데이터를 분석에 활용하기 위해 데이터웨어하우스(DW)와 데이터마트(DM)에서 데이터를 가져옴
- 기존 운영시스템(legacy)에서 직접 가져옴(ERP->SQL)
- ODS(Operational Data Store : 운영 데이터 스토어)에서 전처리(정제)된 데이터를 가져와 DW에서 가져온 내용과 결함하여 분석에 활용
데이터웨어하우란?
- 데이터 웨어하우스는 큰 규모의 데이터를 수집, 관리, 분석하기 위한 데이터 저장 공간입니다. 전사적인(회사전체) 데이터를 저장하고 분석하는데 주로 사용됩니다.(chat GPT)
데이터 마트란?
- 데이터 마트는 데이터 웨어하우스의 일부입니다. 특정 부서나 목적을 위해 데이터를 추출하여 저장하는 것입니다. 부분적인 데이터를 빠르게 분석하기 위해 사용됩니다.(chat GPT)
ODS(Operational Data Store : 운영 데이터 스토어)란?
- 기업의 운영 활동에서 발생하는 데이터를 실시간으로 저장하고 관리하는 데이터베이스입니다. 운영 데이터를 즉시 분석하고 이용하기 위해서 사용되며, 데이터 웨어하우스나 데이터 마트로의 적절한 데이터 전송을 위한 중간 저장소 역할도 할 수 있습니다.
일반적으로 ODS는 데이터의 정확성 및 완전성이 높은 것이 중요하지 않고, 데이터의 실시간성과 효율적인 관리가 목적이므로, 정제되지 않은 데이터도 저장될 수 있습니다. 하지만 분석을 위한 데이터는 정확하고 완전해야 하므로, 데이터 정제는 다른 데이터 저장소(예를 들어, 데이터 웨어하우스 또는 데이터 마트)로의 데이터 전송 전에 수행될 수 있습니다.
스테이지 영역(staging)
-데이터 전처리를 통해 DW와 DM에 결합하여 사용
ex-공공데이터(사용에 따라 ODS가 될 수 있음...애매), 크롤링
- 형식을 정제하고 검증하기 전에 일시적으로 저장하는 것
ODS와 staging의 차이는 어떤 데이터냐이기보단 정제가 되어있냐 안 되어있냐가 될것 같음
데이터의 처리 과정(이해 한방 컷)
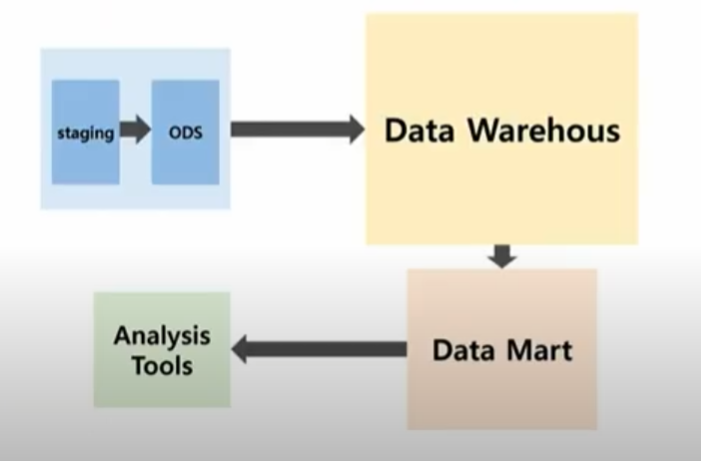
anlaysis tool - R,python,SQL 등등...
탐색적 자료 분석(EDA:Exploratory data analysis)
시각화
가장 낮은 수준의 분석
대용량데이터를 다루는 빅데이터 분석에 필수적(방대한 데이터의 직관적 이해를 위함)
- 탐색적 분석을 할 때 시각화는 필수!
탐색적 분석이란?
- 탐색적 분석(Exploratory Data Analysis)은 데이터를 분석하기 전에 데이터의 구조와 특징, 그리고 데이터에서 어떤 관찰이 가능한지 탐색하는 과정을 말합니다. 탐색적 분석의 목적은 데이터를 이해하고, 데이터에서 특정 관점에서의 결과를 추출하기 위한 가설을 수립하는 것입니다.(chat-GPT)
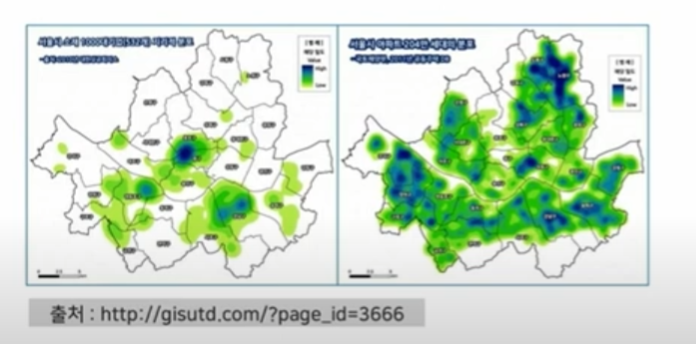
공간분석
공간적 차원과 관련된 속성을 시각화 하는 분석
통계분석
통계 : 어떤 현상을 일정한 체계에 따라 숫자, 표, 그림의 형태로 나타난 것
통계의 종류
기술통계 : 모집단에서 표본 추출, 추출된 표본이 가지고 있는 정보를 파악하기 위해 데이터를 정리, 요약하는 절차 / 데이터의 특성을 요약하는 방법을 말합니다. 기술 통계는 데이터의 평균, 분산, 표준 편차, 최빈값, 사분위수 등을 계산하여 데이터의 특성을 간단하게 요약할 수 있습니다. (이걸 시간순으로 모으면 시계열데이터..?)
추측통계 : 모집단으로부터 추출된 표본의 표본 통계량으로부터 모집단 특성인 모수에 관해 통계적으로 추론하는 절차
모수란?
- 파라미터는 구성원의 속성이나 통계 모형의 특징을 묘사하는 값을 말합니다. 통계학에서, 파라미터는 일반적으로 샘플 데이터로부터 추정되고, 구성원에 대한 가설을 세우거나 모형을 기반으로 예측하는 데 사용됩니다. 파라미터의 예는 구성원의 평균, 분산, 비율 등이 있습니다. 반면에, 샘플 데이터로부터 계산된 통계, 예를 들어 샘플 평균과 샘플 분산은 통계라고 합니다.
데이터 마이닝
대용량의 자료로부터 정보를 요약, 미래에 대한 예측을 목표로 자료간 관계, 패턴, 규칙을 탐색하고 이를 모델링하여 이전에는 몰랐던 유용한 지식을 추출하는 방법, 데이터에서 쓸만한 정보를 추출하는것을 데이터 마이닝이라고 하는듯 통계로 알아낸것이라고 보면 되려나?...아닌듯 GPT에게 물어보자~
데이터 마이닝과 통계는 종종 같이 사용되지만, 다른 목적과 접근 방식을 가지고 있는 관련 분야입니다.
데이터 마이닝은 대량의 데이터에서 숨겨진 패턴이나 지식을 발견하는 과정을 말합니다. 통계학, 머신 러닝, 데이터베이스 시스템 기술을 사용하여 의미있는 관계, 데이터 분류, 예측을 식별합니다. 데이터 마이닝은 일반적으로 비즈니스, 금융, 마케팅 분야에서 고객 행동, 시장 트렌드 등에 대한 통찰력을 얻기 위해 사용됩니다.
반면에, 통계는 데이터의 수집, 분석, 해석, 제시를 다루는 수학의 한 분야입니다. 수학적 모형과 알고리즘을 사용하여 데이터를 요약하고 설명하고, 구성원에 대한 가설을 세우고, 가설을 검정합니다. 통계는 의학, 공학, 사회 과학 등 다양한 분야에서 활용되며, 데이터에서 의미있는 관계, 특징, 패턴을 식별하고 예측 모형을 만드는 데 사용됩니다.
데이터 마이닝 종류
기계학습(machine Learning) : 컴퓨터 프로그래밍을 통해 데이터로부터 스스로 학습하고 결정을 내리는 능력을 갖춘 알고리즘을 개발하는 분야입니다.
ex - 인공신경망(딥러닝같은데), 의사결정나무, 클러스터링(군집분석? 분류문제?), SVM
패턴인식 : 원시 데이터를 이용하여 기존 지식과 패턴에서 발견된 통계 정보를 바탕으로 패턴을 분류하는 방법(머신러닝 기술의 일종)
ex - 장바구니 분석, 연관규칙
딥러닝 : 머신 러닝의 한 분야로, 여러 층으로 구성된 신경망(Neural Network) 구조를 통해 매우 복잡한 문제를 풀 수 있는 능력을 갖춘 알고리즘을 개발하는 분야입니다.
인공 신경망(Artificial Neural Network)은 사람의 뇌와 같은 뉴런을 구조적으로 모방하여 구축된 머신 러닝 모델입니다. 인공 신경망은 다양한 입력을 받아 이를 분석하여 특정 출력을 생성하는 기능을 갖습니다. 인공 신경망은 주로 이미지 분류, 언어 모델링, 자연어 처리 등의 작업에 사용됩니다.
클러스터링(Clustering)은 데이터 마이닝의 한 분야로, 비슷한 특성을 가진 데이터 간의 그룹을 찾는 기술입니다. 클러스터링은 데이터를 여러 그룹으로 분류하는 것을 목적으로 하며, 그룹 내의 데이터 간의 유사성을 기준으로 클러스터를 구성합니다. 클러스터링은 시각화, 고객 세분화, 마케팅 분석, 문제 해결 등에 사용될 수 있습니다.
시뮬레이션 - 데이터 마이닝에서 미지의 시스템을 컴퓨터로 모사하여 결과를 예상하고, 분석하는 과정을 말합니다. 시뮬레이션을 통해 미지의 시스템의 결과를 예측할 수 있어서, 미래의 결과를 예상하고 결정적인 전략을 수립할 수 있습니다. - 복잡한 실제 상황을 단순화해 컴퓨터상의 모델로 만들어 재현하거나 변경
- 현상을 보다 잘 이해하고 미래의 변화에 따른 결과를 예측하는데 사용
ex - 미사일궤적, 고속도로 요금 정산소의 창구수 계산
최적화 - 데이터 마이닝에서 모델을 개선하고, 가장 좋은 결과를 얻기 위해 모델의 파라미터를 조정하는 과정을 말합니다. 최적화 과정을 통해 모델이 데이터에 가장 잘 맞도록 조정됩니다. - 제약조건 하에서 목표값을 개선하는 방식
- 목적함수와 제약조건을 정의, 문제를 해결함
ex - 납기일 최적화
