효율성 문제가 어려웠던 ... 역시 카카오 문제라고 생각했던 문제이다. 보면 단순 구현 같은데 생각보다 깊은 개념을 요구하는 문제였다. 그래서 나는 효율성 못품
1. 문제 설명
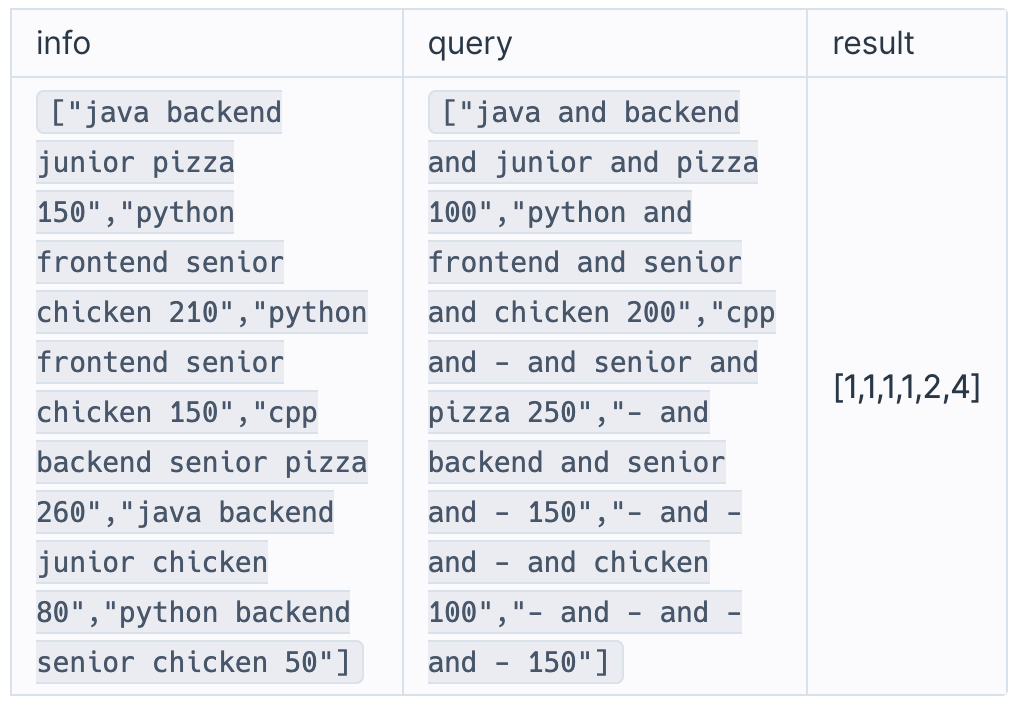
info로 지원자의 정보가 주어지면 다음과 같이 나타낼 수 있다.
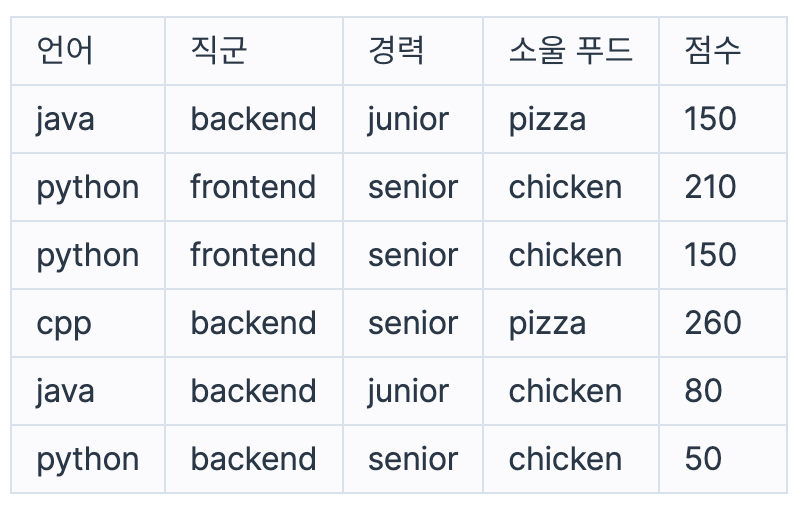
이 지원자들을 query변수로 받은 조건으로 필터링 하여 확인한다.
다음과 같이 진행한다.
- "java and backend and junior and pizza 100" : java로 코딩테스트를 봤으며, backend 직군을 선택했고 junior 경력이면서 소울푸드로 pizza를 선택한 지원자 중 코딩테스트 점수를 100점 이상 받은 지원자는 1명 입니다.
- "python and frontend and senior and chicken 200" : python으로 코딩테스트를 봤으며, frontend 직군을 선택했고, senior 경력이면서 소울 푸드로 chicken을 선택한 지원자 중 코딩테스트 점수를 200점 이상 받은 지원자는 1명 입니다.
- "cpp and - and senior and pizza 250" : cpp로 코딩테스트를 봤으며, senior 경력이면서 소울푸드로 pizza를 선택한 지원자 중 코딩테스트 점수를 250점 이상 받은 지원자는 1명 입니다.
- "- and backend and senior and - 150" : backend 직군을 선택했고, senior 경력인 지원자 중 코딩테스트 점수를 150점 이상 받은 지원자는 1명 입니다.
- "- and - and - and chicken 100" : 소울푸드로 chicken을 선택한 지원자 중 코딩테스트 점수를 100점 이상을 받은 지원자는 2명 입니다.
여기서 확인된 지원자의 명수를 배열로 받아 리턴한다.
[1,1,1,1,2,4]
2. 어려웠던 점
1) 이분탐색
이분탐색을 사용할 줄은 전혀 몰랐다. 이분 탐색 모듈인 bisect는 별도로 포스팅 해야겠다.
3. 문제 풀이
0) 풀이 아이디어
일단 기본적으로 테크 블로그의 글을 참고했다. 카카오 문제는 항상 해설을 확인해서 엉뚱하게 푼게 아닌지 확인해야 한다. 엉뚱하거나, 이해할 수 없는 코드라면 제대로 푼게 아니다. 문제에는 항상 요구사항이 있다.
- 지원자의 스펙이 담긴 info 배열에서 하나의 row를 보자

- 이 지원자는 다음과 같은 query에 만족하는 지원자이고, 해당 query가 있다면 카운팅 될 것이다.
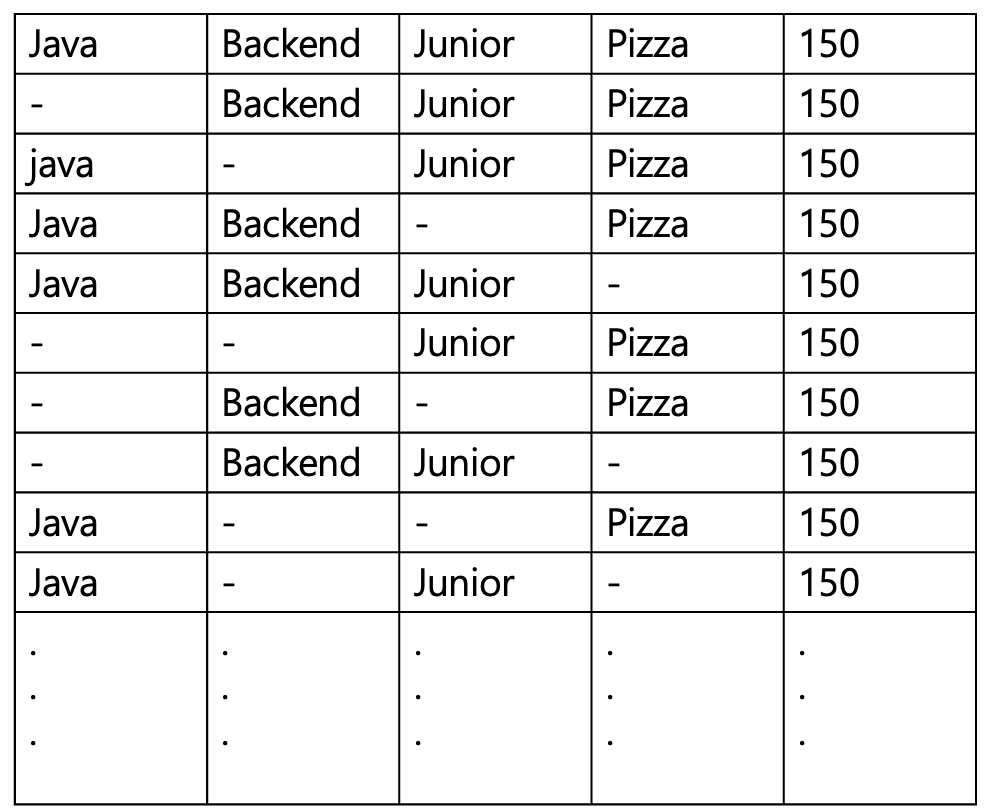
여기의 모든 요소에 카운팅 될 수 있다.
즉, 지원자가 들어갈 수 있는 모든 요구사항의 경우를 만들어 놓고
지원자별 점수만 모아두면 된다.
그래서 특정 요구사항이 요청되면, 해당 요구사항을 만족하는 점수를 확인하고
일정점수 이상인 구간을 찾아 return하면 그게 곧 만족하는 지원자의 수가 되는 것이다.
이때 구간을 찾을때 이분탐색을 활용한다.
1) 1차 풀이
def confirm_employee(info_list, require_info, score):
cnt = 0
for i in info_list:
info_row = i.split()
for info, require in zip(info_row[:4], require_info[:4]):
if info not in require:
if require == "-":
pass
else:
break
else:
if int(info_row[-1]) >= int(score):
cnt += 1
return cnt
def solution(info, query):
result = []
for i in query:
require_info = i.replace(" and", "").split()
result.append(confirm_employee(info, require_info, require_info[-1]))
return result조건을 모두 나눠서, 실제 info 리스트와 하나씩 비교했다. 당연히 효율성은 통과 못함
2) 2차 풀이
from collections import defaultdict
from itertools import combinations
from bisect import bisect_left
result = []
employee_dict = defaultdict(list)
def extract_way_underbar():
global result
for i in range(1,5):
for way in combinations([0,1,2,3],i):
result.append(way)
def extract_info(info_list):
global result
global employee_dict
extract_way_underbar()
for info_each in info_list:
employee_split = info_each.split()
for underbar_list in result:
temp = employee_split
for change_underbar in underbar_list:
temp[change_underbar] = "-"
key = ''.join(temp[:4])
if employee_dict.get(key):
employee_dict[key].append(int(temp[-1]))
else:
employee_dict[key] = [int(temp[-1])]
for val in employee_dict.values():
val.sort()
def solution(info, query):
global employee_dict
extract_info(info)
answer = []
for i in query:
require_info = i.replace(" and", "").split()
score, require_info_str = int(require_info[-1]), ''.join(require_info[:4])
if require_info_str in employee_dict:
potential_employee_score = employee_dict[require_info_str]
index = bisect_left(potential_employee_score, score)
answer.append(len(potential_employee_score) - index)
else:
answer.append(0)
continue
return answer풀이 글을 보고 이해한 다음 다시 풀어봤다. 하지만, 다음과 같이 풀이되지 않았다. 다른 블로그의 풀이를 가져와 출력물을 비교해봤다.
- 다른 블로그 출력물
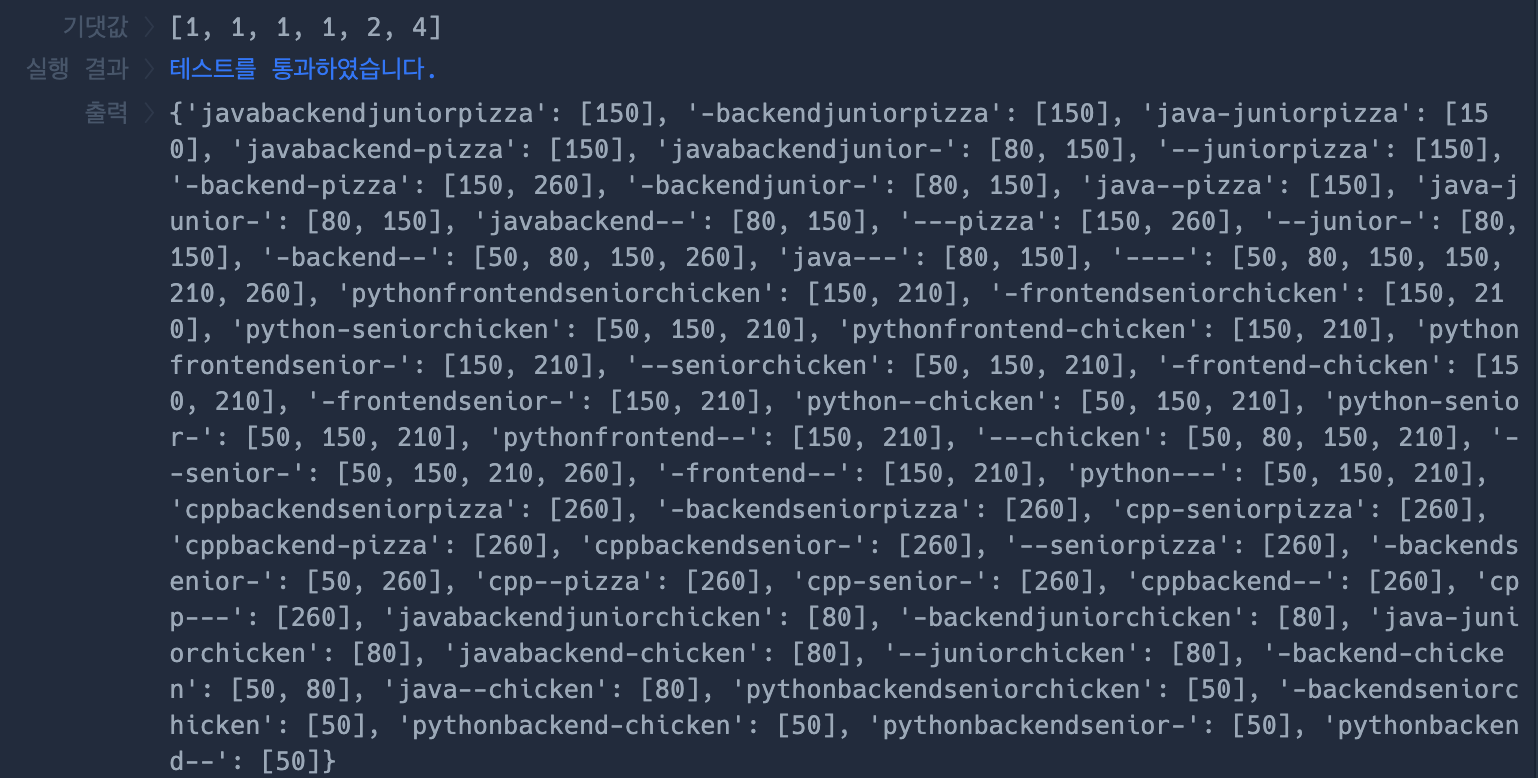
- 내 코드
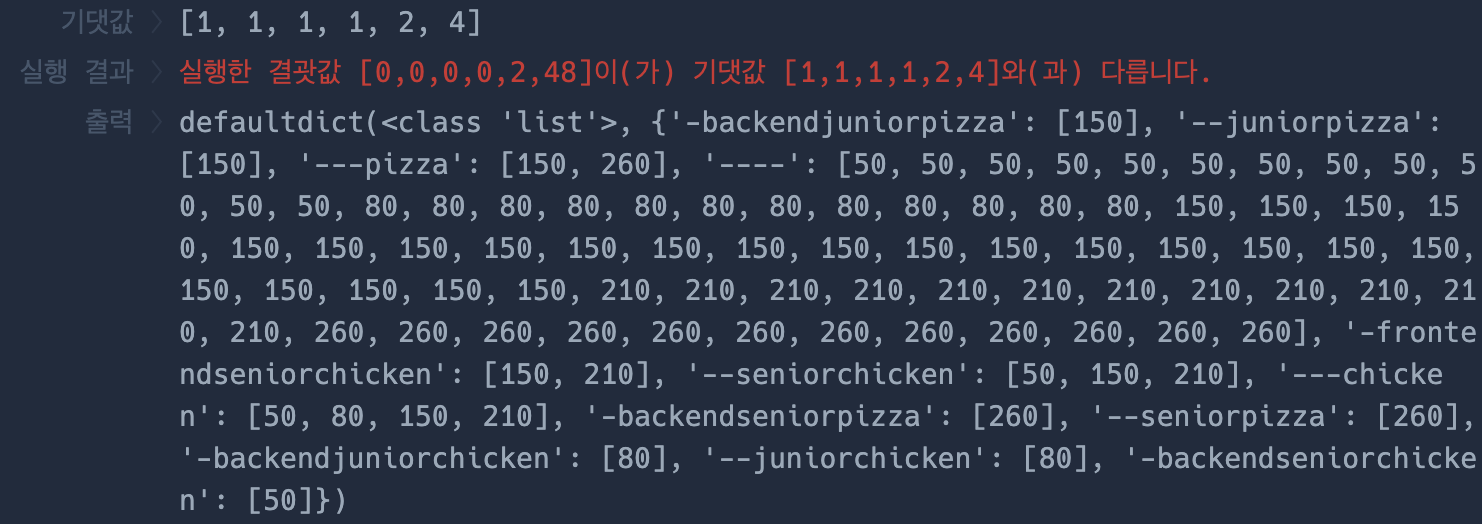
딕셔너리의 키가 모든 경우의 수로 반영이 안됐었다. 자세히 살펴보니 복사를 제대로 안해줬다.
temp = employee_split
이 부분인데 이렇게 하면 temp의 원소를 바꾸게 되면 employee_split의 원소도 바뀌어진다.
파이썬의 얕은 복사, 깊은 복사 부분에 대해서는 포스팅을 이미 해두었으니 필요한 사람은 참고하면 좋을 것 같다.
아무튼 이부분을 temp = list(employee_split) 이렇게 바꿔주었다.
그렇게 하니 대부분의 경우의 수가 적용되었는데 약간 부족했다.
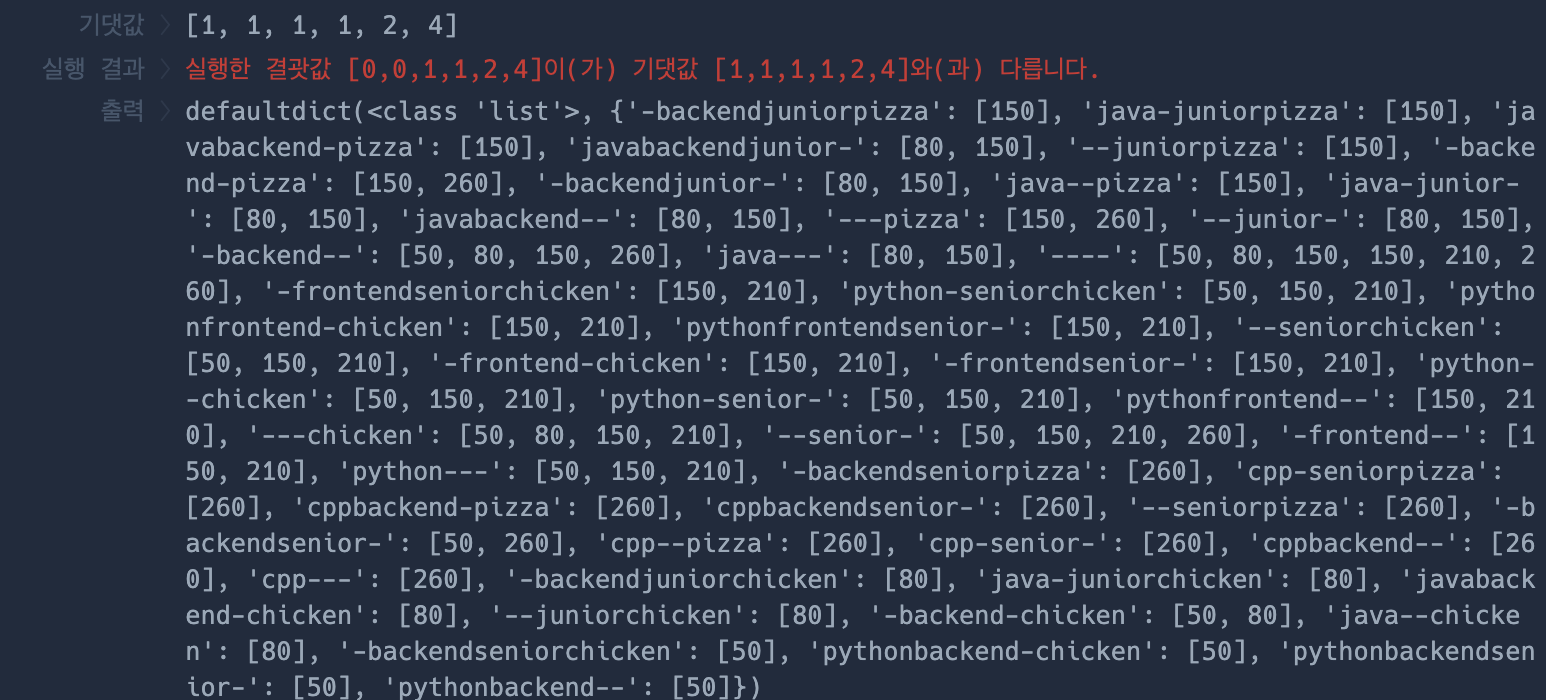
자세히 보니 "-" 을 적용하지 않는 경우도 키로 삽입해줘야 했다. 그래서 이부분을 수정하니 완료!!!
3) 3차 풀이
from collections import defaultdict
from itertools import combinations
from bisect import bisect_left
result = []
employee_dict = defaultdict(list)
def extract_way_underbar():
global result
for i in range(1, 5):
for way in combinations([0, 1, 2, 3], i):
result.append(way)
result.append(())
def extract_info(info_list):
global result
global employee_dict
extract_way_underbar()
for info_each in info_list:
employee_split = info_each.split()
for underbar_list in result:
temp = list(employee_split)
for change_underbar in underbar_list:
temp[change_underbar] = "-"
key = ''.join(temp[:4])
if employee_dict.get(key):
employee_dict[key].append(int(temp[-1]))
else:
employee_dict[key] = [int(temp[-1])]
for val in employee_dict.values():
val.sort() # 시간이 된다면, 여기서도 깊은복사 얕은 복사의 개념을 숙지해두면 좋겠다. 왜 val만 바꾸는데 딕셔너리 전체에 반영이 되는걸까?
def solution(info, query):
global employee_dict
extract_info(info)
answer = []
for i in query:
require_info = i.replace(" and", "").split()
score, require_info_str = int(require_info[-1]), ''.join(require_info[:4])
if require_info_str in employee_dict:
potential_employee_score = employee_dict[require_info_str]
index = bisect_left(potential_employee_score, score)
answer.append(len(potential_employee_score) - index)
else:
answer.append(0)
continue
return answer풀고 나니 정말 많은 개념이 들어가 있다는걸 깨달았다... 개념 하나하나 제대로 숙지해두지 못하면 풀지 못하는 문제, 하지만 개념을 알고있으면 푸는게 어렵지는 않은 문제
카카오는 정말 문제출제를 잘하는 것 같다. 이상한 개념을 요구하지 않고, 정규 교과과정 내에서만 출제하는데 정말 어렵다. 코테계의 평가원 같은 느낌..
아무튼 오늘 포스팅 끝
