1. Search Head Clustering 이란?
검색 헤드 클러스터는 검색을 위한 중앙 리소스 역할을 하는 검색 헤드 그룹이다. 클러스터 내에서는 동일한 검색을 실행하고, 동일한 대시보드를 보고, 클러스터의 모든 멤버에서 동일한 검색 결과에 접근할 수 있다.
1) Search Head Clustering의 이점
-
수평 확장이 가능하다: 사용자 수와 검색 로드가 증가하면 클러스터에 새 검색 헤드를 추가할 수 있다. 또한, 검색 헤드 클러스터를 사용자와 클러스터 사이에 로드 밸런서를 결합하면 사용자와 검색서버 간 네트워크 구성이 깔끔해진다.
-
고가용성: 검색 헤드가 작동 중지되면 동일한 검색 세트를 실행하고 클러스터의 다른 검색 헤드에서 동일한 검색 결과에 접근할 수 있다.
-
No single point of failure: 검색 헤드 클러스터는 동적 캡틴을 사용하여 클러스터를 관리합니다. 캡틴이 작동 중지되면 다른 구성원이 자동으로 캡틴으로 선정된다. 따라서 하나의 포인트로 인해 실패가 발생하지 않는다.
2. Search Head Clustring 아키텍처
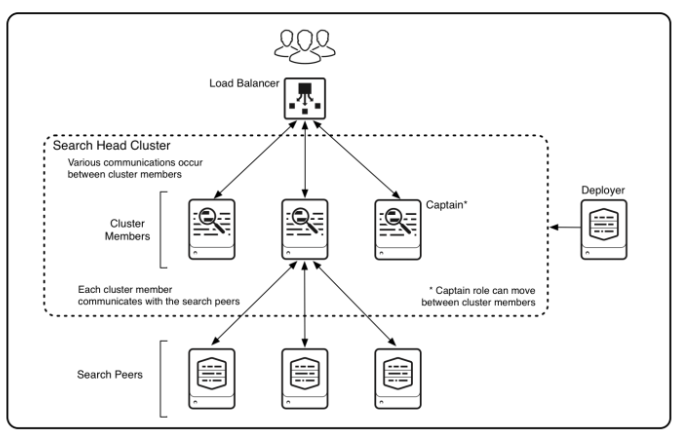
검색 헤드 클러스터링의 아키텍처내에는 총 2가지 역할의 구성원이 존재하는데 하나는 구성원, 다른 하나는 Captain이다.
1) 클러스터 내의 구성원
- 구성원: 검색 혹은 예약된 검색 수행 및 완료된 검색의 메타 데이터를 공유하는 그룹 내의 구성원
- 캡틴: 모든 구성원 간의 검색 작업 예약 및 복제 활동을 조정한다. (쉽게 반장의 느낌이다.)
캡틴의 역할
- 경고 및 경고 조정: 캡틴은 모든 경고를 추적한다.
- 작업 예약: 자신을 포함한 전체 구성원의 부하를 고려하여 작업을 할당해준다. 즉, 사용자가 검색을 수행하면 캡틴이 구성원 중 검색을 수행할 수 있는 구성원을 찾아 수행하게끔 한다.
- 지식 개체들의 번들 파일을 검색 피어(인덱서)들에게 배포한다.
- 완료된 검색의 메타데이터 복제를 조정한다.
- 지식 개체들의 변경사항을 다른 SH구성원에게 복제한다.
지식 개체: 저장된 검색 , 이벤트 유형 , 태그 , 필드 추출 , 조회 , 보고서 , 경고 , 데이터 모델 , 워크플로 작업 및 필드 등
캡틴 선출
보통 SH클러스터링은 동적 캡틴을 사용한다. 이것은 캡틴 역할을 하는 구성원이 변경될 수 있기 때문이다. 블로그의 Step5을 보면 최초에 클러스터링 설정 시 캡틴이 정해지는데 이후 아래와 같은 상황이 나타날 경우 캡틴 선출이 일어난다.
- 현재 캡틴이 Down 되거나 다시 시작된다.
- 네트워크 문제로, 하나 이상의 구성원이 제외된다. 이후 네트워크 파티션이 치유되면 별도의 캡틴 선출이 시작된다. **
- 다수의 구성원이 클러스터에 참여하고 있음을 감지하지 못하면 다시 캡틴 선출이 된다.
** 단, 네트워크 분할이 없는 비캡틴 구성원의 단순한 재시작은 캡틴 선출을 발생하지 않는다.
과반수의 원칙: 예를 들어 6명의 구성원으로 된 클러스터에서는 4개 이상의 표가 필요하다. 7의 절반인 3.5개 초과임으로 4개 이상의 표가 필요하다.
6개의 구성원이라면 6의 절반인 3개 초과가 되어야한다. 여기서 과반수는 절반을 초과하며, 최초에 정의된 모든 구성원의 수를 기준으로 정해진다.
즉 4개의 구성원중 1개가 다운 되어도, 과반수는 3대로 동일하다.
2) 클러스터 외 구성원
- Deployer: 클러스터 구성원에게 앱 및 기타 구성을 배포한다. 이는 클러스터 외부에 있어야 한다. SH 클러스터는 지식 개체와 일부 구성은 자동으로 복제되지만 앱과 기타 구성은 복제되지 않기 때문에 Deployer를 사용한다.
- Search Peer(Indexer): 검색을 실행하는 인덱서이다. 독립적 인덱서이거나 인덱서 클러스터중 하나의 노드일 수 있다.
- Load Balancer: 검색 서버가 여러대인 경우 로드밸런서를 사용해 하나의 VIP로 묶거나 도메인을 설정해 여러대의 서버를 분산하여 접근할 수 있게 한다.
3. Search Head Cluster가 무시하는 정보
- 시스템 구성파일의 변경사항: 대부분 무시된다. 또한, 이러한 시스템 구성파일은 대부분 사용자가 직접 변경하는 케이스인데 이렇게 직접 변경한 정보는 복제되지 않는다. Web, CLI, REST API를 통해 변경된 사항만 변경된다. 구성 파일을 변경하고 싶다면 배포자를 통해 배포 해야한다.
- 새로 설치되거나 업그레이드 된 앱: 배포자를 통해 배포해야 한다.
4. Search Head Cluster가 복제하는 정보
1) Splunk Search Head Cluster가 복제하는 변경사항
$SPLUNK_HOME/etc/system/default
$SPLUNK_HOME/etc/system/default 에서 conf_replication_include에 있는 내용이 복제된다. 즉, SavedSearch, Lookup 등과같은 지식 개체에 대한 변경 또는 추가가 복제된다. 이러한 목록들이 conf_replication_include에 나와있다.
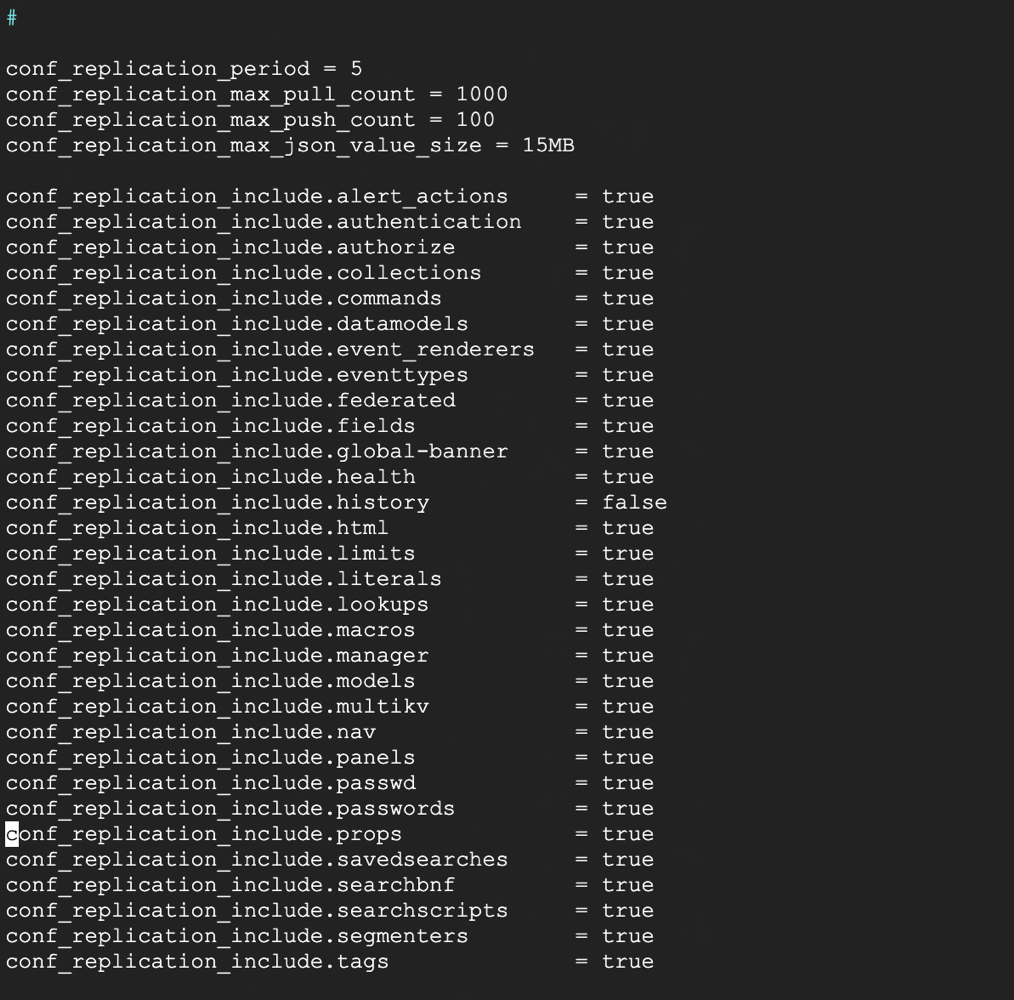
사용자정보, 역할
2) Splunk Search Head Cluster가 복제를 트리거 하는 방법
- Splunk Web
- Splunk CLI
- REST API
위의 3가지 방법을 통해 변경된 사항은 자동으로 복제한다. 하지만, 사용자가 직접 savedsearch.conf파일을 변경하는 경우 복제되지 않는다. 이러한 케이스는 Deployer를 사용해야 한다.
3) Splunk Search Head Cluster 복제 작동 방식
- 사용자가 SH의 구성을 변경
- 해당 멤버는 변경사항을 로컬에 저장 및 캡틴에게 전송
- 5초마다 다른 구성원이 캡틴에게 연락하여 변경사항을 가져옴
- 다른 멤버가 로컬에 변경 사항을 저장한다.
4) Splunk Search Head Cluster 복제가 발생하는 경우
- 활성화된 클러스터 멤버는 5초마다 자동으로 변경사항을 가져온다.
- 새 멤버가 합류하면 캡틴에게 연락하여 기존에 이뤄진 모든 변경사항을 포함한 구성 정보가 새로운 멤버에게 tar로 다운로드 된다.
- 구성원이 제거되었다가 다시 추가하는 경우에도 동일하게 캡틴에게 연락하여 변경사항이 tar로 다운로드 된다.
- 클러스터가 복구하는 경우
5. Splunk Search Head Cluster 복제 동기화 문제
1) 연결이 끊겼던 멤버가 다시 복구되었을 경우, 다시 복구하는 방법
- 캡틴과 멤버가 공통 커밋을 공유하는 경우: 중간 변경 사항을 자동으로 다운로드하여 사전 오프라인 구성에 적용
- 캡틴과 멤버가 공통 커밋을 공유하지 않는 경우: 수동 개입 없이는 제대로 동기화할 수 없다. 구성원의 구성을 업데이트하려면 수동 재동기화 수행에 설명된 대로 구성원에게 캡틴으로부터 전체 구성 tar를 다운로드하도록 해야한다. tarball은 멤버의 기존 구성 세트를 덮어쓰므로 클러스터에서 연결이 끊어진 동안 발생한 로컬 변경 사항이 손실 될 수 있다.
위의 수동으로 복구하는 방법에 대해서는 이 문서를 참고하길 바란다.
6. 클러스터링 관련 커맨드
./splunk show shcluster-status끝으로 SH클러스터링에 대해서 알아보았다. 끝이다.
