16 NULL 처리
NVL(expr1, expr2)
: NULL이면 바꿔치기 Null Value Logic(replace)
expr1이 NULL이면 expr2를 반환, 아니면 expr1 반환
오라클에서 사용
COALESCE(expr1, expr2, ..., exprN)
: NULL이 아닌 첫 값 반환
ISNULL(expr1, expr2)
: SQL Server의 NVL
expr1이 NULL이면 expr2 반환
NULLIF(expr1, expr2)
: 같으면 NULL, 다르면 expr1
expr1과 expr2가 같으면 NULL 반환, 다르면 expr1 반환
17 sign / decode
SIGN(n)
숫자의 부호를 알려주는 함수(양수1, 음수-1, 0)
DECODE(a, 값1, 결과1, 값2, 결과2, ..., 기본값)
a가 이거면 이거,저거면 저거줘 – Oracle의 if문
오라클 전용 함수 (case when의 짧은 버전)
같은 값이 없다면 기본값.
3
SAL > 4000 이면 SAL - 4000 은 양수이므로 SIGN 을 취한 값이 1 이 리턴된다.
DECODE 문을 해석하면 결국 SAL이 4000 보다 큰 경우 1 을, 그렇지 않은 경우 0 을 리턴하므로 최종 출력값은 2
18 case when 축약형 문법
① SELECT DECODE(SUBSTR(JUMIN, 7, 1), '1', '남자', '여자') FROM TAB1;
② SELECT CASE WHEN SUBSTR(JUMIN, 7, 1) = 1 THEN '남자' ELSE '여자' END FROM TAB1;
③ SELECT CASE SUBSTR(JUMIN, 7, 1) WHEN 1 THEN '남자' ELSE '여자' END FROM TAB1;
substr은 문자열 반환하기 때문에 1일 수가 없음 -> 오류
④ SELECT CASE SUBSTR(JUMIN, 7, 1) WHEN '1' THEN '남자' ELSE '여자' END FROM TAB1;
1 -> 3
CASE 문 축약형 문법(비교 대상이 CASE 와 WHEN 사이에 있는)은 반드시 비교 대상과 비교 상수의 데이터 타입이
일치해야 한다.
| 형식 | 사용 예시 | 자유도 | 특징 |
|---|---|---|---|
CASE a WHEN x | CASE 성별코드 WHEN '1' | 낮음 | a = x 형태로만 비교 |
CASE WHEN 조건 | CASE WHEN 점수 >= 90 | 높음 | 다양한 조건 가능 |
when 사이는 = 형태(값)만 비교할 수 있고(when >= 90 이런거 안됨)
조건식을 쓸 땐 case when 조건식 으로 사용.
19 날짜 연산
SELECT TO_CHAR(TO_DATE('2024/08/24 10:00', 'YYYY/MM/DD HH24:MI')
- 30/24/60,
'YYYY.MM.DD HH24:MI:SS')
FROM DUAL;HH24:MI: 24시간형식의 시, 분(MInute)- 30/24/60: 30분 빼기
날짜끼리 빼면 단위가 일(day)인데
1시간 = 1/24(1을 24시간으로 나눔)
1분 = 1/24/60(1시간을 60분으로 나눔)
30분 = 30/24/60
20 COUNT
① SELECT JOB,
COUNT(CASE WHEN DEPTNO = 10 THEN 1 ELSE 0 END) AS "10번부서원수",
COUNT(CASE WHEN DEPTNO = 20 THEN 1 ELSE 0 END) AS "20번부서원수",
COUNT(CASE WHEN DEPTNO = 30 THEN 1 ELSE 0 END) AS "30번부서원수"
FROM EMP
GROUP BY JOB;
② SELECT JOB,
FROM EMP
COUNT(CASE WHEN DEPTNO = 10 THEN 1 END) AS "10번부서원수",
COUNT(CASE WHEN DEPTNO = 20 THEN 1 END) AS "20번부서원수",
COUNT(CASE WHEN DEPTNO = 30 THEN 1 END) AS "30번부서원수"
GROUP BY JOB;
count는 null값을 세지않는다
4 -> 1
1 번은 CASE 문에 의해 10 번 부서원의 경우 1, 그 외 부서원들은 0 을 생성하고, 이를 모두 COUNT 하면 1 과 0 을 모두 세므로 10 번 부서원만 셀 수 없다. 따라서 2 번 보기처럼 ELSE 를 생략하여 조건에 맞지 않는 값을 NULL 로 리턴한다면 NULL 은 COUNT 하지 않으므로 조건에 맞는 대상만 셀 수 있다. SUM 의 경우는 조건에 맞을 경우 1, 그렇지 않을 경우 0 으로 출력하면 조건에 맞는 대상의 개수를 구할 수 있다.
22 논리연산자 우선순위
NOT > AND > OR 순서
23 NULL
null과 사칙연산, 비교연산, 문자열 연산 등 어떤 연산이든 결과는 NULL
24 Group by
3 -> 4
GROUP BY에 나열된 컬럼들의 순서는 결과 집합을 그룹핑하는 기준 컬럼들일 뿐, 그룹 함수의 연산 결과(값 자체)에는 영향을 주지 않는다.
출력 순서만 달라질 뿐 총 그룹 연산 수행 결과는 같다.
29 매핑
SELECT COUNT(*)
FROM TAB1, TAB2
WHERE NAME LIKE RULE_NAME;
tab1과 tab2는 cross join(JOIN 조건 없이 두 개 이상의 테이블을 쉼표로 나열)
각각 독립된 조건으로 따로 카운트 => 3개로 찍힘
31 NULL / EXISTS
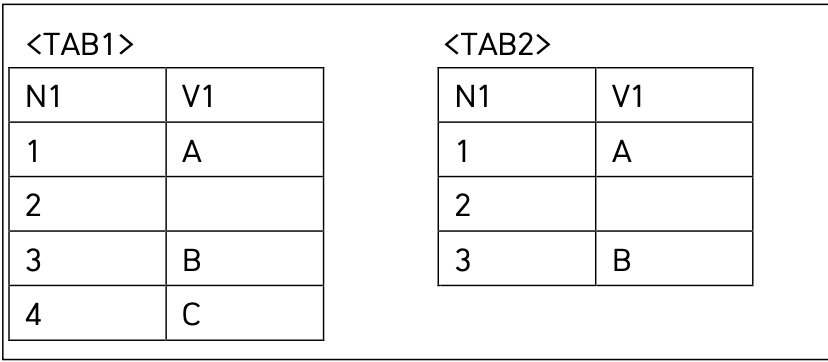
EXISTS는 서브쿼리에 값이 존재하는지를 확인하는 조건절.
주로 서브쿼리의 결과가 '존재하냐, 아니냐(참/거짓)' 를 판단하는 데 사용
where절에서 각 행을 하나씩 처리하는데 서브쿼리 안에서
한 줄 이상의 결과가 나오면 → EXISTS TRUE, 그 행은 선택됨 (출력됨)
한 줄도 안 나오면 → EXISTS는 FALSE → 제외됨
SELECT ...
FROM ...
WHERE EXISTS (
SELECT 1
FROM ...
WHERE 조건
);

2번. NOT IN 연산자는 서브쿼리 결과에 NULL이 포함될 경우 전체가 거짓이 되므로 아무것도 출력되지 않는다.
V1 NOT IN ('A', NULL, 'B', 'C')
=>NOT (V1 = 'A' OR V1 = NULL OR V1 = 'C')
=> (V1 != 'A') AND (V1 != NULL) AND (V1 != 'C')에서
V1 != NULL은 거짓이므로 이 조건으로 인해 전체 조건이 거짓이 된다.
| 조건식 | 결과 |
|---|---|
col IN (NULL) | 항상 FALSE (또는 NULL) |
col NOT IN (NULL) | 항상 FALSE (또는 NULL) |
| 👉 그래서 둘 다 | 조건을 만족하는 행 없음 |
| 오류 발생? | ❌ 아니요, 오류는 발생하지 않음 |
= NULL이나 IN (NULL)은 비교가 안 돼서 출력이 없음

4번. NOT EXISTS 연산자는 반대로 서브쿼리 결과가 거짓이면 출력된다. 따라서 NULL끼리 같은 조건은 항상 거짓이므로 TAB1의 V1이 NULL인 경우와 C가 최종 리턴된다
32 ALL
- ALL: 모든 값과 비교해서도 참이어야 TRUE → 엄격함 (AND 느낌)
- ANY/SOME: 하나라도 참이면 TRUE → 느슨함 (OR 느낌)
- IN: ANY(=) 의 간편한 표현
모든 값과 비교해서 참인것
34 count
1 -> 2
서브쿼리 결과가 항상 거짓이므로 조건에 만족하는 행이 없다.
COUNT(*)는 결과가 없으면 NULL이 아니라 0을 반환
이 경우 COUNT는 NULL이 아닌 0을 리턴한다.
35
1 ->2
고객과 서비스 구매 관계에서 고객은 필수, 서비스 구매는 선택적 관계이므로 LEFT OUTER JOIN을 하면 서비스 구매를 하지 않은 고객의 서비스 구매 정보가 NULL로 출력된다. 따라서 이때, 고객의 성별로 서비스 구매나 서비스 테이블의 컬럼을 COUNT할 경우 NULL은 세지 않기 때문에 정상적으로 구매를 한 고객 수가 리턴될텐데 2번의 경우 고객 테이블의 고객 번호를 세기 때문에 성별 고객 수가 출력된다.
36 집합 연산자(데이터 타입)
각 쿼리의 데이터 타입 일치성, 컬럼 수 일치성, 정렬 위치 등을 빠르게 체크
데이터 타입
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
VARCHAR2(n) | 가변 길이 문자 (가장 많이 사용됨). 최대 n자까지 저장 가능 | VARCHAR2(20) |
NUMBER(p,s) | 정수 또는 실수. p=전체 자리수, s=소수점 이하 자리 수 | NUMBER(7,2) → 99999.99 |
DATE | 날짜와 시간 저장 (YYYY-MM-DD HH\:MI\:SS) | '2024-06-01' |
CHAR(n) | 고정 길이 문자. 항상 n자리를 채움 (공백 포함) | CHAR(5) |
CLOB | 긴 문자열 (문서, 텍스트 등 최대 4GB까지) | 뉴스 본문, 소설 전문 저장 등 |
BLOB | 바이너리 대용량 데이터 (이미지, PDF, 영상 등) | 사진, 첨부파일 저장 |
TIMESTAMP | DATE보다 정밀한 시간 저장 (소수초까지) | '2024-06-01 13:45:32.234' |
FLOAT(p) | 부동소수점 숫자 (NUMBER의 특수형태) | FLOAT(126) |
RAW(n) | 이진 데이터 저장 (고정 길이) | RAW(2000) |
LONG | 긴 문자열 (최대 2GB, 구식/비권장) | 거의 안 씀 |
LONG RAW | 긴 이진 데이터 (구식, BLOB으로 대체됨) | 거의 안 씀 |
INTERVAL | 날짜 간격(기간) 표현 | INTERVAL '2' DAY |
VARCHAR2 vs CHAR: 가변 vs 고정 길이 → 자주 비교 출제
NUMBER(p,s): 소수점 자릿수 포함 계산 문제 출제 多
DATE vs TIMESTAMP: 시간 정밀도 차이 비교
CLOB/BLOB: 대용량 처리, LONG/LONG RAW는 구식으로 주의
집합연산자
- UNION, UNION ALL, MINUS, INTERSECT
양쪽 SELECT의 컬럼 수와 데이터 타입이 호환 가능해야한다
INTERSECT
두 쿼리 결과에서 공통된 행만 추출
중복제거가 자동으로 일어남.
union계의 join.
37 계층형 집계함수
ROLLUP
소그룹 간의 소계를 구하는 함수
함수 내부의 인자로 지정된 그룹화 칼럼 -> 소계를 생성하는 데 사용
그룹화된 칼럼의 수가 N개 -> 소계 N+1개 생성
계층 구조이기 때문에 함수 내의 인자 순서가 바뀌면 결과도 바뀌게 됨.
- ROLLUP(A,B)
: A별, (A,B)별, 전체 그룹 연산 결과 출력 (나열 대상의 순서가 중요)
(A, B)별 집계 + A별 소계 (B가 NULL로 나옴) + 전체 총계 (A, B가 둘 다 NULL)
CUBE
결합 가능한 모든 값에 대해서 다차원 집계를 구하는 함수
CUBE 함수의 인자가 N개라면 2^N 만큼의 소계가 생성
-
CUBE(region, product)
(region, product) → 실제 원래 데이터(region, NULL) → 지역별 소계
(NULL, product) → 상품별 소계(NULL, NULL) → 전체 총계
GROUPING SETS
특정 항목에 대한 소계를 구하는 함수
GROUP BY GROUPING SETS((DNAME, JOB), DNAME, NULL)
GROUP BY GROUPING SETS((DNAME, JOB), DNAME, ())
두 식은 같은 식!
39 FIRST/LAST_VALUE
3 -> 4
FIRST_VALUE, LAST_VALUE는 ORDER BY 컬럼 순서대로 범위 내 가장 처음 값과 마지막 값을 리턴하는 함수
이때 기본 범위는 RANGE UNBOUNDED PRECEDING AND CURRENT ROW(정렬 기준 컬럼의 값이 현재 값 이하인 모든 행을 대상)이다.
따라서 같은 DNAME 내 SAL 순서대로 가장 앞에 있는 이름은
아시아지부의 경우 홍길동, 남유럽지부의 경우 김길동이 된다.
하지만 각 행마다 LAST_VALUE를 구할 때 범위가 처음부터 현재 행까지만 고려해서 마지막 값을 리턴하기 때문에
항상 현재 행의 값이 마지막 값이 되므로 각 행의 값이 리턴된다.
40 TOP, FETCH, ROWNUM, RANK
TOP
-- SQL Server
SELECT TOP 3 *
FROM 테이블명
ORDER BY 컬럼 DESC;
-- 동점 포함하려면
SELECT TOP 3 WITH TIES *
FROM 테이블명
ORDER BY 컬럼 DESC;
TOP n은 ORDER BY가 필수!
WITH TIES
동점자 포함
ORDER BY 필수
TOP(2) WITH TIES 성적 : 성적 동률이 있을 경우 2등 안에 해당하면 같이 포함
FETCH
결과에서 일부 행만 가져오기
SELECT *
FROM 테이블명
ORDER BY 컬럼 DESC
FETCH FIRST 3 ROWS ONLY;
-- 기본 문법
FETCH [FIRST | NEXT] n [ROW | ROWS] [ONLY | WITH TIES]
-- offset + fetch
OFFSET 5 ROWS FETCH NEXT 3 ROWS ONLYfetch first
가장 위에서부터 n개 가져오기
offset n rows
처음부터 n개를 건너뛰고 다음부터 결과 보여줌
offset은 항상 fetch보다 먼저 와야한다
ROWNUM
SELECT *
FROM 테이블명
WHERE ROWNUM <= 3;
-- 정렬
SELECT *
FROM (
SELECT *
FROM 테이블명
ORDER BY 컬럼 DESC
)
WHERE ROWNUM <= 3;
-- 문제
④ SELECT 성적
FROM (SELECT 성적, ROWNUM AS RN
FROM EXAM
ORDER BY 성적 DESC)
WHERE RN <= 3;
정렬보다 먼저 평가되기 때문에 정렬 후 상위 n개가 필요할 때는 서브쿼리 필수
SELECT 절(rownum)이 ORDER BY절보다 먼저 수행 -> SELECT 절에서의 ROWNUM은 ORDER BY 결과를 반영하지 못한다.(높은 성적 순서랑 맞지않다)
rn 수행하면
| 성적 | ROWNUM |
|---|---|
| 75 | 1 |
| 82 | 2 |
| 88 | 3 |
| 90 | 4 |
| 95 | 5 |
order by 하면
| 성적 | ROWNUM |
|---|---|
| 95 | 5 |
| 90 | 4 |
| 88 | 3 |
| 82 | 2 |
| 75 | 1 |
성적 낮은 3명이 나오게 되는 것
3 -> 4
성적이 높은 순서대로 3명을 뽑는 쿼리로 적절한 것은 1, 2, 3번 보기이다.
2번의 경우 WITH TIES를 사용하여 동순위까지 출력하므로 98점과 함께 80점 두 명이 모두 출력된다.
하지만 ROWNUM의 경우 SELECT 절이 ORDER BY절보다 먼저 수행되므로 SELECT 절에서의 ROWNUM은 ORDER BY 결과를 반영하지 못한다. 따라서 성적이 높은순서대로 RN의 값이 형성되지 않기 때문에 원하는 결과를 얻을 수 없다.
41 계층 함수(CONNECT BY)
① CONNECT_BY_ ISLEAF
현재 노드가 말단(ISLEAF)인지 확인
자식이 없으면(말단이면)1, 있으면 0
② CONNECT_BY_ISCYCLE
계층 구조중 순환(Cycle)이 있는지 확인
순환하면 1
CONNECT BY NOCYCLE PRIOR
③ SYS_CONNECT_BY_PATH
루트부터 현재까지 경로를 문자열로 표현
④ CONNECT_BY_ROOT
최상위노드(루트)의 값을 추출
42 EXTRACT
날짜나 시간데이터에서 특정부분 추출
EXTRACT(단위 FROM 날짜값)
-- 예제
EXTRACT(YEAR FROM SYSDATE) → 현재 연도
EXTRACT(MONTH FROM 입사일자) → 입사한 달
EXTRACT(DAY FROM TO_DATE('2024-06-01', 'YYYY-MM-DD')) → 1
-- 문제
CONNECT BY PRIOR 사원번호 = 매니저사원번호
AND EXTRACT(MONTH FROM 입사일자) >= 7
부모-자식 관계를 따지면서, 자식의 입사월이 7 이상인 경우만 연결하라
어떤 자식 노드를 연결할지를 결정하는 조건이기 때문에 connect by 에 and 붙어야함.
ORDER SIBLINGS BY
같은 부모를 가진 형제노드(siblings)들끼리 정렬해주는 문법
2
매니저 사원번호가 NULL인 지점을 시작으로 레벨 1을 부여, 나사장의 사원번호를 매니저 사원번호로 가지면서 하반기 입사자인 행을 찾아 레벨 2를 부여한다. 이렇게 연결된 행으로부터 CONNECT 절의 조건을 만족하는 행을 계속 이어 나간다. 이때, START WITH 절은 CONNECT BY에 있는 조건에 따라 생략되지 않기 때문에 나사장이 상반기 입사자라도 출력된다.
44 REGEXP 정규표현식
REGEXP_COUNT
문자열 안에서 정규표현식과 매칭되는 개수를 세는 함수
REGEXP_COUNT(문자열, '정규표현식')
-- 문제
SELECT
REGEXP_COUNT('abc1004 zz1234', '\d{2}+') AS C1,
REGEXP_COUNT('abc1004-zz1234-100', '\d{2,}+') AS C2
FROM DUAL;
\d{2}+
\d : 숫자 (0~9)
{2}+ : "숫자 2개 이상"
\d{2}+는 사실상 \d{2,} 또는 \d\d+와 동일하게 처리
1004, 1234
1004, 1234, 100
| 패턴 | 의미 | 예시 설명 |
|---|---|---|
* | 0번 이상 반복 | a* → "", "a", "aa", "aaa"... |
+ | 1번 이상 반복 | a+ → "a", "aa", "aaa"... |
? | 0번 또는 1번 (있어도 되고 없어도 됨) | a? → "", "a" |
{n} | 정확히 n번 반복 | a{2} → "aa"만 매치 |
{n,} | 최소 n번 이상 반복 | a{2,} → "aa", "aaa", "aaaa"... |
{n,m} | n~m번 사이 반복 | a{2,4} → "aa", "aaa", "aaaa" |
2
둘 다 숫자(\d)가 2회 이상 나열된 단어의 수를 찾는 문제이므로 C1은 2, C2는 3개가 리턴
45 REGEXP_LIKE + 정규표현식의 문자 클래스 + 수량자
REGEXP_LIKE
문자열에 정규표현식 패턴이 하나라도 "부분적으로" 매치되면 TRUE
REGEXP_LIKE(문자열, '정규표현식')
--문제
SELECT COUNT(COL1)
FROM TAB1
WHERE REGEXP_LIKE(COL1, '[XY-]+Z?');
-
[XY-]+
X, Y, - 중 하나 이상 반복 -
Z?
Z가 있을 수도 있고, 없을 수도 있음 (0번 또는 1번)
=> X, Y, -가 반복되고 그 뒤에 Z가 0개나 1개 있는 문자열 조각
| COL1 | 매칭 여부 분석 |
|---|---|
| AAXYXY-Z | 앞의 AA는 안 맞지만 → XYXY-가 [XY-]+에 매칭됨 → Z도 있음 → ✅ |
| XXYYZ | XXYY는 [XY-]+, Z는 Z? → 완벽 매칭 → ✅ |
| XY- | XY-는 [XY-]+, Z 없어도 OK → ✅ |
| XY-Z | XY-는 [XY-]+, Z는 Z? → ✅ |
| XY-+? | XY-는 OK지만, +?는 패턴에 없음 → 문자열 전체에 매치되는 부분 없음 → ❌ |
-
"XY-+?"
XY- → ✅ [XY-]+에는 잘 맞음
다음 글자 + → ❌ [XY-]에 속하지 않음
?도 마찬가지로 ❌+?는 패턴에 없음 → 문자열 전체에 매치되는 부분 없음
1 -> 4
[XY-]는 X 또는 Y 또는 -와 같다. 따라서 X, Y, - 중 하나가 여러 번 반복되면서 그 뒤에 Z값이 오거나 오지 않는 문자열 배열을 갖는 행은 전체이므로 총 5개가 출력된다.
46 update set
본쿼리 where을 먼저 확인할것!!!!!
4 -> 3
전체 평균(4000)보다 급여가 낮은 직원들의 급여만 수정되므로 김길동 두 명의 급여는 수정되지 않는다. SET절은 각 행의 급여 수정 시 부서명을 확인하여 서브쿼리에서 해당 부서의 최대 급여를 찾아 수정하는 구문이다. 따라서 아시아지부는 모두 3000으로, 남유럽지부는 8000으로 수정된다.
47 ROLLBACK / COMMIT
✅ SAVEPOINT는 중간 저장이 아니라, "중간 되돌리기용 북마크"일 뿐이고, COMMIT이 돼야 진짜 최종 저장
| 구문 | 의미 |
|---|---|
COMMIT | 지금까지 한 모든 작업을 최종 저장 (다시는 롤백 불가) |
ROLLBACK | COMMIT하지 않은 모든 작업 취소 (마지막 COMMIT 상태로 되돌림) |
SAVEPOINT | 중간 저장 아님! 그냥 중간 롤백을 위한 포인트 |
ROLLBACK TO SAVEPOINT | 해당 지점까지만 취소하고, 그 전 작업은 유지 |
4 -> 2
첫 INSERT문장은 COMMIT했기 때문에 영구 저장된다. 그 이후 UPDATE, INSERT, DELETE를 차례대로 하지만 SAVE1 지점으로 롤백하므로 INSERT와 DELETE는 실행 취소된다.
첫 UPDATE문장과 마지막 UPDATE문장은 모두 롤백되어 결과적으로는 첫 INSERT문장만 실행된다. 따라서 남은 행의 SUM(COL2) 결과는 11이다.
48 비교연산자(문자열)
2 -> 4
길이가 다른 경우 길이가 같을 때까지 비교하여 모두 값이 같다면 길이가 큰 문자열을 더 큰 값으로 판단한다.
① 서로 다른 문자가 나올 때까지 비교한다
② 길이가 다르다면 짧은 것이 끝날 때까지만 비교한 후에 길이가 긴 것이 크다고 판단한다
③ 길이가 같고 다른 것이 없다면 같다고 판단한다
