SQLD 4회차 2과목 오답
11 테이블
① 같은 테이블을 동시에 두 계정으로 소유할 수 없다. 하나의 테이블은 반드시 한 계정의 소유여야 한다.
② 테이블명은 중복될 수 없지만, 소유자가 다른 경우 같은 이름으로 생성 가능하다.
③ 하나의 행의 하나의 컬럼에는 반드시 하나의 값만 삽입되어야 한다.
④ 테이블 생성 시 각 컬럼의 데이터 유형을 정의할 수 있고, 생성 이후에는 ALTER 명령어로 변경 가능하다.
14 오류찾기
-- 오류
SELECT T.COL2, SUM(T.COL1), SUM(T.COL3)
FROM TAB1 T
GROUP BY T.COL2
ORDER BY T.COL3;
-- 수정하면
ORDER BY SUM(T.COL3); -- 실행
GROUP BY 절에 포함되지 않은 컬럼으로 정렬할 수 없다. 또한, 컬럼 별칭을 ORDER BY 절에 사용할 경우 컬럼 별칭 앞에 테이블명이나 테이블 별칭을 붙일 수 없다.
15 POWER
power은 거듭제곱을 계산하는 함수.
POWER(밑, 지수)POWER(3,3) 는 3의 3 거듭제곱, 27이 리턴된다.
LAST_DAY는 지정된 날짜가 속한 달의 마지막 날짜를 리턴한다.
17 시간
SELECT ROUND(TO_DATE('2024-08-24 12:00:00','YYYY-MM-DD HH24:MI:SS')) COL1,
ROUND(TO_DATE('2024-08-24 12:00:01','YYYY-MM-DD HH:MI:SS')) COL2
FROM DUAL;
HH24는 24시간 표현식이고, HH는 12시간 표현식이다.
시간은 정오를 기준으로 반올림 시 자리수가 바뀌는데, 둘 다 정오를 나타내므로 반올림 시 일(DAY)의 자리가 바뀌며 24년 8월 25일이 리턴된다.
20 -2 EXISTS
SELECT COUNT(COL1)
FROM TAB1
WHERE NOT EXISTS (
SELECT 'X'
FROM TAB2
WHERE TAB1.COL2 = TAB2.COL2
);
TAB1의 각 행마다 TAB2에서 TAB1.COL2 = TAB2.COL2를 만족하는 행이 있는지 검사하고, 없는 경우만 카운트
EXISTS나 NOT EXISTS는 “서브쿼리에서 행이 하나라도 나오면 TRUE, 아니면 FALSE”를 판단하는 용도
X는 아무 의미 없는 상수값. (존재 여부를 확인하는 거기 때문에 무슨 값을 쓰든 상관없음)
- TAB1의 A (COL2 = 1): TAB2에서 COL2 = 1인 행? ❌ 없음 → NOT EXISTS → ✅ 카운트
- TAB1의 B (COL2 = 2): TAB2에서 COL2 = 2인 행? ✅ 있음 → NOT EXISTS → ❌ 제외
NOT EXISTS는 서브쿼리 조건이 거짓인 경우 메인쿼리의 결과가 출력된다.
따라서 TAB2의 COL2와 일치하지 않는 값은 1이며, NULL은 TAB1과 TAB2가 모두 존재하지만 EQUAL(=) 연산 결과가 항상 거짓이므로, NOT EXISTS에 의해 출력된다.
따라서 COUNT 결과는 2이다.
21 count() 0 or null
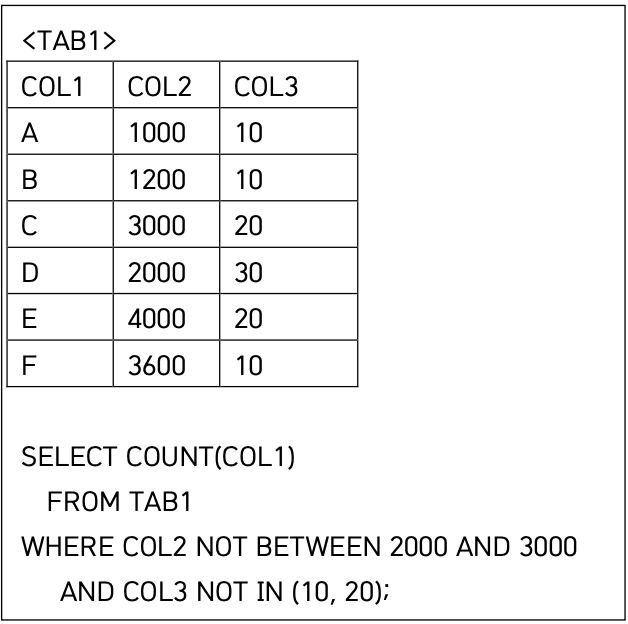
하 같은유형 몇번을 틀리는지..
COUNT()는 조건을 만족하는 행이 없으면 0을 반환한다.
👉 NULL이 아님!
2000과 3000사이 값이 아니면 2000미만, 3000초과가 된다. 이들 중 COL3이 10, 20과 일치하지 않는 행은 존재하지 않는다. 따라서 COUNT 결과는 0이다.
조건에 만족하지 않더라도 COUNT는 NULL이 아닌 0을 리턴한다.
카운트는 절대 null을 반환하지않는다!!!!!!!
22 group by - null
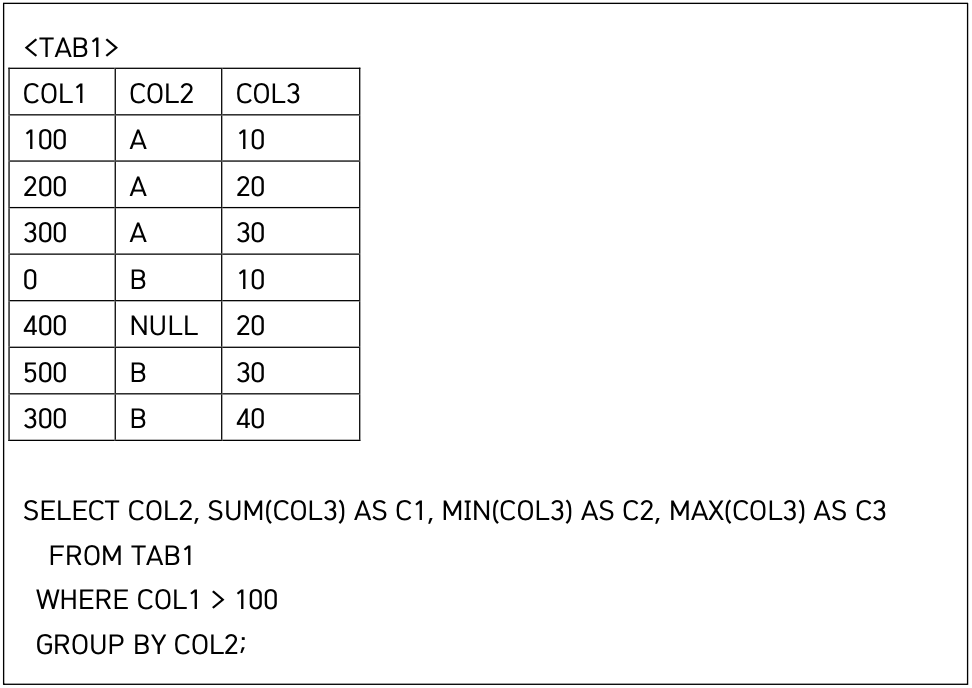
null값이 제일 마지막에 나와야하는게 아니었나?
order by가 들어가면 맞지만, 그냥 group by에서는 아무렇게나(랜덤) 나온다..
23 order by case when
ORDER BY 안에 들어간 CASE문이 정렬 우선순위를 인위적으로 바꾸고 있다

SELECT ID
FROM TAB1
ORDER BY CASE
WHEN ID > 'B' THEN 'A'
ELSE ID
END,
ID;
-
CASE WHEN ID > 'B' THEN 'A' ELSE ID END
ID > 'B'인 경우 → 'A'로 치환, 그 외에는 → 원래 ID 유지
즉, 'B'보다 큰 문자열은 모두 'A' 취급하고 정렬
→ 'A', 'AA', 'ABC' 같은 ID가 'B'보다 작으니까 그대로
→ 'BI', 'BAA' 등은 'B'보다 크기 때문에 'A'로 처리됨 -
ORDER BY CASE ~ END, ID: 1순위 case when, 2순위 id로 정렬
문자 B보다 큰 ID는 BI와 BAA이다. 따라서 ID 는 CASE문에 의해 순서대로 AA, ABC, A, B, A 변환되어 두번째 정렬 기준인 ID 값과 함께 정렬된다. 문자 정렬은 왼쪽부터 비교하여 값이 같을 때까지 비교하여 더 큰 값이 큰 문자열이 되므로 최종 정렬 결과는 정렬 결과는 A(BAA), A(BI), AA, ABC, B 가 된다.
24 -3
-- 2번
FROM 회원
LEFT OUTER JOIN 이용내역
ON 회원.회원번호 = 이용내역.회원번호
JOIN 상품 -- 이용 내역 있는데 상품 테이블에 없는 상품번호는 누락
ON 이용내역.상품번호 = 상품.상품번호
-- 상품이 없는 경우를 배제하기 때문에 틀렸음
-- 3번
FROM 회원
LEFT OUTER JOIN 이용내역 -- 회원이 이용내역 없어도 나옴
ON 회원.회원번호 = 이용내역.회원번호
LEFT OUTER JOIN 상품 -- 이용내역o, 상품x 나옴
ON 이용내역.상품번호 = 상품.상품번호
-- 4번
SELECT 회원.회원번호, COUNT(상품.상품번호), SUM(상품.가격)
FROM 회원, 이용내역, 상품
WHERE 회원.회원번호 = 이용내역.회원번호(+)
AND 이용내역.상품번호 = 상품.상품번호
GROUP BY 회원.회원번호;
--상품에 없는 상품번호는 배제됨
ERD를 보면, 회원과 이용내역은 1대 다 관계이고 회원 -> 이용내역이 선택적 관계이다.
즉, 한 고객이 이용을 하지 않을 수 있기 때문에 상품을 이용하지 않은 고객까지 출력을 원한다면 OUTER JOIN이 수행돼야 한다.
또한 회원 엔터티 기준으로 이용내역이 선택적 관계이면 상품관계 또한 회원 엔터티 입장에서 선택적이다(이용내역이 없으면 이용 상품도 없기 때문) 따라서 상품 테이블도 OUTER JOIN이 수행돼야 한다.
따라서 가장 적절한 것은 3번이다. 4번의 경우 두 번째 조인조건에서 상품.상품번호 뒤에도 (+)를 붙여야 상품 테이블에도 OUTER JOIN이 연산된다.
32 NVL
NVL(a,b): a가 Null이면 b값 표기
아 진짜 언제까지틀릴래 ㅜㅜㅜㅜ
스칼라 서브쿼리는 OUTER JOIN을 수행하지 않아도 연결 조건에 만족하지 않는 행도 출력된다.
name = d, code null일때 scalar에서는 NULL을 반환 (code일치하는게 없으니까)
NVL로 NULL을 100으로 치환하고 있으므로 D의 PRO_FARE는 100으로 리턴
33 집합연산자
① 두 집합의 컬럼 수가 일치해야 한다.
② 두 집합의 각 컬럼의 데이터 유형이 일치해야 한다.
③ 두 집합 중 위의 집합의 컬럼명을 전체 집합의 컬럼명으로 가져간다.
④ 두 집합의 컬럼 사이즈는 달라도 집합 연산이 가능하다.
34 GROUPING SETS
DEPTNO별, JOB별, 전체 소계를 출력하는 함수는 GROUPING SETS(DEPTNO, JOB, NULL) 이다.
(DEPTNO, NULL)
(NULL, JOB)
(NULL, NULL)
35 LAG
LAG (컬럼명, n, 기본값)
n : 몇 행 이전을 참조할 것인가
기본값: 이전 행이 없을 경우 대신 사용할 값(기본 null)
LAG(SAL, 2, 0) : SAL행의 2행 이전값을 참조하는데, 이전 행이 없다면 0 으로.
37 CUME_DIST()
Cumulative누적 Distribution분포
RATIO_TO_REPORT는 총 합 기준 COL2의 값의 크기에 대한 차지 비율을 출력,
CUME_DIST는 COL2 순서대로 각 행의 상대적 누적 위치 출력,
PERCENT_RANK는 COL2 순서대로 각 행의 누적 분위수(0~1 사이)를 출력한다.
-
CUME_DIST() OVER(ORDER BY COL2)→ 누적분포
현재 행 이하의 개수 / 전체 행 수
col2의 값이 작을수록 낮은 위치, 값이 클수록 1에 가까워짐 -
PERCENT_RANK()→ 백분위 순위
(현재 행 순서 - 1) / (전체 행 수 - 1)
첫 행은 무조건 0, 마지막 행은 1
38 NTILE window function
n-tile
NTILE(n) OVER (PARTITION BY ... ORDER BY ...)
전체 데이터를 n개의 균등한 그룹으로 나눔
GN(group number) = 1 → 하위 그룹, GN = 2 → 상위 그룹 (2개로 나누니까)
앞쪽그룹부터 1,2,3,..., 순서대로 번호를 매김
SELECT SUM(SAL)
FROM (
SELECT ENAME, DEPTNO, SAL,
NTILE(2) OVER(PARTITION BY DEPTNO ORDER BY SAL) AS GN
FROM EMP
)
WHERE (DEPTNO = 10 AND GN = 1)
OR (DEPTNO = 20 AND GN = 2);
deptno별로 그룹을 나눈 후, 2개의 균등한 그룹으로 나누는 것.
그룹으로 나눌 때 명학히 나눠지지 않으면 앞 그룹의 크기를 더 크게 나누므로 10번 부서의 1번 그룹원은 MILLER, CLARK이며, 20번 부서의 2번 그룹원은 SCOTT과 FORD 이므로 1300 + 2450 + 3000 + 3000 = 9750 이 된다.
43 REGEXP_replace
SELECT REGEXP_REPLACE('031-234-4567', '\d+', 'XXX', 1, 2) FROM DUAL;
031-XXX-4567
문자열 처음부터 찾아서 두 번째로 발견되는 숫자의 연속 문자열을 XXX로 치환하면 031-XXX-4567 이 리턴된다.
44 REGEXP_SUBSTR
REGEXP_SUBSTR(source, pattern, position, occurrence, match_parameter, subexpr)
occurrence: 몇 번째 매치를 찾을지
match_parameter: 대소문자 구분 등 옵션 (보통 NULL)
subexpr: 괄호로 감싼 몇 번째 그룹(캡처 그룹)을 추출할지 지정
SELECT REGEXP_SUBSTR('123-234-4545-233', '((\d+)-(\d+))-((\d+)-(\d+))', 1, 1, NULL, 4) FROM DUAL;
| 그룹 번호 | 설명 | 원본: '123-234-4545-233' |
|---|---|---|
| 전체 | 전체 패턴 매치 | '123-234-4545-233' |
| (1) | ((\d+)-(\d+)) → 앞쪽 덩어리 | '123-234' |
| (2) | \d+ → 123 | |
| (3) | \d+ → 234 | |
| (4) | ((\d+)-(\d+)) → 뒤쪽 덩어리 | '4545-233' |
| (5) | \d+ → 4545 | |
| (6) | \d+ → 233 |
서브그룹을 추출하는 문제이다.
서브그룹 순서는 ((A)-(B))-((C)-(D))에서 A-B -> A -> B -> C-D -> C -> D 순서대로 정해진다. 따라서 4번째 서브그룹은 뒤에 두 숫자집합의 결합인 4545-233 가 된다.
46 COMMIT / ROLLBACK
① COMMIT을 한 이후에는 ROLLBACK을 수행해도 이전 값으로 돌아갈 수 없다.
② INSERT 한 이후 컬럼 추가 시 INSERT 값은 자동 저장되어 ROLLBACK 할 수 없다.
Insert는 DML이지만, 컬럼추가(alter)는 DDL.
DDL 특징: 즉시 commit
③ ROLLBACK을 한 명령을 다시 ROLLBACK으로 취소할 수 없다.
④ SAVEPOINT 지점이 COMMIT 이전일때 해당 SAVEPOINT까지 ROLLBACK 시도 시 ROLLBACK 명령어 자체가 에러가 발생한다.
예제
1 SELECT * FROM EMP_T1;
2 SAVEPOINT SP1;
3 DELETE FROM EMP_T1 WHERE JOB = 'CLERK';
4 COMMIT;
5 INSERT INTO EMP_T1 VALUES(1111,'PARK','CELRK',1112,SYSDATE, 8000, NULL, 20);
6 ROLLBACK TO SP1;이렇게 있다고 가정할 때 6번의 ROLLBACK TO SP1; 을 실행하게 되면 COMMIT이후 5번의 문장이 ROLLBACK되는 것이 아니라 ROLLBACK 에러 문구가 발생합니다. 즉 5번 문장은 실행이 그대로 되어 있습니다.
뜬금포 복기
✅ DELETE: 행의 "값" 하나 삭제
✅ TRUNCATE: 구조는 남김
✅ DROP: 구조까지 삭제
48 테이블 복제
① CREATE TABLE 테이블명 AS SELECT 문으로 테이블 복제가 가능하다.
CREATE TABLE NEW_EMP AS
SELECT * FROM EMP;
EMP의 구조(컬럼명, 데이터 형식 일부)와 데이터가 복제됨.
단, 제약조건은 복제되지 않음
② 테이블 복제 시 컬럼 순서 및 데이터 유형도 복제된다.
③ 테이블에 생성한 PRIMARY KEY 도 함께 복제된다.
PRIMARY KEY, UNIQUE, FOREIGN KEY, CHECK 같은 제약조건은 복제되지 않음.
④ PRIMARY KEY 나 UNIQUE 설정 없이 부여된 NOT NULL 속성은 함께 복제된다.
