 찾을 수 있다.
그렇다면 어떻게 q*와 v*를 어떻게 구할 것인가?
그 방법은 다음 2가지
1. Policy Iteration (policy evaluation and policy improvement)
- policy를 반복적으로 업그래이드 하겠다.
2. Value Iteration
이를 dynamic programming이라고 부른다.
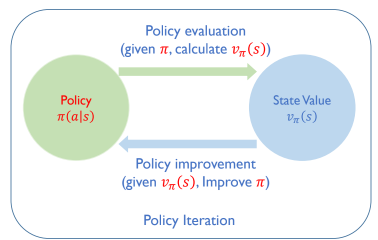
Planning by Dynamic Programming
-
For prediction
• Input: MDP S, A, p, r, ρ0, γ and policy π
• Output: value function vπ -
For control
• Input: MDP S, A, p, r, ρ0, γ
• Output: optimal value function v∗ and optimal policy π∗
Planning by DP: Methods
MDP에 관한 모든 정보를 알고 있고, 문제가 작을 때 활용 가능
-
Prediction : mdp와 policy가 주어졌을때, policy를 반복적으로 평가 (벨만 ex pectation 방정식 활용)
-
Control : mdp와 policy가 주어졌을때, policy반복적으로 평가 및 greedy policy (Bellman Expectation Equation) 와 value iteration (Bellman Optimal Equation)
Optimal Value Function vs. Optimal Policy
fixed-point iteration method의 필요성
fixed-point iteration method
fixed-point : 함수를 만족하는 해
fixed-point iteration : 해를 구하는 정의
어떻게 해를 구하는가?
초기값 x0에서 시작해서 반복적으로 찾아가겠다.
