SQLD 3회차 2과목 오답
14. DISTINCT
DISTINCT는 "SELECT 절 전체의 결과 행"을 기준으로 중복을 제거
① DISTINCT 뒤에 나열되는 컬럼들의 중복값을 한 번만 출력하기 위해 사용한다.
✅ SELECT DISTINCT a, b
❌ SELECT a, DISTINCT b는 SQL 문법 오류
② SELECT 문에서만 사용 가능하다.
④ DISTINCT 뒤에 * 를 사용할 수 있다.
1/4 - 1
③ DISTINCT 뒤에 나열되는 컬럼의 순서가 바뀌어도 결과 집합 수는 같다.
DISTINCT COL1, COL2의 경우 두 컬럼의 값이 모두 같은 집합을 중복값으로 간주, 하나만 출력하기 때문에 DISTINCT COL2, COL1의 결과와 순서만 다를뿐 집합의 수는 동일하다.
19 NVL(A,B)
다음 중 정상적으로 실행되지 않는 문장은? (단, DBMS는 오라클)
① SELECT 100 + '1' FROM DUAL;
oracle은 문자형 1을 숫자형으로 자동 형변환한다.
③ SELECT TO_DATE('11', 'DD') + 10 FROM DUAL;
'11' → 11일 (오라클은 기준 날짜(현재 날짜의 연도와 월) + 11일로 간주)
날짜 + 10 → 날짜 연산 OK
④ SELECT NVL(100, 'NULL') FROM DUAL;
NVL(a,b): a가 Null이면 b값 표기
a와 b의 타입이 같아야 하는데 숫자와 문자열이 나타나 오류
오라클에서는 1) 묵시적 형 변환으로 인해 숫자로 변환 가능한 문자값과 숫자값의 연산이 가능하다. 3) 또한 "일"만 있는 경우 날짜로 변환하면, 현재 날짜의 연도와 월을 따른다. 4) NVL의 경우 첫 번째와 두 번째 인수의 데이터 유형이 일치해야 한다.
20 NULL VS 결과행 x
첫 번째 문장은 조건에 만족하는 COL1값이 NULL이므로 NULL 그룹이 리턴된다. 따라서 COUNT를 하면 0이 출력되며, 두 번째 문장은 HAVING 조건에 만족하는 그룹이 없으므로 공집합이 출력되어 COUNT 결과가 NULL이 된다.\
count(null) = 0
count() = 결과 Null(조건만족하는 행 x)
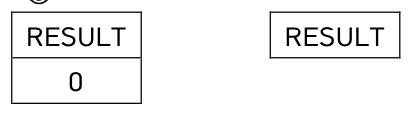
출력값이 null이 나오려면?

SELECT 'NULL' AS RESULT FROM DUAL; -- ❌ 문자열 "NULL"
SELECT NULL AS RESULT FROM DUAL; -- ✅ 진짜 NULL
SELECT NULL + 100 AS RESULT FROM DUAL;
SELECT DECODE(NULL, NULL, NULL) AS RESULT FROM DUAL;
SELECT COUNT(*) FROM EMP WHERE 1=0; -- 0
SELECT AVG(SAL) FROM EMP WHERE 1=0; -- null
'NULL' : 문자열 → "NULL"이라고 글자 출력됨
NULL : 진짜 널값 → 결과 셀에 아무것도 안 보임 (NULL)
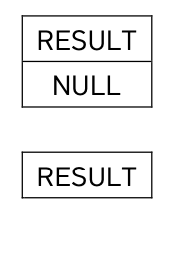
→ 결과 테이블이 존재하고, NULL이라는 값이 들어 있음
(즉, 행은 존재하는데 값이 NULL인 상태)
SELECT NULL AS RESULT FROM DUAL;
SELECT COUNT() FROM STUDENT WHERE SCORE > 100;
조건을 만족하는 행이 없지만, count()이기 때문에 0을 반환
→ 컬럼은 있는데, 출력된 행(row)이 전혀 없음
(즉, 결과 자체가 없는 SELECT)
행이 없는 경우는 아예 해당 조건을 만족하는 데이터가 없음
SELECT col FROM 테이블 WHERE 1 = 0;
SELECT SCORE, COUNT(*) FROM STUDENT WHERE SCORE > 100 GROUP BY SCORE;
조건을 만족하는 행이 없음 -> group by 묶을게 없음 -> 출력없음
| 구문 | 의미 | 조건 만족하는 행 없음 시 |
|---|---|---|
COUNT(*) | 모든 행 수 (NULL 포함) | 0 (1행 출력) |
COUNT(SAL) | SAL이 NULL이 아닌 행만 카운트 | 0 (1행 출력) |
AVG(SAL) | SAL 평균 계산 (NULL 제외하고 계산) | NULL (1행 출력) |
정리
| 함수 | NULL 포함 여부 | 조건 미만 시 결과 |
|---|---|---|
COUNT(*) | 포함 | 0 (숫자) |
COUNT(컬럼) | 제외 | 0 (숫자) |
AVG(컬럼) | 제외 | NULL |
SUM(컬럼) | 제외 | NULL |
MAX(컬럼) | 제외 | NULL |
24 문자열 순서
SUBSTR(JUMIN, 3, 2)은 태어난 월을 추출하기 때문에, 순서대로 12, 11, 06, 01, 08의 문자 유형으로 출력된다.
이를 TO_NUMBER를 사용하여 숫자 형태로 변환하면 12, 11, 6, 1, 8이 되는데, 이를 다시 TO_CHAR로 변환하게 되면 문자값의 비교 규칙에 따라 1 < 11 < 12 < 6 < 8 순서대로 출력된다. (문자는 가장 왼쪽부터 비교하여 값이 작을수록 작은값이 된다)
26 LEFT JOIN
left는 다 살리는거 주의!!
28 SCALAR SUBQUERY
① 하나의 로우에 해당하는 스칼라 서브쿼리 결과 건수는 1건 이하여야 한다.
② 하나의 로우에 해당하는 스칼라 서브쿼리 결과가 0건이면 NULL로 출력된다.
③ 스칼라 서브쿼리는 반드시 한 컬럼만 출력이 가능하다.
④ 메인쿼리와 스칼라 서브쿼리의 연결 조건이 필요하다면 반드시 스칼라 서브쿼리에 정의해야 한다.
스칼라 서브쿼리는 메인쿼리 행마다 한 번씩 실행되기 때문에 메인쿼리의 값을 서브쿼리 내부에서 참조해야만 그 행에 맞는 결과를 가져올 수 있다.
--잘못된 예시
SELECT ename,
(SELECT MAX(sal) FROM emp) AS max_sal
FROM emp
WHERE deptno = (SELECT deptno FROM emp WHERE empno = 7788);
-- 모든 행에 대한 max(sal)을 계산하기 때문에 연결이 안됨
--
--바른 예시
SELECT e.ename,
(SELECT MAX(sal)
FROM emp x
WHERE x.deptno = e.deptno) AS max_sal
FROM emp e;
인라인 뷰에서는 메인쿼리의 값을 참조할 수 없다
33 ANY
IN (서브쿼리)
서브쿼리 결과에 존재하는 임의의 값과 동일한 조건
ALL (서브쿼리)
서브쿼리 결과에 존재하는 모든 값을 만족하는 조건
ANY (서브쿼리) / SOME (서브쿼리)
서브쿼리 결과에 존재하는 어느 하나의 값이라도 만족하는 조건
EXISTS (서브쿼리)
서브쿼리 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건
any이니까 250보다 작거나 350보다 작은거면 참임
조건을 가장 넓게 만족시키는 경계값을 기준으로 삼기때문에 많이 만족할 수 있는 350으로.
ANY는 작다와 만나면 값들 중 최댓값을 리턴한다. 따라서, 메인쿼리 WHERE절은 COL2 < 350 이 되므로 A, B, C들의 COL2의 총 합은 600이 된다.
34 UNION
① UNION 연산자는 조회 결과에 대한 합집합을 나타내며 정렬된 결과를 출력해준다.
② UNION ALL 연산자는 조회 결과를 정렬하고 중복되는 데이터를 모두 출력한다.
③ INTERSECT 연산자는 조회 결과에 대한 교집합을 의미한다.
④ MINUS 연산자는 조회 결과에 대한 차집합을 의미한다.
35 ROLLUP

(deptno, sum(sal))
(null, sum(sal))이므로 rollup(deptno)
rollup(deptno, sum(sal))이면 (null,null)도 나와야함
ROLLUP은 전체 소계를 함께 출력한다. 즉, ROLLUP(A) => GROUP BY A 결과에 전체 소계 출력
37 ROWS vs RANGE + 프레임 지정방식
윈도우 프레임
윈도우 함수에서 각 행을 기준으로 계산에 포함할 데이터의 범위를 지정하는 것
| 기준 | 의미 |
| ------- | ------------------------------------ |
| ROWS | 정렬된 행 기준 (정확히 몇 행) |
| RANGE | 정렬 기준 값의 범위 기준 (값이 같은 행은 함께 포함됨) |
range는 값!!!!
| 키워드 | 의미 |
|---|---|
UNBOUNDED PRECEDING | 처음부터 |
1 PRECEDING | 바로 이전 행(값) |
CURRENT ROW | 현재 행 (또는 현재 값과 같은 값 전체) |
1 FOLLOWING | 바로 다음 행(값) |
UNBOUNDED FOLLOWING | 끝까지 |
누적합의 범위가 각 행마다 이전행과 현재행, 다음행을 연산하고 있으므로(JONES 기준 1100 + 2975 + 3000 = 7075) 1 PRECEDING AND 1 FOLLOWING 이며, SAL이 같은 SCOTT과 FORD의 누적합이 각각 다르게 계산되었으므로 ROWS가 적절하다
40 계층 CONNECT BY ROOT/PRIOR
CONNECT BY PRIOR part = deptno → 부모가 part, 자식이 deptno
연결하려면 다음 행의 DEPTNO가 100이어야 하는데 연결이 되는 행이 없다 -> 트리 퍼지지 않음
=> 결국 루트 노드만 출력
PRIOR의 위치가 PART에 있으므로 가장 최상위 학과(PART IS NULL)를 먼저 출력하고, 두 행의 PART를 DEPTNO 로 갖는 행을 찾지만 해당 행이 없으므로 최상위 학과인 공과대학과 인문대학만 출력된다.
42 REGEXP 정규표현식
문자 클래스([])와 메타문자(., |, \, -, A-z) 처리 방식
-
A-z : ASCII 65~122 범위 전체 (대소문자 + 중간 특수문자)
A–Z, [, \, ], ^, _, `, a–z -
| : | 문자 자체
-
0-9 : 숫자 0~9
-
. : 문자 . 자체
SELECT REGEXP_LIKE('|', 'A|B') → FALSE
SELECT REGEXP_LIKE('|', '[A|B]') → TRUE ← 여기서 |는 단순 문자REGEXP_REPLACE 함수의 동작 방식
REGEXP_REPLACE(str, pattern) : 정규표현식 pattern과 일치하는 부분을 제거 (기본: 빈 문자열로 대체)
[A-z|0-9. ] 패턴은 영문 또는 | 또는 숫자 또는 ** 또는 . 그리고 공백**을 모두 지칭하는 패턴이다. 따라서 이들을 모두 지우면 ,과 :만 남게 된다.
43 DML
3
① DELETE 사용 시 FROM 문구는 생략이 불가능하다.
ANSI SQL에서는 DELETE 테이블명도 허용
② 일부 데이터 DELETE 시 WHERE 절은 반드시 붙이지 않아도 된다.
일부니까 where 붙어야함
③ 반드시 COMMIT 또는 ROLLBACK을 수행하여 TRANSACTION을 종료해야 한다.
DML(INSERT, UPDATE, DELETE)은 COMMIT/ROLLBACK없으면 미반영
④ UPDATE 사용 시 동시에 여러 컬럼 수정은 가능하다.
UPDATE 테이블 SET col1 = 'A', col2 = 'B'
UPDATE로 동시 여러 컬럼 수정 가능하다. DELETE 시 FROM은 생략이 가능하다.
DML 시 COMMIT 또는 ROLLBACK으로 트랜잭션을 종료하지 않으면 변경된 행의 잠금이 발생하여 다른 사용자의 사용에 제한이 생긴다.
45 컬럼변경
① 컬럼의 크기를 늘리고 줄일 수는 없다.
컬럼의 최대 길이만큼 줄일 수 있다. (늘리는건 언제든 가능)
데이터가 이미 들어있는데 줄이려는 길이보다 데이터 값이 더 길면 에러
-> 현재 들어있는 값보다 작게 줄이는건 안됨
② 컬럼이 NULL 값만 가지고 있으면 데이터 유형을 변경할 수 있다.
③ 컬럼에 NULL 값이 없을 경우에만 NOT NULL 제약조건을 추가할 수 있다.
④ 컬럼의 DEFAULT 값을 바꾸면 변경 작업 이후 발생하는 행 삽입에만 영향을 미친다.
49 UNIQUE
① 외래키(자식이 부모의 기본키를 참조)를 생성 한 경우 부모 테이블의 참조키 컬럼(PK)을 삭제할 수 없다.
참조무결성 깨짐
② 제약 조건 추가 시 제약조건 이름을 명시하지 않을 수 있다.
③ 이미 존재하는 컬럼에 대해 NOT NULL 제약조건 추가 시 반드시 MODIFY로 처리한다.
④ NULL값이 삽입되어 있는 경우 UNIQUE 제약조건을 추가할 수 있다(PRIMARY 안됨)
50 권한
① 권한은 테이블 소유자와 with grant option을 부여받은 사용자만이 부여할 수 있다.
② 테이블에 대한 조회 권한 부여 시 즉시 반영된다.
③ 롤에 있는 권한을 회수한 이후 롤을 부여받은 유저는 해당 권한을 갖지 않게 된다.
④ WITH grant OPTION을 통해 부여받은 테이블 조회 권한을 다른 유저에게 부여할 수 있다.
WITH ADMIN OPTION은 ROLE부여 권한 전달
롤에 있는 권한을 회수하는 경우 롤을 부여받은 유저도 해당 권한을 즉시 잃게 된다. 4번 문장은 WITH GRANT OPTION에 대한 설명이다.
DDL / DML / DCL / TCL 정리
| 분류 | 이름 (약자) | 주요 명령어 | 하는 일 |
|---|---|---|---|
| DDL | Data Definition Language | CREATE, ALTER, DROP, TRUNCATE | 데이터 구조 정의 (테이블 만들기, 수정, 삭제 등) |
| DML | Data Manipulation Language | SELECT, INSERT, UPDATE, DELETE, MERGE | 데이터 조회·조작 (내용 추가, 수정, 삭제 등) |
| DCL | Data Control Language | GRANT, REVOKE | 권한 제어 (누가 무엇을 할 수 있게 할지 설정) |
| TCL | Transaction Control Language | COMMIT, ROLLBACK, SAVEPOINT | 트랜잭션 제어 (변경사항 저장, 되돌리기 등) |
권한은 오직 GRANT로 준다. WITH 옵션도 GRANT에서만 붙일 수 있다!
-- [1] user1에게 emp 테이블 조회 권한을 주되,
-- 다른 사람에게도 이 권한을 넘길 수 있게 함
GRANT SELECT ON emp TO user1 WITH GRANT OPTION;
-- [2] user2에게 DBA 롤을 주되,
-- 다른 사용자에게도 DBA 롤을 넘길 수 있게 함
GRANT DBA TO user2 WITH ADMIN OPTION;
