MDP는 강화학습의 환경을 구성하는데 중요한 역할을 하는 수학적 기반
시간이 고정되어있다고 가정하면 순간의 state, action, reward는 랜덤변수
전체 Trajectory는 랜덤 프로세스
목표는 다음과 같다.
1. trajectory의 joint 확률을 규정 (여기서 쓰이는 과정이 markov 정리)
2. trajectory의 평균을 최대화를 하도록 어떤 액션을 취할지 결정

강화학습은 여기에서부터 시작된다.
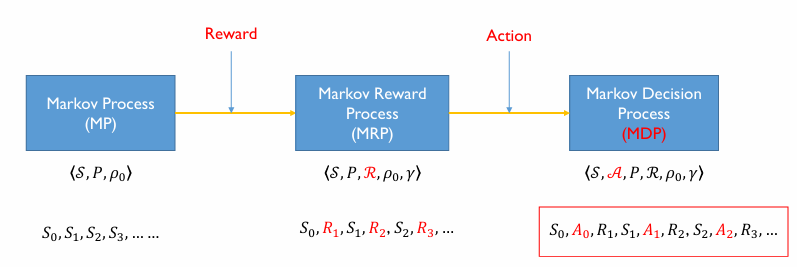
- Markov Process (state로 이루어진 프로세스)
여기에 reward 개념이 들어감 - Markov Reward Process
여기에 action policy가 들어감 - 최종 Markov Decision Process 완성
Markov Property
random process 특별히 마르코브 특징을 갖는다.
현재 직전까지의 history가 다음 상태에 영향을 미치지 않는다. (conditional independence)
마르코브는 state transition 확률만 알면 복잡한 joint 확률 대신에 마르코브 프로세스를 알 수 있게 된다.
예를 들면, 상태가 맑음, 흐림 두가지만 존재한다고 하자.
transition matrix (오늘 날씨에만 의존한다고 가정)은 다음과 같다.

최초의 확률은 P(맑음) = 0.6, P(흐림) = 0.4
오늘 상태가 '맑음'이라고 가정하고 다음 상태를 구하면 다음과 같다.
P(맑음,맑음,흐림 | 맑음) = P(맑음|맑음) P(맑음|맑음) P(흐림|맑음) = 0.8 0.8 0.2
