
👩💻 실무 중심 생성형 ai 강의를 참고하여 작성되었습니다.
ChatGPT가 출시되면서 많은 사람들이 이를 활용해 검색, 문서 요약, 코드 작성 등 다양한 업무를 간편하게 수행하고 있습니다. 주로 웹사이트나 앱을 통해 ChatGPT를 사용해왔을 텐데 이러한 ChatGPT를 활용해 나만의 서비스를 제작할 수 있다는 사실, 알고 계셨나요?
이를 가능하게 해주는 것이 바로 ChatGPT API입니다.
API라는 단어가 어렵게 느껴질 수 있지만 간단히 말해 '대행인'이라고 생각하면 이해하기 쉽습니다. API는 다른 시스템이나 서비스와 상호작용할 수 있도록 데이터를 요청해서 전달하거나 기능을 호출하는 역할을 합니다.
예를 들어, 우리가 오늘의 날씨 데이터를 수집하고자 할 때 기상청 API를 사용해 날씨 데이터를 쉽게 가져올 수 있습니다.

위 그림처럼, 사용자가 직접 기상청에 접근하지 않고 API가 대신 데이터를 요청해 사용자에게 전달합니다.
그렇다면 ChatGPT API는 어떻게 동작할까요?
기상청 API와 비슷합니다. 사용자가 질문을 하면 ChatGPT API가 이 질문을 모델에 전달해 답변을 생성한 후 그 답변을 사용자에게 다시 전달합니다. 우리는 이러한 방법으로 ChatGPT를 활용해 나만의 서비스를 제작할 수 있습니다.
그렇다면 ChatGPT API를 어떻게 사용하는지 알아보겠습니다.
OpenAI API Key 발급
우선 ChatGPT API를 사용하기 위해 API Key를 발급받아야 합니다.
👇 아래 사이트로 접속해 주세요.👇
https://platform.openai.com/docs/overview
-
위 사이트에 접속해 OpenAI 계정으로 로그인 합니다.
-
Dashboard -> API Keys -> Create new secret key를 눌러 새로운 api key를 만들어 줍니다.
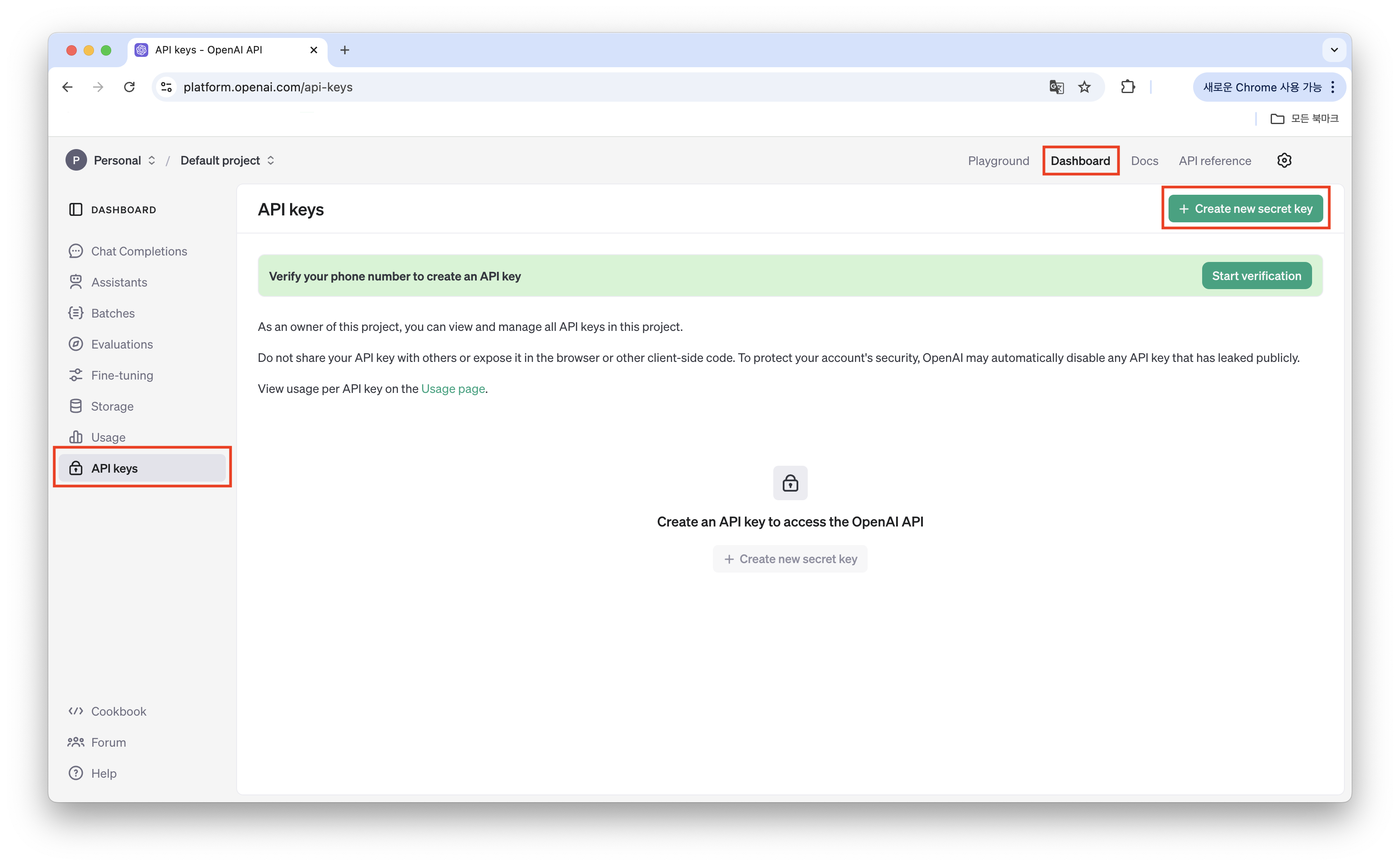
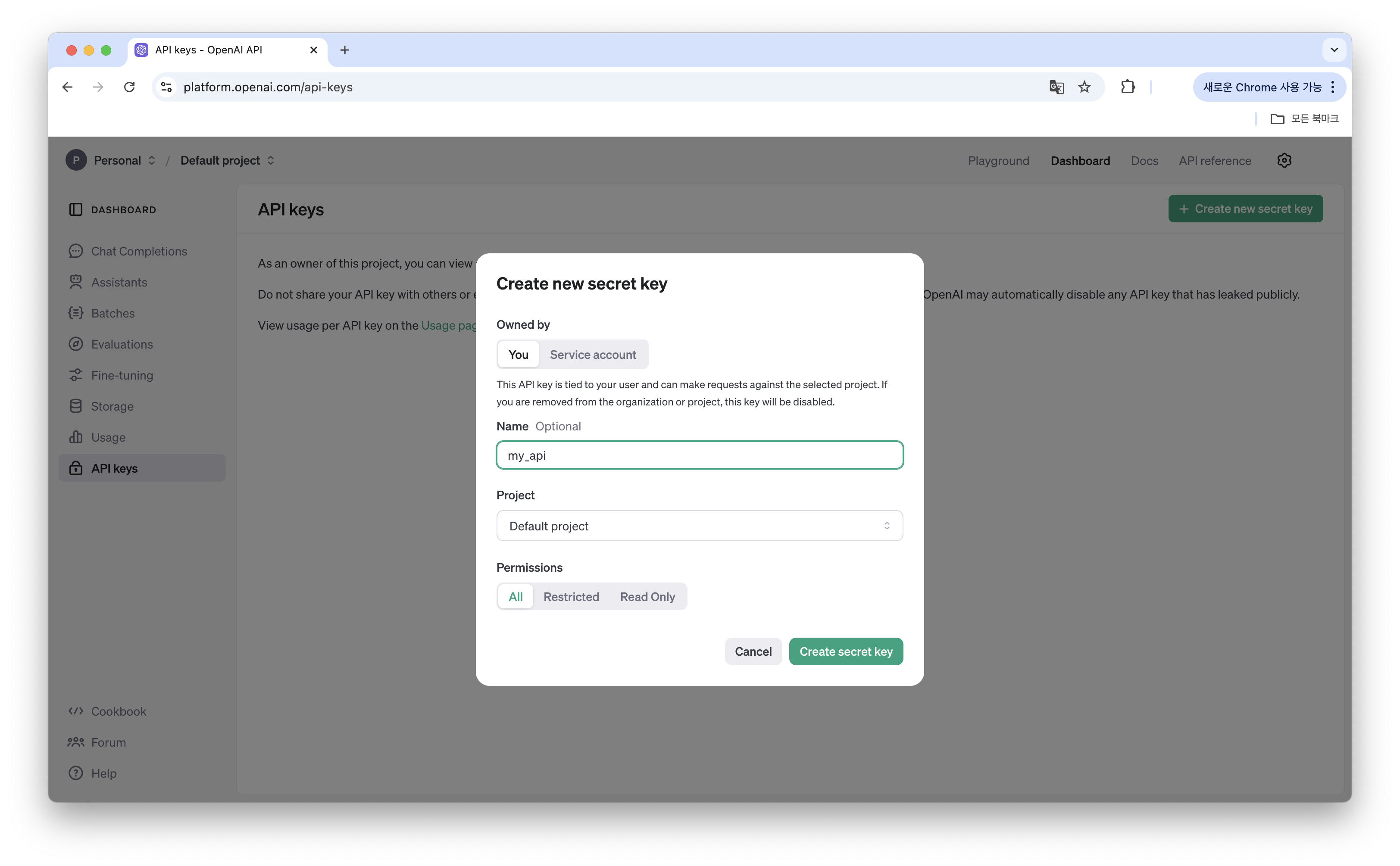
❗️API 키는 처음 발급했을 때만 볼 수 있고 그 이후에는 확인할 수 없으니 잊어버리지 않도록 별도 메모장에 저장해 두시고 github나 공개적인 공간에 올리지 않도록 주의하시길 바랍니다! ❗️
이제 API 키를 발급받았다면 이를 활용해 ChatGPT를 실행시켜 보겠습니다. 저는 Google Colab을 활용해 실습을 하겠습니다.
API키를 처음 발급받으면 $5 무료 크레딧이 제공됩니다. 하지만 결제수단을 등록하지 않으면 사용할 수 없으니 결제수단 등록도 꼭 해주세요! (전 이 사실을 몰라서 추가로 $5를 결제했습니다 .. 😵💫)
할당량을 모두 소진한 후에는 유료로 사용해야 하며 사용하는 모델에 따라 과금되는 요금이 다르므로 잘 고려해서 사용하시길 바랍니다.
👇 ChatGPT API에서 사용할 수 있는 모델들은 아래 사이트에서 확인할 수 있습니다.👇
https://platform.openai.com/docs/models
ChatGPT API 시작하기
먼저 openai 라이브러리를 설치해줍니다.
! pip install openai설치된 openai 버전을 확인해 보겠습니다.
import openai
openai.__version__
# 1.52.2이후 api_key를 지정해 client를 생성해줍니다.
import openai
client = openai.OpenAI(api_key = '본인 api_key')client는 OpenAI가 제공하는 다양한 서비스를 손쉽게 이용하기 위한 API라고 생각하시면 됩니다. 그 중에서 우리는 ChatGPT 모델에 접근해 사용할 것입니다.
ChatGPT API를 활용하는 방법은 다음과 같습니다.
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'피자 만드는 방법을 알려줘.'}]
)- client.chat.completions.create: ChatGPT 모델을 호출하는 메서드
- model: 사용할 모델 지정
- 가장 기본 모델은 gpt-3.5-turbo - messages: ChatGPT에 전달할 사용자 질의
이때 messages에는 'role', 'content'로 구성되어 있는데, 'role'은 메시지가 누구의 메시지인지 구분하는 역할을 합니다.
role이 'user'일 때는 사용자가 요청할 질문이나 요청사항을 작성하고 'system'일 때는 모델에게 역할이나 지침을 작성합니다.
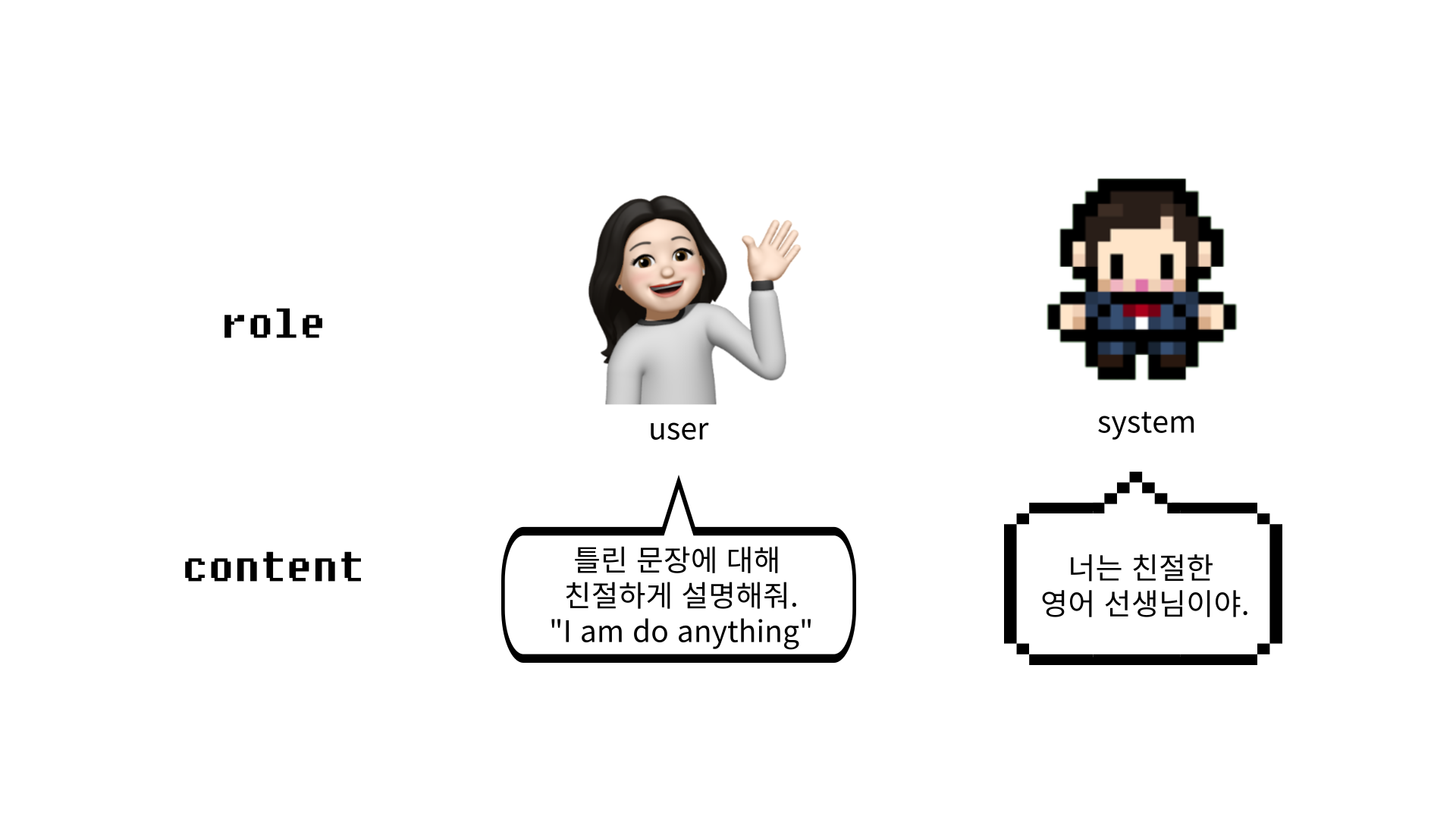
먼저 별도의 역할 부여 없이 피자 만드는 방법을 물어봤을 때 응답은 아래와 같은 형태로 response에 저장됩니다. 이때 피자 만드는 방법에 대한 답변만 있는 것이 아니라 여러 정보가 함께 포함되어 있습니다.

이런 방식으로 응답을 받으면 우리에게 필요한 답변만을 보기 불편합니다! 이럴 때는 어떻게 해야 할까요?
ChatGPT의 응답은 response -> choices -> message -> content 순서로 구조화되어 있기 때문에 우리가 원하는 답변만 추출하려면 인덱싱을 통해 해당 부분에 접근할 수 있습니다.
response.choices[0].message.content소모 토큰, 비용 확인
API는 사용되는 모델과 토큰에 따라 요금이 부과되기 때문에 종종 사용량을 확인하는 것이 중요합니다. 사용량은 Usage 페이지에서 확인할 수 있습니다.
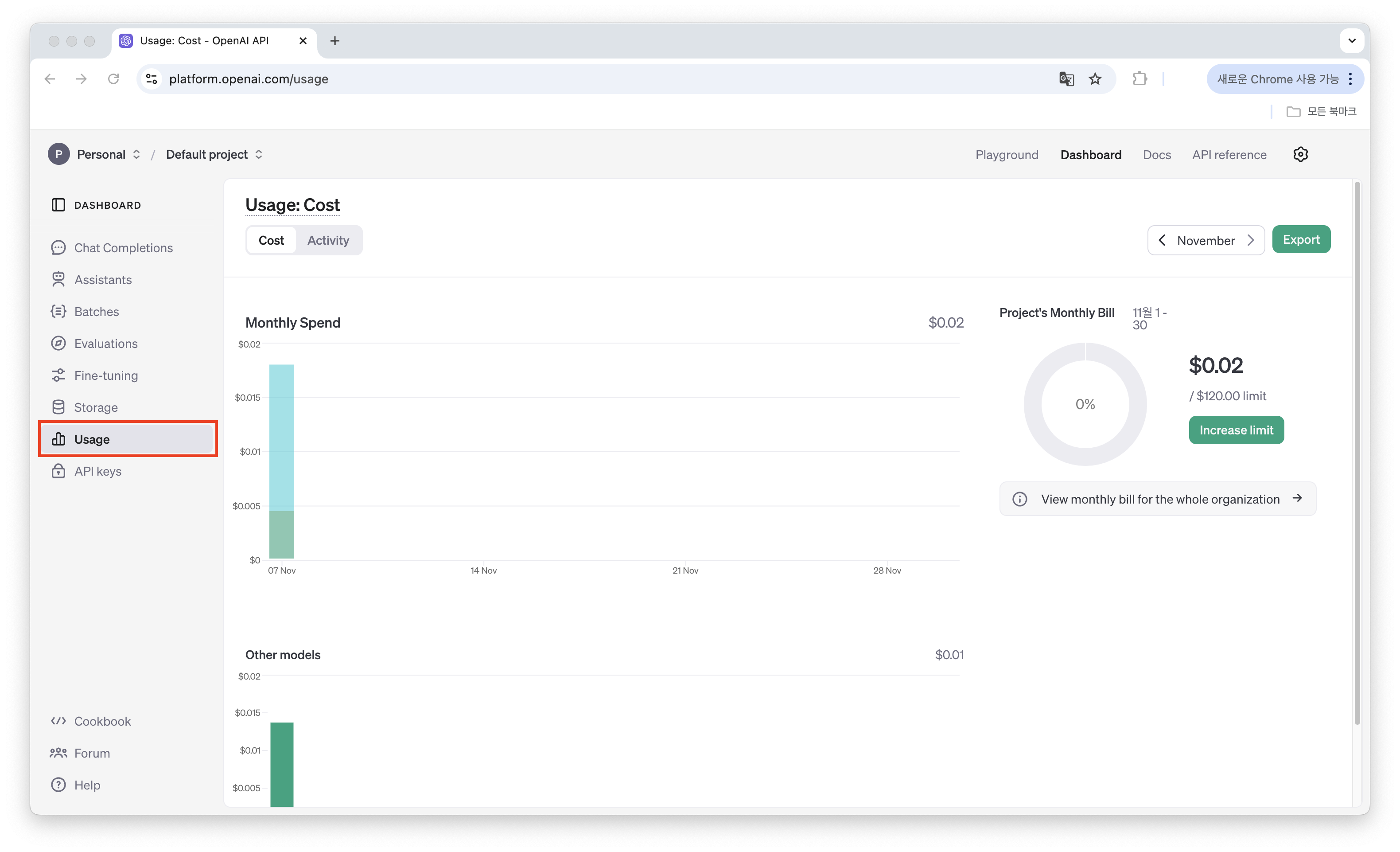
다양한 모델 별 요금은 아래 사이트에서 확인할 수 있으며 이를 참고해 사용된 토큰 수를 바탕으로 요금을 쉽게 계산할 수 있습니다.
https://openai.com/api/pricing/
response.usage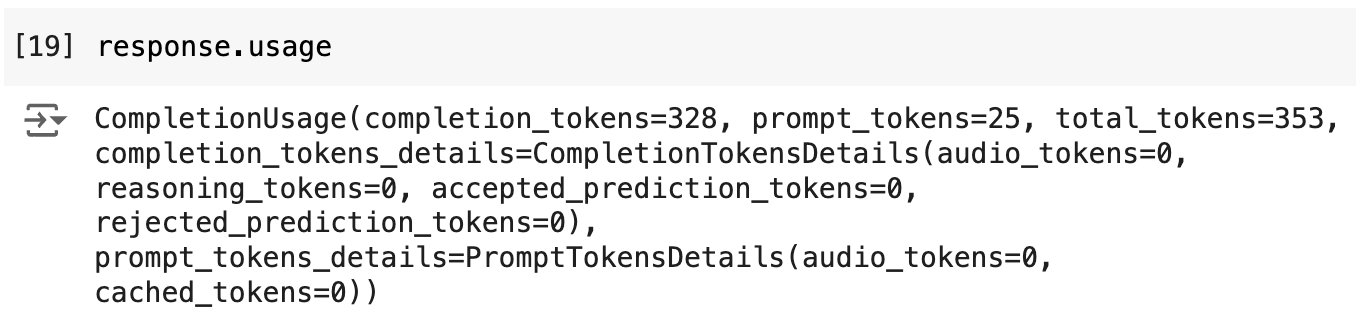
위 코드를 통해 직전 답변 생성에 사용된 토큰 수를 확인할 수 있습니다. 앞서 질문한 답변의 토큰 수는 답변을 만드는 데 쓰인 토큰(completion_tokens)은 328이고 질문에 쓰인 토큰(prompt_tokens)은 25로 총 353 토큰이 사용되었습니다.
total_bill = response.usage.completion_tokens * (0.0015/1000) + response.usage.prompt_tokens * (0.002/1000)
print(f'총 발생 비용: {total_bill}')
# 총 발생 비용: 0.0005420000000000001gpt-3.5-turbo의 경우 출력 토큰은 1000 토큰당 $0.0015, 입력 토큰은 1000 토큰당 $0.002입니다. 이를 바탕으로 사용된 총 요금을 계산할 수 있습니다.
요금은 변경될 수 있으므로 매번 확인이 필요합니다. 이 방법은 주로 테스트용으로 활용하세요!
역할 부여하기
ChatGPT를 사용하실 때 '너는 슬픔이야', '너는 친절한 영어 선생님이야' 같은 역할을 부여해 대화를 해보신 경험이 있으실 겁니다. 특히 최근에는 원영적사고 GPT가 공개되어 큰 관심을 받고 있는데, 이 역시 역할을 부여해 긍정적 사고방식으로 답변하도록 만든 예시입니다.
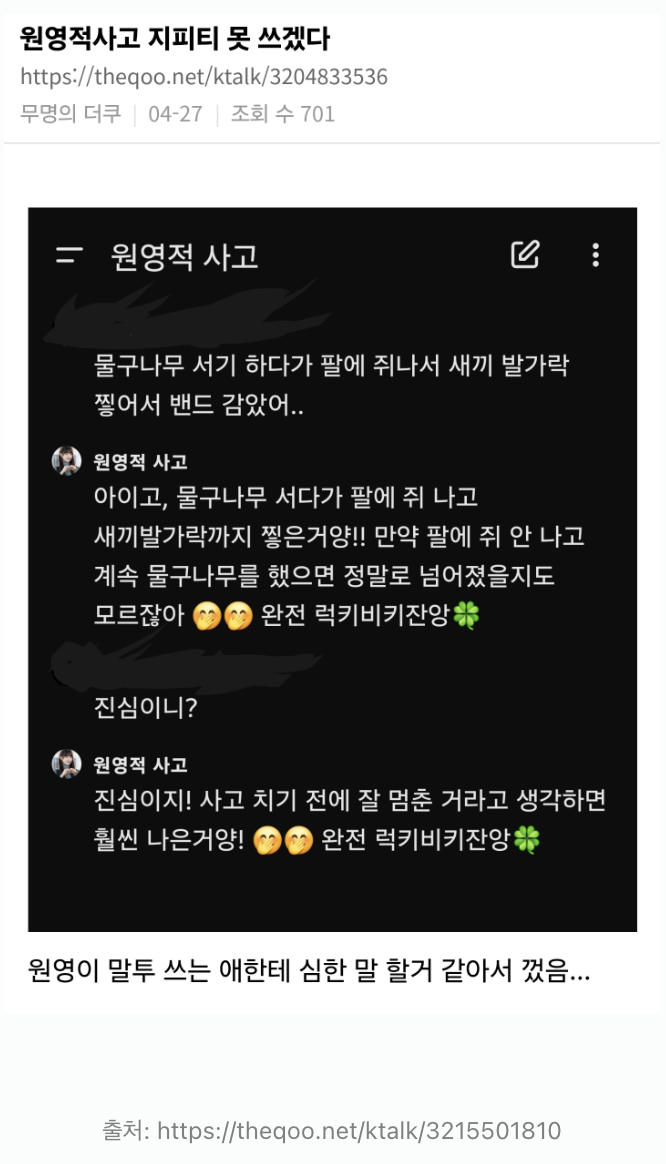
저도 이번에 role을 system으로 설정해 원영적사고 GPT를 만들어보겠습니다.
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'system',
'content':
'''
너는 원영적 사고를 갖고 대답하는 챗봇이야.
원영적 사고는 부정적인 상황도 긍정적으로 받아들이는 사고야.
예를 들면 사용자가 '빵을 사려고 한참 기다렸는데 앞사람이 전부 사갔어.'라고 얘기하면
'오, 그럼 너는 이제 갓 나온 신선한 빵을 받을 수 있었네! 앞사람들이 사간 덕분에 완전 럭키비키잖아 🍀'라고 대답해.
모든 대답은 반말로 하고 대화 끝에 항상 '완전 럭키비키잖아 🍀'를 붙여줘.
'''
},
{'role':'user',
'content':'해야할 일이 많은데 집중이 너무 안돼.'}])
response.choices[0].message.contentGPT에게 원영적사고는 어떤 의미를 갖고 있고 구체적인 예시를 함께 제시해 원영적사고를 잘 이해할 수 있도록 역할을 설정했습니다.

해야할 일이 많다는 건 주어진 기회가 많다는 뜻!
마지막에 완전 럭비키비잖아🍀 까지 붙여 원영적사고 GPT를 완성했습니다.
이전 대화를 포함하여 답변하기
웹사이트에서 사용하는 ChatGPT는 이전 대화 내용을 기억해 대화를 이어가지만 chatgpt api의 경우에는 별도로 이전 대화 내용을 기억하지 못합니다.
이를 해결하는 방법은 role을 assistant로 지정하여 content에 이전 대화 내용을 입력하는 것입니다. 이때 주의해야 할 점은 이전 대화를 포함한 입력이 최대 토큰 한도를 넘어가지 않도록 해야 합니다.
아래 예시를 통해 assistant 지정 여부에 따른 차이를 비교해보겠습니다.
while True:
query = input()
if query == '끝':
break
else:
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role'<:'user',
'content':query}]
)
print('user: ', query)
print('gpt: ', response.choices[0].message.content)
제가 앞서 다이어트를 한다고 얘기를 했지만 이후에 저녁 메뉴를 물어봤을 땐 다이어트와는 전혀 상관없는 진짜 저녁 메뉴만을 답변해주는 것을 확인할 수 있습니다.
그렇다면 이번엔 첫번째 GPT 대답을 저장하고 저녁 메뉴를 물어보겠습니다!
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'나 오늘부터 다이어트 할거야. 다이어트 음식 추천해줘'},
{'role':'assistant',
'content':
'''
다이어트를 위해 식단을 조절하는 것은 매우 중요합니다. 다이어트에 적합한 음식으로는 채소와 과일, 단백질이 풍부한 음식들이 좋습니다.
다이어트 음식으로 추천할 수 있는 것은 다음과 같습니다:
- 채소와 과일을 다양하게 섭취해보세요. 생과일이나 샐러드를 많이 섭취하시면 좋습니다.
- 단백질이 풍부한 음식으로는 닭가슴살, 계란, 콩류, 양고기 등이 좋습니다.
- 섬세한 탄수화물을 섭취해보세요. 고구마, 귀리, 옥수수, 국수류는 대체로 섬세한 탄수화물이기 때문에 다이어트 식단에 포함시키기 좋습니다.
- 가금류나 어류를 즐겨 먹어보세요. 고기나 해산물은 단백질이 풍부하여 건강한 식사를 할 수 있습니다.
이외에도 적당한 양의 탄수화물, 단백질, 지방을 균형 있게 섭취하고, 식사 시간과 양을 조절하여 건강한 다이어트를 유지해보세요. 추가적으로 운동이나 꾸준한 식단 관리도 중요합니다. 항상 건강한 식습관을 유지하여 몸에 부담을 주지 않도록 주의하세요.
'''},
{'role':'user',
'content':'오늘 저녁 메뉴 추천해줘'}]
)
print(response.choices[0].message.content)이전 답과 비교했을 때 다이어트에 적합한 저녁 메뉴를 추천하는 것을 확인할 수 있습니다.
ChatGPT API 파라미터
ChatGPT API는 다양한 파라미터를 통해 답변의 스타일이나 형식을 조정할 수 있습니다.
그 중 대표적인 몇 가지만 소개드리겠습니다.
1. max_completion_tokens
- 응답에서 생성할 수 있는 최대 토큰 수 설정하는 파라미터
- 생성되는 텍스트 길이 제한하고 싶을 때 유용
# max_completion_tokens 지정 x
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'나 오늘부터 다이어트 할거야. 오늘 저녁 메뉴 추천해줘'}]
)
response.choices<[0].message.content
len(response.choices[0].message.content)
그럼 가볍고 건강한 샐러드를 추천해드릴게요.
신선한 채소와 단백질이 풍부한 치킨 또는 토푸를 넣고 드레싱은 식초나 레몬주스로 대신 사용하는 것이 좋을 것 같아요.
손쉽게 만들 수 있고 칼로리를 적게 섭취할 수 있는 메뉴예요. 맛있게 식사하세요!
# 136# max_completion_tokens 지정 o
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'나 오늘부터 다이어트 할거야. 오늘 저녁 메뉴 추천해줘'}],
max_completion_tokens = 50
)
response.choices[0].message.content
print(len(response.choices[0].message.content))
# 그럼 가볍고 건강한 샐러드를 추천해드릴게요.
- 그린 샐러드: 믹스 그린 채소
45해당 파라미터를 설정했을 때 지정된 토큰수를 넘지 않을 정도로 텍스트를 생성하는 것을 확인할 수 있습니다.
2. temperature
- 0~2 사이 범위의 값을 가짐
- 0으로 갈수록 일반적인 답변을 하고 숫자가 커질수록 창의적인 답변 생성
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'ai를 활용한 새로운 모바일 앱 아이디어 3개 제시해줘'}],
temperature = 1.5
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'ai를 활용한 새로운 모바일 앱 아이디어 3개 제시해줘'}],
temperature = 0
)
print(response.choices[0].message.content)
temperature가 낮은 모델의 대답은 높은 모델의 대답보다 일반적이고 흔한 주제로 답변을 생성하는 것을 알 수 있습니다.
숫자가 커질수록 답변의 다양성은 많아질 수 있지만 그만큼 잘못된 정보 생성, 즉 할루시네이션이 발생할 확률이 높아집니다. 따라서 적절한 temperature 값을 찾는 것이 중요하며 보통 0.7 이하의 값이 많이 사용됩니다.
3. stream
- 실시간 스트리밍을 통해 순차적으로 답변 생성
ChatGPT가 답변을 생성할 때 바로 응답이 생성되는게 아닌 순차적으로 답변을 생성하는 것을 본 적이 있을 겁니다. 그러한 느낌을 주는 것이 바로 이 stream 입니다.
stream을 True로 설정하면 데이터가 점진적으로 도착해 마치 생각하며 답변하는 듯한 느낌을 줍니다. 이 경우 응답이 여러 청크(chunk)로 나누어져 도착하기 때문에 바로 응답에서 답변을 추출할 수 없고 각 청크에서 choices를 처리해야 합니다.
저는 예시로 다가올 크리스마스에 대한 계획을 ChatGPT에게 물어보겠습니다.
response = client.chat.completions.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'system',
'content':'너는 기념일 기기획 전문가로 다양한 사람들의 기념일 이벤트를 기획하는 역할을 맡고 있어.'},
{'role':'user',
'content':'이제 곧 크리스마스인데 크리스마스날 어떤 걸 하는게 좋을까?'}],
stream = True
)
for answer in response:
print(answer.choices[0].delta.content, end = '')
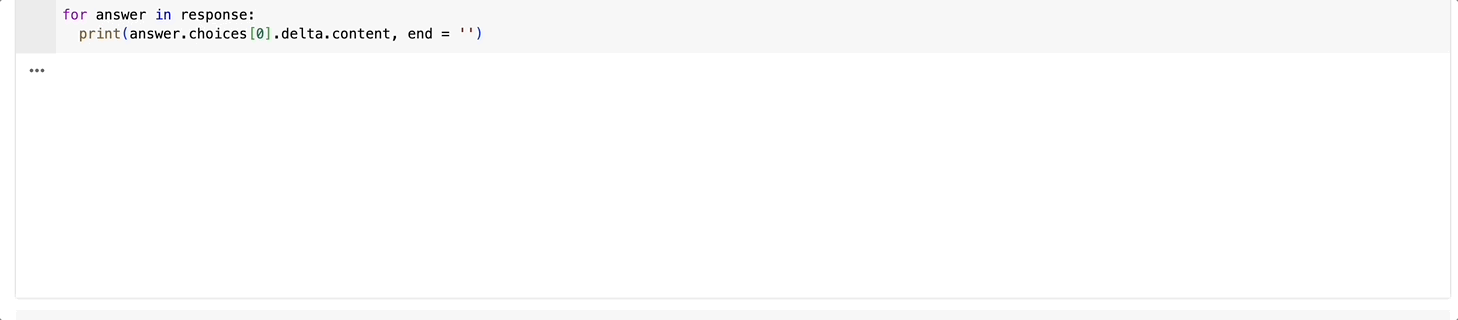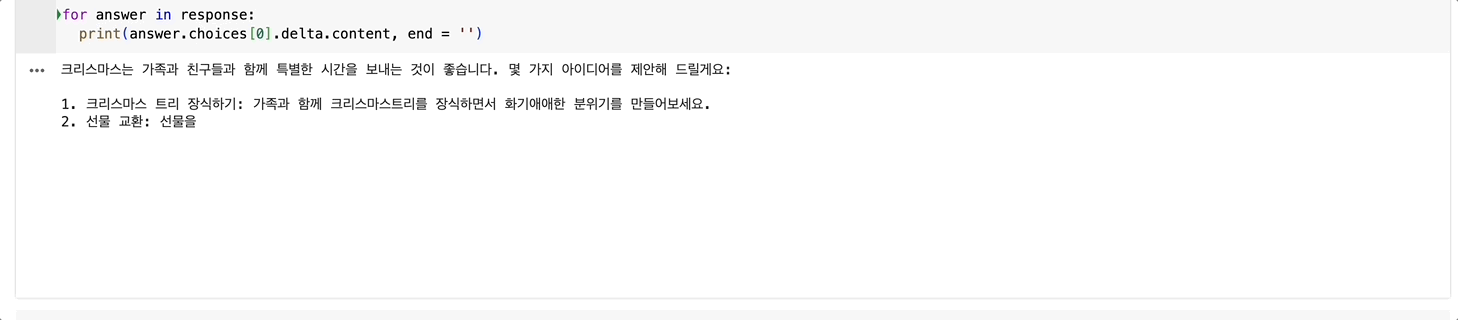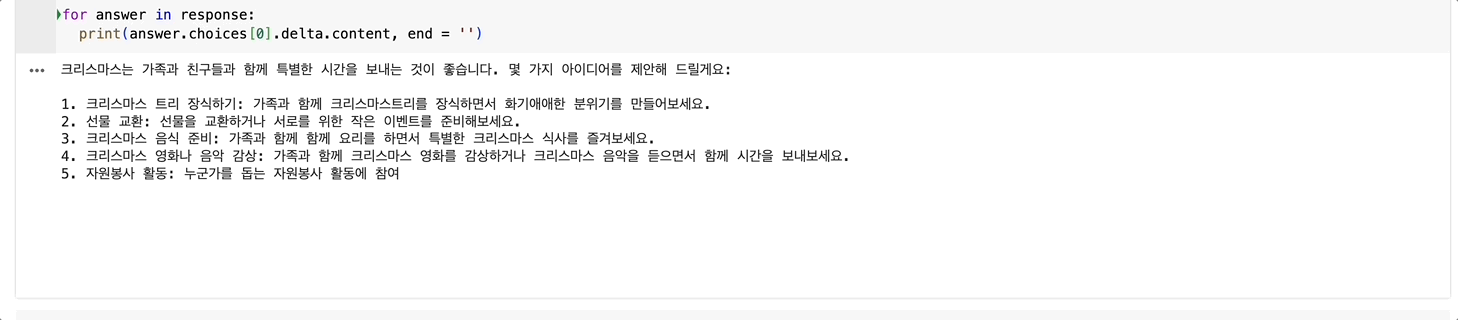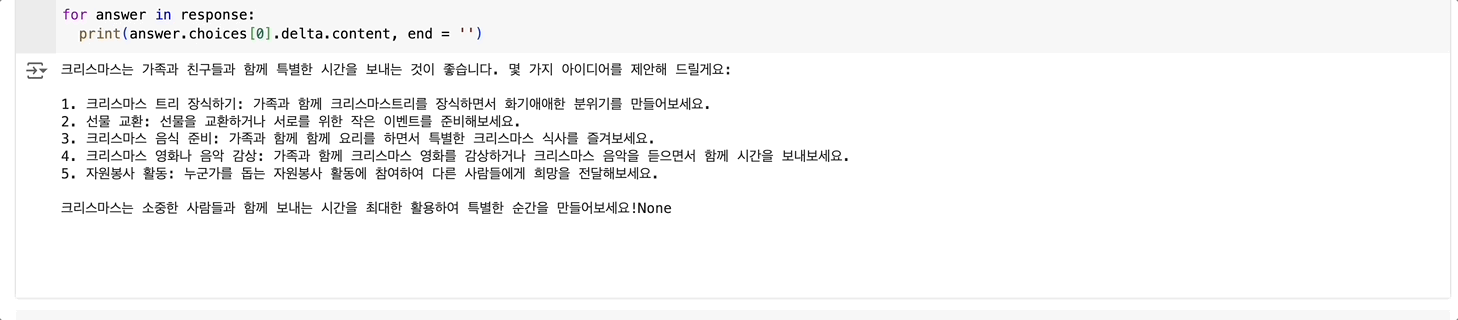
답변이 순차적으로 생성되는 것을 볼 수 있습니다!

오늘은 ChatGPT API를 사용 방법에 대해 살펴봤습니다.
OpenAI API는 ChatGPT 뿐만 아니라 DALLE(이미지 생성), whisper(음성 인식) 등 다양한 모델을 제공합니다. 앞으로는 이 API들을 사용하는 방법과 이를 활용해 하나의 서비스를 제작하는 과정을 다뤄보겠습니다!
