splunk
1.Splunk eventstats streamstats

eventstats, streamstats에 관해 설명한다.stats를 이용해 그룹화 하여 나온 결과를 다시 컬럼으로 사용할 수 있는 기능이다.말 그대로 stats를 이벤트 성으로 사용하겠다는 의미이다.다음과 같은 데이터 셋이 있다고 하자.이때, 다음과 같은 쿼리를 사
2.Splunk Summary Index에 관하여, savedsearch 등
splunk summary index에 관하여 포스팅을 한다. 참조한 페이지는 여기 , 그리고 여기 이다. 1. Summary Index란? 보통 여러 데이터들을 전처리하거나, 조건을 적용 혹은 규칙을 설정하여 통계 혹은 집계를 낼 때에 우리는 Saved Search
3.Splunk 의 커맨드 유형, Commands Type
오늘은 splunk의 commands 유형에 대해 알아볼 것이다.마찬가지로 참고한 사이트는 2가지 이다. 유튜브 채널공식 홈페이지별거 아닌 것 같은 개념이지만, splunk에서 다양한 명령어를 사용하고 처리할 때 이 개념을 모르면 제대로 적용하기 어려워진다. 어떤 명령
4.Splunk Reporting Command records를 못받아올때, Splunk Reporting command
custom search command 를 개발하다가 Reporting command 를 개발하는데, records를 못받아오는 문제점이 생겼다. 내가 사용했던 SPL의 구조는 다음과 같다. 여기서, 원시 데이터를 검색하고 바로 customsearch command를
5.Splunk multikv, Splunk 테이블 형식의 데이터 필드 추출하기, top/ps 필드 추출
Splunk의 필드 추출은 웹에서 진행할 수도 있다. 하지만, 보통 splunk 에서 필드를 추출하는 단위는 하나의 이벤트이다. 웹로그 상의 이벤트가 됐던, 어떤 네트워크 트래픽이 됐던 하나의 사건 단위여야 한다. 그런데, 터미널에서 우리가 실시간으로 top 명령어를
6.Splunk NOT과 !=의 차이점
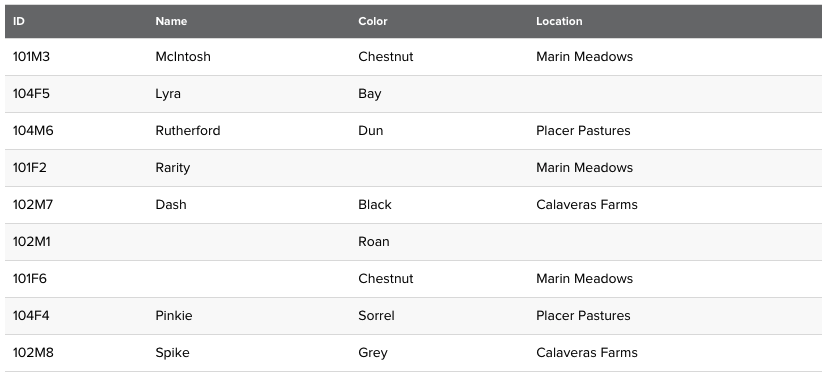
쿼리를 작성하는데, != 조건으로 작성한 쿼리가 뭔가 잘못 작동하고 있었다.이러한 쿼리였는데, 이 조건에 의하면 옷은 후드가 아니면서 동시에 신발이 플랫슈즈가 아닌 조건을 만족하는 데이터를 추출하는 것 이었다. 그런데 생각해보니.. AND 로 이어진 그룹 조건이다 보니
7.Splunk timechart에 관하여
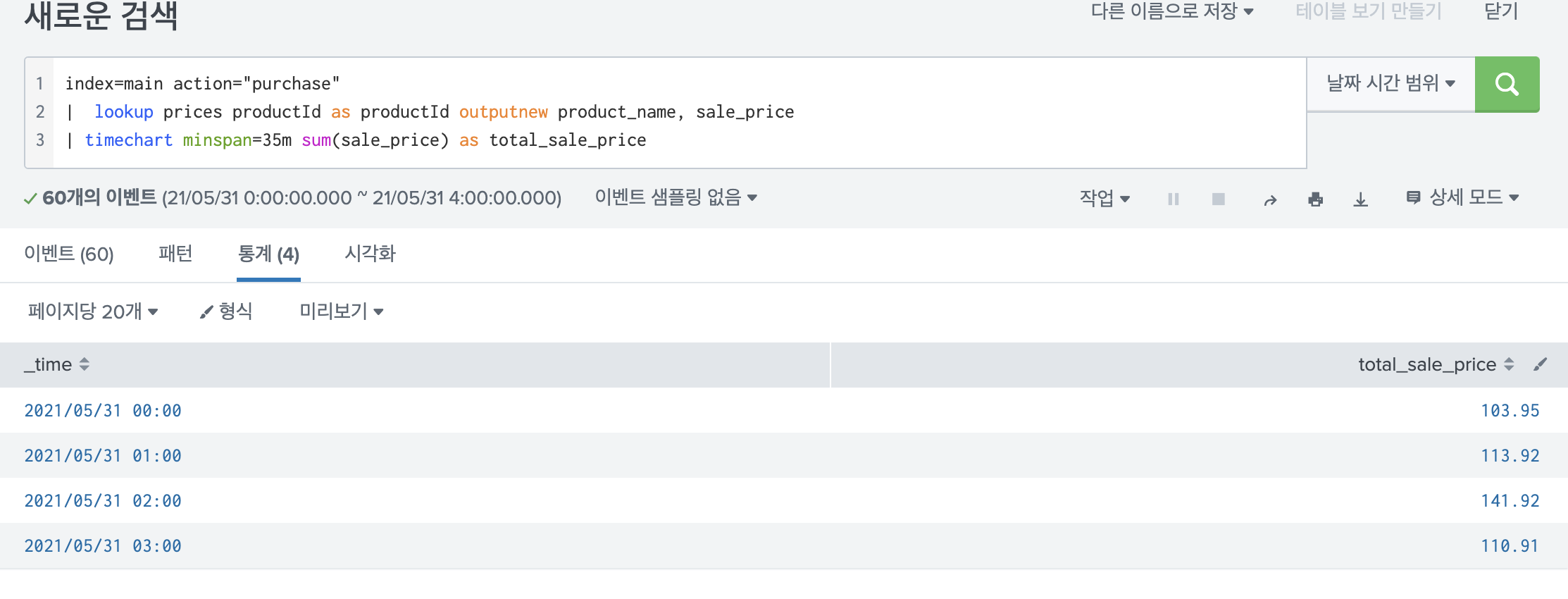
오늘은 splunk에서 가장 많이 쓰는 시각화 명령어중의 하나인 timechart에 대해서 설명하겠다. 실제로 여러번 쓰지만, 이리 저리 조건을 넣다보면 뭔가 원하는대로 안될 때가 많아서 정리해 둘 필요가 있다고 느꼈다. 이번 포스팅은 공식 문서와, 유튜브 영상을 참고
8.Splunk iconify, highlight, rangemap 명령어
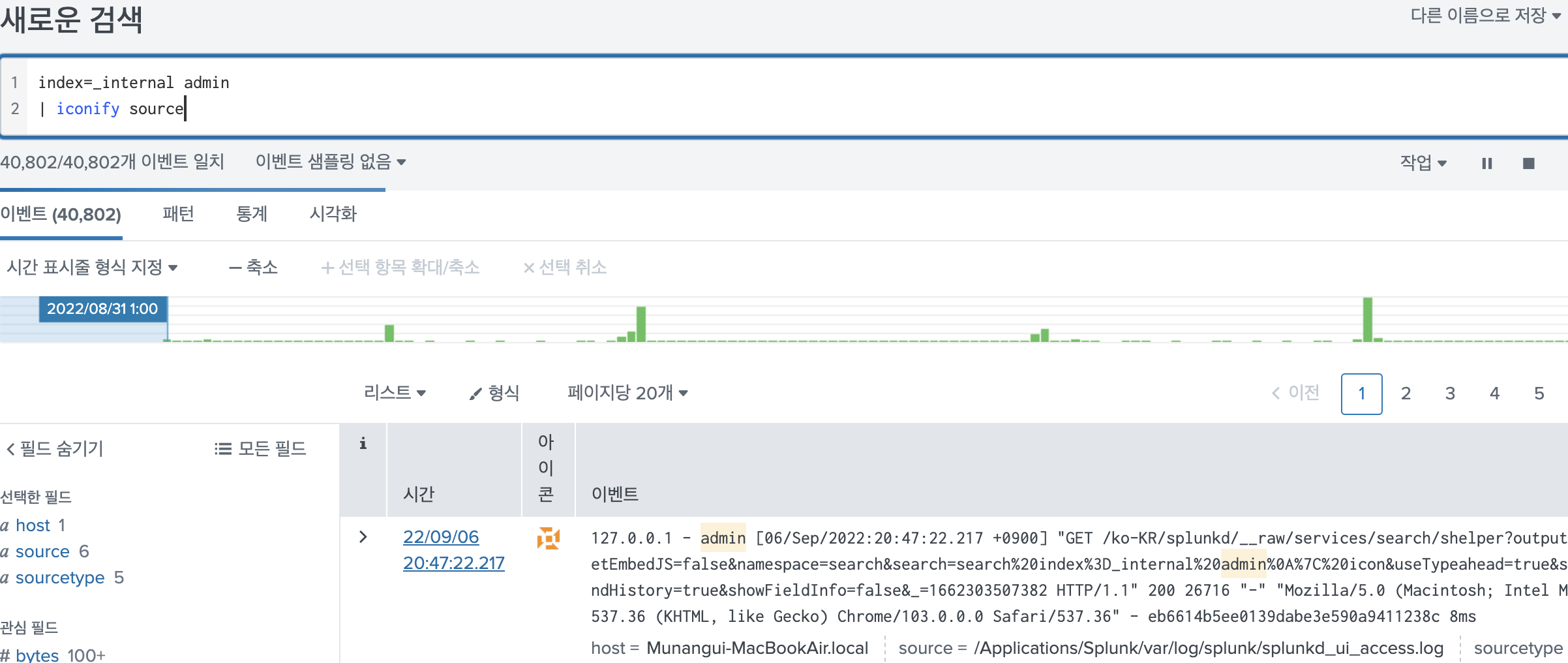
3가지 다 distributable streaming 명령어이다. distributable streaming 일 경우에는 streaming 한 명령어로써 작용하는데, SH에서 작동할 수도 있고 IDX에서 작동할 수도 있다.말 그대로 이벤트 하나하나에 Icon을 넣어주는
9.Splunk fillnull, filldown 명령어, Splunk 채우기 명령어, 여러 필드의 NULL을 다른 값으로 채우기, 조건부 필드 채우기 등
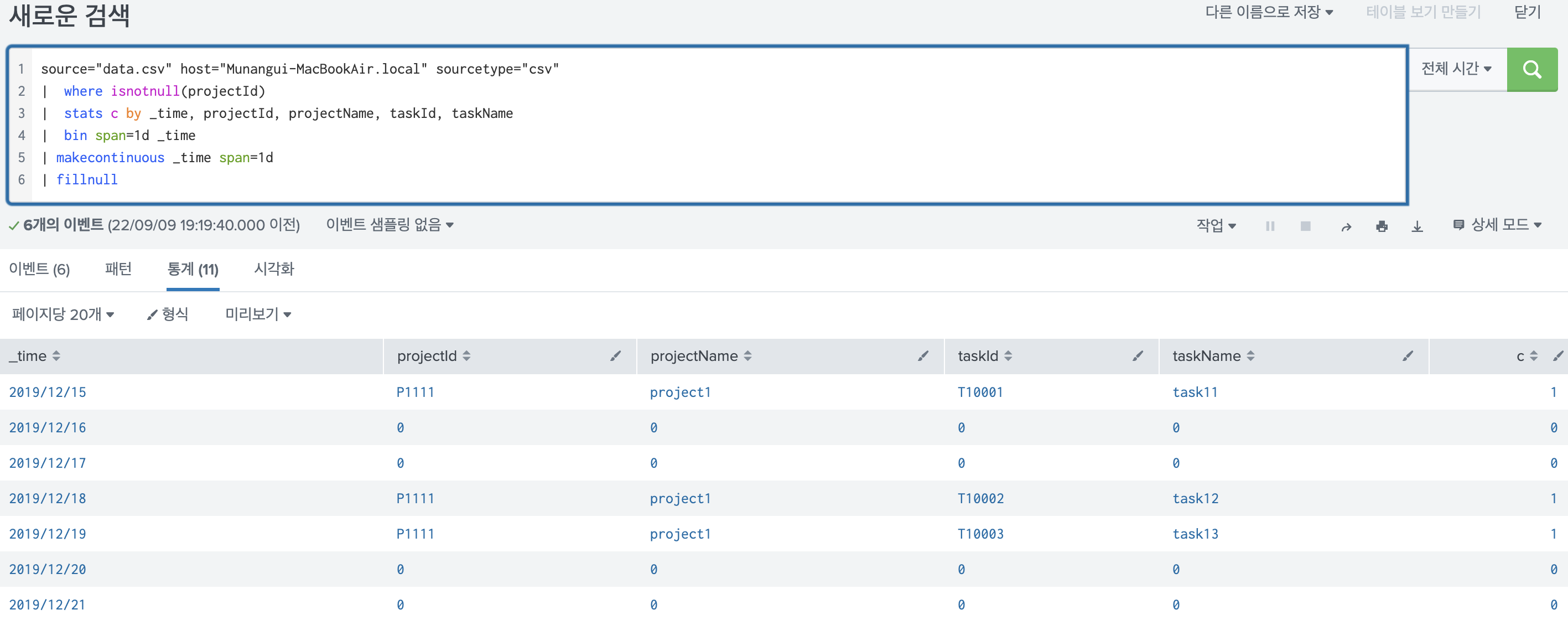
오늘은 fillnull, filldown에 대해 알아보려고 한다. fillnull은 자주쓴다. 왜냐면 stats와 같은 변환 명령을 사용할 때 split-value값에 null값이 포함된 경우에는 자동으로 집계에서 빠지게 된다. 이런 데이터도 추가해주기 위해서 fill
10.Splunk addtotals vs addcoltotals
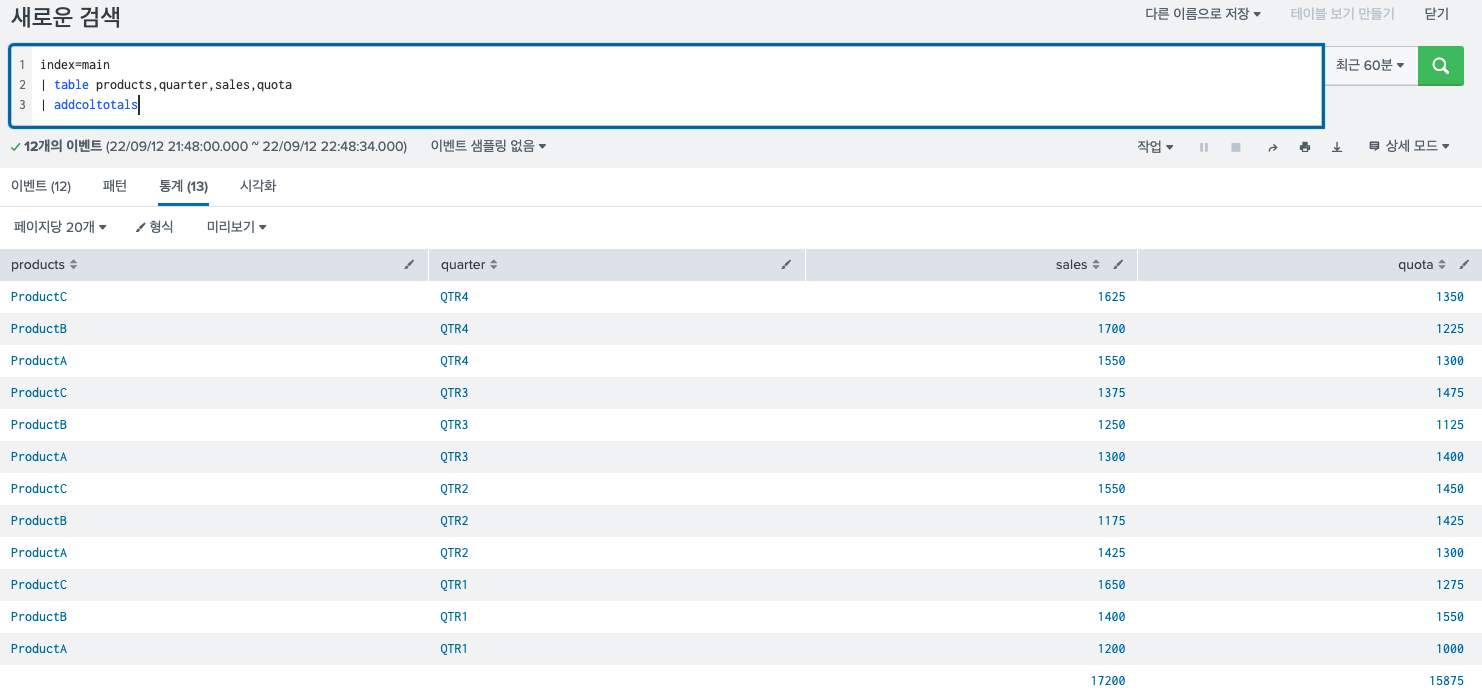
splunk에서 자주쓰이는 명령어 중 하나인 addtotals와 addcoltotals의 차이점에 대해서 설명하겠다.매우 쉽다.동영상을 보고 정리했다.컬럼 별 합계의 결과를 나타내어 주는명령어이다.이러한 명령어를 실행하게 되면 결과는 다음과 같다. 맨 마지막 row에
11.Splunk transpose, xyseries/ Splunk 열(column)을 행(row)으로 바꾸기/ Splunk 표 만들기
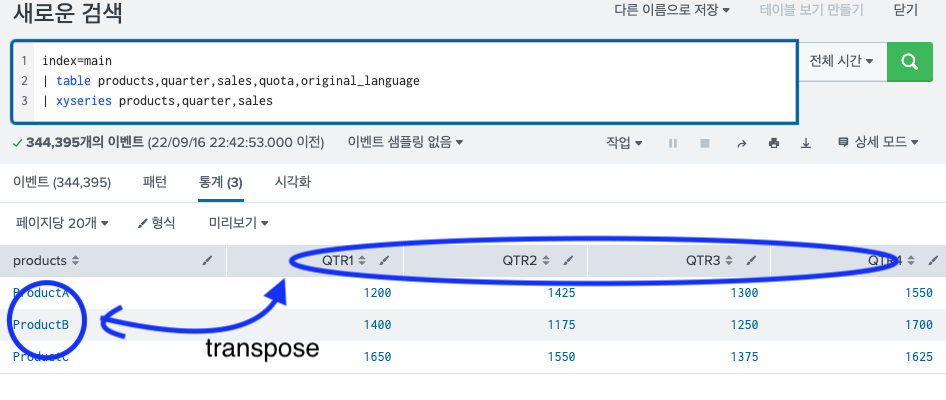
splunk 에서 자주 쓰이는 transpose와 xyseries명령어에 관하여 포스팅을 한다. 엄청 자주 쓰이는건 아니지만, 가끔 필요할 때가 있고 또 필요할때 보면 은근 헛갈리는 2가지 명령어이다. 비슷한 것 같지만 전혀 다른 명령어이다. 이번에 확실히 정리해두고
12.Splunk set command/ Splunk 두 개의 검색결과 중에서 같은 것만 찾기, 두 개의 검색결과 비교하기, 차이나는 결과 찾기
splunk 에서 두가지의 검색결과를 비교할 수 있는 명령어가 있다. 정말 집합의 의미로 set 명령어이다. 2가지 하위 집합의 교집합, 차집합, 합집합을 확인할 수 있다. 파이썬에서 set이라는 해시테이블로 구현된 자료구조가 있는데 그 기능과 동일하다. splunk
13.Splunk diff command/Splunk saved search, dashboard xml source 형상관리 하기
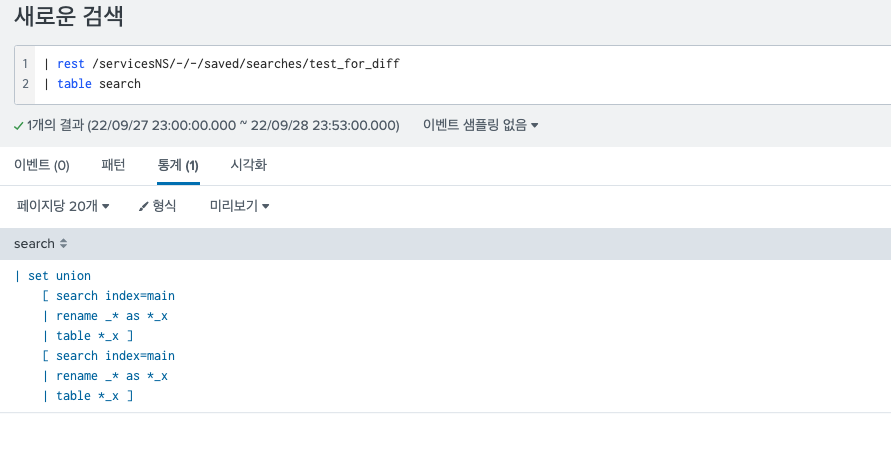
splunk 를 사용하다 보면, 특히 saved search 나 dashboard의 소스코드를 형상관리 해야될것 같은 생각이 든다.사실 마땅히 splunk에서 제공되는 형상관리 툴은 없다. 내부에서 git을 사용할 수 있게끔 만들어진 앱이 있는데 아직 사용해보지는 않았
14.Splunk Workflow, 워크플로우 만들기
splunk를 쓰다보면 workflow를 쓰는 일이 많아진다. 말 그대로 워크 플로우다. 어떤 검색을 하거나, ES에서 이벤트를 보거나, 등등.. 내가 보고있는 데이터로 추가적인 요청이 이어지는 플로우를 생성해주는 도구라고 생각하면 될 것 같다. Splunk 공식 문서
15.Splunk {} 연산자의 활용
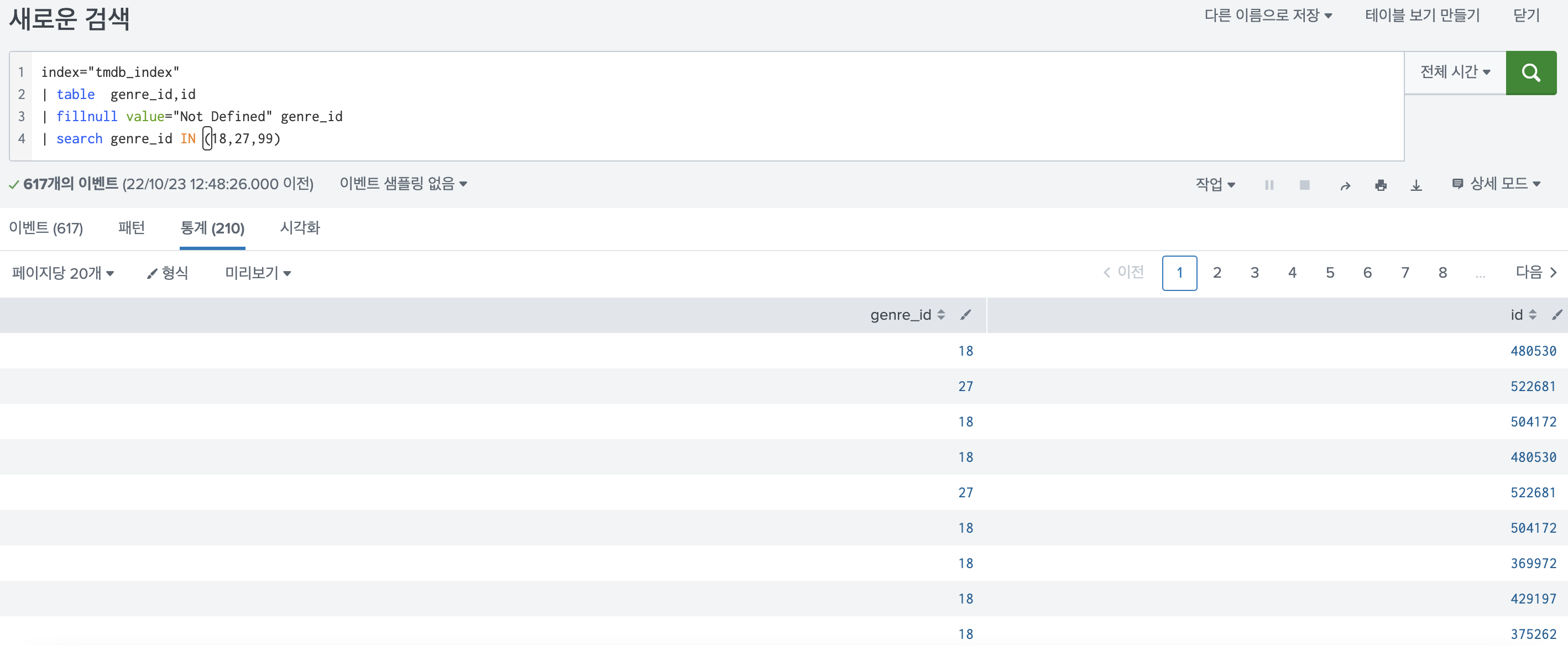
splunk 에서 {} 연산자가 있다. python에서 string.format으로 사용하는 기능과 매우 동일하다고 보면 된다.바로 쿼리로 보여주면 이렇게 된다.이런 검색을 했다고 치자. 그럼 다음과 같은 결과가 나온다.여기서 {} 연산자를 추가한 쿼리를 1줄 더 추가
16.Splunk eventtype, 이벤트 타입, 스플렁크 이벤트 타입, 이벤트 타입의 모든 것
오늘은 splunk 이벤트 타입에 관하여 포스팅한다. 유튜브를 참고, 공식문서를 참고했다. 1. 개념 Eventtype은 스플렁크에서 룩업, 태그와 같은 knowledge object 중 하나이다. Eventtype은 우리가 특정한 이벤트 들을 카테고리처럼 분류하여
17.Splunk history 명령어/ Splunk 검색 기록 보기 / Splunk 검색 히스토리 보기
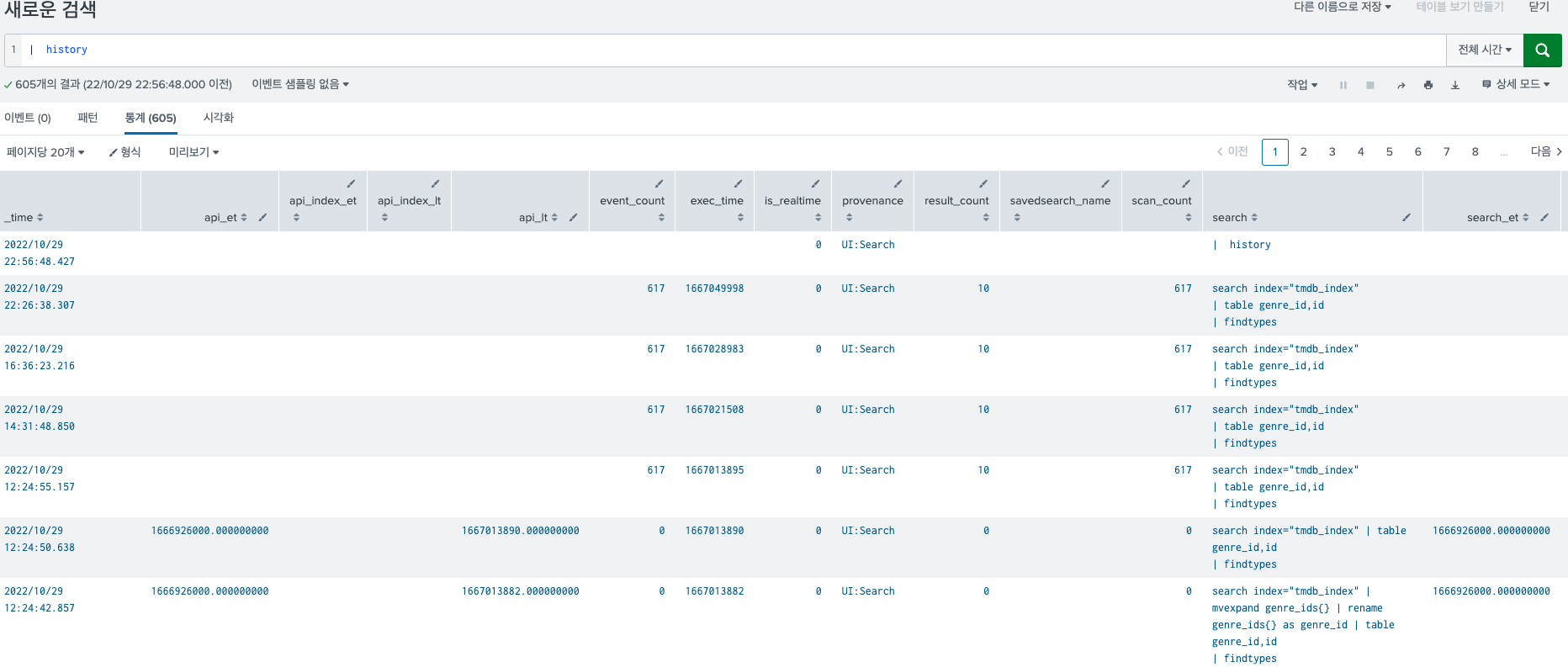
매우매우 간단하지만 유용한 history 명령어에 대해 소개한다.말 그대로 검색했던 기록을 모두 보여준다.간단하다. 그냥 history 라고 치면 된다.생각보다 너무 상세하게 나와서.. 매우 유용하다 느꼈다. 검색하다가 막 아까 검색한 쿼리문을 날려버렸을 때 아주 유용
18.Splunk multisearch 명령어
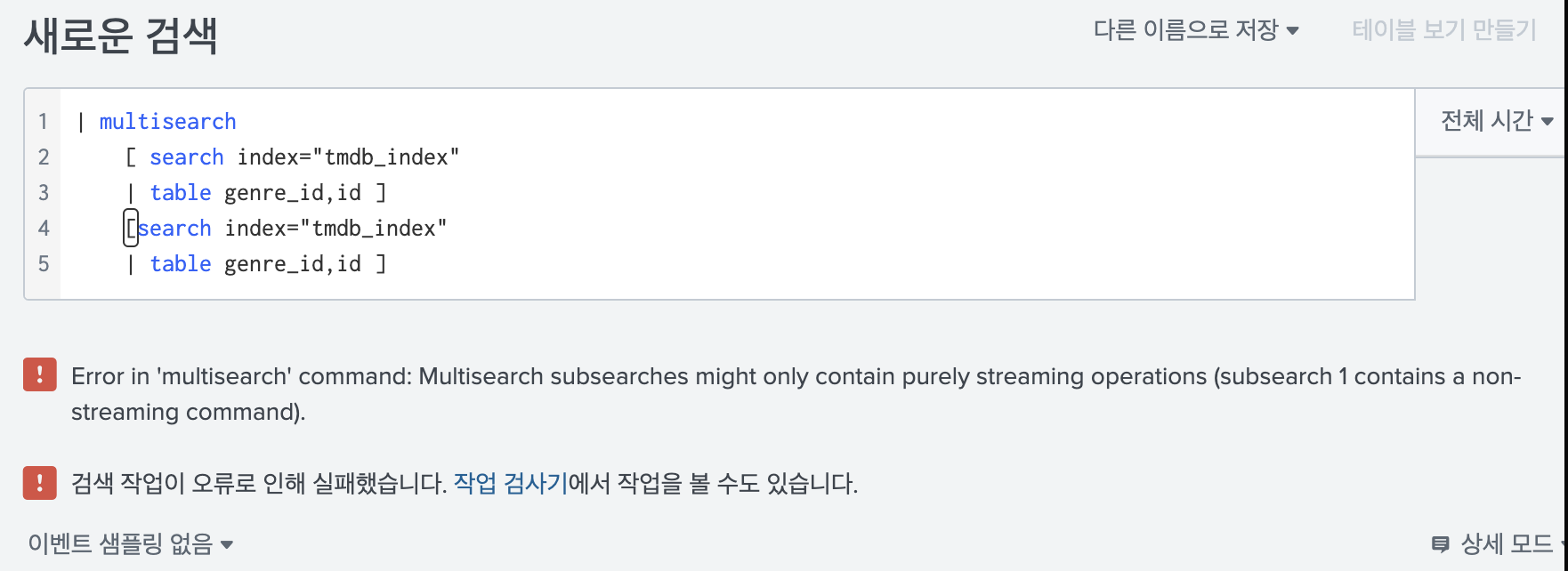
말 그대로 여러개의 search 문을 동시에 날려 결과를 확인할 수 있는 명령어 이다. 너무나도 간단하지만 많이 사용하기 떄문에 도움이 될 것 같다.공식문서를 참고했다.사용법은 정말 간단하다. 맨 위에 multisearch를 쓰고, 아래에 순서대로 하위 검색을 나열하면
19.Splunk append, appendpipe, appendcols append의 모든 것/ Splunk 검색결과 합치기
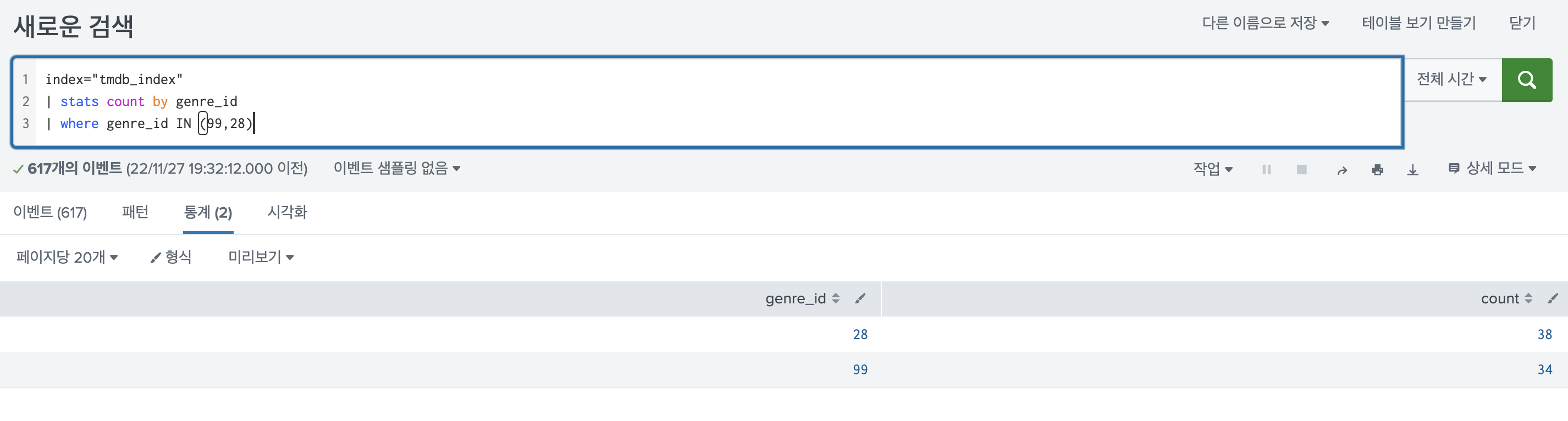
보통 대시보드를 만들때 두가지 결과를 합치고 싶을 때가 많다. 그럴때 많이 사용하는 것이 append 명령어 이다. appendpipe, appendcols는 거의 사용한 적이 없으나 알아보니 유용한 기능이고 이왕 아는거 3가지 다 아는게 나은것 같다. 검색을 합치는
20.Splunk JSON_PART1 json_object, json_set/ JSON 1탄
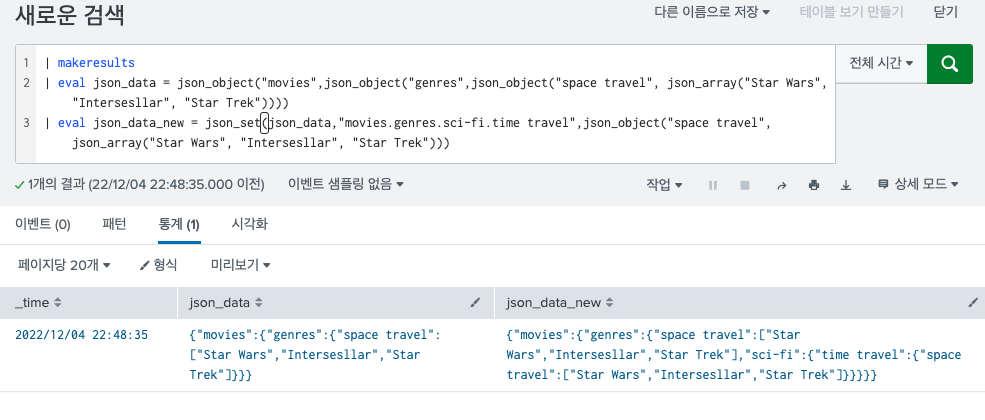
Splunk에서 은근 json 데이터를 많이 다루게 되는데, 이때 무조건 json 관련 함수를 쓰게된다. 쓸 때마다 찾아봐야해서 블로그에 정리해두려고 한다. 일단 공식 홈페이지에 가보면 json 과 관련된 함수가 11개나 있다. 각기 사용 방법이 다른데, 비슷한듯 하
21.Splunk JSON_PART2/ json 배열, json 관련 함수/ Splunk JSON 2탄
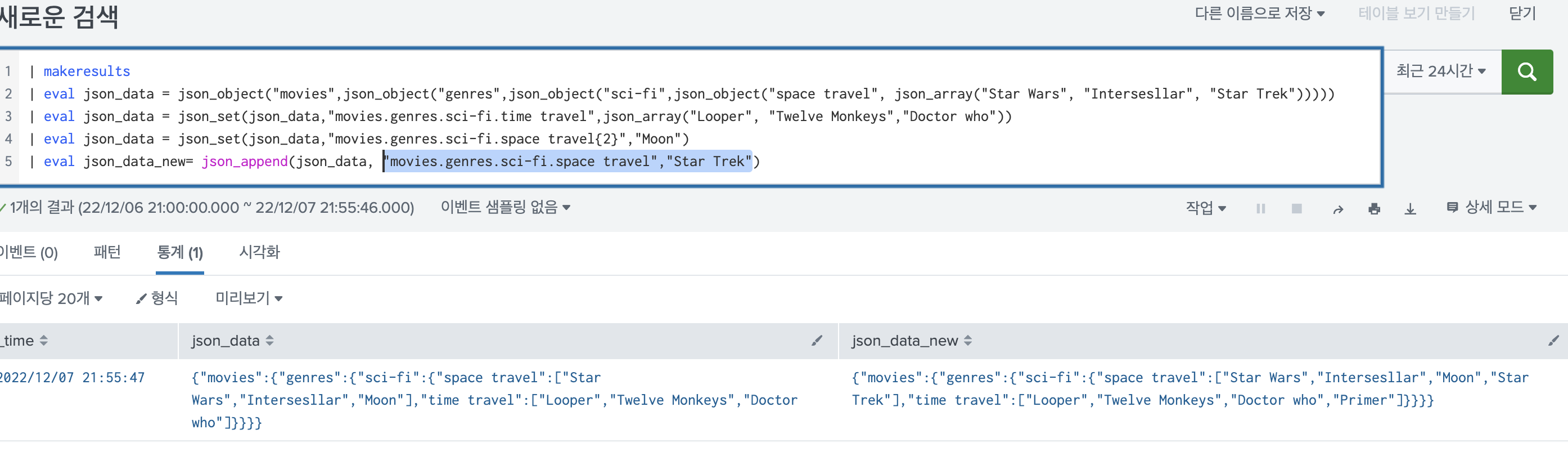
Splunk에서 은근 json 데이터를 많이 다루게 되는데, 이때 무조건 json 관련 함수를 쓰게된다. 쓸 때마다 찾아봐야해서 블로그에 정리해두려고 한다.일단 공식 홈페이지에 가보면 json 과 관련된 함수가 11개나 있다. 각기 사용 방법이 다른데, 비슷한듯 하면서
22.Splunk 앱 제거하기
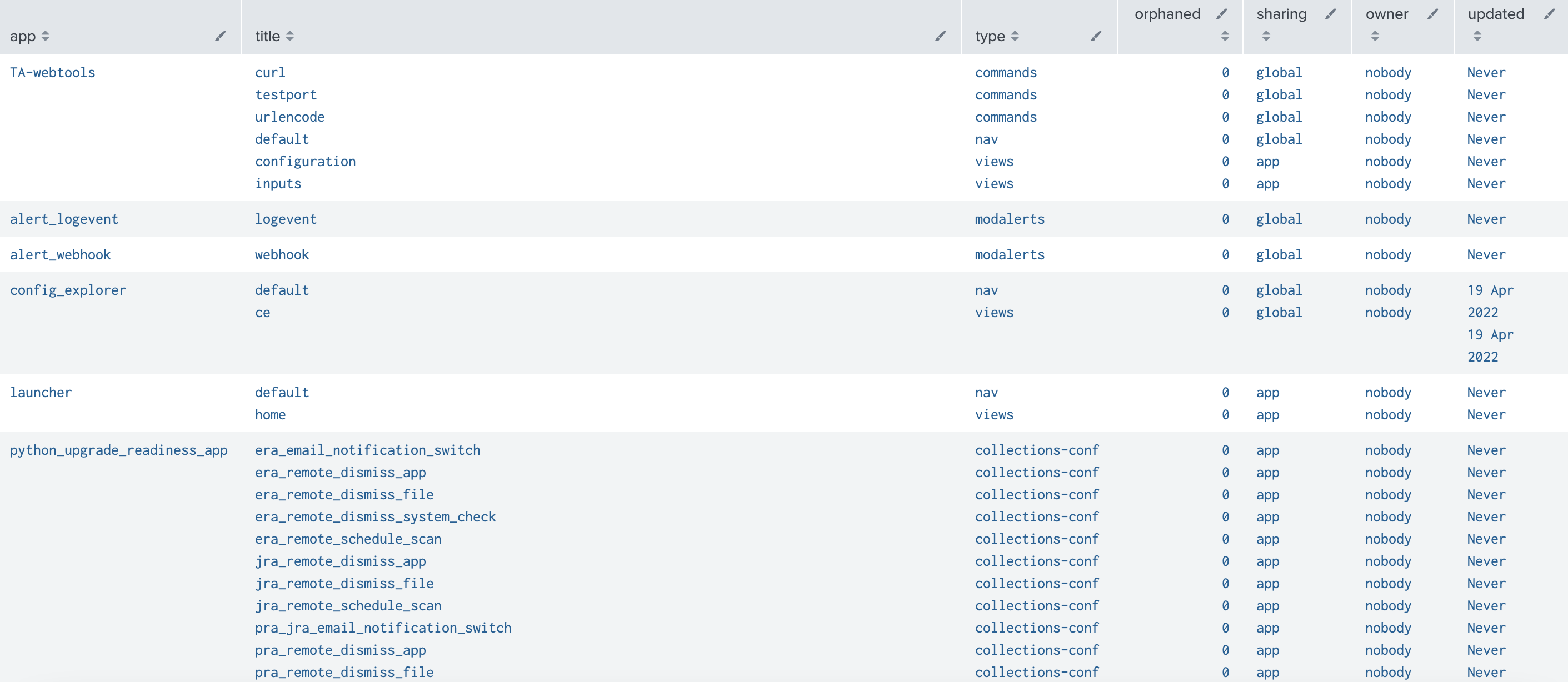
Splunk에서 앱을 제거해야 할 때가 있다. 일단 UI에서는 제거하는 탭이 없다.터미널에서 직접 제거해줘야 하는데, 이때 주의해야 할 점이 있다.saved searchesevent typestagsfield extractionslookupsreportsalertsda
23.Splunk DB-Connect app 시작하기 - 1탄 (Splunk에 RDBMS DB연결하기)

유튜브 영상을 참고했다. 0. 개념 1. 관련 프로그램 설치하기 1) mysql 설치하기 나는 맥북을 사용하기 때문에 맥북 기준으로 설치 가이드를 안내한다. 윈도우를 사용하는 경우에는, 사용 방법만 다를 것이기 때문에 각 OS에 맞는 설치 방법을 검색하여 프로그램을
24.Splunk DB-Connect app 시작하기 - 2탄 (Splunk에 RDBMS DB연결하기)
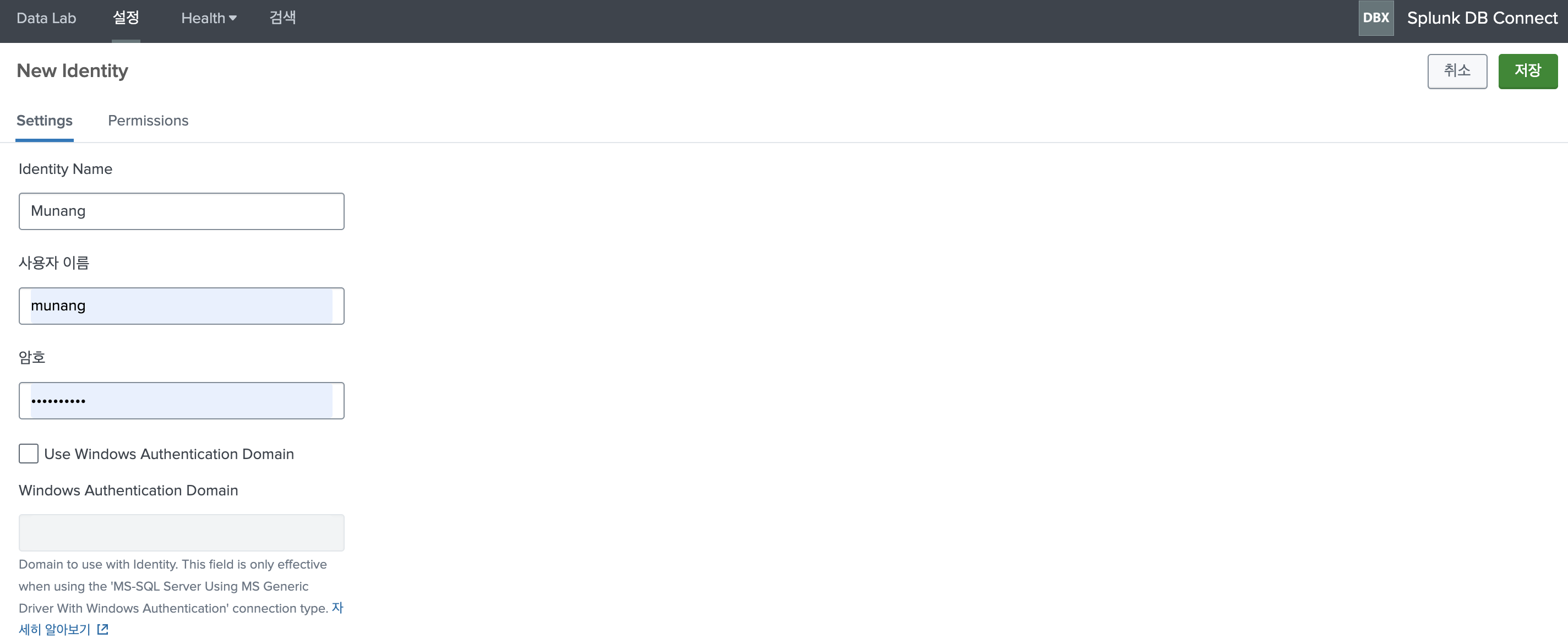
이번 포스팅에서는 앞서 1탄에서 DB-Connect 앱을 사용하기 위한 설정을 모두 마친 후 실제 DB Connect에서 사용할 Identity생성과, 연결을 담당하는 객체(?)를 생성하는 과정을 진행할 것 이다.Splunk 에서 DB에 연결할 데이터 베이스 전용 사용
25.Splunk DB-Connect app 시작하기 - 3탄 (Splunk에 RDBMS DB연결하기, RDBMS 데이터 수집하기)
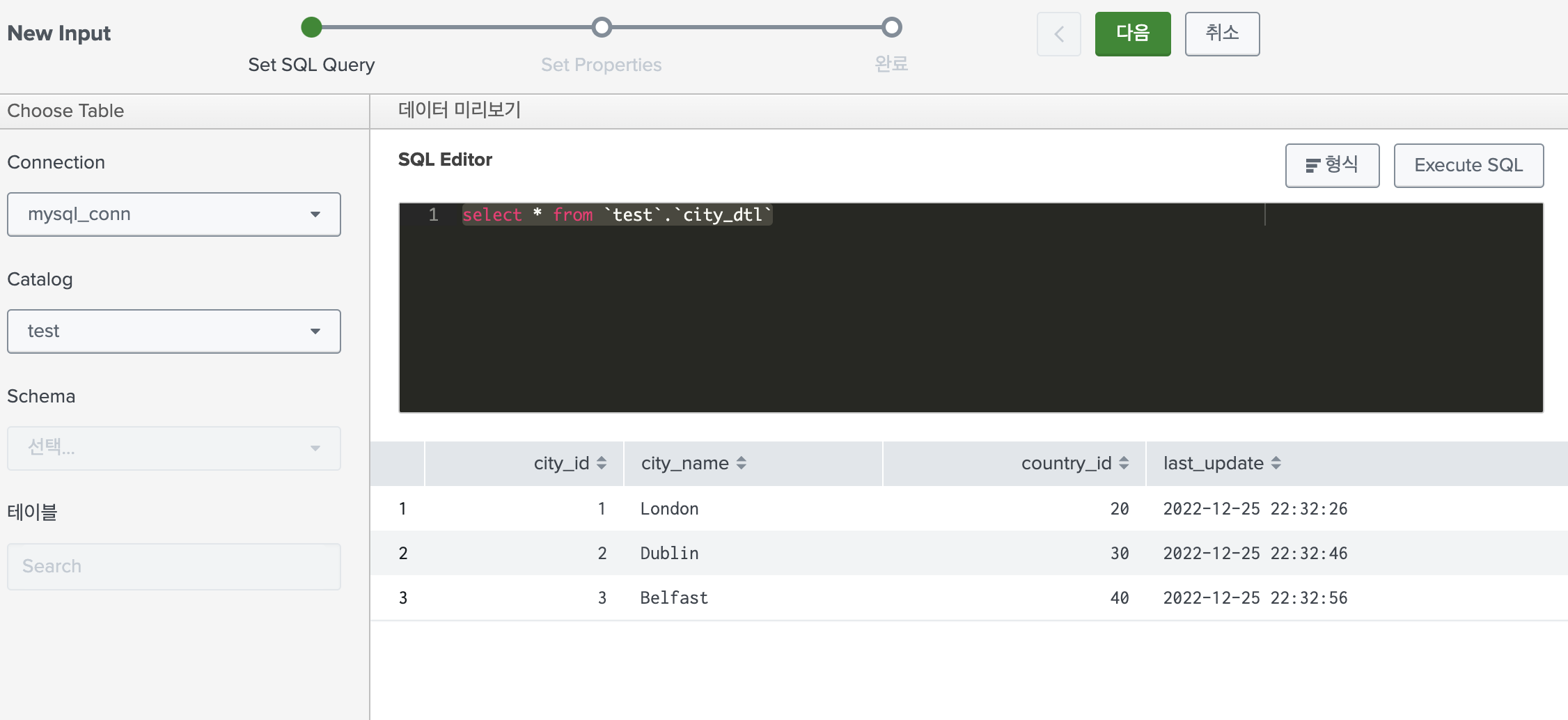
오늘은 본격적으로 DB-Connect app으로 데이터 베이스의 데이터를 인덱스로 가져올 것 이다. 먼저 DB-Connect app> Data Lab > New InputConnection: 내가 특정 SQL에 연결하기 위해 만든 커넥션을 선택해준다.Catalog: 연
26.Splunk DB-Connect app 시작하기 - 4탄 (Splunk에서 RDBMS로 데이터 INSERT, UPDATE 하기, dbxoutput 사용하기)
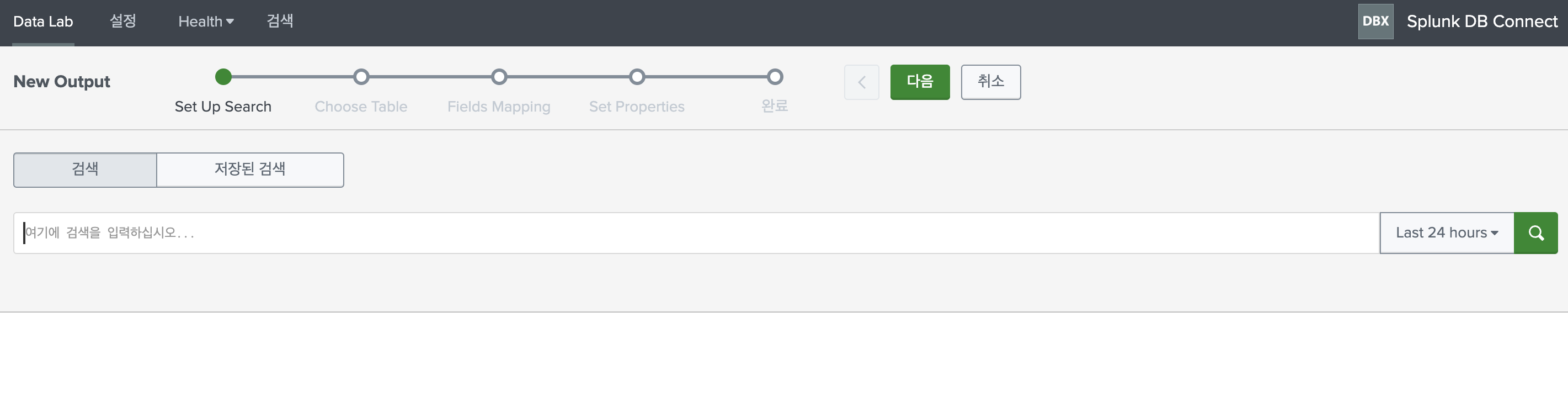
splunk에서 쿼리를 사용해서 RDBMS에 접근할 때에는 대부분 dbxquery를 사용한다. 하지만 간혹 dbxoutput 쿼리를 사용할 때가 있다. 그런데 맨 처음 dbxoutput을 사용할 때 이상한 점을 느낀다. 그냥 update, insert 쿼리를 사용해서
27.Splunk map, foreach 사용법
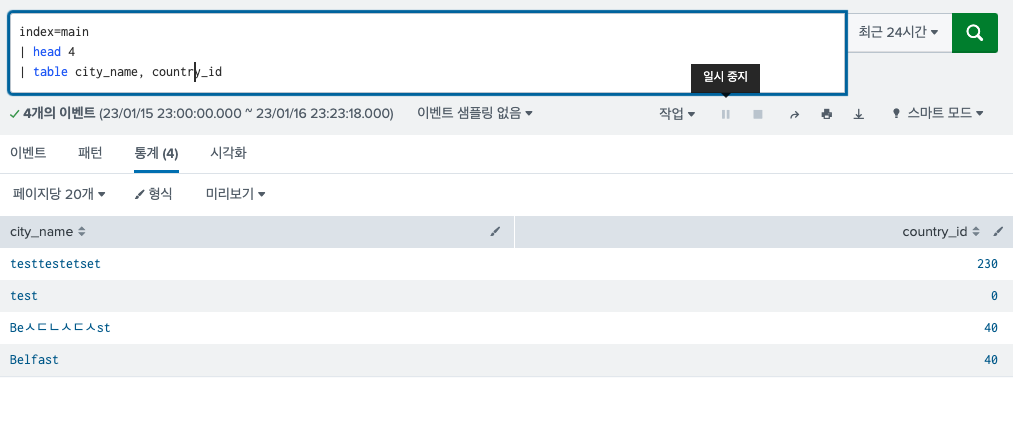
가끔 splunk로 쿼리를 사용하다보면.. 특히 saved search를 제작할 때에 for문을 돌리고 싶다는 생각이 든다. 정확히 쿼리에 for문을 사용한다는 것 자체가 애매한 표현이기는 하지만, 반복적인 행위를 쿼리 내에서 수행할 수 있는 방법이 있다. 사용하는 방
28.Splunk 정규 표현식 관련 커맨드 rex
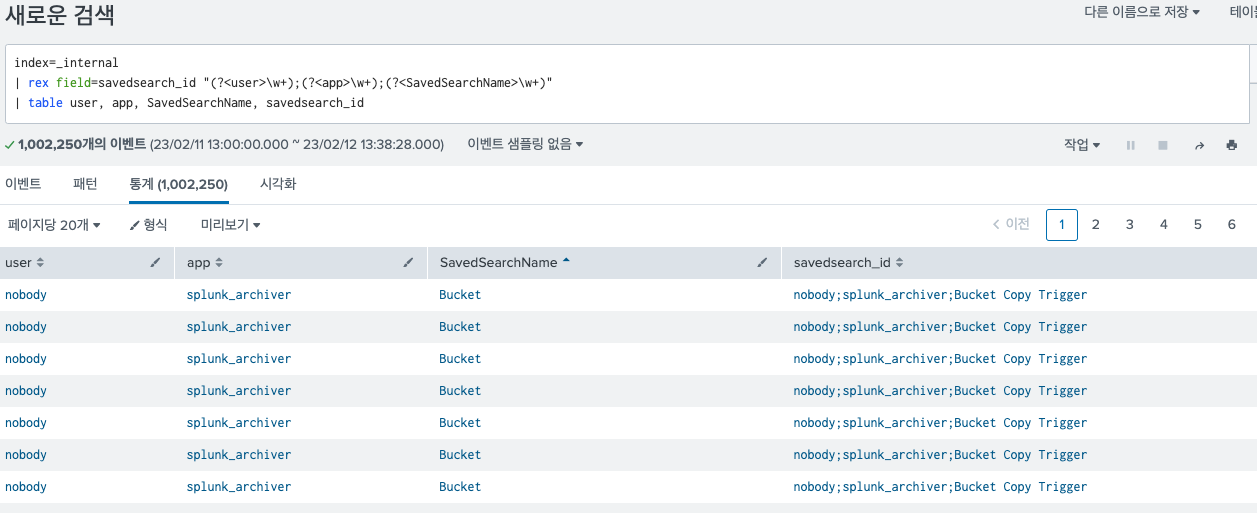
splunk에서 정규 표현식을 사용할 때 자주쓰는 rex를 정리한다. 정규표현식을 기반으로 필드를 추출해주는 커맨드이다. 필드를 추출할때 사용되기 때문에 정규 표현식 중에서도 (?P<name>regex) 형태의 명명 그룹 기능을 이용한다.그 외에도 sed를 이용해
29.Splunk Job Inspector에 관해
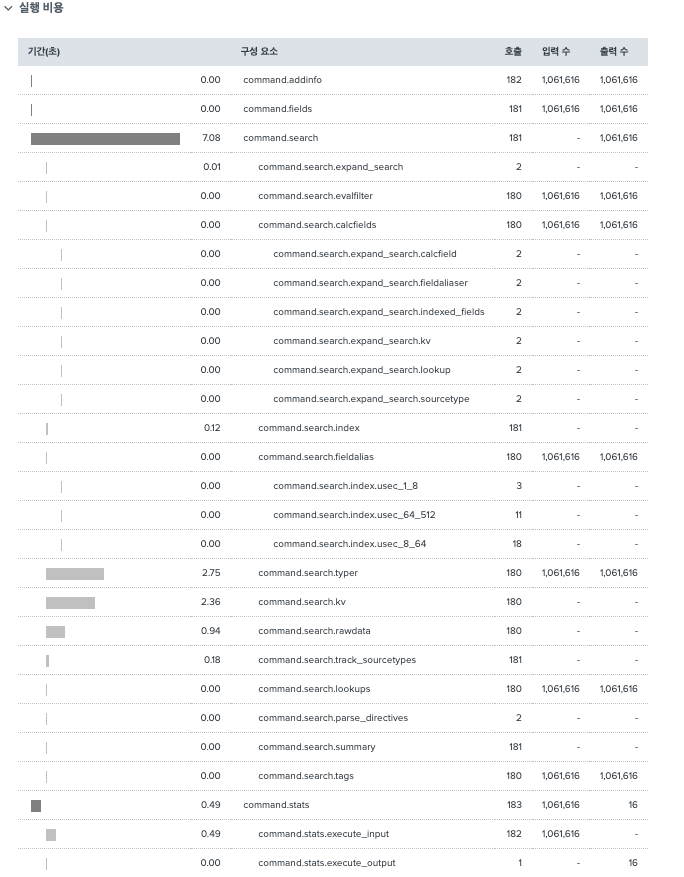
Splunk 작업 검사기에 대해 정리한다. 매번 볼 때마다 정리의 필요성을 느껴왔다.나는 보통 custom command search를 만들어서 사용할때 에러 로깅으로만 사용해왔는데, Splunk를 쓸 수록 세이브 서치를 만들면서, 다량의 데이터를 이용해 검색하면서 이
30.Splunk return & format 에 관하여 / 여러 column과 row를 한번에 검색할 때
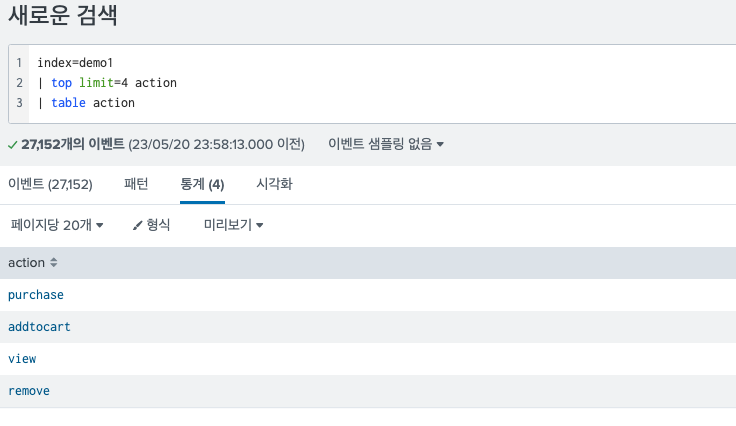
Splunk를 이용해서 검색하다보면 어떤건 제외하고, 어떤건 포함하고 하는 식으로 이것 저것 조건을 만들게 된다. 그러다 보면 예외 처리나 포함하는 구문으로만 10줄이 넘어가게 된다. 이럴때 유용하게 사용할 수 있는 명령어가 있는데 바로 return과 format이다.
31.Splunk tstats 에 관해
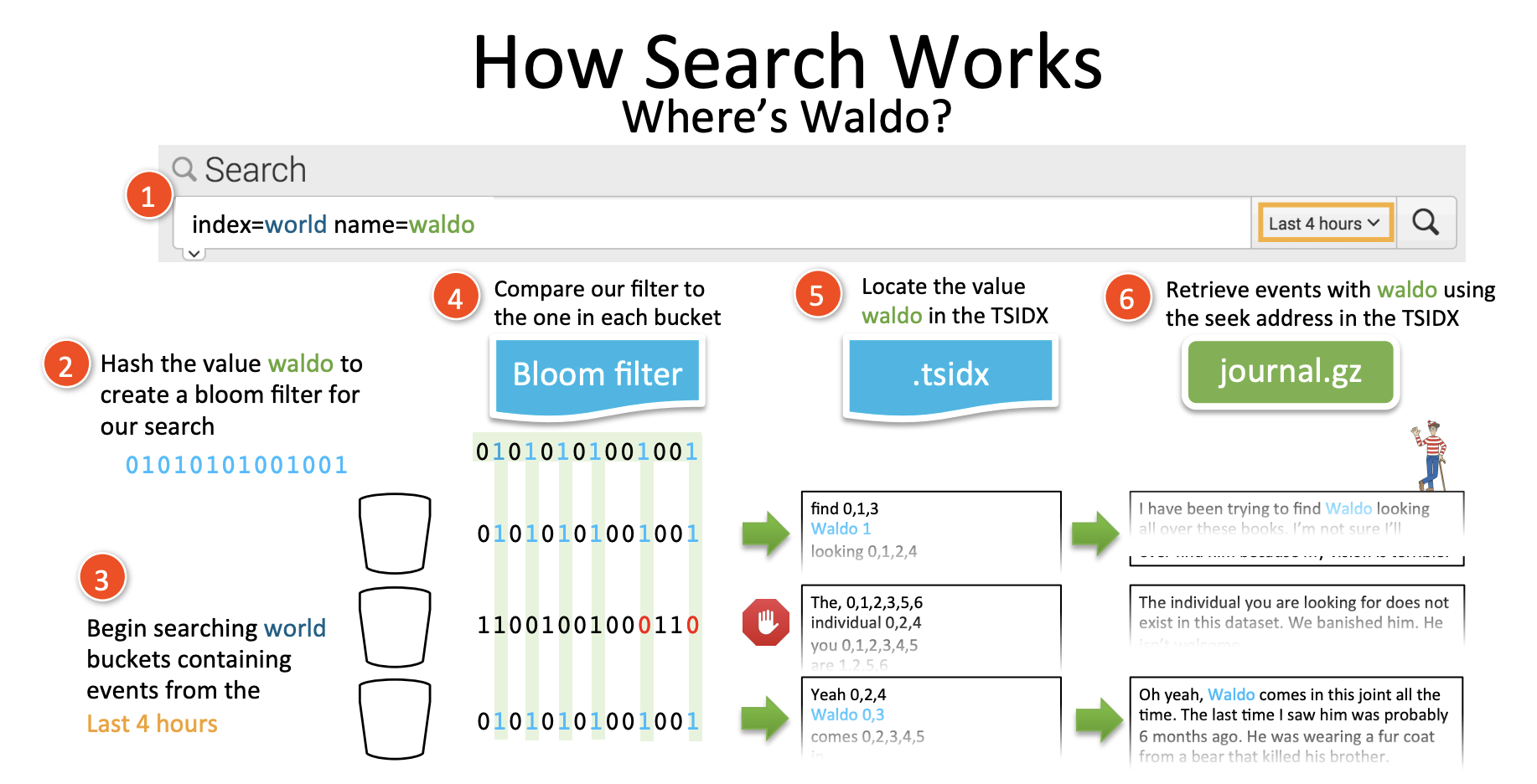
오늘은 tstats에 관해 알아본다. tsidx 파일의 통계수행을 위한 전용 커맨드이다. 기능은 stats와 유사하지만 훨씬 더 효율 적이다. tsidx는 timeseriesindex 이다. tsidx는 데이터의 각 고유 키워드를 원시 데이터에 저장되는 이벤트의 위치값
32.Step 1. Splunk 인스턴스에 Universal Forwarder 연결해보기
오늘은 Splunk 인스턴스를 설치하는 실습을 해볼 것 이다. 구글 클라우드로 했었지만, 무료 라이센스가 다 끝나서 오라클 클라우드를 이용했다. 오라클 클라우드는 무료기능도 다양해서 이 점이 좋다. splunk 다운로드 주소 wget -O splunk-9.1.2-b6
33.Configuration in Splunk/Splunk .conf 파일 우선순위/Splunk 구성파일
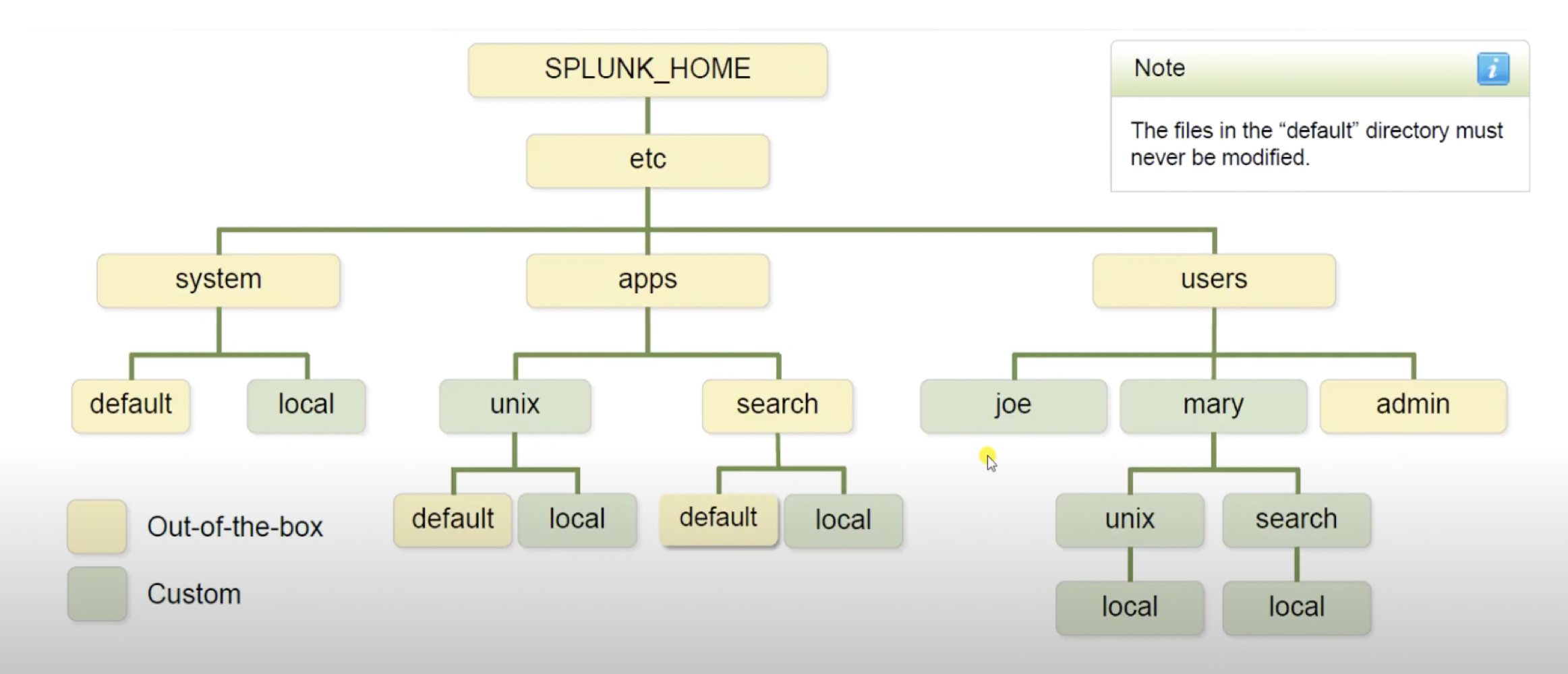
오늘은 Splunk를 사용한다면 가장 많이 접근하게 되는 .conf 구성 파일의 우선 순위를 알아볼 것 이다. local, default 등의 디렉토리가 나오는데 사용하다 보면 헷갈려서 정리해두는게 좋을 것 같다.splunk 에서 구성 파일은 다음과 같은 설정을 지정할
34.Step 2. Splunk 인스턴스에 Heavy Forwarder 연결해보기
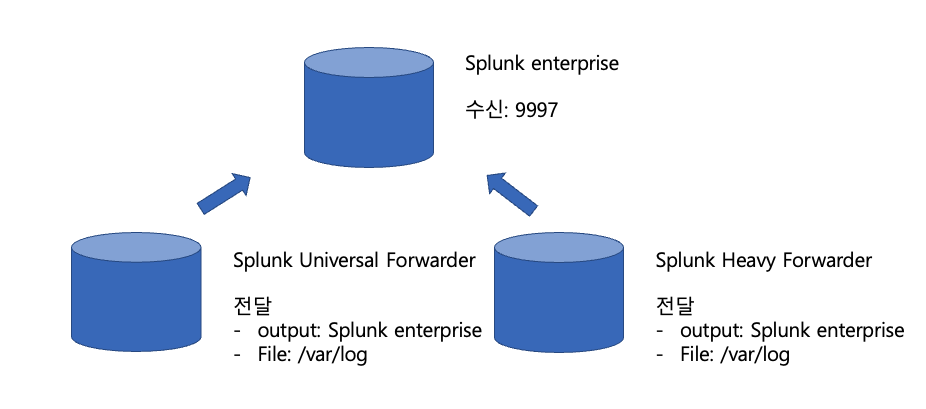
오늘은 Universal Forwarder가 연결된 구성에 Heavy Forwarder를 추가하여 구성해볼 것 이다.
35.Step 3. Splunk Heavy Forwarder를 이용해 라우팅, 필터링 하여 인덱서 저장하기
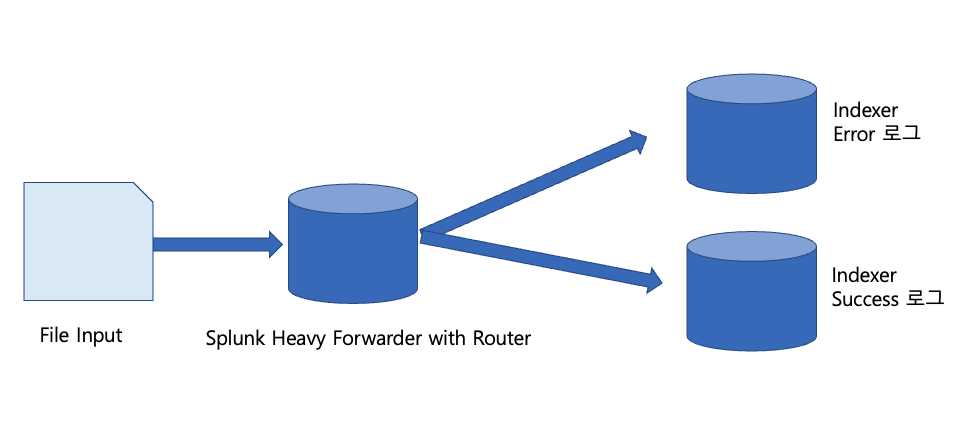
노로바이러스에 걸려서 한동안 힘들었다. 아무튼 이번 시간에는 헤비포워더의 라우팅, 필터링 기능을 이용해 다른 인덱서에 각각 저장하는 실습을 해 볼 것이다. 오늘 해볼 구성을 그림으로 표현하면 다음과 같다. 간단한 구성이다. 1. Splunk 인스턴스 설치 설치과정은
36.Step 4. Splunk Forwarder Deployment 구성해보기
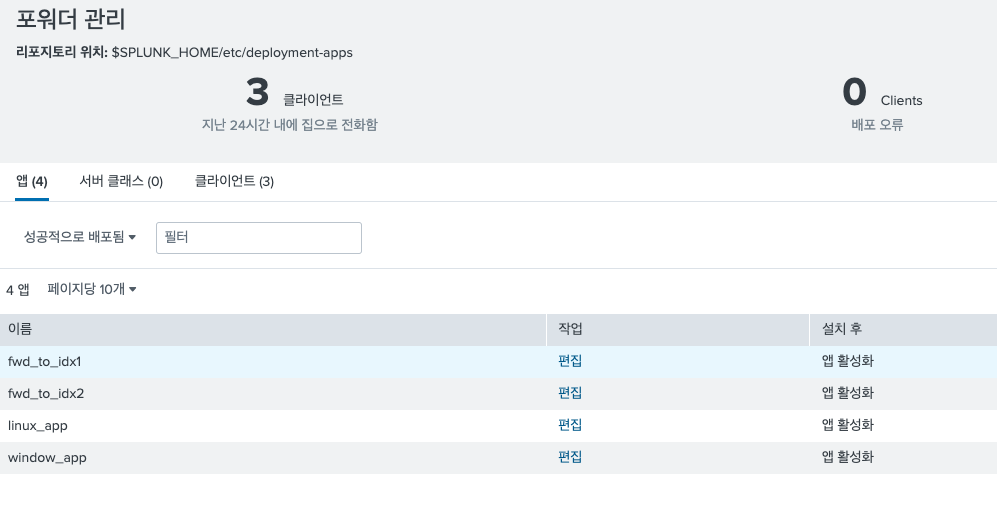
여러 Forwarder를 운영한다고 할 때, 각 포워더가 하나의 인덱서를 바라본다고 한다면 우리는 매번 포워더에 접속해서 변경사항을 반영해야 할 것 이다. 여간 불편한 것이 아니다. 이때 필요한 것이 Deployment 서버이다. 하나의 배포 서버에 복사본을 만들고
37.Splunk Input 부터 Search 까지의 데이터 파이프라인 과정
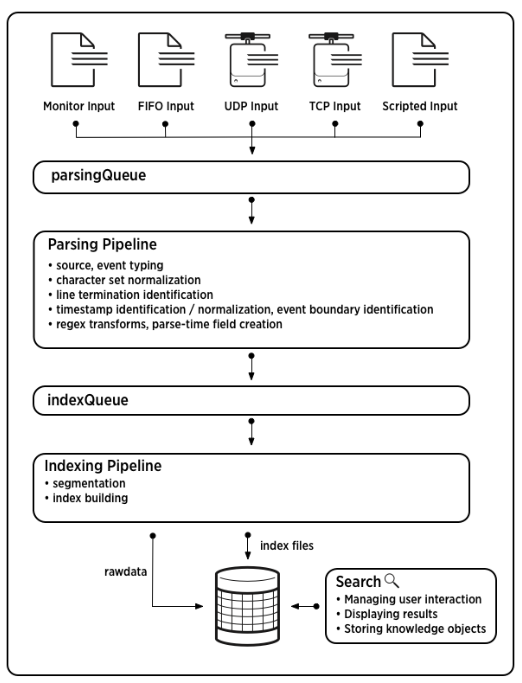
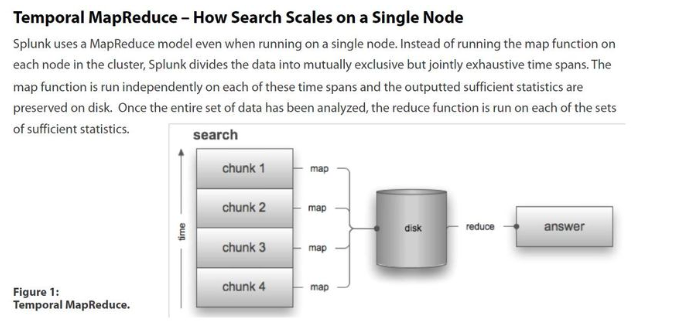
오늘은 Splunk에 데이터가 입력되는 순간부터 검색되는 순간 까지의 데이터 파이프 라인에 대해 알아 볼 것 이다. 스플렁크 공식 문서를 참고하였다. 출처: Splunk 공식 Docs데이터 파이프 라인은 크게 4가지 단계로 이루어져있는데 입력, 파싱, 인덱싱, 검색 과
38.Splunk Component / Splunk 구성요소 알아보기
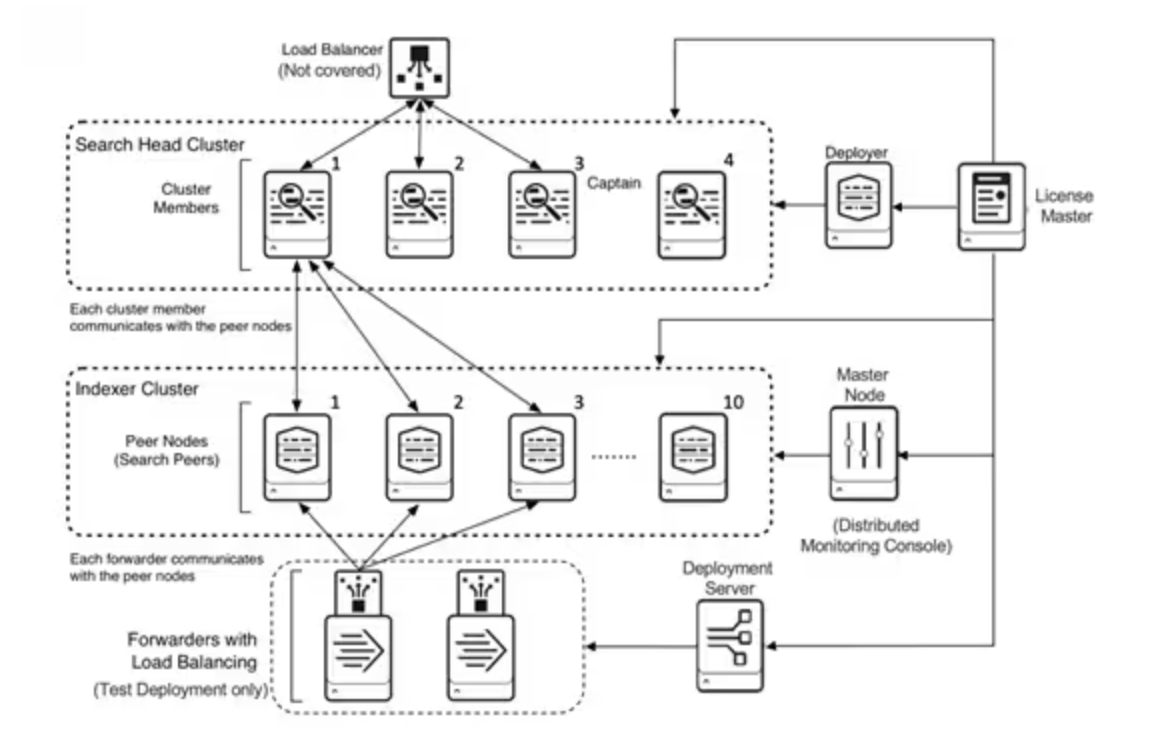
splunk를 알아보려면 어떤 요소가 있고 그것이 어떤 구조로 이뤄져있는지 파악해야 하는데, 이번 시간에는 어떤 요소가 있는지 알아볼 것 이다. 참고 문서는 Splunk Docs이다. splunk의 구성 요소는 아래와 같다. 아래의 구성요소는 모두 같은 인스턴스로 설치
39.Step 5. Splunk Search Head Clustering & Deployer 구성
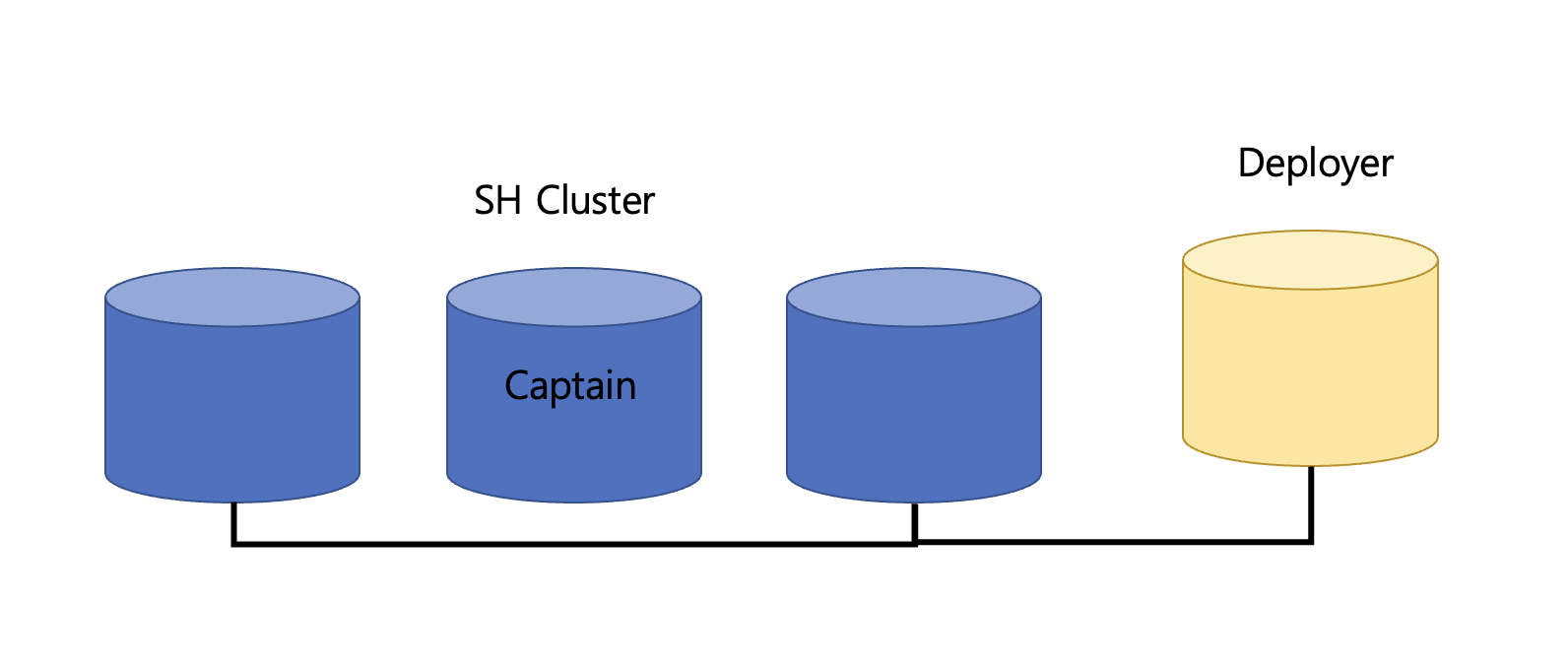
오늘은 Splunk에서 Search head 클러스터링과, Deployer를 구성해보겠다. 1. Splunk 인스턴스 준비 Splunk 인스턴스는 총 6대가 필요하고, 3대는 검색헤드, 2대는 인덱서, 1대는 디플로이어로 사용할 것 이다. 모두 Splunk Enter
40.Step 6. Splunk Search Head Clustering에 Indexer 연결하기
Search head 클러스터링에 인덱서를 연결하는 작업을 해 볼 것이다. 이번 과정은 Step5와 연결된다. 따라서, Step5를 끝낸 이후에 진행하면 좋을 것 같다. 설정>분산환경>검색 헤드 클러스터링 부분을 확인하여 클러스터링 설정이 되어있는지 먼저 체크한다.안되
41.Splunk Search Head Cluster에 관하여/ Search Head가 복제하는 정보
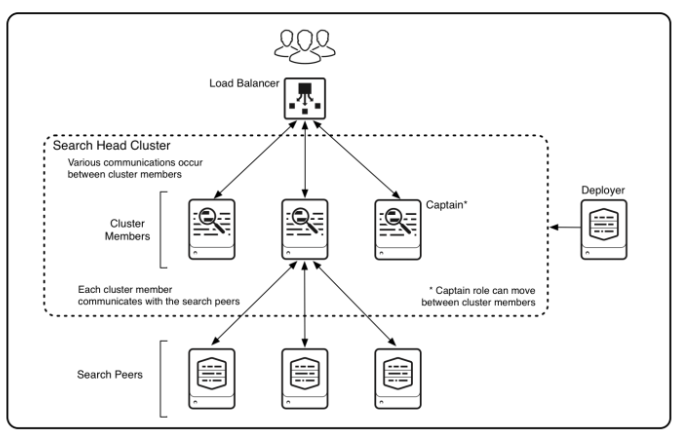
검색 헤드 클러스터는 검색을 위한 중앙 리소스 역할을 하는 검색 헤드 그룹이다. 클러스터 내에서는 동일한 검색을 실행하고, 동일한 대시보드를 보고, 클러스터의 모든 멤버에서 동일한 검색 결과에 접근할 수 있다.수평 확장이 가능하다: 사용자 수와 검색 로드가 증가하면 클
42.Step 7. Splunk Search Head Clustering에 새로운 멤버 추가하기/클러스터 멤버 add하기
오늘은 기존에 있는 SH 클러스터링에 새로운 검색 헤드 멤버를 추가하게 되는 경우를 실습한다. 내용은 Step5에서 이어지기 때문에 아직 해보지 않았다면, Step5를 완료하고 실행하는 것이 좋다. 오늘 포스팅은 길지 않다. 먼저 기존의 SH클러스터링을 구성하기 전,
43.Step 8. Splunk Search Head Cluster에서 멤버 제거하기/ Cluster 멤버 영원히 제거/ Cluster 멤버 제거 후 재사용하기
내용은 Step7에서 이어진다. 따라서 Step5~7의 구성을 실행해보지 않은 사용자는 직접 해본 후 Step8로 넘어오는 것을 추천한다. 1. Remove Cluster Member 1) 클러스터 멤버로 재사용이 될 경우의 제거 soft way는 해당 클러스터의 멤
44.Step 9. Splunk Search Head Clustering Captain Election Work / Splunk Search Head 클러스터링 캡틴 선출 과정 / Splunk 캡틴 선출
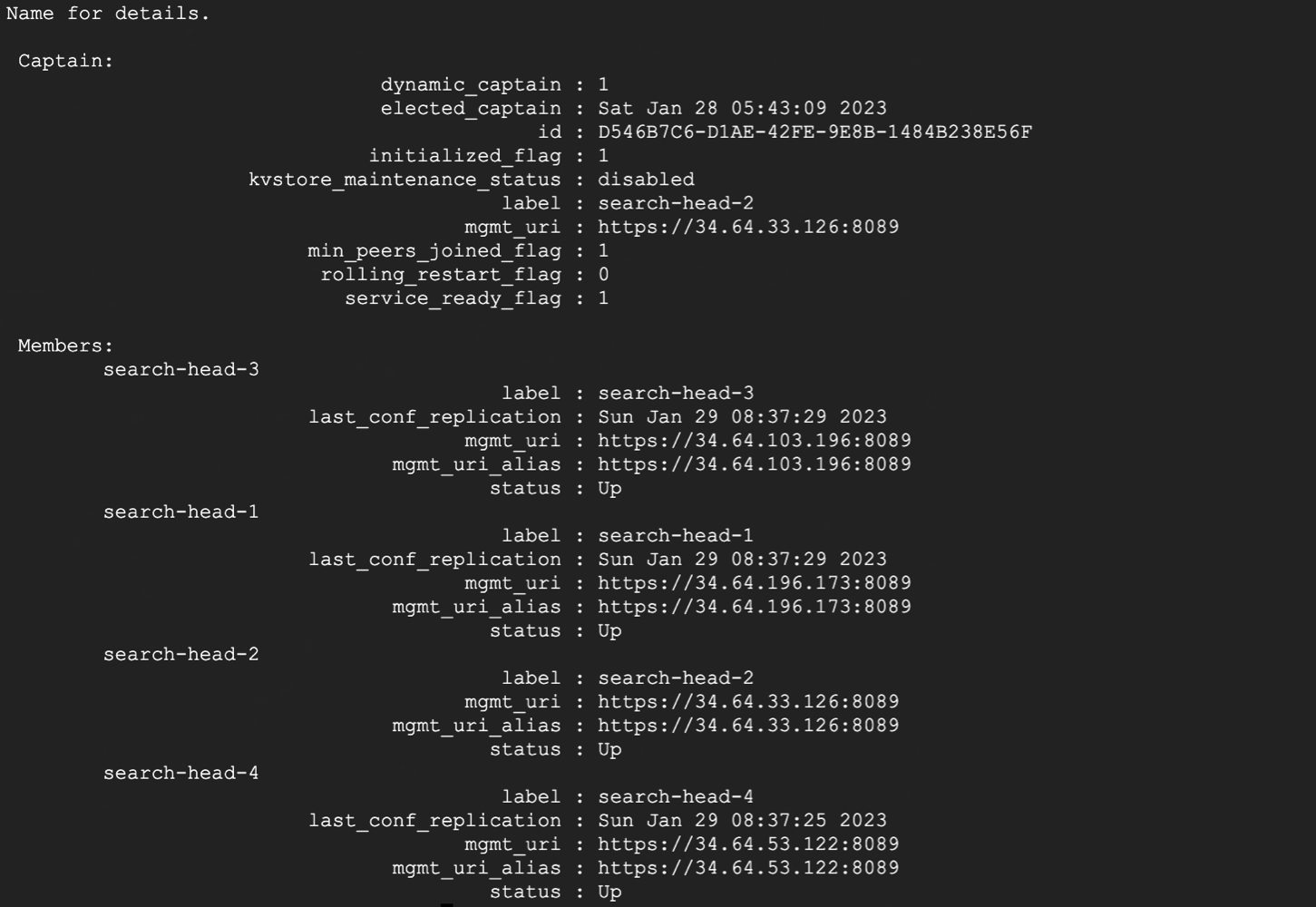
이번에는 SearchHead 클러스터링에서 캡틴 선출 과정에 대해 확인한다. 이번 시간에는 SH 클러스터링이 이미 갖춰져 있다는 가정하에 진행한다. 클러스터링 환경을 갖추지 못한 사람은 Step5. Splunk Search Head Clustering & Deploye
45.Step 10. Splunk Static Captain/ Splunk 정적 캡틴
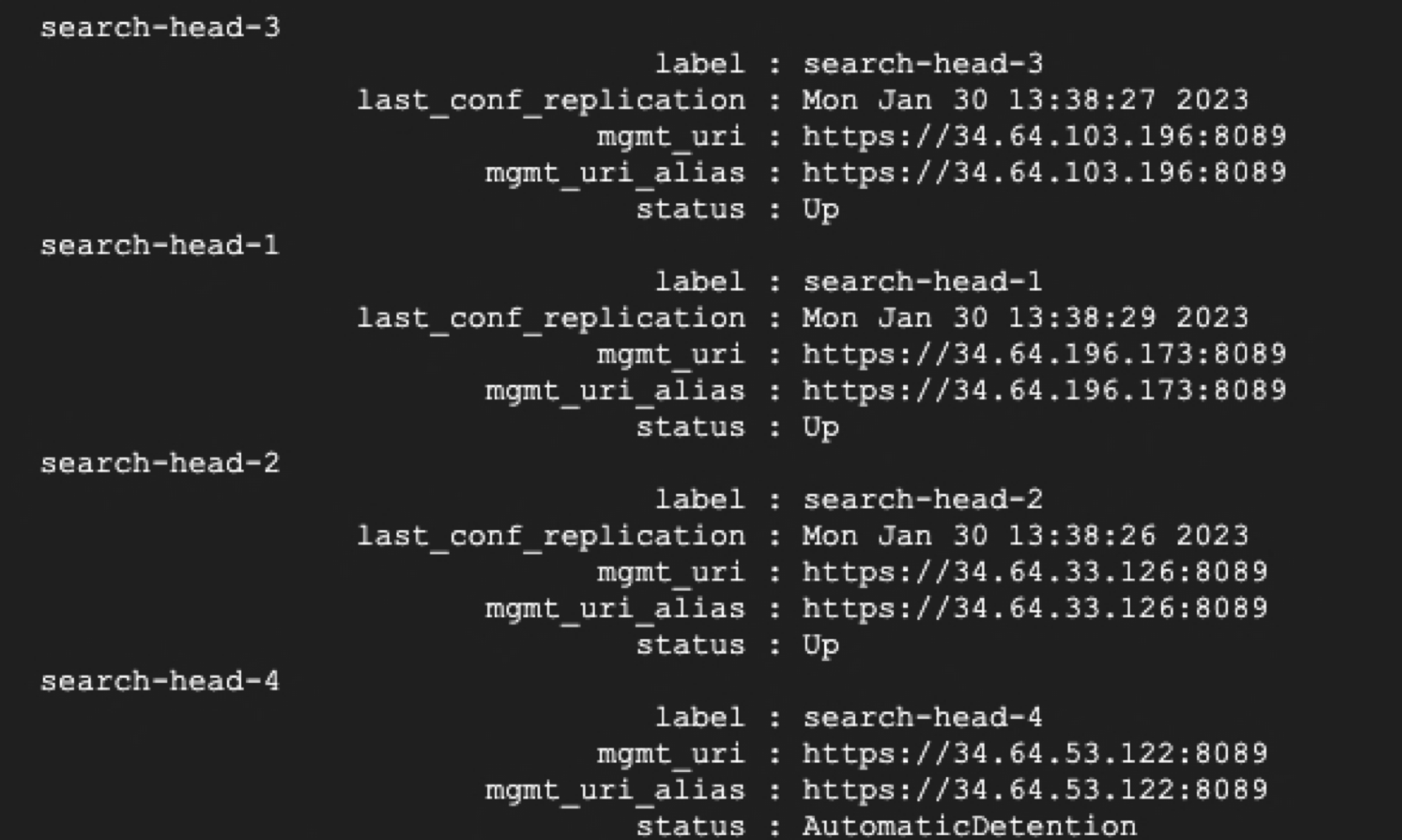
이 내용은 Step 9 에서 이어진다. Step 9의 마지막 부분에서 과반수의 원칙을 충족하지 못하는 만큼의 Search Header 구성원이 존재할 경우, 캡틴 선출에 실패하는 케이스를 확인했다. 실제 상황에서 이런 경우는 매우 희소한 편이나 이를 대비해 Static
46.Splunk Search Artifacts에 관하여
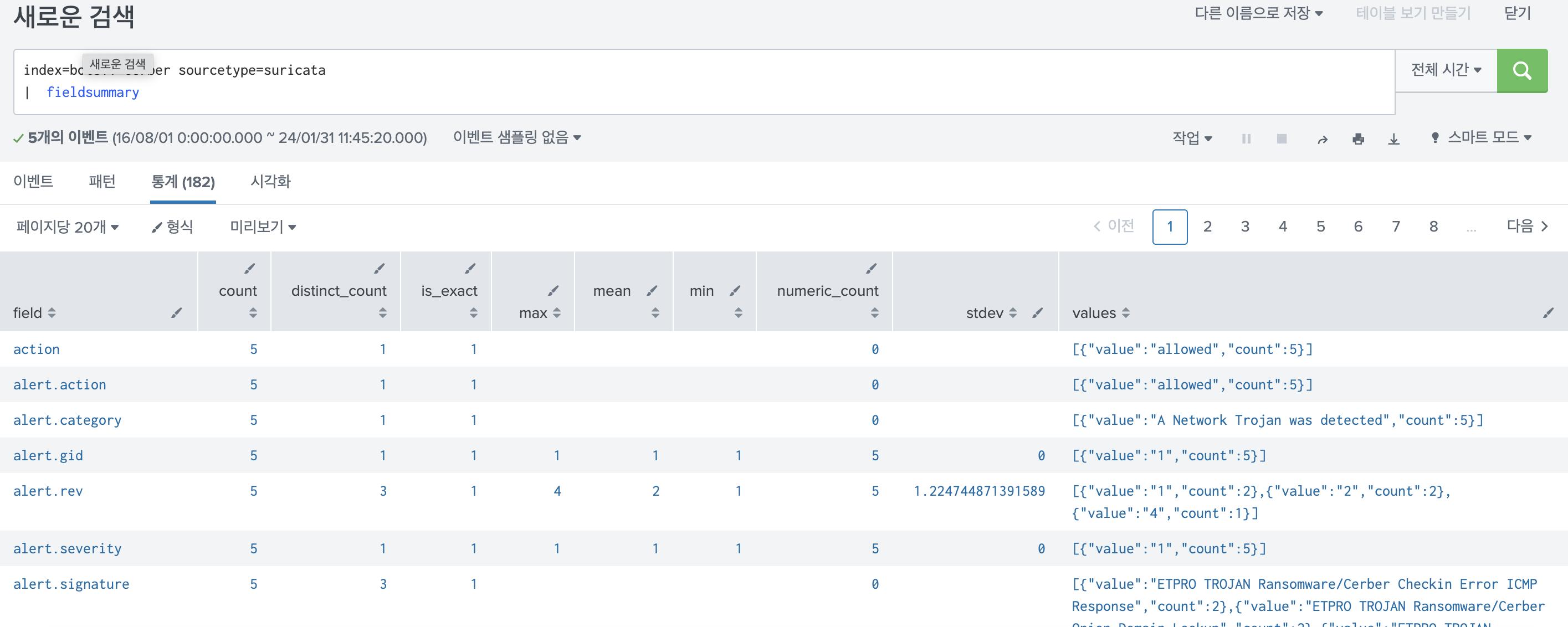
오늘은 Splunk의 검색 팩터에 대해 다룬다. 이전에 Splunk Search Head Clustering을 구성할 때에 복제 팩터에 대해 언급한 적이 있다. 바로 이 부분이다. 위의 명령어에서 클러스터의 구성 정보를 지정할 때에 복제 팩터를 지정해 줘야 한다.
47.Splunk Indexer Cluster에 관하여
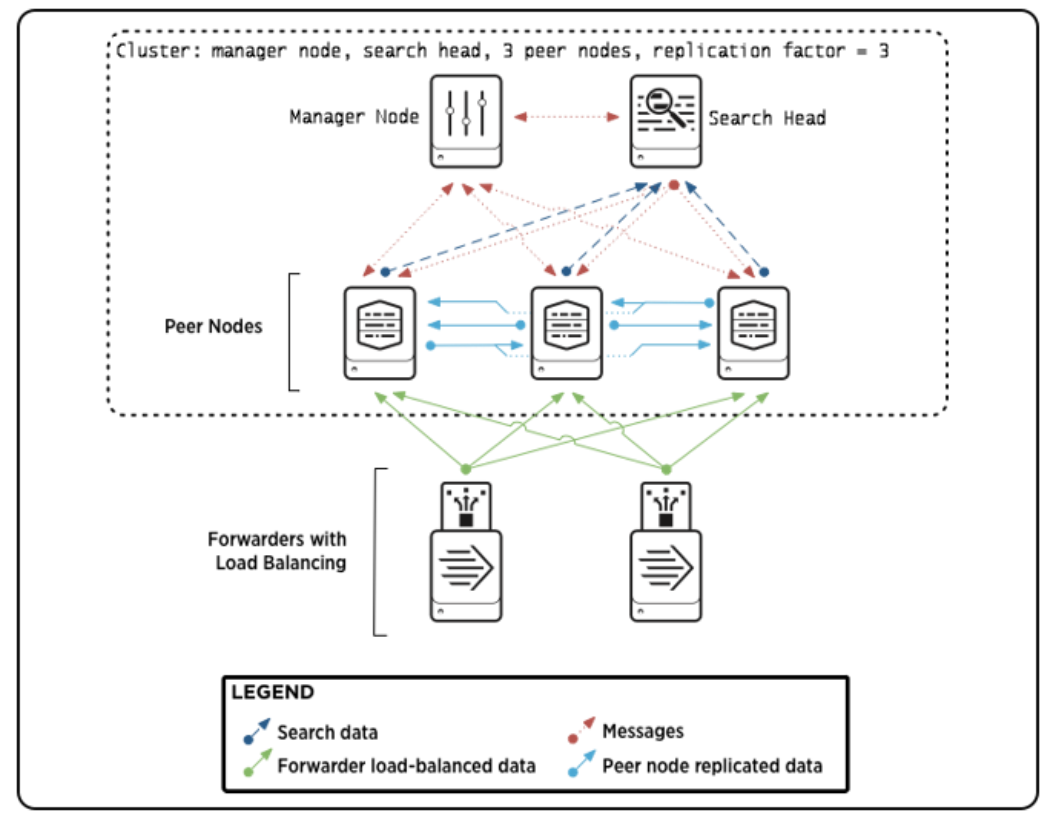
오늘은 Splunk Indexer Clustering에 대해 포스팅을 한다. 0. Indexer Clustering이란? Splunk 시스템이 모든 데이터의 여러 복제본을 보관할 수 있도록 서로의 데이터를 복제하도록 구성된 Splunk Enterprise의 인덱서 그
48.Splunk Bucket에 관하여
오늘은 Indexer Cluster 에서 등장했던 중요한 개념 중 하나인 Bucket 개념에 대해 조금 더 상세하게 알아보려고 한다. 아래의 나온 그림은 이 문서에서 가져왔으며, 내용의 대부분은 공식 문서를 참고하였다. 1. Bucket 이란? Splunk 에서 데이
49.Splunk stats와 chart, timechart의 차이에 관하여

Splunk를 사용하다보면 일단 거의 집계관련 커맨드는 stats만 사용하게 된다. 이것으로 대부분의 내용 커버가 가능하다. 그래서 사실 이것만 알아도 문제는 없지만, 가끔 아주 간혹 chart 명령어를 사용할 때가 있다. stats는 시각화를 하게 될 경우 원하지
50.Splunk DataModel, 가속화의 개념에 대해
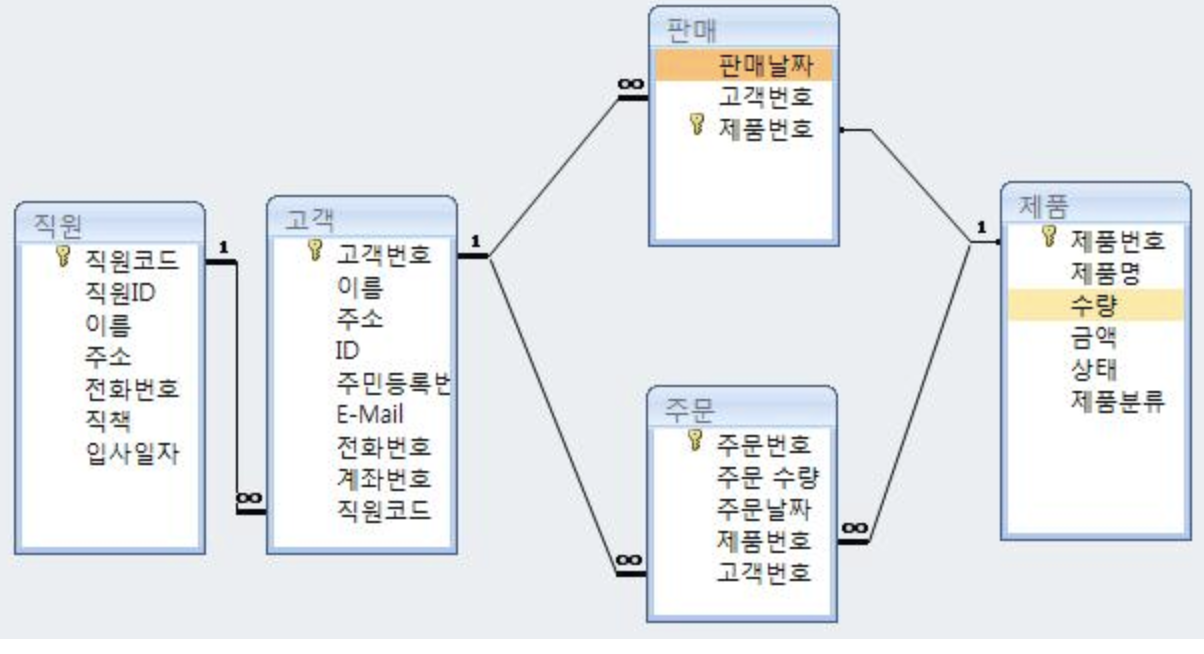
Splunk를 사용할 때 stats, 대시보드, savedsearch 다음으로 많이 사용하는 것은 DataModel이 아닐까 싶다. 가속화, 데이터 모델 등 데이터 모델과 관련된 키워드는 여러 번 듣게 되지만 정확히 무슨 개념인지 모른다. 따라서 이번에는 DataMo
51.Step 11. Splunk Indexer Clustering/ Splunk 클러스터링/ Splunk 인덱서 클러스터링 설정하기
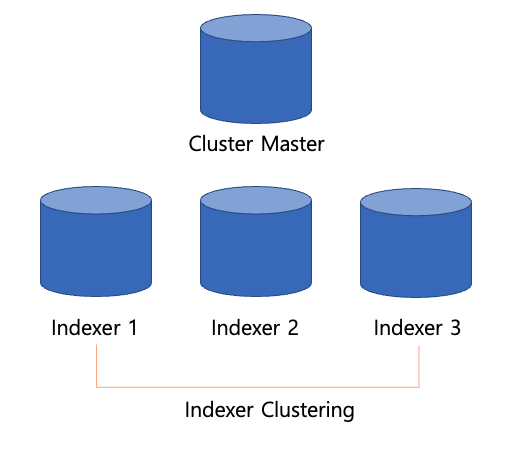
Step10에서 내용이 이어진다. 이전 포스팅을 통해 서버 구성이 덜 되었다면 이전 포스팅을 참고하여, Search Head Clustering 및 인덱서 서버를 설치한 후 진행하는 것이 좋다. 이전 포스팅을 통해 Splunk의 Indexer Clustering의 개념
52.Step 12. Splunk Indexer Clustering과 Search Head Clustering을 연결하기
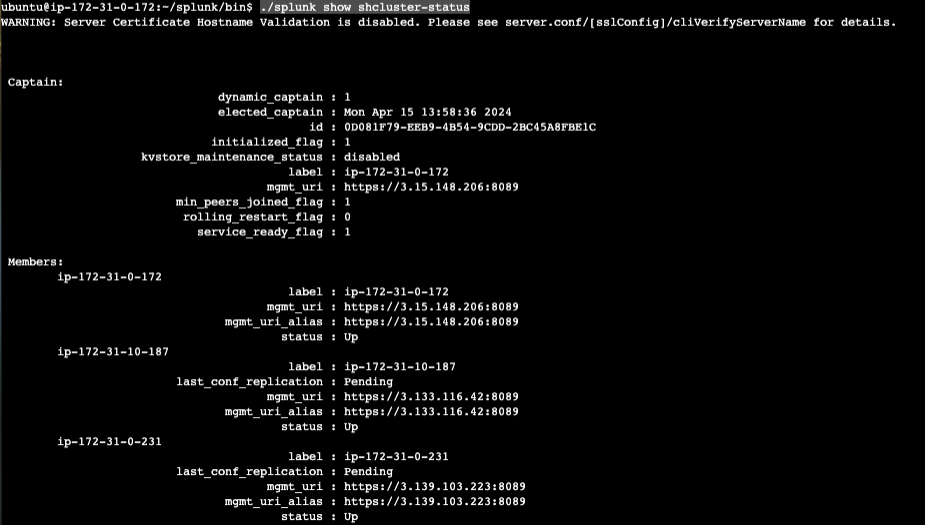
Step 11 에서 이어지는 내용이다. 이번에는 인덱서 클러스터링 그룹에 서치헤더 클러스터링 그룹을 연결할 것 이다. 작업은 굉장히 간단하지만, 기존에 Step 10에서 완성한 인덱서 클러스터링과 Step 5에서 완성한 서치헤더 클러스터링 그룹이 완전히 존재한다는 가정
53.Splunk DataModel 생성해보기
오늘은 이전 개념에 이어 DataModel 생성하는 방법에 대해 알아보겠다. DataModel 생성 데이터 모델은 기본적으로 계층적인 구조이다. 이번에 새로운 케이스로 생성할 데이터 모델의 계층 구조는 다음과 같다. 아래의 구조를 데이터 모델로 정의하는 작업을 진행할
54.Splunk DataModel 가속화 상세 설정, Summary Index와의 차이점에 대해

이전까지 Splunk DataModel에 관한 개념, 생성법에 대해 알아봤다. 이번에는 가속화의 상세 설정, Summary Index 와의 차이점에 대해 알아보려고 한다. 1. DataModel 가속화의 설정에 대해 1) 가속화란? 데이터 모델 가속화는 나의 블로그
55.Splunk Search Query 속도 올리는 법 / Query가 느려요 / TERM() 사용하기 / 고속모드 / 작업검사기 등

오늘은 Splunk에서 쿼리의 속도를 올리는 법을 알아보고자 한다. 사용하다 보면, 가끔 같은 쿼리가 갑자기 느려질때가 있다. 혹은 사용하려던 쿼리의 데이터가 너무 많아서 처리가 불가능한 경우가 있다. 모든 경우를 커버할 수는 없지만 대부분 아래의 방법으로 해결이 되었
56.Splunk dashboard 시간 토큰 설정하기/ 시간 토큰 다른 패널에 전달하기 / Splunk 시간 변수 전달하기
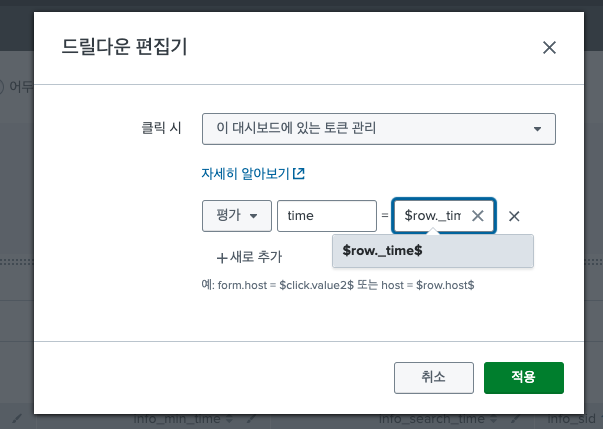
대시보드를 구성하다 보면,, 시간 토큰값을 내려받아 하위 패널의 검색에 사용할 경우가 많은데 그럴때마다 찾아보게 된다. 따라서 한번에 정리해두려고 한다. 1. 상위 패널에서 설정한 시간 값 내려받기 1) 토큰 eval식 활용하기 2) subsearch 활용하기 2.
57.Splunk Index에 대한 정보 알기 / dbinspect / metadata / eventcount / 인덱스에 로그 개수 확인 / 인덱스 사이즈 확인
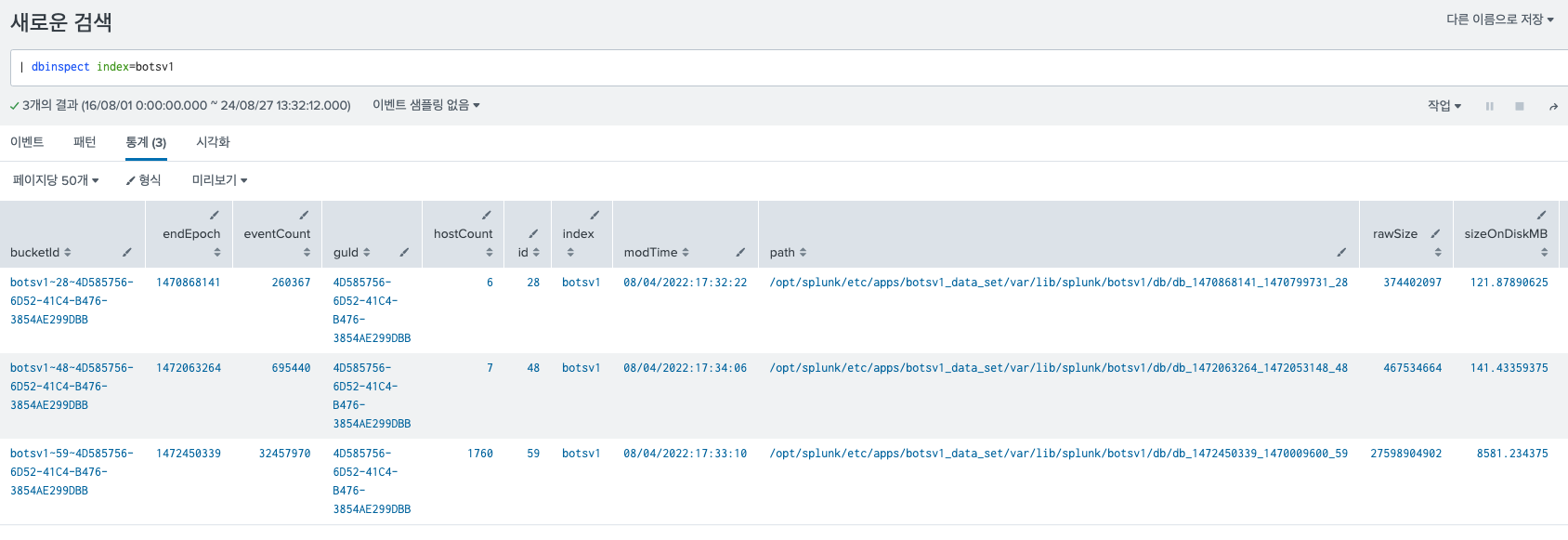
Splunk를 사용하다 보면 위의 정보를 확인해야 할 때가 있다. 그런데 막상 정보를 어디서 확인해야 할지 모르겠다. CM이니 LM이니 접속을 했는데, 내가 생각하는 데이터가 안나온다. 그럴때 알아두면 유용한 명령어 이다. 그냥 search head에서 검색을 해도 결
58.Splunk DLTK 셋업 하기/ DSDL / DeepLearningToolkit 설정 / Splunk AI
Splunk에서 모델 생성, 배포 등의 프로세스를 진행하기 위해 DLTK 를 세팅해줬다. MLTK도 충분히 좋지만, 코드로 내가 원하는 모델을 배포하기 위해서는 결국 DLTK 세팅이 필요하다. 로컬 환경, 단일 호스트에서 진행하였다. DLTK 앱을 설치하기 위해서는 M
59.Splunk BOTS 2025 후기
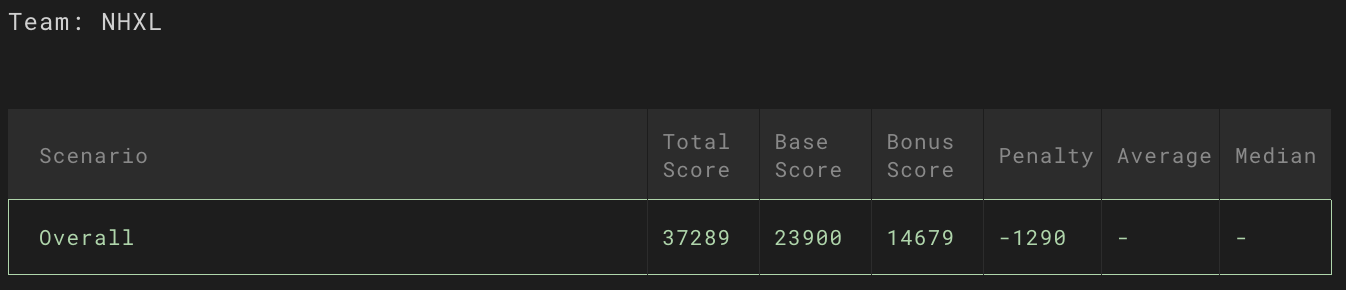
splunk bots 에 나갔다. 일단 이번에 토스 가디언즈랑 FISCON 행사 때문인지 사람이 별로없었다.행사를 시작하면서 열심히 문제를 풀었다. 분명 초반에는 상위권을 달리고 있었는데 ㅎㅎㅎㅎㅎㅎ마지막에... 뇌 정지 이슈가 오면서 결국 6등으로 마무리 했다.분명.