
엔티티 매핑시 주의사항
자바 객체의 필드와 관계형 데이터베이스의 테이블의 컬럼을 매핑하는 과정이다.
엔티티와 테이블 매핑
테이블과 매핑되기 원하는 객체는 반드시 @Entity 어노테이션을 클래스 선언부에 적어야한다.
@Entity 로 등록된 객체는 엔티티 매니저에게 crud를 요청할 수 있다.
@Entity 작성시 주의사항
- entity는 기본 생성자(protected , public)가 필수로 있어야 한다.
- final, enum, interface, inner 클래스에 사용불가
- 저장할 필드는 final 이어서는 안된다.
@Table
@Table(name = "db테이블명") 을 클래스선언부에 적어주어 매핑될 db 테이블명을 지정할 수 있다. 이 어노테이션을 작성하지 않으면 클래스이름으로 테이블과 엔티티객체를 매핑한다.
@Column
엔티티와 매핑될 DB 컬럼에 대한 정보를 제공한다.
@Column(name = "student_id")
String studentId;
저장될 엔티티 객체의 필드에 선언하며, 해당 필드가 저장될 DB 컬럼 명을 작성한다.
보통 DB는 student_id 처럼 언더바를 활용해 띄어쓰기를 표현하기 때문에 아예 엔티티의 컬럼명 매핑 방식을 언더바로 지정할 수도 있다.
〈property name="hibernate•ejb.naming—strategy" value=Horg.hibernate. cfg. ImprovedNamingStrategy" />persistence.xml 파일에 해당 옵션을 부여하면 엔티티객체의 카멜표기법으로 작성된 컬럼명을 언더바 표기법으로 바꿔서 매핑하게 된다.
기본키 매핑하기
〈property name="hibernate.id.new_generator_mappings" value="true" />
DB에서 자동 생성되는 기본키 매핑시 allocationSize 사용방식의 변경으로 인해 위의 설정을 persistence.xml에 추가해주면 좋다. 기본값은 false로 되어있다.
기본키 매핑 - DB의 primary key와 엔티티의 키 필드를 매핑한다.
@Id 어노테이션
- 자바기본형
- 자바 래퍼Wrapper형
- String
- java.util.Date
- java.sql.Date
- java.math.BigDecimal
- java.math.Biglnteger
위의 타입이 데이터베이스의 기본키로 사용될 수 있다.
직접 키로 지정하기
엔티티 객체 생성시 직접 키로 사용될 값을 지정할 때 사용한다.
키로 사용되길 원하는 타입의 필드 위에 @Id 어노테이션을 붙여 기본키로 매핑한다.
자동생성 키 매핑하기
데이터베이스에서 생성해주는 키 값을 엔티티 객체에서 사용하고 싶을때 선택하는 방식이다.
@Id 어노테이션과 @GenerateValue 어노테이션을 키로 사용될 필드에 함께 주어 매핑한다.
DB에서 자동 생성키를 제공하는 방식은 크게 Squence 객체를 사용한 방식과 Auto_Increment 방식이 존재한다. 각각의 방식에 따라서 @GenerateValue의 사용법도 달라진다.
@GenerateValue(strategy = GenerationType.IDENTITY)
우선 MySql 계통의 DB에서 제공하는 Auto_Increment 방식으로 생성된 기본 키 값을 매핑하는 방식을 알아보자.
방법은 위의 어노테이션을 @Id 어노테이션과 함께 필드에 부여하면 된다.
Auto_Increment 방식은 데이터베이스 테이블에 insert되는 시점에 키 값이 생성된다는 중요한 특징이 있다.
이런 특징으로 인해서 strategy = GenerationType.IDENTITY를 사용하게 되면 객 DB에서 생성된 키값을 가져오기 위한 insert가 즉시 일어난다.
다시말해 엔티티 객체를 영속성 컨텍스트에 저장하는 아래의 코드 시점에 DB로 쿼리가 즉시 실행된다. 쿼리의 쓰기지연이 일어나지 않는 것이다.
entityManager.persist(엔티티객체);
@GenerateValue(strategy = GenerationType.SEQUENCE)
오라클 및 몇몇 데이터베이스는 시퀀스라는 객체를 이용해 값을 생성하고 이를 데이터 저장시 키값으로 활용한다.
시퀀스는 DB상에 존재하는 객체로 단순히 다음 값을 생성해주는 역할을 한다.
이는 테이블에 행을 삽입할때 키 값이 생겨나는 MySql 계통의 Auto_Increment 컬럼과는 달리 테이블과는 별도의 값 생성기 객체를 두는 방식이기 때문에 insert 실행 없이 자동 생성되는 키값을 가져올 수 있다.
따라서 SEQUENCE 방식의 자동생성 키 매핑은 정상적으로 쿼리의 쓰기 지연이 지원된다.
@Entity
@SequenceGenerator(
name = "MY_SEQ_GENERATOR",
sequenceName = "BOARD_SEQM, // DB의 시퀀스 객체 이름을 적는다.
initialValue = 1, allocationSize = 50) // 50이 기본값.
public class 학생 {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MY_SEQ_GENERETOR") // 위에서 제작한 시퀀스 제네레이터의 이름을 적어준다.
private Long id;
사용법은 클래스 위에 @SequenceGenerator를 만드는 것으로 시작된다. 순서대로 만들어질 시퀀스 제네레이터의 이름, DB에 존재하는 시퀀스객체의 실제이름, 시작값, allocationSize는 키값이 몇씩 증가할 것인지를 지정한다.
이처럼 제작된 시퀀스 제네레이터를 실제 키로 사용될 필드 위에 키 매핑 전략과 함께 옵션으로 지정해주면 된다.
@GenerateValue(strategy = GenerationType.SEQUENCE , generator = "제네레이터 이름")
주의사항
시퀀스 전략의 또다른 주의 사항으로는 allocationSize 옵션의 기본값이 50이라는 사실을 아는 것이다.
allocationSize는 자동 증가 키 값의 증가량이라고 했는데 이것이 50이면 DB의 시퀀스 객체도 증가량이 50으로 동일해야 한다. 아래와 같은 쿼리로 DB에서 시퀀스 객체를 생성할 때 increment by 50으로 같은 양을 설정해야한다.
start with [initialValue] increment by [allocationSize]그러면 왜 기본 증가량이 50일까? 성능을 향상시키기 위한 세팅이라고 볼 수 있다. 앞서 기본키 매핑하기 에서 아래와 같은 설정을 해주어야한다고 언급했다.
〈property name="hibernate.id.new_generator_mappings" value="true" />
해당 옵션에 의해 활성화되는 jpa의 sequence 매핑 성능 최적화 기능은 다음과 같다.
DB에서 시퀀스 값을 50만큼 확보해온다. 그 다음 코드상에서 기본 키가 필요할땐 100이 되기 전까지는 DB에서 시퀀스에게 값을 요청하지 않으며, 50만큼 확보한 범위 내에서 1씩 증가시켜 저장한다.
쉽게 말해 50씩 뭉텅이로 가져와서 id++; 연산을 한다는 의미이다.
IDENTITY와 SEQUENCE 외에도 TABLE이라는 별도의 시퀀스 전용 테이블을 생성해 사용하는 전략이 있으나 넘어가도록 하겠다. 사용 방법은 SEQUENCE와 거의 유사하다.
@GeneratedValue(strategy = GenerationType.AUTO)
이것은 GeneretedValue의 기본값으로 DB에 맞춰 변동시켜주겠다는 의미이다.
자연키와 인조키
앞서 설명한 모든 내용은 PK로 사용될 컬럼에 관한 매핑 방식이었다. 이 챕터에서는 키로 사용되는 값의 형태에 따른 분류인 자연키와 인조키를 살펴본다.
자연키 - 이메일, 주민등록번호, 전화번호
인조키 - 시퀀스, Auto_Increment, 키 테이블
두 유형의 키의 차이는 그 자체로 의미를 갖는가 하는 여부이다. 시퀀스같이 단순히 증가하는 값은 어떤 의미도 갖지 않기에 인조키라는 유형으로 분류된다.
반면 주민등록번호나 전화번호는 그 자체가 특정한 의미를 부여받고있으며, 이는 변경가능성을 내포한다. 예를들어 전화번호를 국가적 차원에서 형태를 변경시킨다던가. 개인이 전화번호를 변경할 가능성도 충분하다.
인조키를 사용하는 것을 권장한다.
어떤 비즈니스적인 의미도 갖지 않는 인조키야말로 앞으로도 변하지 않을 가능성이 높은 식별자이다. 따라서 jpa에서도 모든 엔티티에 대해 식별자로 인조키를 쓸 것을 권장하고 있다.
필드와 컬럼 매핑하기
엔티티 객체의 필드와 테이블의 컬럼은 @Column 애너테이션으로 매핑정보를 작성한다.
대부분의 자료형은 @Column 을 사용하지 않아도 테이블과 정상적으로 매핑된다.
@Column 없이 엔티티 클래스에 정의된 필드는 해당하는 이름과 동일한 컬럼을 테이블에서 찾아 매핑하게 된다. 앞서 살펴본 카멜케이스에서 언더바 표기법으로 변환해주는 기능을 함께 사용하면 유용하다.
자동 DDL 사용시 주의사항
int 기본형 타입을 매핑하면 DB에 not null 제약조건이 함께 적용된다. 이는 기본형 int 가 null 을 가질 수 없음을 고려한 것이다.
그런데 int 타입에 @Column 을 함께 명시하면 @Column(nullable = true)가 기본 설정이기 때문에 nullable한 컬럼이 DB에 만들어진다.
기본형 int 타입이더라도 @Column(name = "컬럼명" ) 컬럼명 매핑을 위해 @Column을 사용하게 되면 nullalbe = false 속성도 함께 주어야함을 의식하고 있어야 한다.
@Enumerated @Lob @Temporal
위의 어노테이션은 @Column과 함께 필드에 사용될 수 있으며, 각각 특별한 타입을 지정하기 위해 사용된다.
@Enumerated
자바의 enum 타입을 DB에 매핑하기 위한 어노테이션이다. 자바의 enum이 db에 저장되는 방식은 두가지가 제공된다.
@Enumerated(EnumType.ORDINAL)
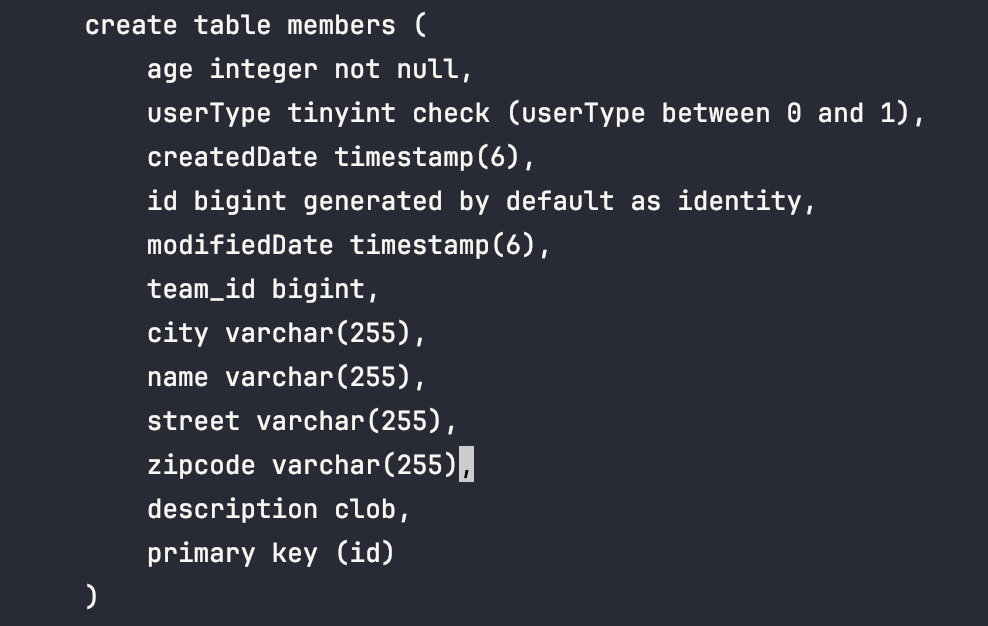
h2 데이터베이스를 대상으로 jpa가 만들어준 테이블 생성문을 보면 userType이라는 enum 타입이 tinyint 타입으로 저장된 것을 볼 수 있다.
ordinal로 설정된 enum은 enum타입의 객체가 정의된 순서에 맞춰 0, 1, 2 같은 정수값으로 DB에 저장된다.
@Enumerated(EnumType.STRING)
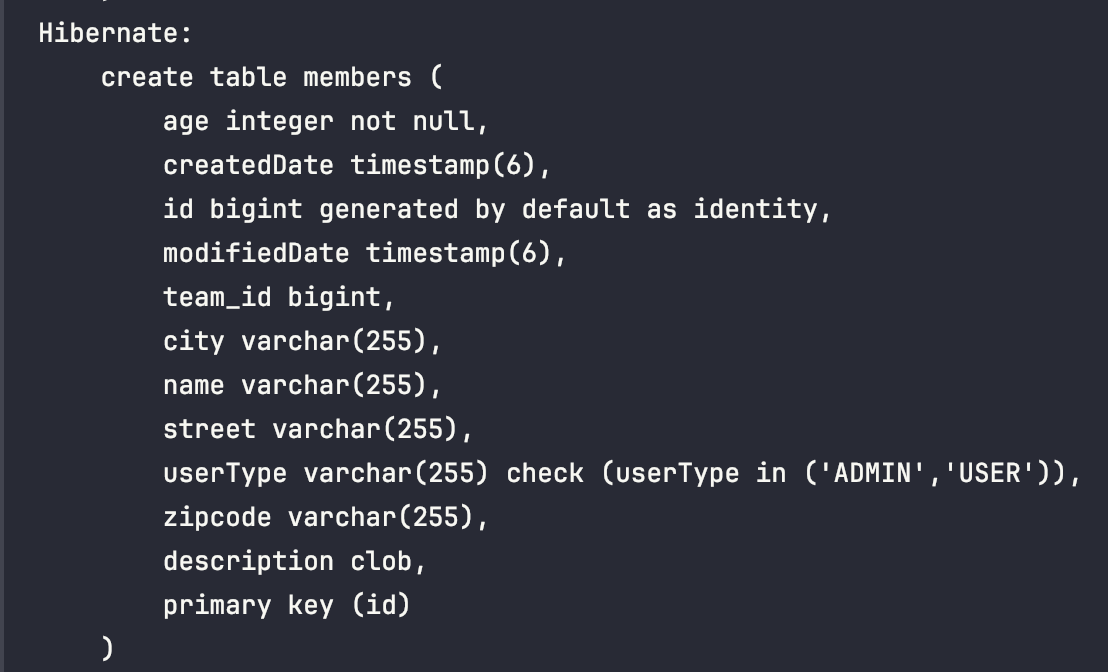
스트링으로 설정된 userType은 다음과같이 varchar로 매핑되는 것을 확인할 수 있다.
스트링으로 설정된 enum타입은 그 열거형 타입의 객체 이름이 그대로 DB에 저장된다.
주의사항
만약 auto DDL에 의해 자동으로 생성된 테이블이 아닌 기존에 생성되어있는 테이블이 enum을 담기 위해 VARCHAR 타입의 칼럼을 만들어 놓았다고 가정하자.
이때 저장될 객체가 @Enumerated(EnumType.ORDINAL) 을 enum필드의 매핑정보로 사용한다면 0, 1 같은 정수값이 varchar컬럼에 저장되는 것을 막을 수 없다.
위의 사진과 같이 별도로 check 제약조건을 컬럼에 설정해주어야 한다.
@Lob
String 타입의 필드는 DB의 VARCHAR 타입과 매핑된다. 그러나 길이제한이 없는 텍스트를 저장하기 위해서는 VARCHAR와는 다른 타입이 필요하다.
이를 위해 DB마다 다른 타입이 제공되며, jpa의 Entity는 단지 String 타입을 @Lob 어노테이션과 함께 정의하면 각각의 DB에 맞게 길이제한 없는 문자열로 매핑된다.
■ CLOB: String, char[],java.sql.CLOB
■ BLOB : byte[] ,java.sql.BLOB
간단하게 문자는 CLOB, 문자 외에 타입은 BLOB로 매핑된다.
@Temporal
LocalDateTime, Date 같은 시간 관련 객체를 DB에 맞게 매핑한다.
• TemporalType.DATE: 년 - 월 - 일
• TemporalType.TIME: 시 : 분 : 초
• TemporalType.TIMESTAMP: 년 - 월 - 일 시 : 분 : 초
@Temporal을 생략하면 DB에서 timestamp로 정의된다.(년월일시분초)
김영한 저자의 책 자바 ORM 표준 JPA 프로그래밍을 읽고, 학습 목적으로 정리한 글이며 기록목적으로 작성되어 언급하지 않고 생략된 내용이 많습니다.
