MySQL로 SQL 시작하기
1.MySQL 시작하기

이 시리즈는 42Seoul에서 SQL 공부 모임에 따라 시작한 시리즈입니다.최대한 공식문서나 Stack Overflow 같은 다수의 의견이 반영된 기록을 기반으로 제작할 예정이며, 해당 문서가 실제 내용과 다를 수 있음을 미리 알립니다.
2.DB 란 무엇인가?
개요 > A database is an organized collection of structured information, or data, typically stored electronically in a computer system. A database is us
3.Docker를 통한 MySQL 설치하기
2021년 09월 25일 기준맥북 M1에 맞는 MySQL을 설치하려면 아래와 같은 다른 명령어를 통해 이미지를 받아야 한다.GitHub Docker-Library issue아래와 같이 MySQL Image가 등록이 되어있다면 정상적으로 설치된 것이다.이후 해당 내용을
4.테이블의 구조
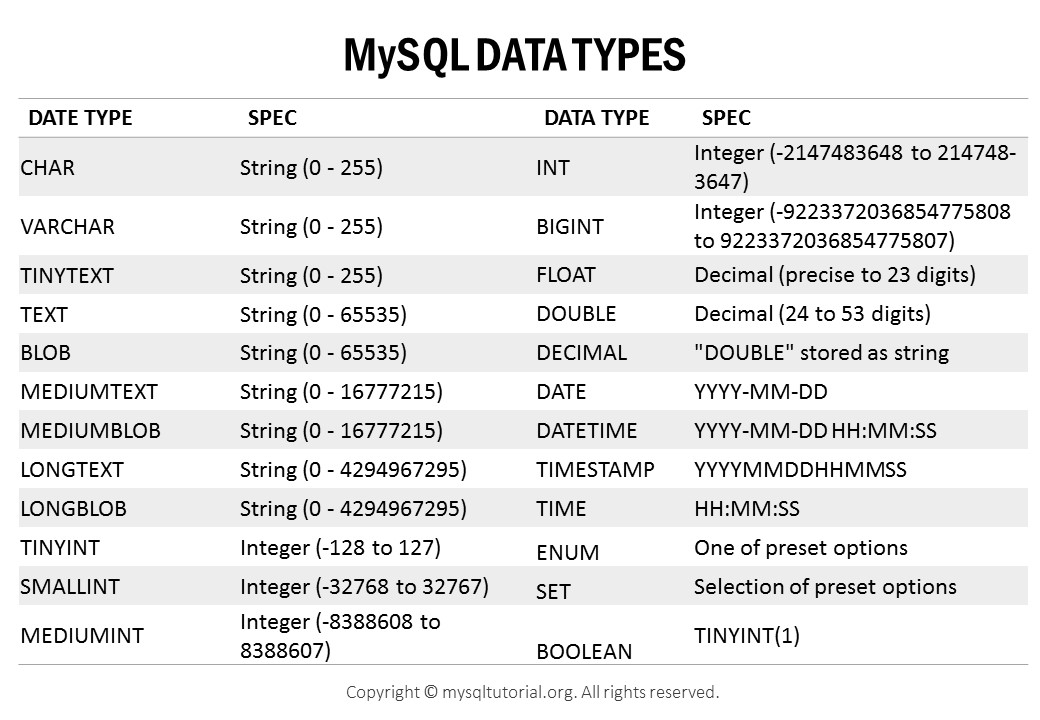
출처 : https://www.mysqltutorial.org/mysql-data-types.aspx앞의 글에서 설명했듯이 Column에는 자료형(데이터 타입)이 존재합니다.아래는 해당 타입에 대한 설명입니다.정수값을 저장할 수 있는 자료형입니다. 실수는 저장
5.검색조건의 지정
우리는 SELECT에서 몇가지를 선택하거나, 조건을 설정함으로서 원하는 데이터만을 조회할 수 있다.이는 전체 조회보다 매우 효율적이며, 유연하게 수정이 가능하다.SELECT는 COLUMN을 지정함으로, 테이블 전체가 아닌 특정 COLUMN 만을 조회할 수 있다.또는 추
6.패턴 매칭
앞서 사용한 연산자로도 문자열을 비교할 수는 있다.하지만 문자열을 보통 조회할 때에는 완전히 같은 값을 조회하는 경우도 있지만특정 문장이 있는지, 특정 패턴을 만족하는지를 찾아내는 경우가 더 많을 것이다.SQL은 LIKE 기능을 통해 이를 제공한다.LIKE는 특정 패턴
7.정렬
앞의 장을 통해서 이제 데이터를 선별하여 가져올 수 있게 되었다.하지만 실제 데이터는 입력된 순서, 또는 뒤죽박죽으로 데이터가 들어오게 된다.여기서 사용되는 것이 바로 ORDER BY 명령어이다.해당 방식처럼 ORDER BY에 정렬할 COLUMN명을 달고, 어떤 방식으
8.복수의 열을 정렬하기
우리는 정렬을 배우기 전까지는 ORDER BY를 사용하지 않았다.SQL에서 이를 지정하지 않는다고 해서 입력한 순서대로 데이터가 나오지 않기 때문이다.이때에는 SQL이 순서를 무시하고 서버 상황에 따라 데이터가 뒤죽박죽으로 들어오게 된다.그렇다면 만약 ORDER BY
9.결과 행을 제한하기

SELECT 명령에서 일부 데이터 반환을 제한할 수 있다. 이를 지원하는 기능이 바로 LIMIT 이다.위와 같이 SELECT 문장의 맨 뒤에 위치하게 되며 n에 최대출력할 행의 수를 입력한다.최대의 수를 입력한다는 뜻는 즉 아무리 많이 나와도 n개를 초과하게 나오지 않
10.수치연산
SQL를 사용하여 DB에서 내가 원하는 대로 필요한 데이터를 가져오는 작업을 진행했다.하지만 여기서 더 나아가서 좀 더 다양한 것들을 시도해 볼 수 없을까? 일반적으로 우리가 어떤 물건의 개수와 각 개수의 가격을 가져오면 이를 합산하여 총 가격이 얼마인지와, 해당 특정
11.문자열 연산
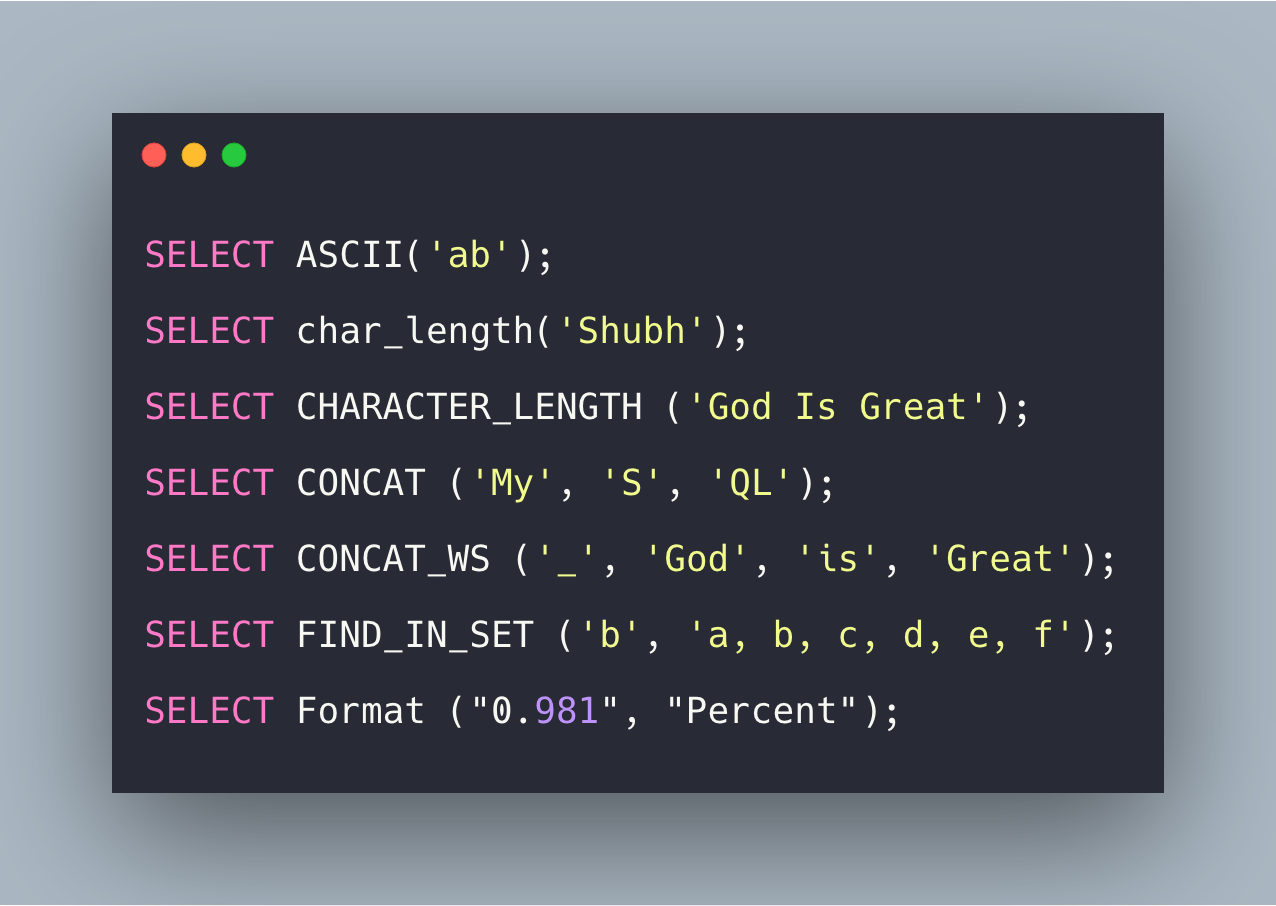
데이터 중에는 문자열 타입이 존재하는데, 이러한 데이터를 위한 연산자가 따로 존재한다.아래는 몇가지 예시를 서술한다.MySQL에서는 CONCAT이라는 함수로 문자열 결합을 지원한다.파라매터의 값은 최소 2개 이상이여야 하며, 그 이상 들어가도 상관없다. 물론 MySQL
12.날짜 연산
시간에 대한 데이터는 상당히 까다롭다.시분초 계산과 함께 년월일에 대한 제약이 존재하며, 특정 년도에 따라 년월일 계산이 달라지기 때문이다. 이러한 이유로 대부분의 프로그래밍 언어에서는, 이런 시간 계산을 위한 라이브러리를 제공하며 있다.MySQL에서도 이러한 연산을
13.CASE 문으로 데이터 변환하기

데이터는 여러가지 방면으로 사용됩니다.많은 어플리케이션, 서비스에서 데이터를 통해서 연산을 통해 사용자에게 전달합니다. 하지만 해당 데이터를 항상 같은 방식으로 이용할 것이라는 보장이 없습니다. 만약 남여의 데이터를 각각 다른 국가에서 사용한다면? 공통적으로 영문이나
14.INSERT
데이터를 테이블에 삽입할 때에는 INSERT 문을 활용한다.INSERT 문을 사용할 때에는 값을 VALUES에 table column 순서대로 차례도록 입력한다.단 column의 순서를 변경하거나, 특정 column들의 값을 집어넣고 싶다면 table명 뒤에 해당 co
15.DELETE

데이터를 삽입하는 경우가 있듯이 데이터의 삭제 또한 필요하게 된다.이 때에는 DELETE 명령어를 사용하여 데이터를 삭제한다.이전의 INSERT에 비해 입력해야 할 데이터가 상당히 적다. 어디의 table의, 어떤 조건의 데이터를 삭제할 건지만 입력하면 된다.WHERE
16.물리삭제 논리삭제
서비스에 맞추어서 테이블을 설계하다 보면 데이터의 삭제에 대해 나오게 된다.일반적으로 우리가 앞서 배운 내용으로 생각하면 DELETE 명령어를 통해서 삭제하면 되는 것이 아닌가 생각할 수도 있지만, 실제로 몇몇 상황을 생각해보면 데이터를 지우기 껄끄럽거나 애매한 상황이
17.COUNT
데이터를 사용하다 보면, 데이터의 상세내용 외 특정 데이터의 갯수를 구하거나, 중복된 내용을 지우고 싶은 경우가 생긴다. 이를 사용하는 것이 COUNT와 DISTINCT 이다.해당 행의 개수를 구하는 함수이다. 안에 들어있는 내용을 중복에 관계없이 NULL 이 아닌 행
18.집계함수
그렇다면 조금 더 욕심을 내서, 평균이나 합산등을 구하는 함수는 없을까? 당연히 존재한다.각각 집합에서 가장 큰, 작은 데이터를 도출해내는 함수입니다.단 해당 함수의 경우 NULL은 무시합니다. 날짜, 문자열에도 이를 사용할 수 있습니다. 특히 문자열에서는 알파벳 순서
19.그룹화

앞전 집계합수를 통해서 데이터의 갯수를 특정할 수 있었다. 그렇다면 이번에는 데이터의 그룹에 따라 개수를 구하는 것은 가능할까? 각 지역별 인구수나, 남학생-여학생의 학생 수 등을 구할 때 처럼 말이다. GROUP BY는 이러한 상황에서 도움이 된다.해당 처럼 GROU
20.서브쿼리
서브쿼리는 명령문 안에 지정하는 하부 SELECT 명령어이다. 주로 WHERE에 사용되며, 좀 더 유연하게 쿼리문을 사용할 수 있도록 도와준다.SELECT 는 여러 구간에서 서브쿼리가 가능하다. INSERT는 VALUES에 서브쿼리가 가능한데, 계산된 값을 넣거나, 테
21.상관 서브쿼리
서브쿼리를 통해 쿼리문을 좀 더 다채롭게 쓸 수 있다는 것을 알았다.하지만 여기서 하나 더 추가해서 서브쿼리는 쿼리문에서 사용하는 table값을 가져와서 where문에 넣을 수 있다. 즉 이렇게 쿼리간의 연관성이 있는 서브쿼리를 상관 서브쿼리라고 부른다.해당 컬럼의 값
22.DB 객체
우리는 DB의 Table에 insert, delete등의 조작행동과 view를 통해 미리 데이터를 조회해두거나 index를 통해서 더 빠른 데이터조회를 할 수 있게 합니다. 이러한 것처럼 실제로 DB내에 실체를 가지는 것들을 객체라고 부릅니다.DB 객체는 이름을 가집니
23.테이블 조작
이전에 배웠던 데이터 조작언어와 달리, 테이블을 조작하는 언어를 DDL 이라고 한다.DDL로는 CREATE, DROP, ALTER가 존재하며, 이를 이용하여 테이블을 생성, 삭제, 수정한다.TABLE을 조작하려면 스키마 안에서 조작해야 하며, 처음에는 해당 스키마를 사
24.제약

지금까지 배운 테이블은 컬럼명과 자료형에 맞게끔 데이터를 조작하는 것이였고, 해당 방법에서 크게 벗어나지 않는다면, 큰 문제없이 진행되는 그런 것들이였다. 하지만 실제로 테이블에는 좀 더 많은 조건들이 존재한다.UNIQUE는 말 그대로 유일하다는 뜻이다. 해당 조건이