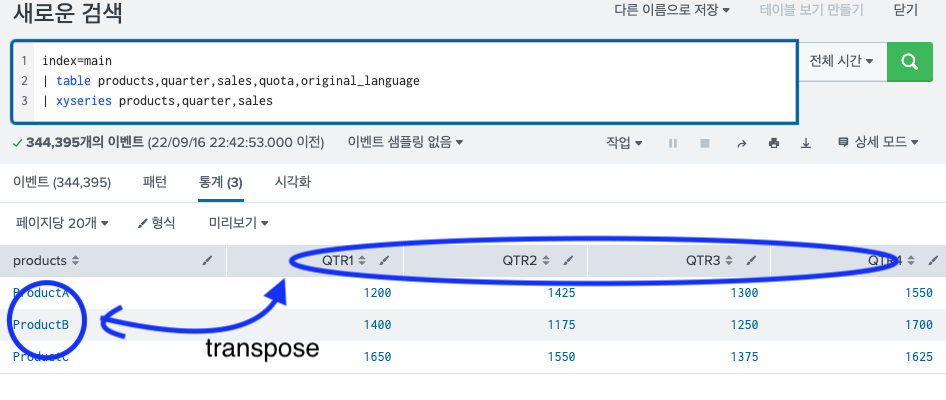
splunk 에서 자주 쓰이는 transpose와 xyseries명령어에 관하여 포스팅을 한다.
엄청 자주 쓰이는건 아니지만, 가끔 필요할 때가 있고 또 필요할때 보면 은근 헛갈리는 2가지 명령어이다. 비슷한 것 같지만 전혀 다른 명령어이다. 이번에 확실히 정리해두고 넘어가려고 한다.
이번에도 유튜브 영상 과 splunk 공식 문서를 참고했다.
1. xyseries
1) 사용법
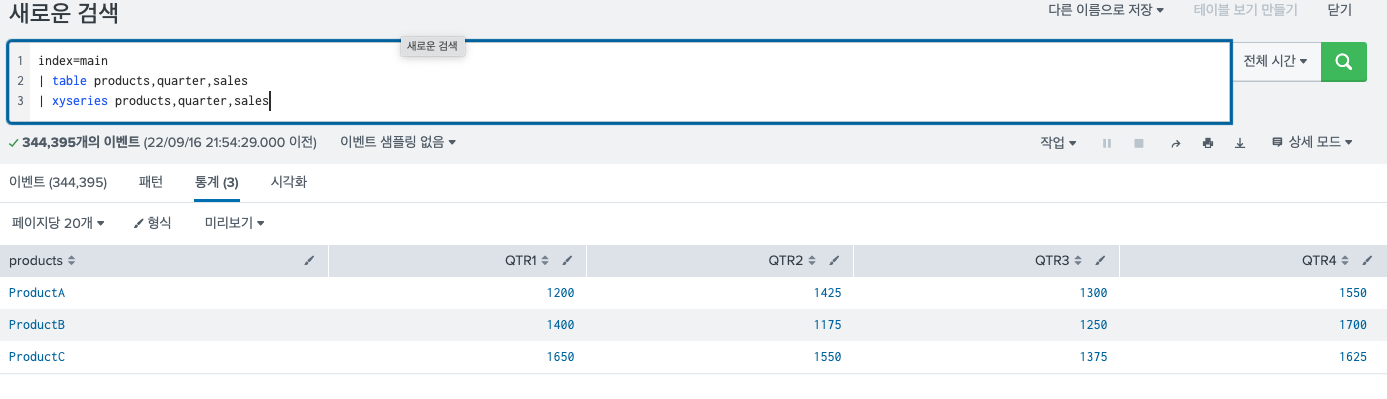
쉽게 말하면 xysereis는 splunk를 search한 결과로 표를 만들어준다. 우리가 생각하는 표의 형식은 보통 이러하다.(1)

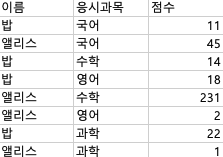
그런데 Splunk의 검색결과는 이렇게 생겼다.(2)
그래서 xyseries는 (2)처럼 보이는 검색 결과를 (1)으로 보여주는 명령어이다.
명령어는 어떻게 쓰냐? 총 3가지의 인수가 있다.
| table 이름, 응시과목, 점수 -> 여기까지 하면 (2)의 결과가 나올 것 이다.
| xyseries "이름", "응시과목", "점수" -> 이렇게 하면 (1)의 결과가 나온다.| xyseries "표의 맨 왼쪽에 위치할 컬럼 명a", "표의 최상단에 위치할 컬럼 명b", "a와 b로 x,y 축을 이루는 표를 만들었을 때 가운데 위치할 데이터 값들"
실제로 검색했을 때는 다음과 같다.
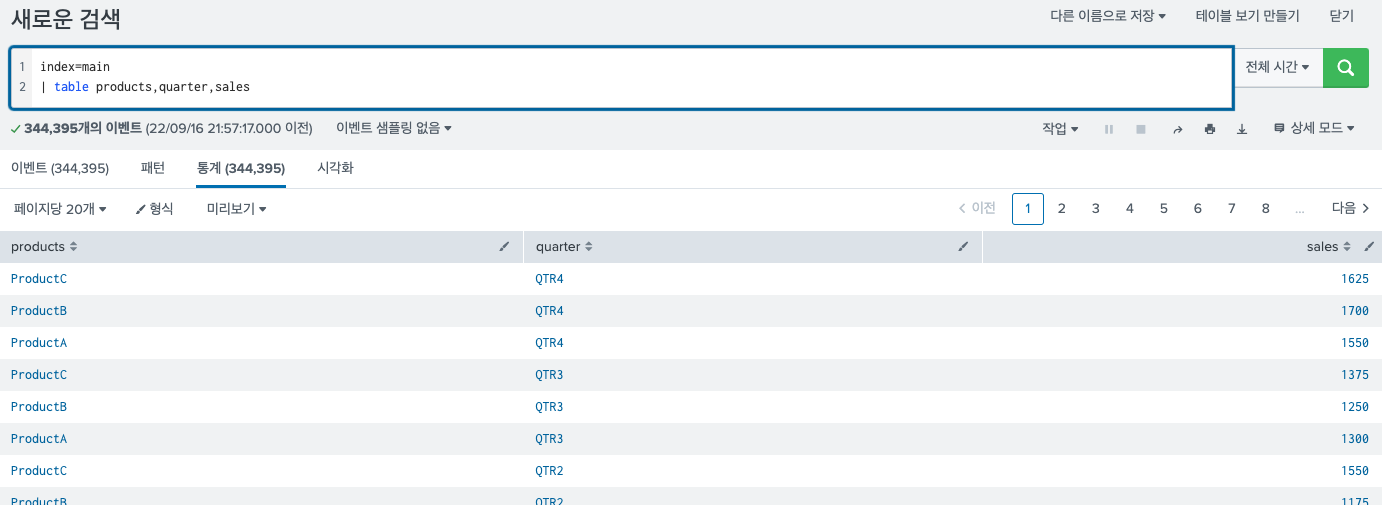
이러한 데이터를 xyseries를 사용하면 이렇게 된다.
2) 옵션 조건
옵션 조건은 sep, format 2가지가 있다. 이 2가지 조건을 사용하기 위해서는 집계에 대한 split-by-field 명령을 포함하는 검색을 작성해야 한다고 한다. 근데 실제로 필자가 샘플 데이터로 실습했을 때에는 split-by-field로 인해 집계된 데이터가 아니라, Number타입 이면 가능한 것 같다.
- 3번째 인수에는 여러가지 값이 들어갈 수 있다.
3번째 인수에는 1개의 인수만 넣는게 아니라 중복해서 여러개의 인수를 넣을 수 있다.
바로 예시로 보여주면 다음과 같다.
이렇게 되어있는 테이블 마지막 칸에 quota라는 데이터를 추가하게 되면
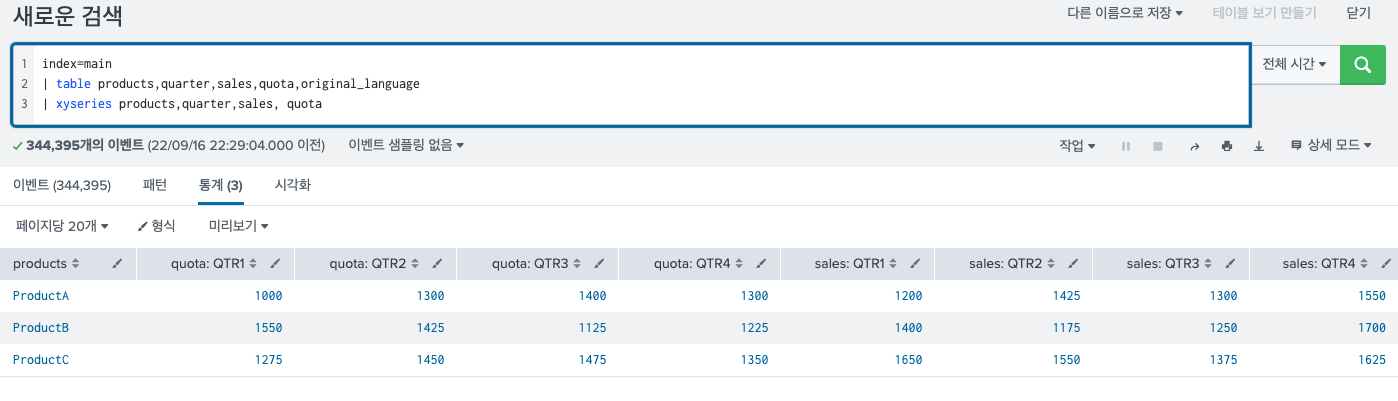
queter 필드에 대한 sales, quota 값들이 구분되어서 컬럼으로 형성되었고, 해당 값이 데이터 필드 안에 채워져 있는 것을 확인할 수 있다.
3개도 될까? 하고 3가지 값을 넣어봤는데 3가지도 가능했다.
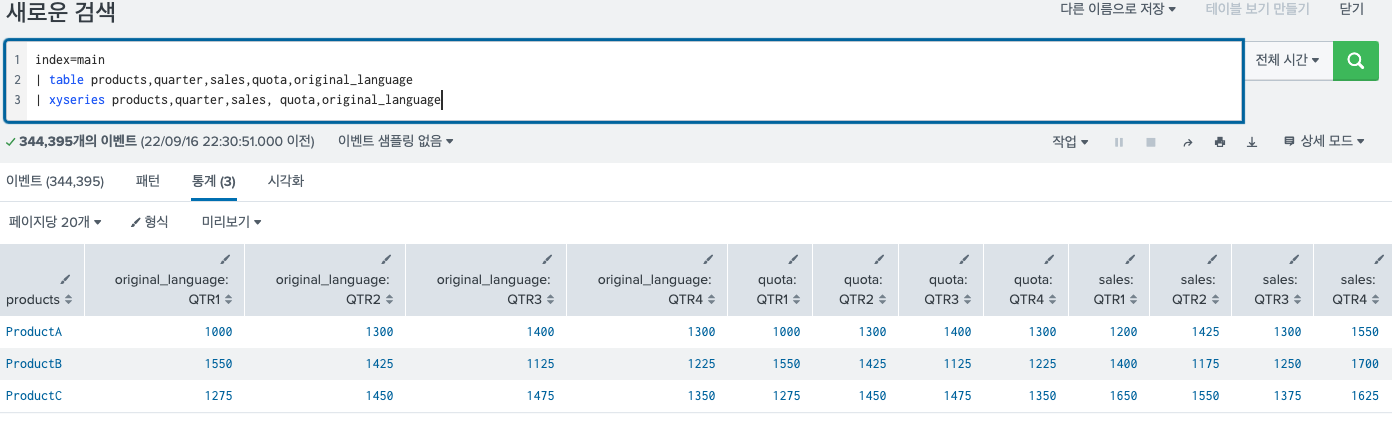
- 3번째 인수와 관련된 것 2가지 옵션
- 첫 번째 옵션은 sep 옵션이다. 위에서 봤을 때 3번째 인수를 여러개 넣게 되면 해당 인수가
:으로 묶여져서 나오게 된다. 이게 디폴트 값이다.
이 디폴트 값을 변경해주는 것 이다.
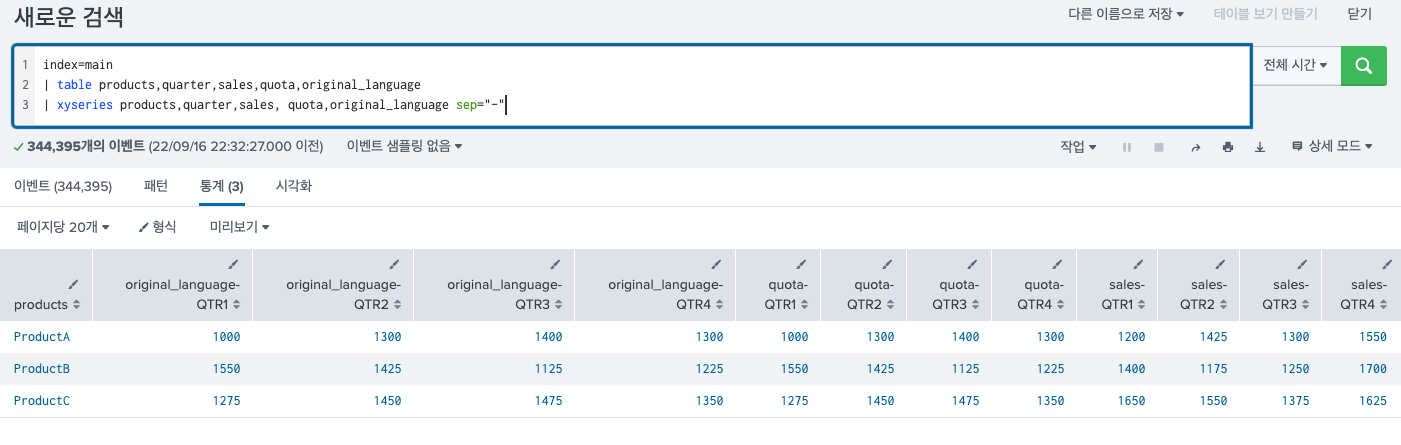
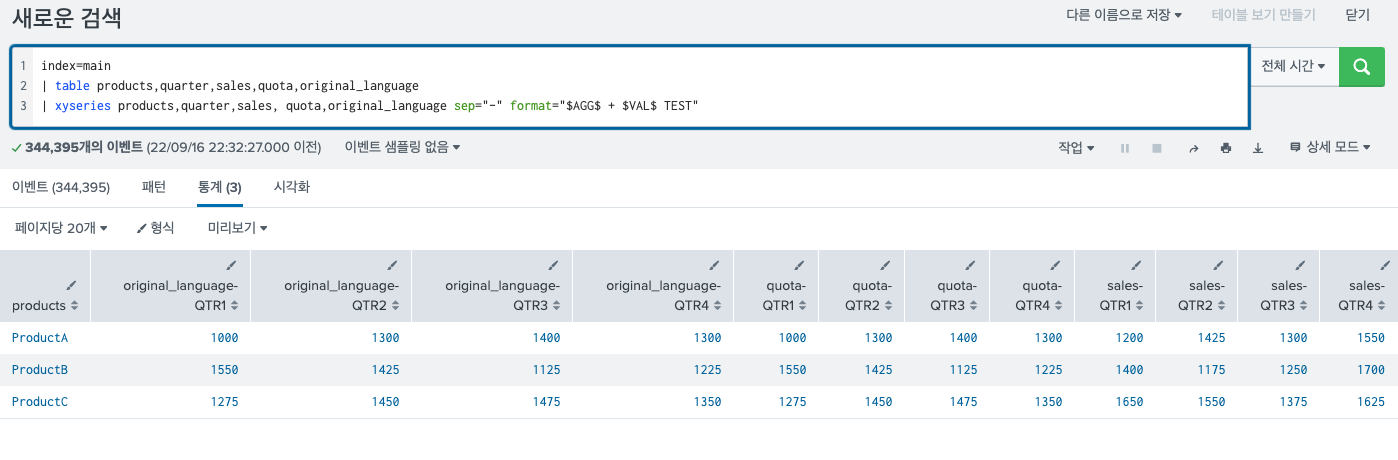
- 두 번째 옵션은 이 값의 형태를 다르게 출력해주는 것 이다.
보면 다음과 같다.
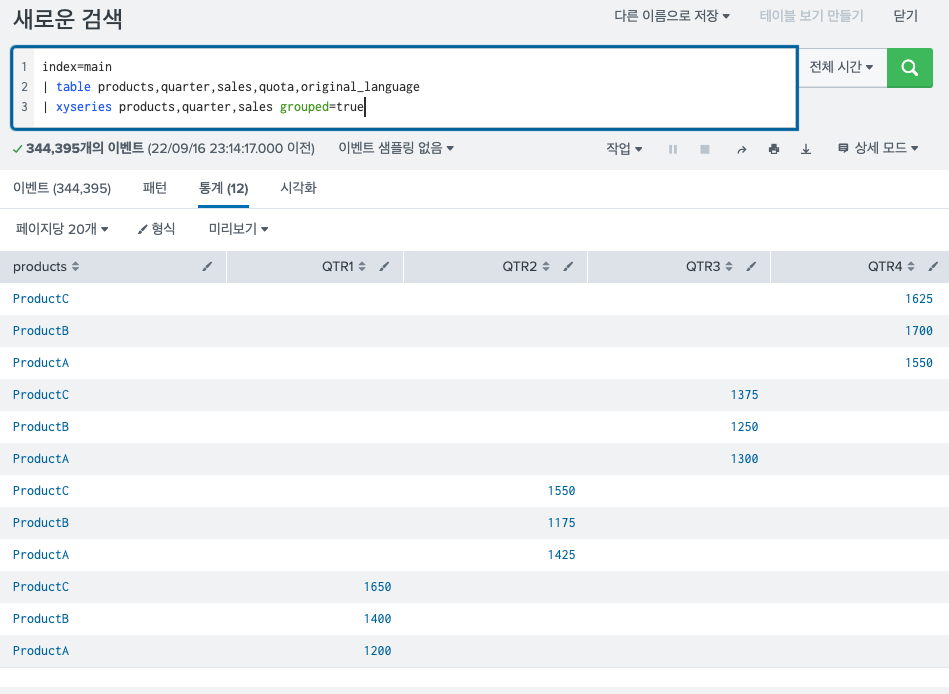
- grouped
그룹화를 하지 않는것이 기본 옵션이고, true로 하게될 경우 다음과 같은 모습이다.
3) distributable streaming 명령어
스트리밍 명령어이기 떄문에 IDX에서 실행이 가능하다. 하지만, grouped=true인 경우, 변환명령어로 작동하게 된다. x필드 기준으로 그룹화를 해야 하기 때문에 stats와 같은 변환명령 처럼 동작하기 때문이다.
4) alias 가능
별칭이 있기 때문에 이 별칭 그대로 사용할 수 있다.
똑같이 나온다.
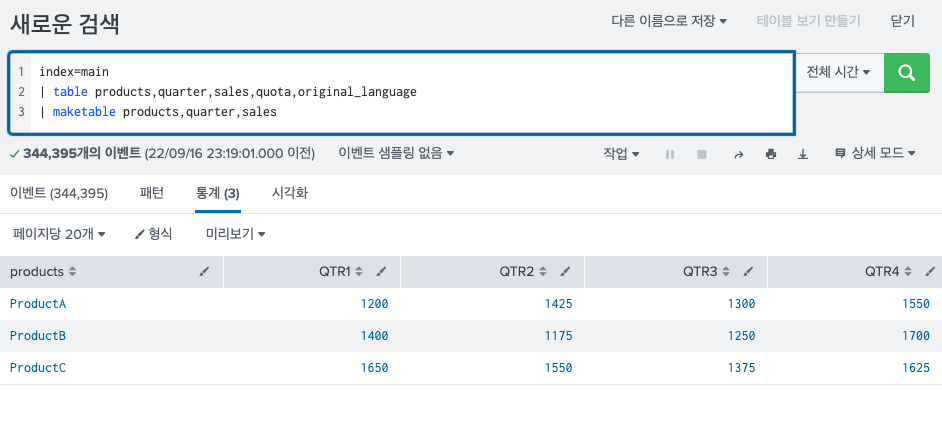
5) 중복된 데이터는 자동으로 제거된다.
기본적으로 중복 값이 포함된 결과가 제거된다.
중복된 값을 포함하고 싶다면, streamstats를 사용하여 레코드 번호를 만들어 유지시킬 수 있다. 하지만 시도해보니 기존에 있던 필드의 형식이 깨지기 때문에 참 난감해진다.
스플렁크 커뮤니티에서 찾아본 결과 이런 형식으로 사용하는 경우가 있었다.
이것을 참조하여 필요한 사람들은 사용하길 바란다.
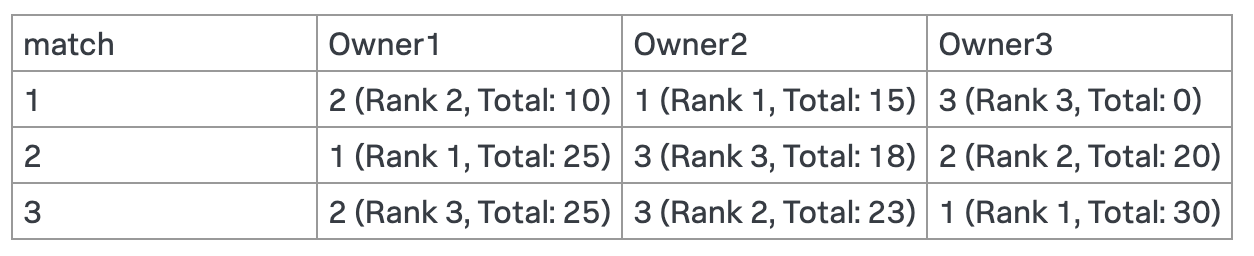
축구경기별 누적 점수를 기준으로 순위를 메기는 쿼리
index=index
| chart sum(TotalPoints) AS Points BY match, "Sold To"
| fillnull value=0
| untable match Owner Points
| sort match
| streamstats sum(Points) AS Total BY Owner
| sort match Total
| streamstats count AS Rank BY match
| xyseries match Owner Rank
2. transpose
1) 사용법
이름 그대로의 기능을 한다. 열과 행을 바꿔주는 기능이다. 보통 transpose 명령어를 사용할 때에는 xyseries를 먼저 적용시킨 후 사용하는게 통상적이다. 왜냐면 말 그대로 x축과 y축을 이루는 컬럼과 행을 바꿔주는 것이기 때문에 기본적으로 표 형식의 데이터를 사용해야 용이하게 다룰 수 있다.
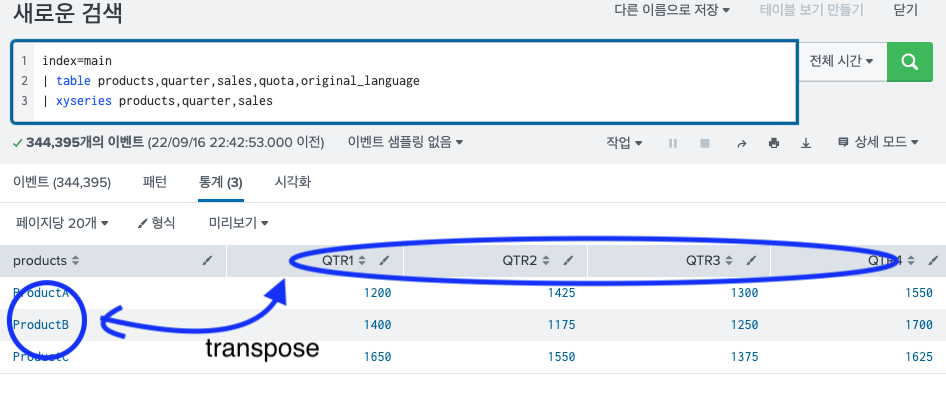
이후 명령어를 적용하면 다음과 같이 변한다.
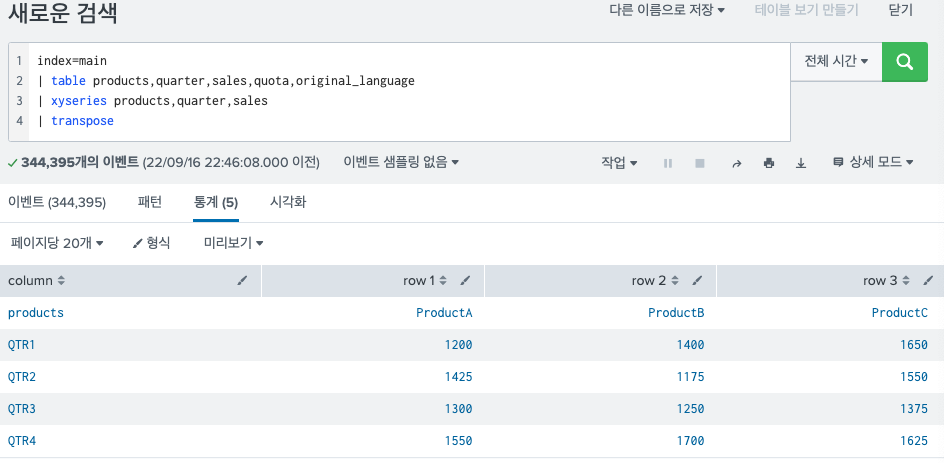
특징이 있다면 새로운 컬럼이 새로 생긴다는 것 이다. 그래서 이 디폴트로 생기는 컬럼명을 변경할 수 있는 옵션에 대한 설명도 2)에 추가했다.
2) 옵션 조건
- header_field
위에 디폴트로 생기는 컬럼 명을 따로 지정해줄 수 있다. 최상단에 있는 컬럼들을 테이블의 헤더라고 Splunk에서는 부르는데 이 헤더의 값들을 변경해줄 수 있다.
header필드에 기존에 컬럼에 있던 컬럼명을 넣어주면 그대로 헤더의 필드값을 형성하는 것을 확인할 수 있다.
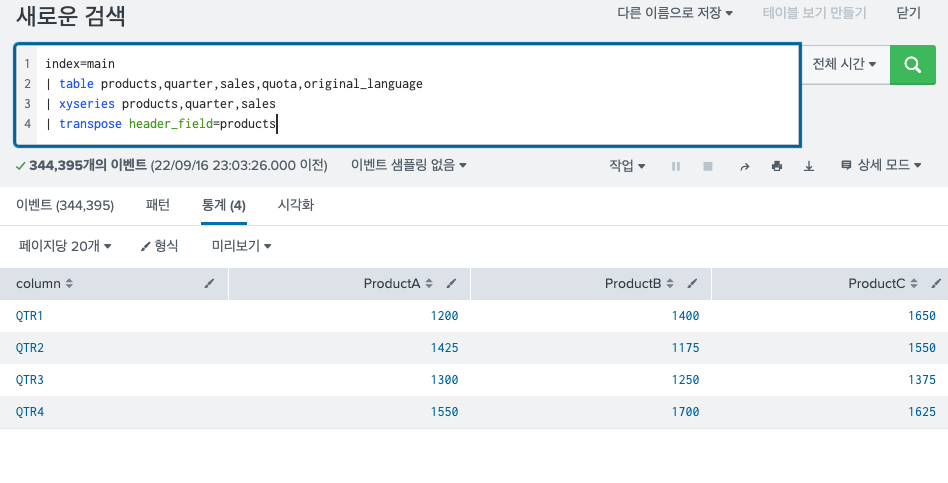
- header_field_2
합계를 이용해 정렬된 결과로 확인해보자.
addtotals명령어와 sort명령어를 같이 사용했다.
이렇게 되면 Total값 기준 정렬이 되기 때문에 다음과 같은 모습을 확인할 수 있다.
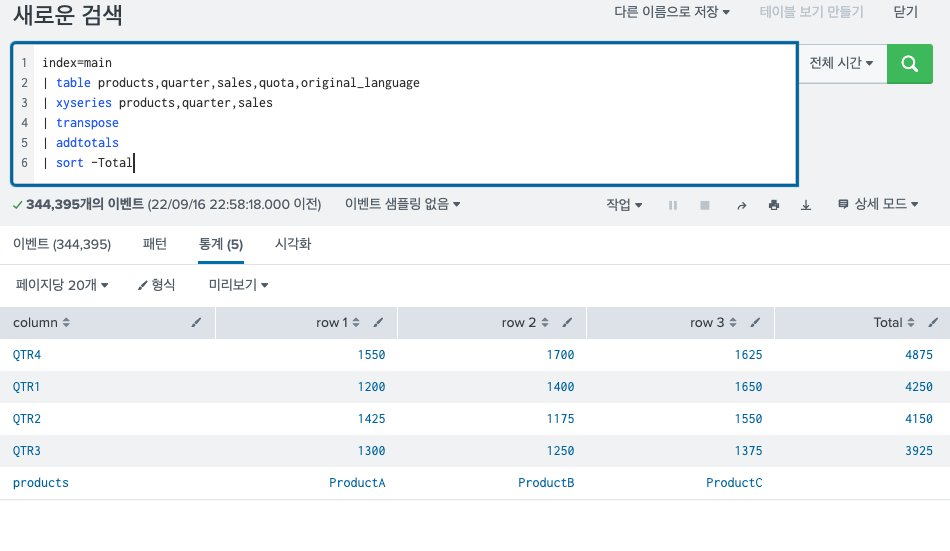
이렇게 되면 가장 아래 줄로 필드명이 내려가게 되고, 여기서 transpose를 다시해주면 다음과 같은 모습을 확인할 수 있다.
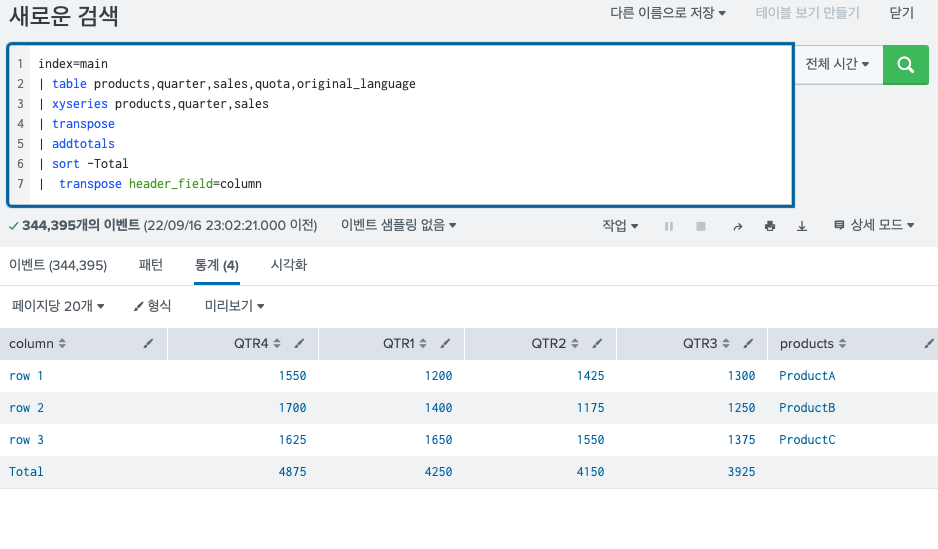
헤더 필드의 네임을 위에서 봤던 column네임으로 하게 되면 실제 헤더에 기존에 column 에 있었던 값들이 헤더로 올라간 것을 확인할 수 있다.
그런 다음에 보기좋게 column 필드를 제거해주면?
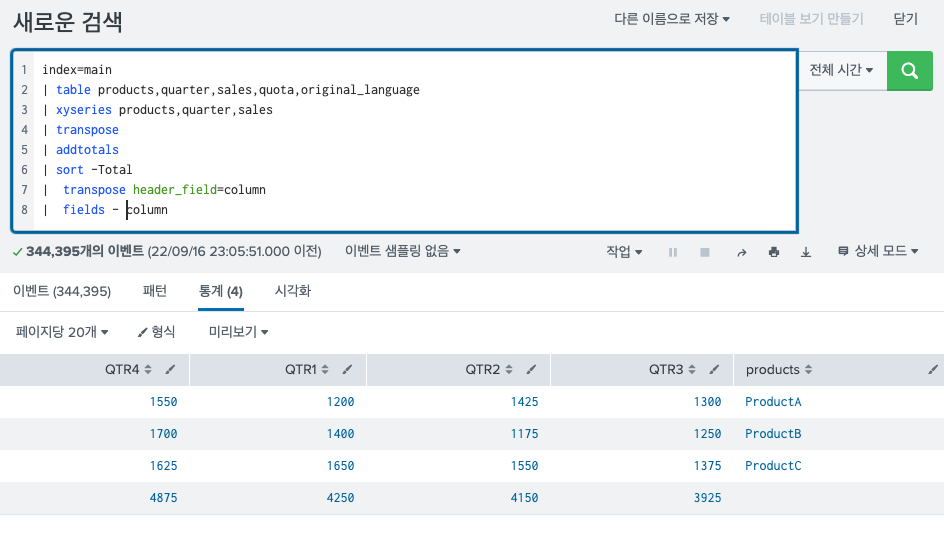
정렬 + 표 형식 + x,y바꿔줌 + Total 값 확인 까지 완성이다.
- header_field + column_name
컬럼 명을 따로 지정해줄 수 있다. 원래 header_field만 사용했던 데이터는 이렇게 생겼었는데
여기서 컬럼명을 따로 지정해줬다.
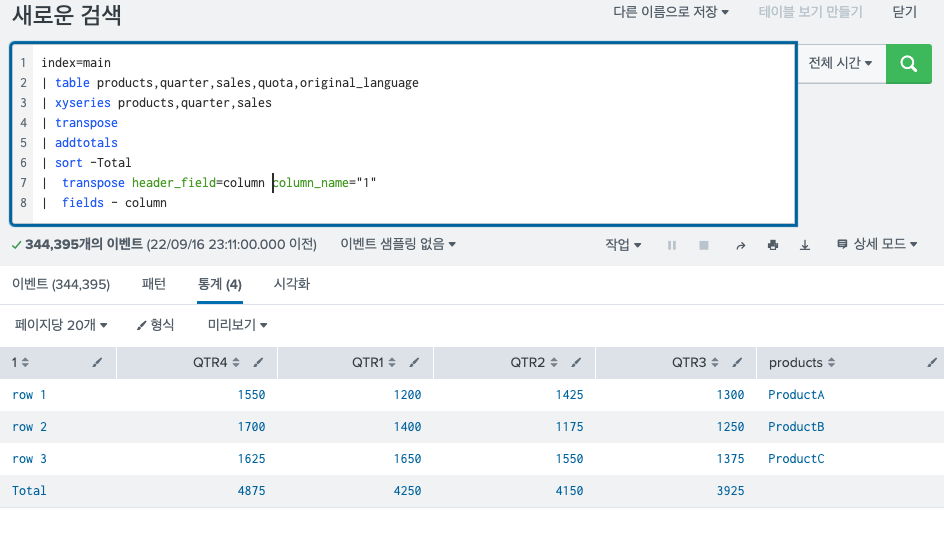

splunk 고수님 잘보고 갑니다~!