Splunk를 사용할 때 가속화, 데이터 모델 등 데이터 모델과 관련된 키워드는 여러 번 듣게 되지만 정확히 정리하지 않으면 무슨 개념인지 헷갈리기 쉽다.
따라서 이번에는 DataModel, 가속화에 대해 개념을 정리해두려고 한다.
1. DataModel이 뭐야?
데이터 모델을 생성하면, 흔히 뭔가 새로운 인덱스가 생기거나 새로운 객체가 생성된다고 착각을 한다. 실제로 나도 처음엔 그랬다. 하지만 데이터 모델은 단순히 논리적으로 데이터간의 계층관계를 정의한 것 이다.
예를들어 내가 Email이라는 데이터 모델을 생성했다고 하자. (데이터 모델은 Splunk의 CIM에서 제공하는 데이터 모델을 예시로 활용했다.)
Email의 데이터 모델을 살펴보면 아래의 구조로 되어있다.
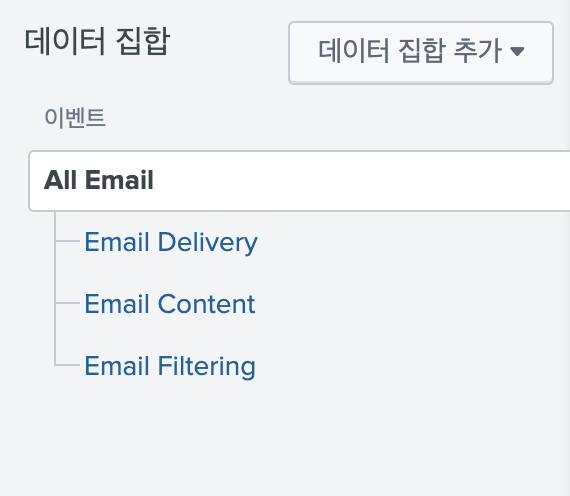
그러면 위의 그림은 이렇게 해석할 수 있다.
All Email에 해당하는 데이터는 Email 전체를 나타내는 데이터구나.
그리고 이메일 데이터는 크게 하위 3가지 데이터로 나뉘어지는데 Delivery(메일 송, 수신), Content(메일 본문, 파일 등의 내용), Filtering(필터링되어 차단되거나 스팸함으로 들어간 메일) 이 있구나.
이런 식으로 데이터 모델은 이러한 데이터 간의 계층적인 관계를 정의하는 것 이다. 데이터 모델을 정의해서 새로운 인덱스가 생기거나, 데이터를 재생성하는 것이 아니다.
참고로 각각의 All Email, Delivery, Content, Filtering을 구성하는 데이터를 정의 하는 방법을 Splunk에서는 제약 조건이라고 한다.
1) DataModel은 왜 쓸까?
전통적인 RDBMS와 다르게 설계된 Splunk의 특성상 데이터 상의 관계를 확인할 수가 없다. Splunk와 같은 빅데이터 플랫폼 시스템은 데이터를 수집하는 데에 초점이 맞춰져있다. 따라서 데이터 간의 관계를 표현하는 데에는 기존의 RDBMS보다는 부족하다.
조금 더 해석하자면 우리가 쓰는 Splunk는 아래의 그림처럼 데이터의 스키마, 유형과 관계가 엄격하게 정해진 데이터를 수집하는게 아니다.
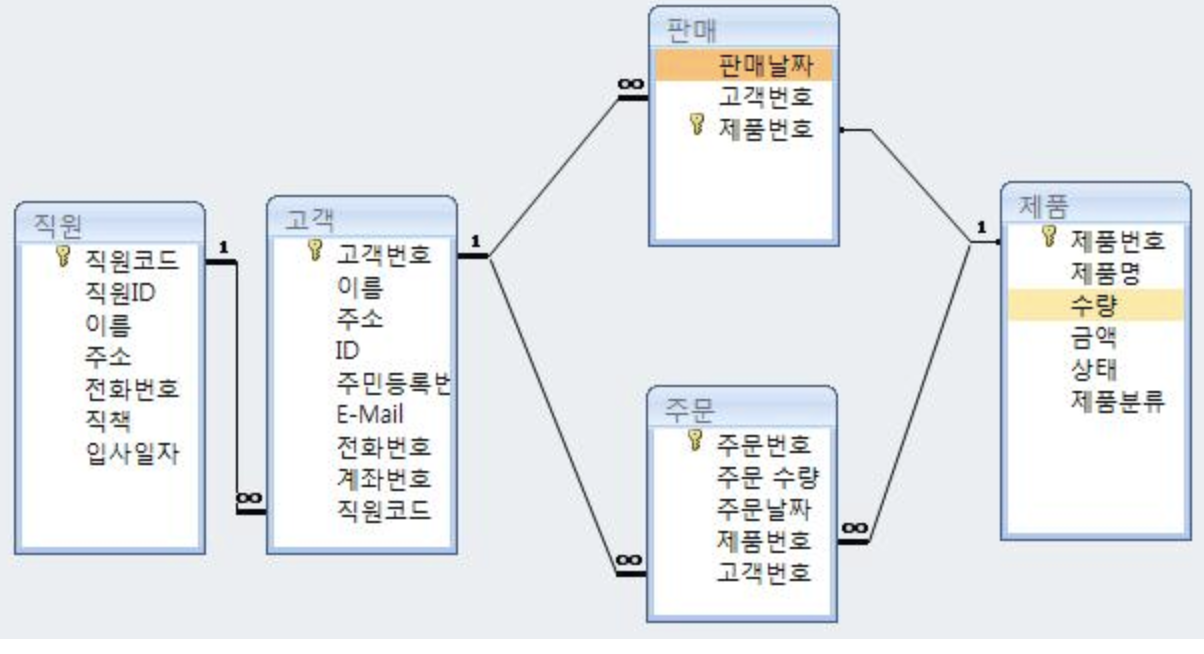
그림 출처: http://www.fun-coding.org/mysql_basic1.html
다양한 이기종의 데이터를 빠르게, 실시간으로 수집하는 데에 초점이 맞춰져 있다.
하지만 우리가 다양하고, 많은 데이터를 수집하는 만큼 데이터가 어떤 형태인지, 어떠한 구조를 가지고 있는지 모를 수 밖에 없다.
따라서 이러한 데이터의 구조를 파악하기 위해 도입된 개념이 데이터 모델이다.
데이터 모델의 구조를 살펴보면, Email 데이터는 어떤 데이터인지?(루트 이벤트, 루트 검색, 루트 트랜잭션), 그 데이터는 하위에 어떤 종류, 타입의 데이터가 존재하는지?(하위)를 파악할 수 있다.
2. DataSet
위에서 언급했다 시피 데이터 모델은 논리적인 계층 관계를 정의한 것 이다. 따라서, 데이터 모델의 이름은 그 계층관계가 정의된 객체의 이름이라고 보면 되고, 그 데이터 모델 내부에 각각 논리적 관계를 나타내는 데이터 집합 이 계층적으로 연결되어있다.

이게 데이터 모델이고, 이 데이터 모델 내부에는
이렇게 계층 관계로 나타내어진 데이터 셋이 존재하는 것 이다. 이러한 데이터 셋은 총 4가지 종류가 존재한다.
1) 루트 이벤트 데이터
루트 이벤트 데이터는 가장 기본적으로 사용되는 데이터 셋이다. 데이터의 유형을 가장 광범위하게 나타내는 경우에 사용된다. 예를들어 이메일이라고 한다면, 간단하게 index=email 로써 이메일 데이터만을 추출해 이것은 이메일 데이터임을 나타내는 용도로 사용된다.
아래는 Splunk의 CIM에서 제공되는 Email 데이터 모델의 루트 이벤트 데이터의 제약조건이다. 가장 간단하게 정의된 형태로 볼 수 있다.

2) 루트 검색 데이터
루트 검색 데이터는 데이터를 광범위하게 표현할 때에 복잡한 필터링을 사용하거나, 집계 명령어(ex:stats 등)을 사용할 때에 사용한다.
아래는 Splunk의 CIM에서 제공되는 Endpoint 데이터 모델의 Port 루트 검색 데이터 제약조건이다. 이벤트 데이터에 비해 데이터 추가, 변형 등의 검색이 추가된 것을 볼 수 있다.

3) 루트 트랜잭션 데이터
루트 트랜잭션 데이터는 데이터를 그룹화 하여 표현할 때에 사용한다. 특정 이벤트가 발생한 데이터를 그룹화 하여 저장하고 싶을 때 사용할 수 있다.
예를들어 침해사고가 발생한 데이터의 IP가 고정되어있고, 해당 IP가 약 30초 동안 1초 이상 멈춤 없이 통신을 하였다고 가정하면 루트 트랜잭션 데이터로 다음과 같이 표현할 수 있다.
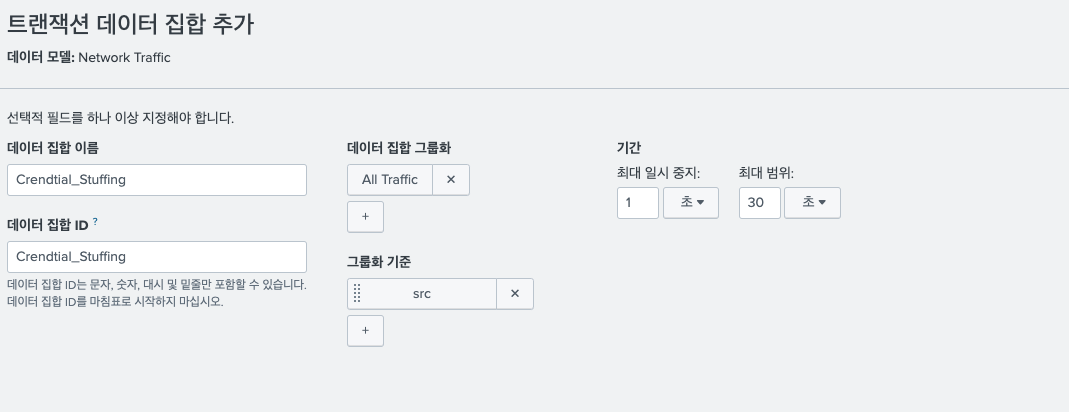
- 참고로, 루트 트랜잭션 데이터 정의 시 검색하는 데이터 집합이 이미 루트 이벤트 데이터나 루트 검색 데이터에서 정의된 데이터를 활용한다.
- 따라서 위에서는 네트워크 트래픽 데이터 모델에서 이미 정의된 All Traffic 데이터 셋 중 src로 데이터를 그룹화 하였다.
- 그룹화 중, 최대 일시 중지 시간과 범위 시간은 선택 옵션이다.
4) 하위 데이터
하위 데이터는 1)~3)데이터에서 추가적으로 필터링을 하여 하위 관계를 나타내고 싶을 때 사용한다. 아래 그림에서 보이는 경우가 모두 하위 데이터를 나타낸다.
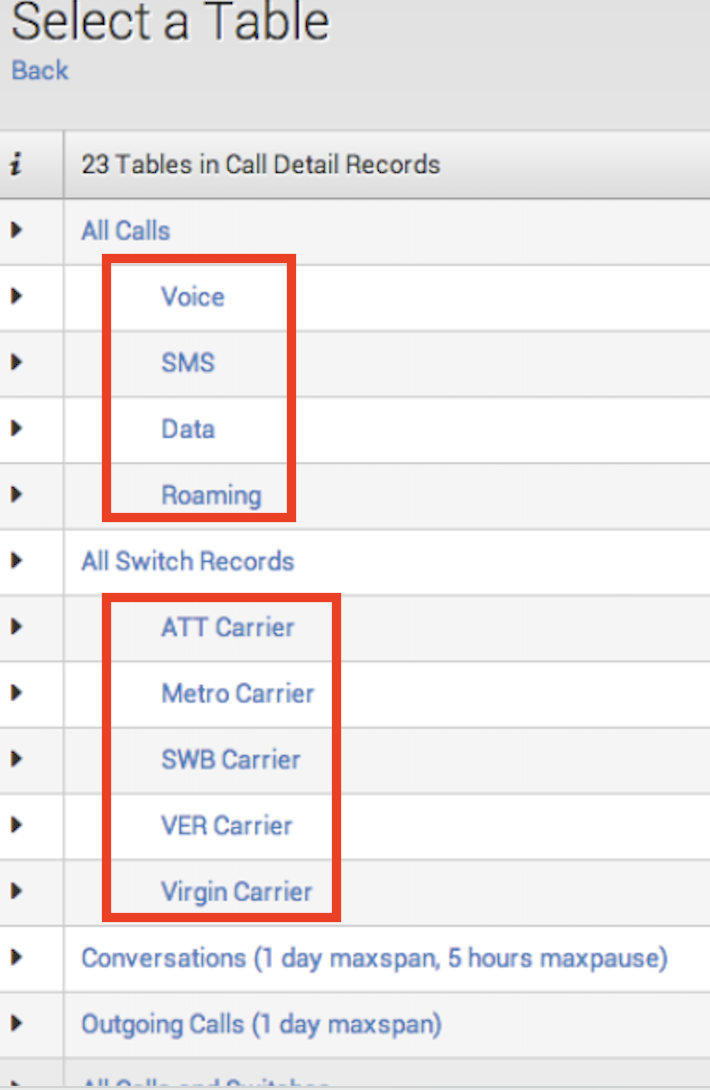
하위 데이터를 정의하게 되면, 기본적으로 상위데이터에서 정의한 데이터는 모두 상속된다. 따라서 제약 조건을 살펴보면 아래와 같이 상속됨이라고 표기가 되어있다.

- 그림출처: Splunk 공식 Docs
All Traffic의 데이터 제약조건은 상속되어있고, 그 데이터들 중 action의 값이 *인 데이터를 하위 데이터로 정의하였다. 따라서 제약조건이 action=* 으로 나와있는 것을 볼 수 있다.
그 외에 데이터 필드 추출은 데이터 셋에 맞는 데이터 필드를 추출했다고 보면된다. 기존에 우리가 데이터 필드를 추출하는 과정과 같다고 보면 된다.
3. Data Model Acceleration이 뭐야?
데이터 모델 가속화가 평소에 우리가 혼동하던 개념이 아닐까 싶다.
데이터 모델을 빠르게 조회되는 데이터가 생성되는 것 이다. 데이터 모델과 데이터 모델 가속화는 다르다.
가속화는 무엇일까?
데이터 모델을 가속화하면, 루트 이벤트 데이터에 대한 tsidx파일 생성이 이루워진다. 이는 인덱스에서 데이터를 가져오는 원시적인 이벤트 검색이 일어나지 않고 인덱스 파일에서 데이터를 바로 사용하기 때문에 데이터 검색이 가속화 된다.
tsidx가 무엇이고, 파일로 인해 데이터가 검색되는 과정은 무엇인지에 대해 이전에 tstats 포스팅에도 기재했으나 이 포스팅에도 중복해서 기재하겠다.
1) tsidx란?
tsidx는 timeseriesindex 이다. tsidx는 데이터의 각 고유 키워드를 원시 데이터에 저장되는 이벤트의 위치값과 함께 연결한다. 이 말을 이해하려면 아래의 그림을 보면서 Splunk 검색이 어떻게 되는지 먼저 알아야 한다.
검색이 이뤄지는 과정
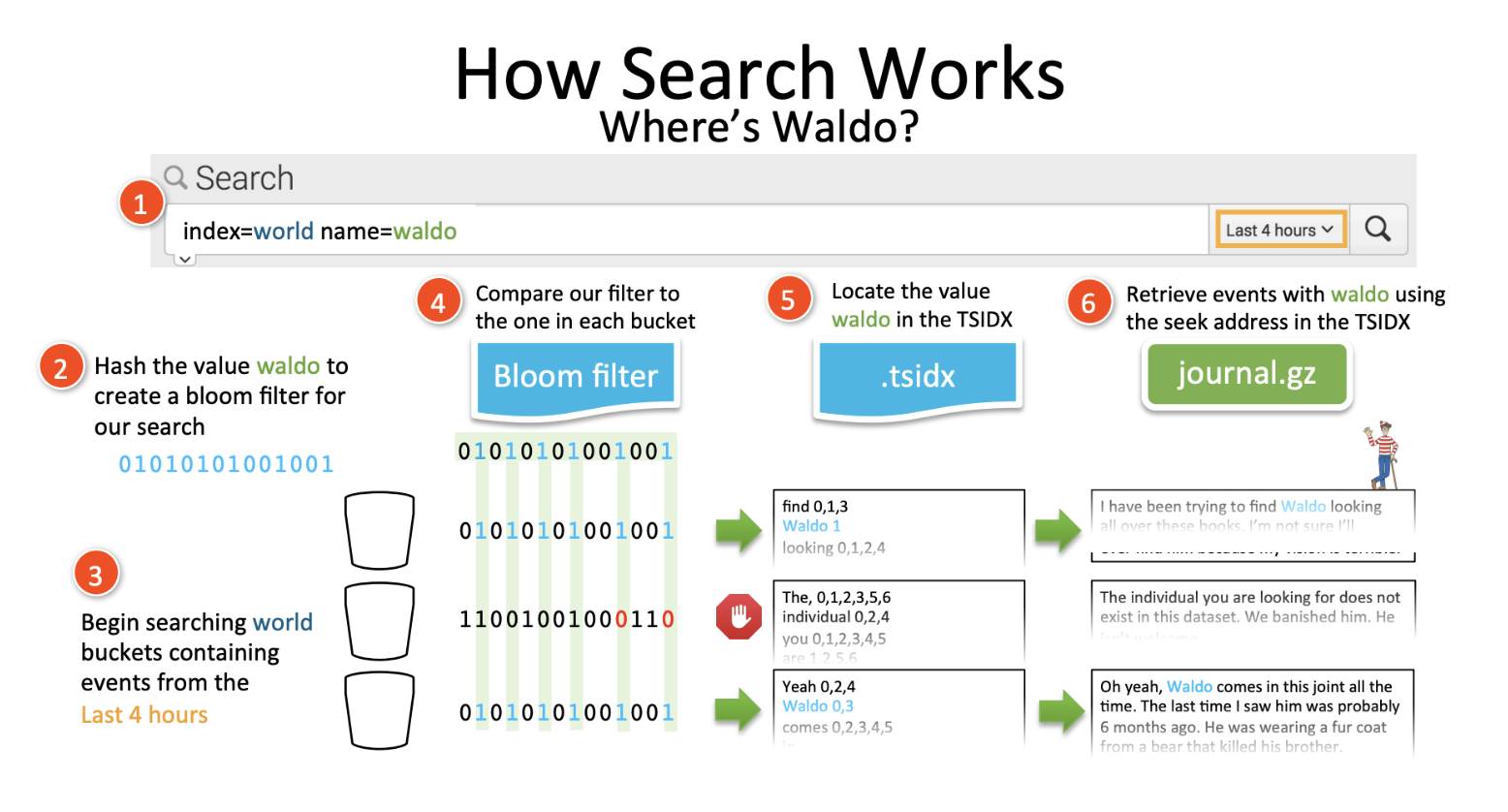
- index=world name=waldo 라는 검색을 실행한다.
waldo라는 단어를 해시값으로 변경한다. 이후 블루밍 필터를 생성한다. (= waldo라는 단어가 존재하는지 확인하는 필터를 만든다.) - Bloom Filter: Bloom Filter는 빅데이터 플랫폼에 주로 사용되는 방법으로 특정 대상을 검색할때 전체 집합 속 데이터의 존재 여부를 알려준다. 없는 것을 빨리 찾아주기 때문에 불필요한 검색을 줄여준다.
- world 인덱스를 찾아서 검색할 버킷을 찾는다.
앞서 만들었던 waldo Bloom Filter를 각 버킷의 Bloom Filter와 대조한다. - 필터를 통해 waldo라는 단어가 포함된 버킷만 추출하게 된다. (그림에서는 4->5의 과정이다.)
- 버킷은 tsidx와 journal.gz로 이뤄져 있는데, tsidx에는 waldo라는 키워드가 저장되는 이벤트의 위치값과 함께 연결되어있다.
- tsidx에서 waldo라는 키워드와 매칭된 원시 데이터의 위치 값을 찾아 journal.gz에서 데이터를 가져온다.
가 검색이 이뤄지는 과정이다. 위의 과정을 확인해보면 tsidx는 각 키워드와 그 키워드의 원시데이터가 저장된 위치값이 저장된 인덱스 파일이라는 말이 자연스럽게 납득된다.
위의 설명에서 보이는 tsidx가 데이터 모델을 가속화 하게되면, 생성되는 인덱스 파일이다. 가속화를 하게 되면 일반 인덱스 데이터와 달리 journal.gz를 거치지 않고 바로 인덱스 파일에서 데이터를 가져올 수 있는 형태를 구축하여 검색을 가속화 시켜준다. 그래서 검색이 빨라진다.
2) 루트 이벤트 데이터만 가속이 가능
데이터 모델을 가속화 하면, 데이터 모델에 정의된 데이터 세트 중 루트 이벤트 데이터만 가속이 가능하다.
3) 데이터 모델 가속화 하기
데이터 모델 가속화는 데이터 모델의 편집에서 가속화 편집을 누른 후 데이터 가속화를 체크해주면 된다.
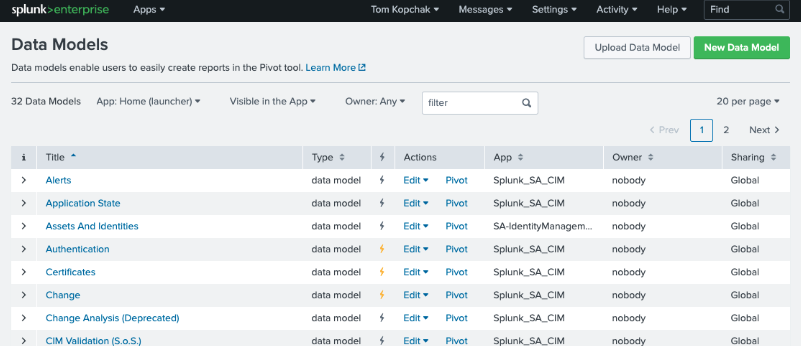
그러면 아래와 같이 노란 번개 불이 들어온 것을 볼 수 있다. 이렇게 되면, Splunk가 데이터 모델에 정의 된 루트 이벤트 데이터의 tsidx를 생성한다.
완료된 것은 Status를 통해 확인할 수 있다. 100%라고 나오면 내가 정의한 루트 이벤트 데이터 세트에 대한 tsidx가 모두 생성된 것 이다.

이것으로 오늘은 데이터 모델과 데이터 모델 가속화에 대한 개념을 알아보았다.
다음 포스팅에는 데이터 모델 생성은 어떻게 하는지, 데이터 모델가속화 설정은 어떻게 해야하는지, Summary Index와의 차이점에 대해 기재하겠다.
끝이다.
