작년에 공모전을 하면서, 학습 도중 메모리가 부족한 현상이 잦았다.
분명 데이터 셋이 많은 것도 아닌데, 메모리가 계속 부족했고 로컬에서 작업하다 코랩에서, 코랩에서 작업하다 코랩 프로까지 갔는데도 메모리가 꽉 차게 되었다.
그만한 리소스를 먹을 정도가 아닌데 나는 내가 메모리를 매우 비효율적으로 사용한다고 체감했다. 그당시에는 너무 시간이 없었고, 대폭 효율화 할만한 방법도 떠오르지 않았다. 흑.
오늘 캐글 사이트에서 이리저리 둘러보다 대부분의 코드에서 메모리를 줄이는 선 작업을 하였다. 살펴보니 엄청 간단했다. 데이터 타입을 줄이는 것 이다.
아. 그러네 대학생때 데이터 타입별 몇 비트이고, 뭐가 다른지 배웠는데 하나도 써먹지 못하다니.
이 사이트를 참고했다.
1. 방법
- 모든 열을 반복
- 열이 숫자인지 확인
- 열이 정수로 표현될 수 있는지 확인
- 최소값과 최대값 찾기
- 값의 범위에 맞는 가장 작은 데이터 유형을 결정하고 적용
2. 코드 본문
# Reduce Memory Usage
# reference : https://www.kaggle.com/code/arjanso/reducing-dataframe-memory-size-by-65 @ARJANGROEN
def reduce_memory_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype.name
if ((col_type != 'datetime64[ns]') & (col_type != 'category')):
if (col_type != 'object'):
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
pass
else:
df[col] = df[col].astype('category')
mem_usg = df.memory_usage().sum() / 1024**2
print("Memory usage became: ",mem_usg," MB")
return df- if 문을 확인해보면 데이터의 최대값, 최소값을 출력해 데이터의 범위를 확인하고, 범위가 특정 데이터 타입으로 제한이 가능하면 변경하는 코드이다.
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:3. 실제로 써보니..
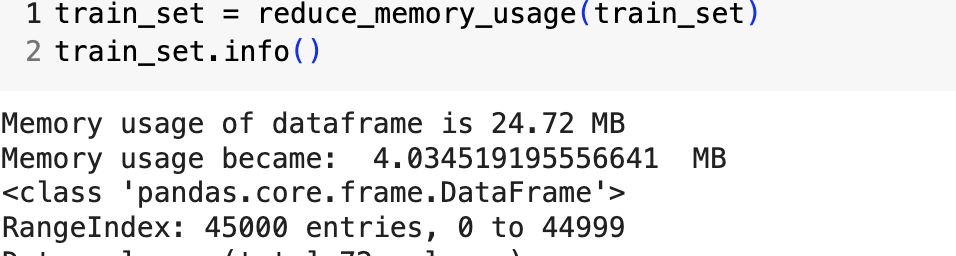
메모리가 1/6으로 줄었다... 게다가 성능차이도 없다. 앞으로 잘 활용해야겠다.
