splunk에서 정규 표현식을 사용할 때 자주쓰는 rex를 정리한다.
rex
정규표현식을 기반으로 필드를 추출해주는 커맨드이다. 필드를 추출할때 사용되기 때문에 정규 표현식 중에서도 (?P<name>regex) 형태의 명명 그룹 기능을 이용한다.
그 외에도 sed를 이용해 필드의 문자를 바꾸거나 대체할 수 있다.
기본적인 형태는 다음과 같다.
| rex field=test "(?P<name>regex)"1) (?P<name>regex) 형태 사용하기
그룹 기능을 사용하면 name으로 추출된 데이터를 그대로 변수로 사용할 수 있다.
예를 들어서 다음과 같이 이용해보자.
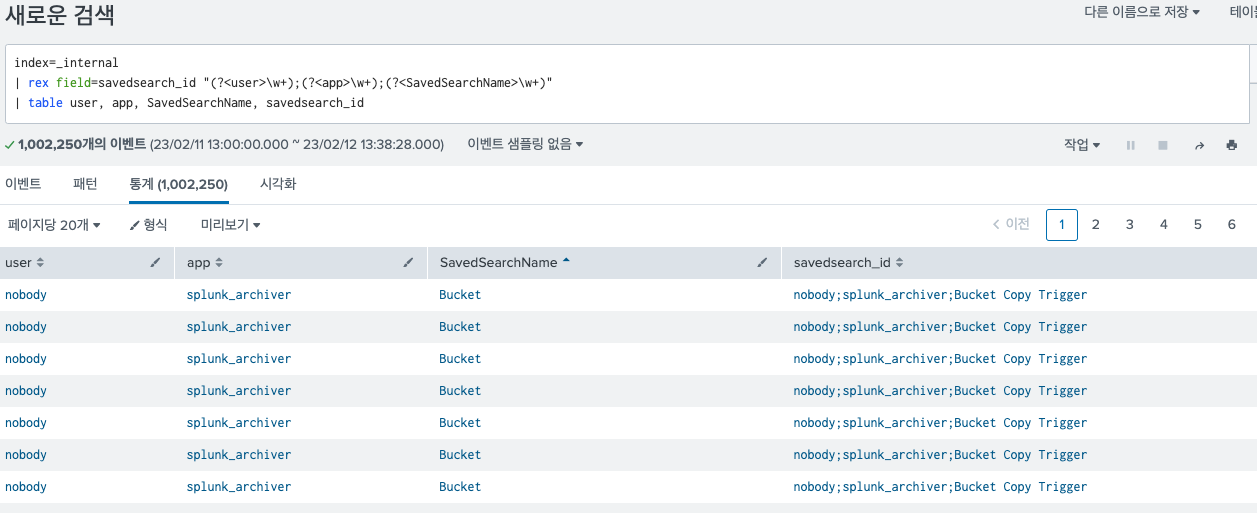
index=_internal
| rex field=savedsearch_id "(?<user>\w+);(?<app>\w+);(?<SavedSearchName>\w+)"
| table user, app, SavedSearchName, savedsearch_id인터널 로그 데이터에서 세이브 서치의 로그 정보를 가져오는 내용이다.
정규식은 전체 데이터 중 savedsearch_id 필드에서 정규식으로 세이브 서치의 사용자명과, 앱, 그리고 서치 명을 추출한다.
그러면 다음과 같은 결과를 볼 수 있다.
- 옵션
- max_match: 정규식이 일치하는 필드를 제어한다. 무제한으로 설정하려면 0으로 하면 된다.
- offset_field: 이것은 바로 SavedSearchName로 예를 들어 보여주면 다음과 같다.
| rex field=savedsearch_id offset_field=SavedSearchName "(?<user>\w+);(?<app>\w+);(?<SavedSearchName>\w+)"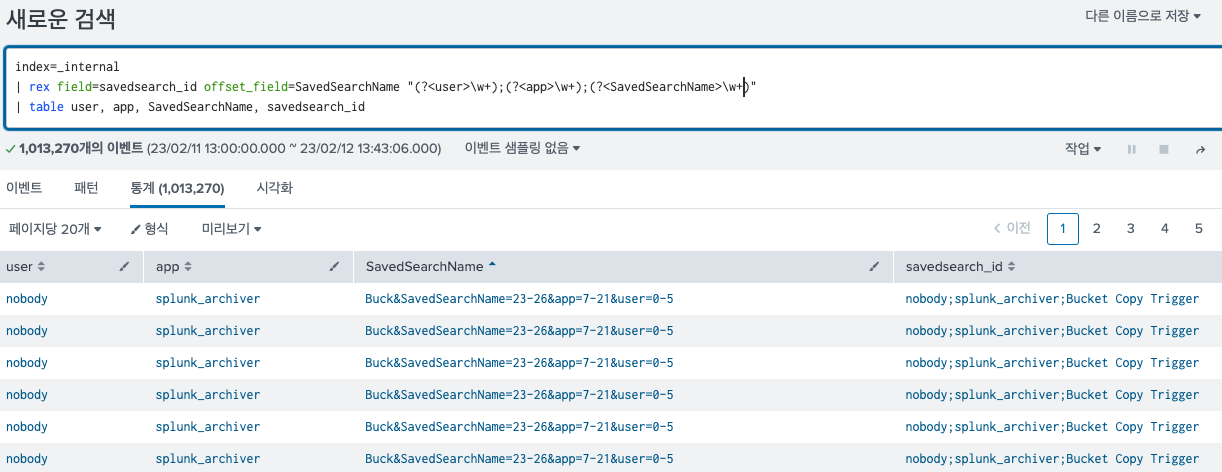
그림처럼 각각의 정규식의 해당하는 필드의 offset위치 정보를 보여준다.
2) sed(stream editor) 사용하기
sed 기능에는 2가지 버전이 있다.
-
s/<regex>/<replacement>/<flags>
- regex 정규식에 해당하는 문자 부분을 replacement 부분을 대체 한다. 이때 flags는 4라고 적으면 4번째에 일치하는 부분만 대체 한다.
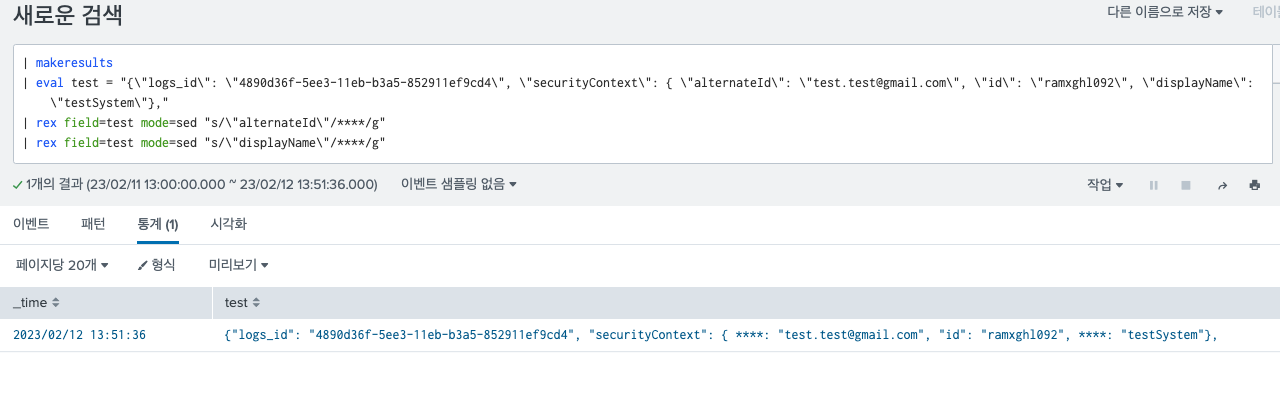
바로 예시를 들어 보여주면 다음과 같다.| makeresults | eval test = "{\"logs_id\": \"4890d36f-5ee3-11eb-b3a5-852911ef9cd4\", \"securityContext\": { \"alternateId\": \"test.test@gmail.com\", \"id\": \"ramxghl092\", \"displayName\": \"testSystem\"}," | rex field=test mode=sed "s/(\"alternateId\":\s+\")([^\"]+)/\1****/g" | rex field=test mode=sed "s/(\"displayName\"\:\s+\")([^\"]+)/\1****/g"이러한 쿼리를 입력하게되면, alternateId, displayName 정규식에 해당하는 부분을 * 별로 치환하는 명령어이다. 결과는 다음과 같다.

-
y/<string1>/<string2>/
- string1에 해당하는 부분을 string2로 대체하는 단순 문자열 대체 구문이다.| makeresults | eval test = "{\"logs_id\": \"4890d36f-5ee3-11eb-b3a5-852911ef9cd4\", \"securityContext\": { \"alternateId\": \"test.test@gmail.com\", \"id\": \"ramxghl092\", \"displayName\": \"testSystem\"}," | rex field=test mode=sed "s/\"alternateId\"/****/g" | rex field=test mode=sed "s/\"displayName\"/****/g"이번에는 alternateId, displayName 문자열 자체를 치환한다.
s 옵션은 정규식에 해당하는 부분을, y 옵션은 단순히 일치하는 부분을 바꿔준다고 생각하면 될 것 같다.
