오늘은 fillnull, filldown에 대해 알아보려고 한다. fillnull은 자주쓴다.
왜냐면 stats와 같은 변환 명령을 사용할 때 split-value값에 null값이 포함된 경우에는 자동으로 집계에서 빠지게 된다. 이런 데이터도 추가해주기 위해서 fillnull 구문을 이용해 null인 필드를 채워준다.(기능상 이유)
아니면 단순히, table로 이용해 확인할 때 null이 되어있는 필드를 채워주기 위해 사용하기도 한다.(미관상의 이유)
이름 그대로 직관적이고, 많이 사용하고, 너무 쉬운 명령어이다. 그래서 여러 활용예를 들어서 포스팅을 하려고 한다.
추가로 filldown은 자주 쓰이지는 않는다. 근데 확인해보니 꽤나 유용한 명령어이다.
1. fillnull
이름 그대로 직관적인 명령어이다. 말 그대로 null인 값을 채워준다는 의미이다. 디폴트 값은 0으로 채워지며, 특정 필드를 지정해서 채우면 해당 필드가 지정된 값으로 채워진다.
1) 사용 예시
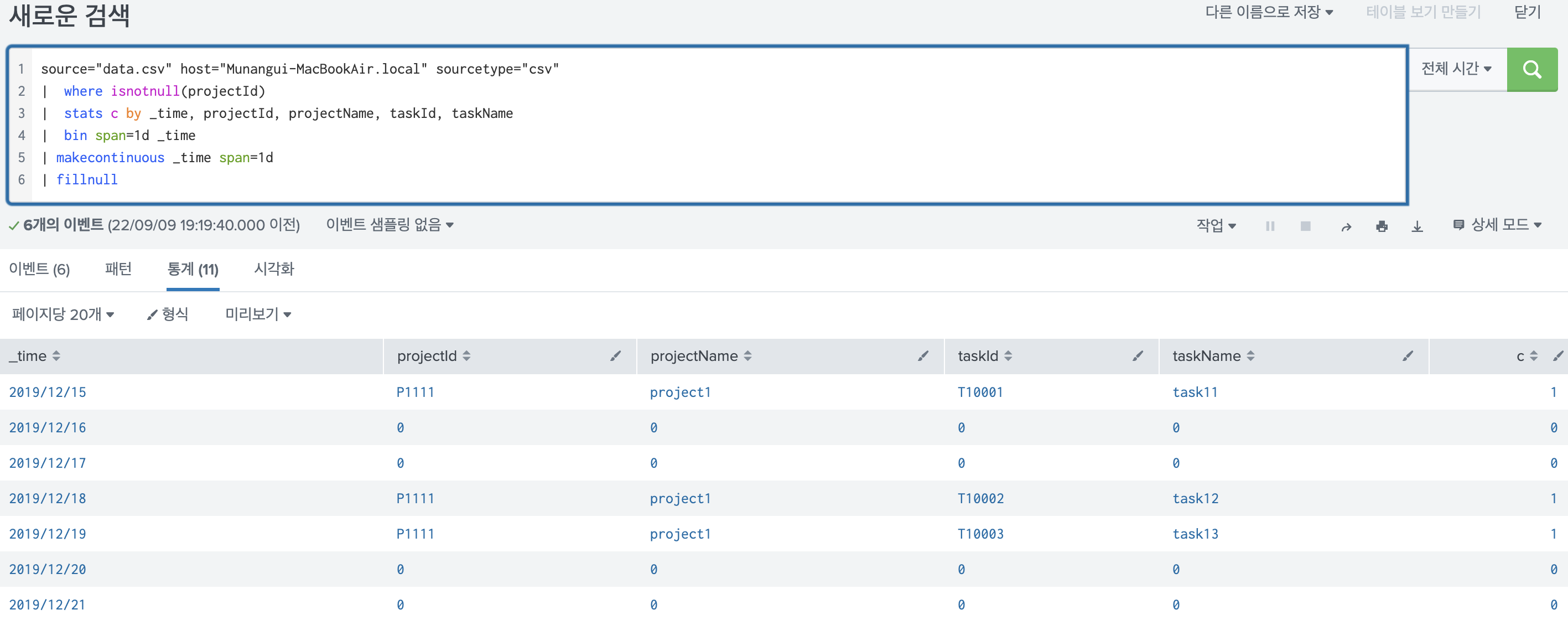
- 참고사항
- makecontinuous 명령어는 말 그대로 time 필드의 순서가 15, 18, 19 순이라면 중간에 빠진 16, 17일을 넣어 continuous 하게 해주는 명령어이다. 단순히 날짜를 채워서 연속적인 형태로 보여주는 역할을 한다. 그렇기 떄문에 나머지 필드는 모두 null인 상태였다.
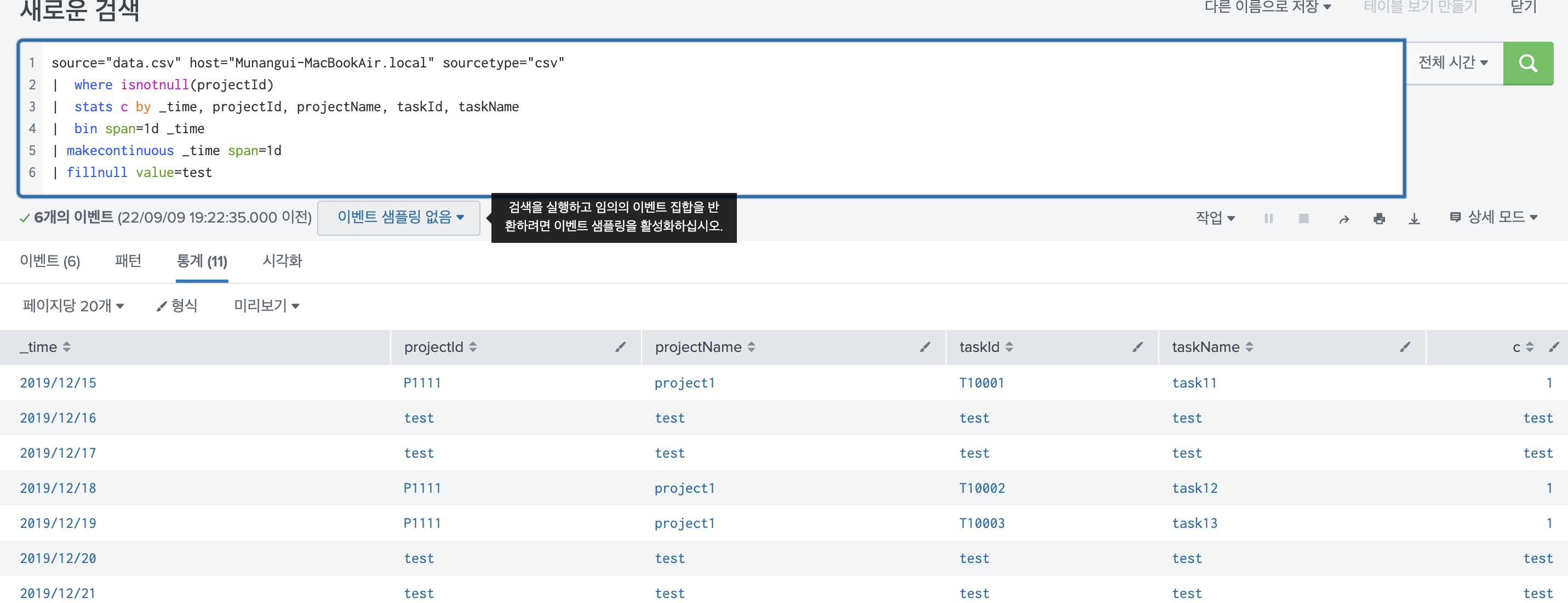
2) 특정 필드가 NULL일때는 A를, 다른 필드가 NULL이면 B를 넣고 싶다면?
여러 필드를 선택적 값으로 fillnull 하고싶다면, 다음과 같이 fillnull 명령어를 여러번 사용해주면 된다. 하지만 미관상 별로여서 b안을 더 사용하게 된다.
a) fillnull 여러번 쓰기
source="data.csv" host="Munangui-MacBookAir.local" sourcetype="csv"
| where isnotnull(projectId)
| stats c by _time, projectId, projectName, taskId, taskName
| bin span=1d _time
| makecontinuous _time span=1d
| fillnull taskId value=test
| fillnull taskName value=test2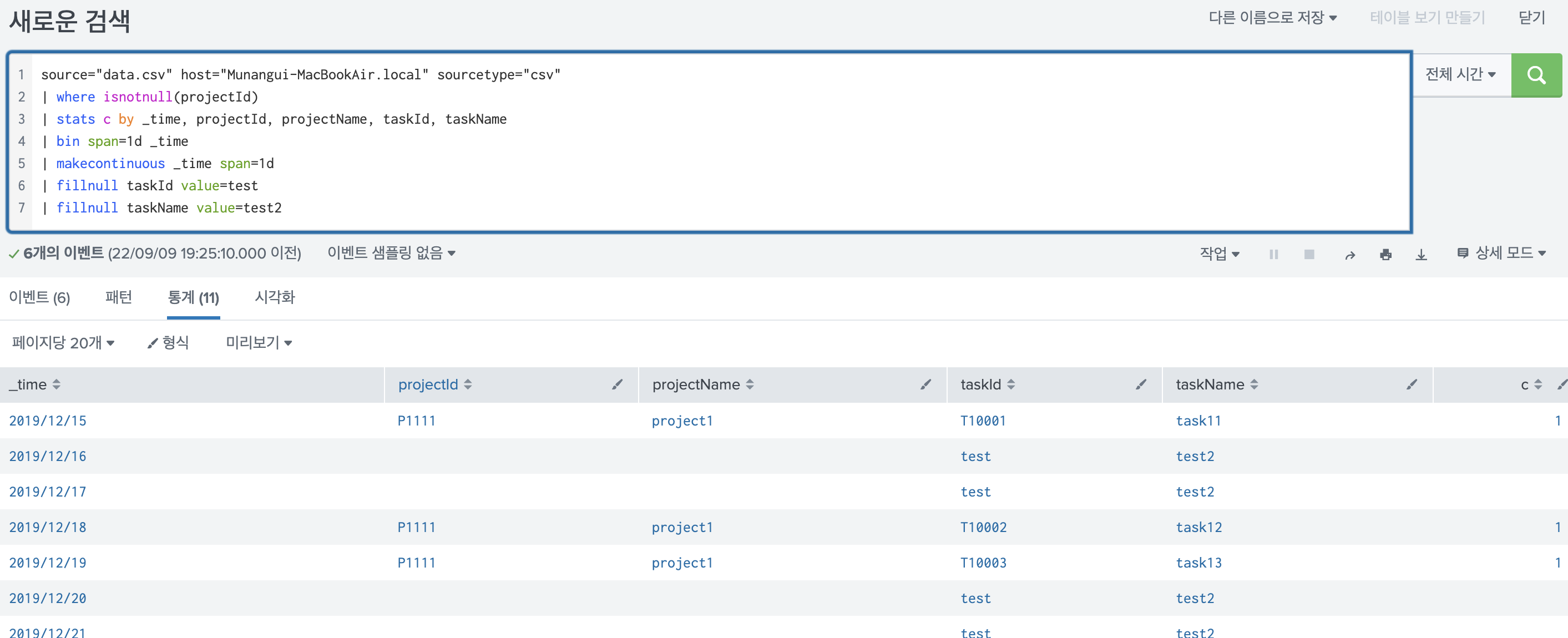
b) eval-coalesce 사용하기
coalesce는 합치다 라는 의미를 가지고 있다. coalesce의 인수로 들어온 필드가 null값을 가지게 되면, 지정해준 값으로 합쳐준다.
source="data.csv" host="Munangui-MacBookAir.local" sourcetype="csv"
| where isnotnull(projectId)
| stats c by _time, projectId, projectName, taskId, taskName
| bin span=1d _time
| makecontinuous _time span=1d
| eval taskId=coalesce(taskId,"test1"), taskName=coalesce(taskName,"test2")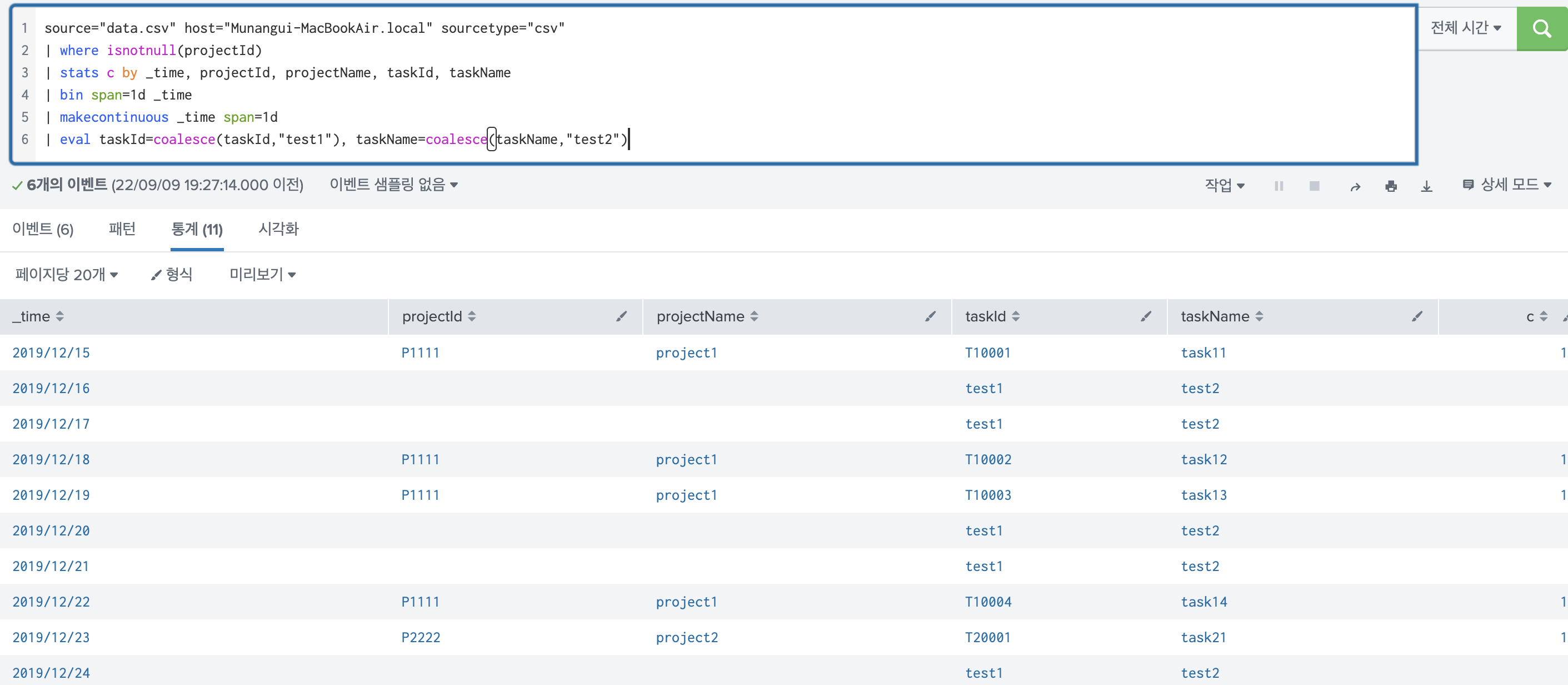
3) 조건을 지정해서 ~할 경우, fillnull하고 싶다면
eval을 사용하면 된다. c값이 null인 경우에만 taskId를 채워주도록 했다.
source="data.csv" host="Munangui-MacBookAir.local" sourcetype="csv"
| where isnotnull(projectId)
| stats c by _time, projectId, projectName, taskId, taskName
| bin span=1d _time
| makecontinuous _time span=1d
| eval taskId=if(isnull(c),"conditional fillnull",taskId)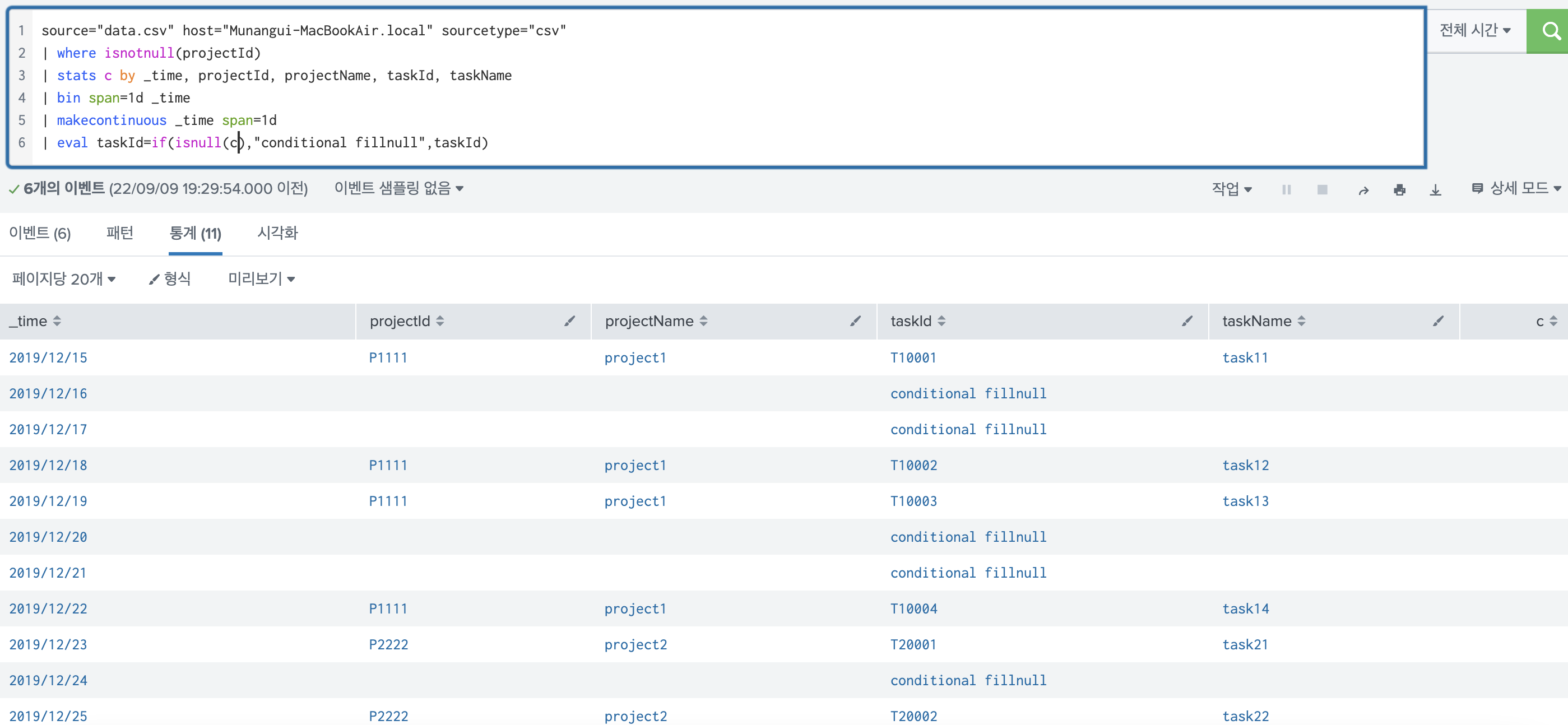
2. filldown
이것도 채우는 명령어 이지만... 이것은... 내려서 채운다.
예시를 들어보면 이렇게 보인다. 결과부터 보면 바로 이해될 것 이다.
1) 사용예시
filldown 하기 이전의 데이터는 다음과 같다.
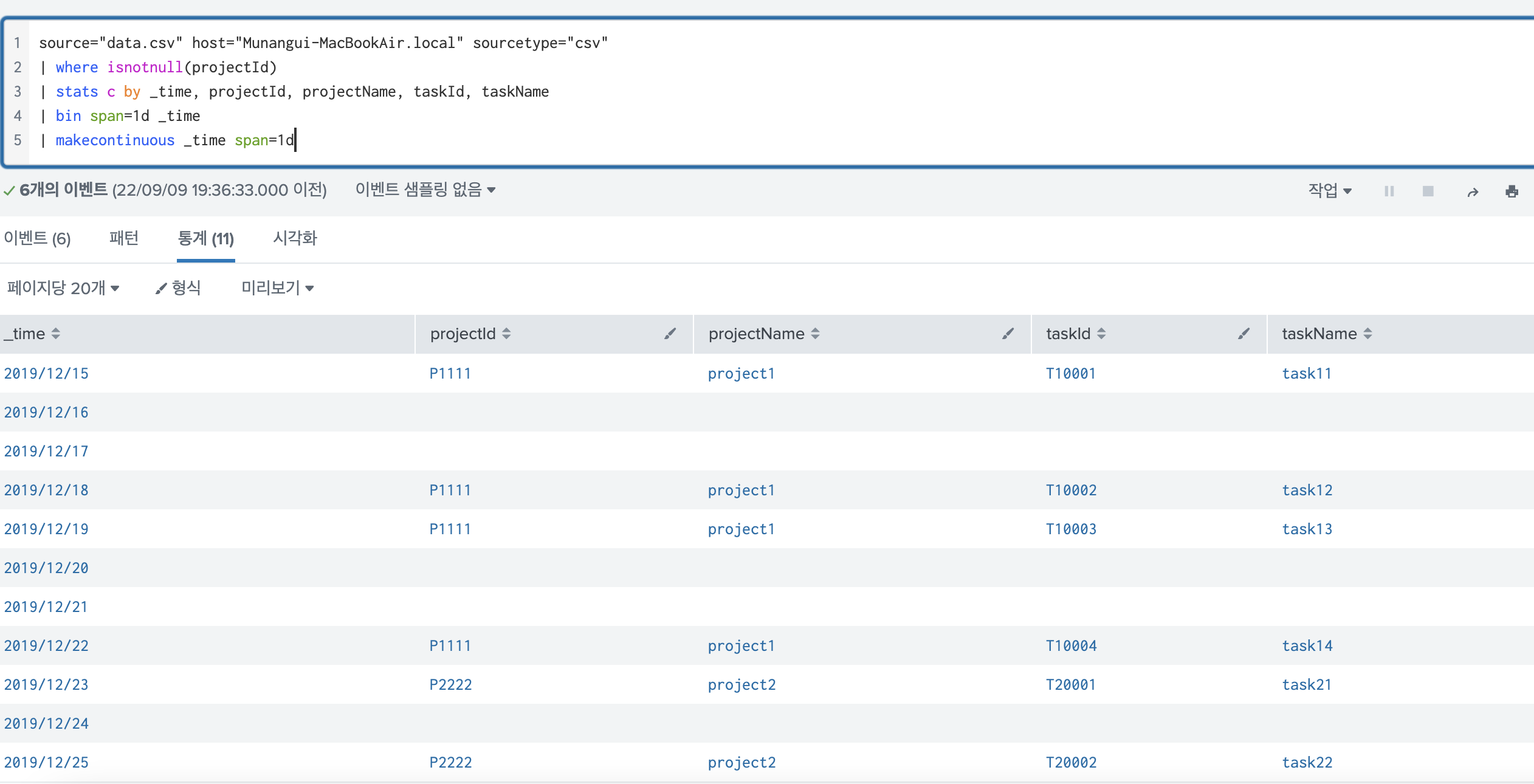
filldown 해보면 다음처럼 된다.
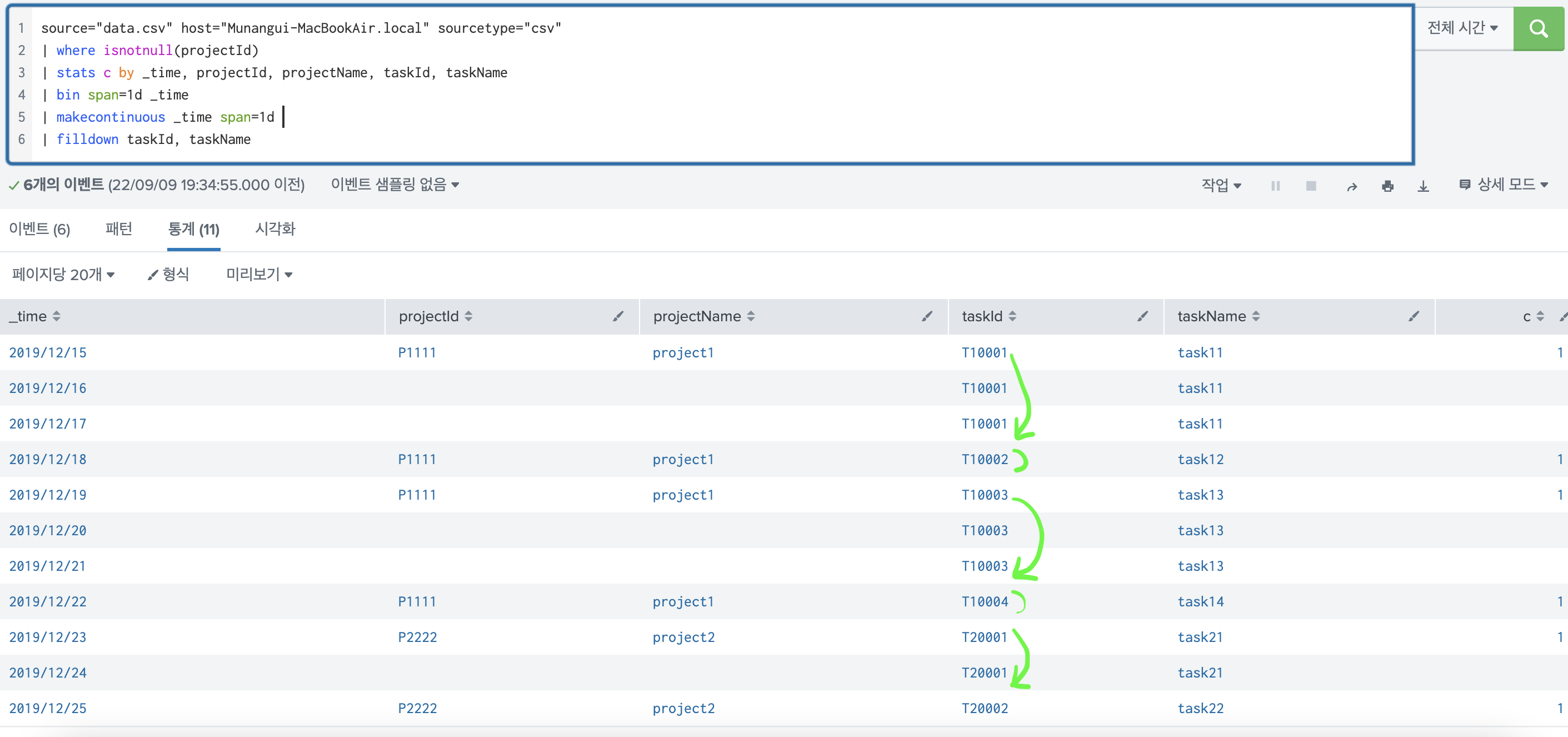
이렇게 지정해준 필드에서 Null인 값을 최초에 만난 값으로 계속 채워준다. 이후 NULL이 아닌 값을 만나게 되면 그 다음부터는 해당 값으로 채워준다.
2) fillnull 과 활용해서 사용
source="data.csv" host="Munangui-MacBookAir.local" sourcetype="csv"
| where isnotnull(projectId)
| stats c by _time, projectId, projectName, taskId, taskName
| bin span=1d _time
| makecontinuous _time span=1d
| fillnull projectId, projectName, c value="test"
| filldown taskId, taskName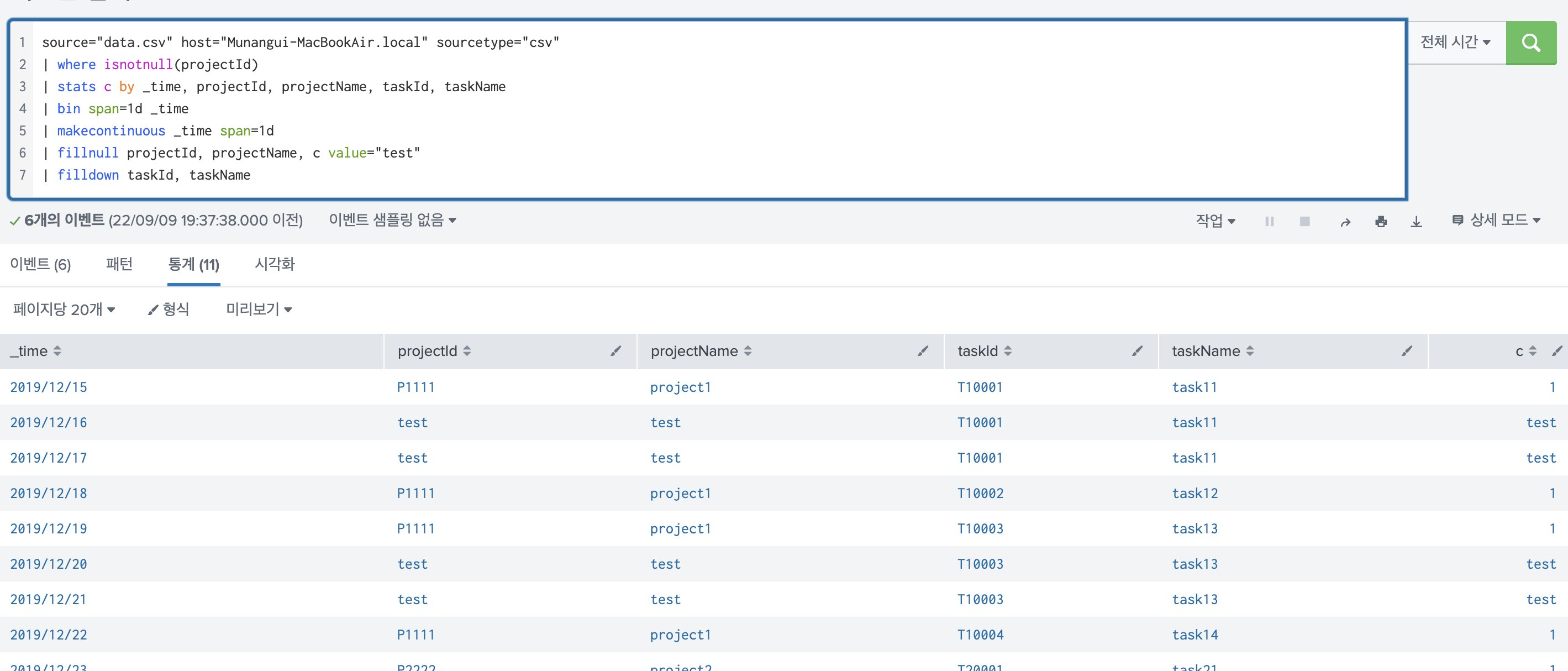
3. fillnull의 command 타입
2가지 처리방식을 가지는 fillnull
당연히 streaming command 일 줄 알았으나, 한가지 놀라운 점을 알아냈다. 바로 filed list가 지정되어있지 않으면 dataset processing 으로 처리된다는 점이다. (아닐 경우에는 distributed streaming command로 실행된다.)
왜지? 왜지? 왜 이렇게 나뉘어서 실행되는지 이해가 안돼서 스플렁크 커뮤니티에 질문글을 올렸다...
답변은 다음과 같았다.
필드 이름이 지정되면 인덱서는 필드에 값이 없음을 확인하고 채우기 값을 대체하기 쉽습니다. 필드 이름을 지정하지 않으면 null 값이 있는 필드를 알기 위해 전체 필드 집합을 알아야 합니다. 배포할 수 있는 기능이 아닙니다.
그렇다.. 나는 처음에 null인 데이터가 있으면 모조리 그냥 0으로 SH에서 넣어버리면 된다고 생각했는데, 어떤 필드에서 null이 있는지 알려면 결국 전체 데이터를 모두 확인해야 되기 때문이었다...
필드 명이 지정되면, 해당 필드만 확인하면 되기 때문에 그만큼 부담이 적을 것이다... 답변을 들으니 더욱 명확해지는 듯 하다..

무냉공듀 사진 바꾸셨네요