데이터를 조회하는 명령어
SELECT는 SQL에서 데이터 조회 시 사용하는 DML(Data Manipulation Language)명령어다. 해당 명령어는 질의, 나 쿼리라고 불리기도 합니다.
구조
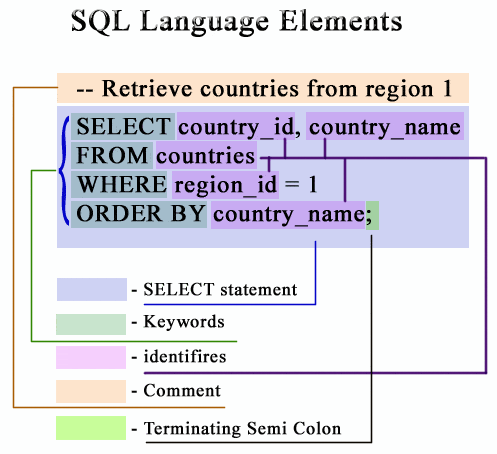
SELECT 구조는 특정 패턴구조를 가진다.
SELECT statement 다음 에는 표기할 column을 나열하고
FROM은 해당 데이터를 조회할 테이블의 명칭을
WHERE 는 데이터의 조건을 입력하며
ORDER BY에는 어떤 column을 중심으로 정렬을 진행할 것인지 명시한다.
이중 SELECT statement, FROM 은 생략이 불가능한 내용이며, 항상 명시해야한다.
또한 여기서 추가하지 않았지만 상당히 많은 패턴이 추가 될 수 있으며, DBMS에 따라 이에 추가할 수 있는 부분이 조금씩 다르다.
아래 하단의 링크는 ORACLE사에서 제공하는 SELECT SQL에 대한 레퍼런스이다.
https://docs.oracle.com/cd/B19306_01/server.102/b14200/statements_10002.htm
테이블은 규칙성 있는 데이터의 집합이다.
SELECT는 특정 테이블의 데이터를 조회하는 명령어입니다.
그렇다면 테이블은 무엇일까요? 앞 챕터에서 말씀드렸듯이 테이블은 2차원 데이터라고 말씀드렸습니다. 그리고 SELECT SQL에서 우리는 테이블의 몇가지 특징을 알 수 있습니다.
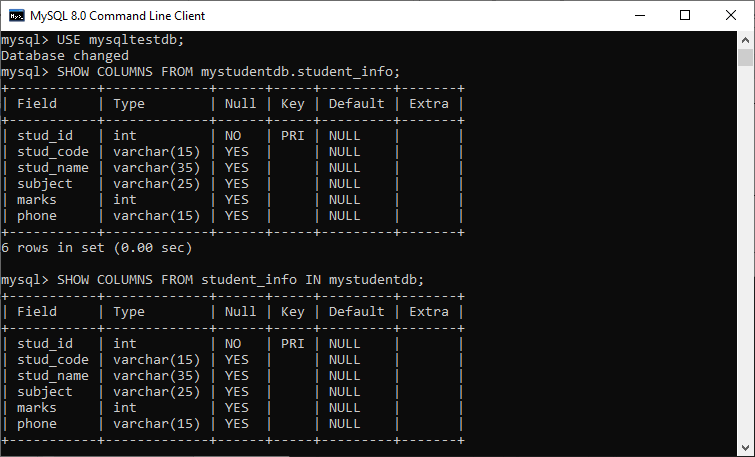
위의 사진은 테이블의 column 전체를 조회하는 명령어의 입력 결과입니다.
테이블은 Column이라는 것이 있으며, 이는 입력해야 할 데이터의 양식에 대한 규격과 이를 부르는 명칭을 의미합니다.
student_info table을 보면
a. stud_id, stud_code, stud_name, subject, marks, phone 이라는 컬럼을 가집니다.
b. 이 중 stud_id는 Type이 오직 int형만 입력이 가능하도록 설정되어 있습니다.
다른 column도 이와 같은 타입이 존재합니다.
c. Null에 대한 값으로 yes, no가 있습니다.
즉 NULL(데이터의 필수입력 여부) 가능 여부 등의 데이터 입력에 대한 조건을 걸 수 있습니다.해당 테이블은 stud 에 대한 정보를 저장하며, 학생의 아이디(id), 코드(code), 이름(name), 과목(subject), 마크(marks), 연락처(phone)의 정보를 묶어 데이터로 저장합니다. 그리고 아이디와 마크는 숫자만을, 학생의 이름, 과목, 마크는 문자열로 데이터를 저장하며, 아이디는 무조껀 데이터가 존재합니다.
이와 같이 테이블은 특정 규칙에 맞게 데이터 덩어리가 저장되어 있으며, 데이터의 특정 필드를 column으로 이러한 덩어리를 구분하고 있다는 것을 알 수 있습니다.
그렇기에 SELECT에서 Column을 선택하여 이러한 데이터들 중 일부만을 선택하여 가져올 수 있으며, 해당 데이터를 어디서 가져와야 하는지를 알기 위해 해당 Table의 명칭을 FROM에 적어주는 것이며, Column의 데이터 타입은 고정되어 있기 때문에 WHERE이나 ORDER BY 등에 조건을 넣어 이를 필터링 할 수 있다는 것을 알 수 있습니다.
