SQLD 5회차 오답
19문제 틀려서 합격..
아악 제발 본시험때도 이렇게 합격하게 해주세요..
1 스키마
스키마 : DB설명서
- 외부 스키마
- 사용자가 보는 관점에서 데이터베이스 스키마를 정의
- 사용자나 응용 프로그램이 필요한 데이터를 정의(View : 사용자가 접근하는 대상)
--논리
- 개념 스키마
- 사용자 관점의 데이터베이스 스키마를 통합하여 데이터베이스의 전체 논리적 구조를 정의
- 전체 데이터베이스의 개체, 속성, 관계, 데이터 타입 등을 정의
--물리
- 내부 스키마
- 데이터가 물리적으로 어떻게 저장되는지를 정의
- 데이터의 저장 구조, 컬럼, 인덱스 등을 정의함
4 엔터티 사이 관계 고려
관계 : 엔터티간의 연관성을 나타낸 개념
① 두 개의 엔터티 사이에 정보의 조합이 발생되는가?
② 두 개의 엔터티 사이에 관련 있는 연관규칙이 존재하는가?
③ 업무기술서, 장표에 관계연결에 대한 규칙이 서술되어 있는가?
④ 업무기술서, 장표에 관계연결을 가능하게 하는 동사가 있는가?
-> 행위적 관계
5 주식별자 특징
주식별자의 특징은 유일성, 최소성, 불변성, 존재성 이다
① 유일성 : 주식별자에 의해 모든 인스턴스 유일하게 구분
② 최소성 : 주식별자는 유일성을 만족하는 최소한의 속성으로 구성.
③ 불변성 : 주식별자가 지정되면, 그 값은 변하지 않는다(고유값으로 항상 존재)
④ 존재성 : 주식별자 지정시 반드시 값이 존재(NULL 안됨)
6. 정규화
제1 : 하나에 하나, 반복제거
제2 : 완전함수종속
제3 : 이행적 종속 제거
BCNF : 결정자가 후보키
제4 : 다중값 종속 제거
제5 : 조인에 의한 종속성 분해
10 식별자
① 업무에 의해 만들어지는 식별자를 본질식별자라고 한다.
업무에 없던걸 새로 만드는거(업무적 무의미)게 인조식별자고,
업무에 의해 만들어지는 것(업무적 유의미)은 본질이 맞다
② 꼭 필요하지 않지만 관리의 편이성 등의 이유로 인위적으로 만들어지는 식별자를 인조식별자라 한다.
③ 본질식별자가 복잡한 구성을 가질 때 주로 인조식별자를 생성한다.
④ 인조식별자를 사용하면 중복 데이터 발생 가능성이 있어 데이터 품질이 저하된다.
11 데이터 무결성
데이터 무결성 종류
① 개체 무결성 : 테이블의 기본키를 구성하는 컬럼(속성)은 NULL 값이나 중복값을 가질 수 없음
② 참조 무결성 : 외래키 값은 NULL 이거나 참조 테이블의 기본키 값과 동일해야 한다.
(외래키란 참조 테이블의 기본키에 정의된 데이터만 허용되는 구조이므로)
③ 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값 이어야 함
④ NULL 무결성 : 특정 속성에 대해 NULL 을 허용하지 않는 특징
⑤ 고유 무결성 : 특정 속성에 대해, 값이 중복되지 않는 특징
⑥ 키 무결성 : 하나의 릴레이션(관계)에는 적어도 하나의 키가 존재해야 함
(테이블이 서로 관계를 가질 경우 반드시 하나 이상의 조인키를 가짐)
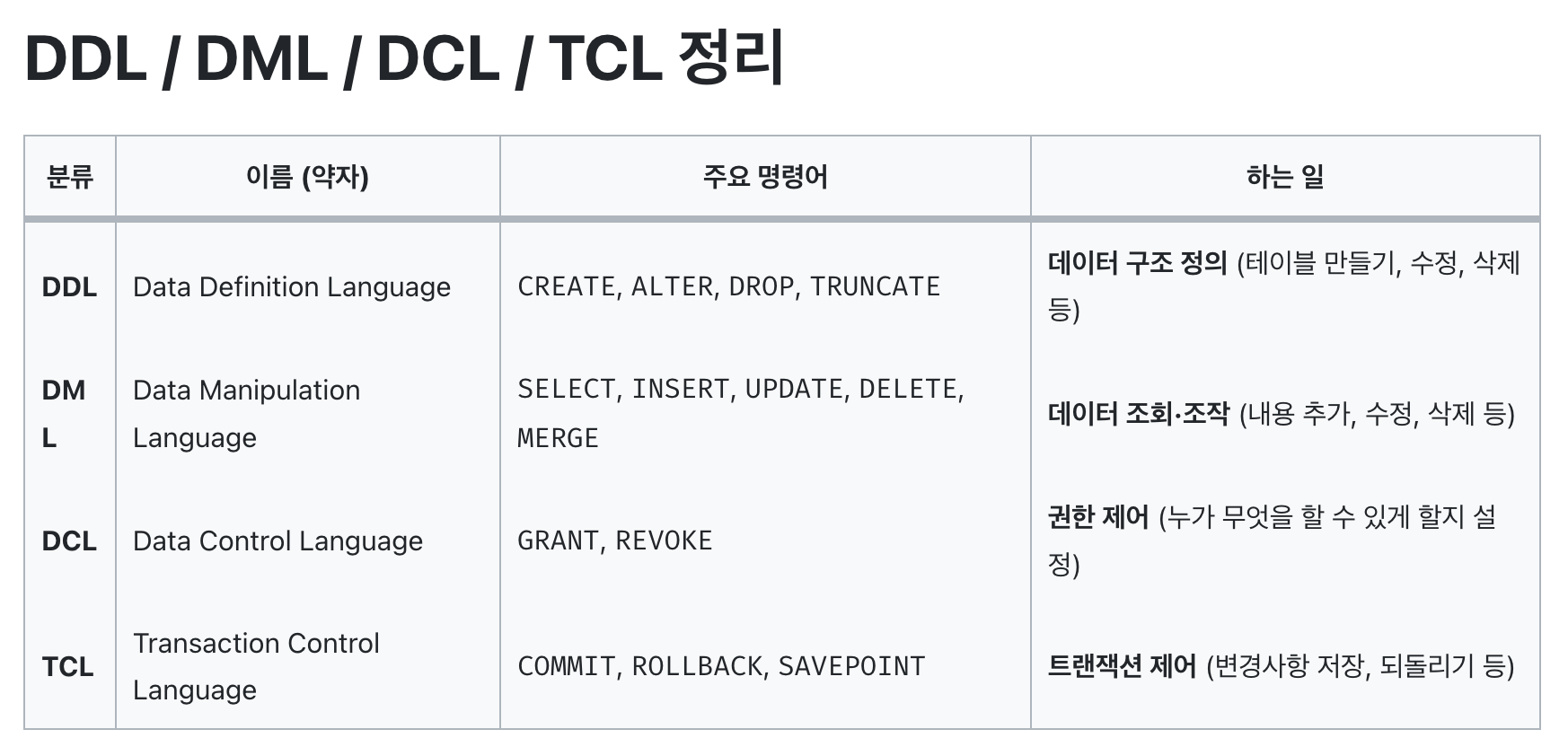
13 SQL 분류
17 문자열 함수
- ② SUBSTR('Sql Developer', -5, 2) : lo
SUBSTR(string, position, length)문자열의 특정 위치부터 길이만큼 잘라냄.
position이 음수일 경우 뒤에서부터 시작, length는 음수와 상관없이 오른쪽으로.
- ④ RTRIM('ABCAA', ‘A’) : BC
RTRIM(string, trim_characters)
RTRIM('ABCAA', 'A') 오른쪽 끝에서부터 trim_characters에 해당하는 문자들을 제거
한 글자씩 개별적으로 판단. 연속된 글자만 제거하는 것이 아니다
오른쪽 끝부터 A 제거 -> ABC
22 GROUP BY
① GROUP BY 절에는 컬럼 별칭을 사용할 수 없다.
② GROUP BY 뒤의 컬럼 순서는 그룹을 결정하는데 영향을 주지 않는다.
결과적으로 GROUP BY에 나열되는 컬럼들의 값들이 모두 같으면 하나의 그룹이 되기 때문에 GROUP BY A, B 나 GROUP BY B,A이나 두 컬럼의 값이 같은 그룹은 동일
③ GROUP BY 뒤의 첫 번째 값이 UNIQUE한 경우 뒤에 어떤 컬럼을 추가적으로 명시해도 그룹의 수는 변화없다.
첫번째 컬럼이 이미 모든 행마다 고유함.
=> 나머지 어떤 컬럼으로 묶든 어차피 한줄로 나옴
④ GROUP BY 절에 사용하지 않은 컬럼은 SUM과 같은 집계함수와 함께 SELECT절에 사용 가능하다.
30 순수 관계 연산자(기본vs일반)
🔹 순수 관계 연산자(Pure Relational Operators)
→ 관계 대수의 기본적이고 이론적인 연산자들로 집합 이론 기반이며 일반 SQL 함수보다 더 원초적인 조작 도구
| 순수 관계 연산자 | 설명 |
|---|---|
| SELECT (σ) | 조건에 맞는 튜플(행) 선택 |
| PROJECT (π) | 특정 속성(열)만 선택 |
| RENAME (ρ) | 릴레이션이나 속성의 이름 바꾸기 |
| UNION (∪) | 두 릴레이션의 합집합 |
| SET DIFFERENCE (−) | 두 릴레이션의 차집합 |
| CARTESIAN PRODUCT (×) | 두 릴레이션의 모든 조합 생성 |
| JOIN | PRODUCT와 SELECT의 조합 |
| DIVISION (÷) | 일부 속성에 대해 공통적으로 연결된 튜플 찾기 |
② DIVISION : 공통 연결 튜플 구하기 (÷)
순수 관계 연산자는 릴레이션의 구조와 특성을 이용하는 연산자로 SELECT, PROJECT, JOIN, DIVISION이 있다.
33 서브쿼리 - 다중행 vs 다중컬럼
② 다중행 서브쿼리(결과 여러 행 반환)는 단순한 비교연산자(=, <, >)를 사용할 수 없다
대신 in, any, all같은 다중행 연산자 사용.
④ 다중컬럼 서브쿼리의 SELECT절에 사용된 컬럼은 메인쿼리 SELECT절에 전달할 수 없다.
다중컬럼 서브쿼리(Multiple-column subquery)
SELECT절에 여러 컬럼을 포함한 서브쿼리로 조건절(WHERE, IN 등) 에서 튜플 비교 형태로 사용 가능
하지만! 메인쿼리의 SELECT절에서 직접 가져오는 건 불가능
서브쿼리는 SELECT절에서 하나의 값(스칼라)만 반환해야하기 때문이다.
2 / 4
다중컬럼 서브쿼리는 메인쿼리의 FROM 절이 아닌 WHERE 절에서 비교 상수로서 사용되므로 메인쿼리에서 사용할 수 없다.
35 차집합 / 불포함 조건
SELECT *
FROM TAB1, TAB2
WHERE TAB1.COL1 != TAB2.COL1;
TAB1과 TAB2를 카티션 조인한거기 때문에 모든 조합 중에서 값이 다른 경우 전부를 출력
=> 원래보다 훨씬 많은 중복결과 + COL1이 null인 경우 비교 x -> 누락
보기 2번의 경우 각 행마다 COL1의 값과 같지 않은 값을 COL2에 선택하기 때문에 TAB1의 B, C, D의 TAB2의 두행이 모두 선택되어 출력된다.
37 SUM WINDOW FUNCTION

SUM(컬럼) OVER(PARTITION BY 그룹컬럼 ORDER BY 정렬컬럼)
SUM(COL2) OVER(PARTITION BY COL1 ORDER BY COL2)
sum(컬럼)하면 누적합이 나옴..!!
→ 기본적으로는 COL1으로 그룹 나눈 후, COL2 기준 정렬해서 누적합을 구하지만 여기서 COL2 값이 같은 행들끼리는 “같은 누적합”을 공유해
📌 order BY만 있을 경우, TIES(같은 값) 간에는 동일한 누적합 결과가 적용
40 논리연산자 순서
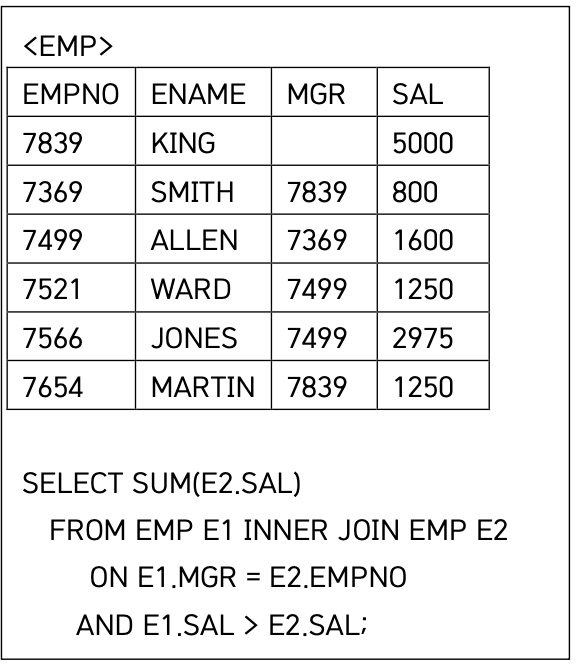
sum(e2.sal)은 상사급여!!! 사원급여가 아니다 ㅠㅠ 정신차리길 ~
41 계층형 질의 ORDER SIBLINGS
SELECT LEVEL, EMPNO, ENAME
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR
-
START WITH: 루트 노드 지정 (최상위 부모)
-
CONNECT BY: 부모-자식 관계 지정 (어떻게 연결되는지)
② 행의 연결관계는 CONNECT BY에 전달한다. -
LEVEL: 계층의 깊이 표시
-
ORDER SIBLINGS BY: 같은 LEVEL(형제노드)끼리 정렬
계층형 질의에서는 일반 Order by로 정렬이 안됨.
order siblings by 사용!!
④ 같은 레벨일 경우 추가 정렬을 원한다면 ORDER BY에 컬럼명을 나열하면 된다.
42 PIVOT
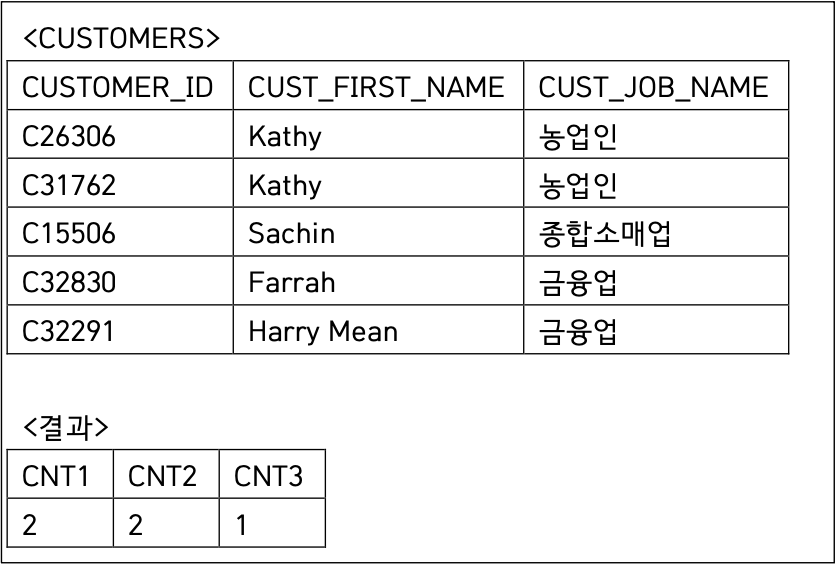
SELECT ...
FROM 원본테이블
PIVOT (
집계함수(집계대상컬럼)
FOR 기준컬럼 IN (값1, 값2, 값3...)
)
-- 문제
SELECT "'금융업'" AS CNT1, "'농업인'" AS CNT2, "'종합소매업'" AS CNT3
FROM (
SELECT CUST_JOB_NAME
FROM CUSTOMERS
)
PIVOT (
COUNT(CUST_JOB_NAME) FOR CUST_JOB_NAME IN ('금융업','농업인','종합소매업')
);
집계컬럼과 기준컬럼이 같음 -> 중복적이고 의미없음
Count는 1씩 세기 때문에 중복값도 구분 x
43 REGEXP REPLACE
REGEXP_REPLACE(문자열, 정규표현식, 바꿀값)
SELECT REGEXP_REPLACE('ABCCCAC BC BBBC', 'AB|C+') FROM DUAL;
바꿀값을 지정하지 않는다면 제거가 됨
삭제!!! 하 원래 replace는 바꾸는거 아니었냐고.... 언제부터 니가 제거였는데..
AB|C+ 는 "AB" 또는 C가 1회 이상 연속된 문자열을 나타내므로 이를 모두 삭제하면 A B BBB만 남게된다.
44 REGEXP_SUBSTR
SELECT REGEXP_SUBSTR('HDATALAB_1@NAVER.COM', '__________') FROM DUAL;-
① (\w|_)+
\w는 영문자+숫자+밑줄 -
② [A-z_0-9]+
순서는 중요하지 않음. 대괄호 [] 안은 "이 중 하나"라는 의미니까, [A-z_0-9]나 [0-9_A-z]나 [z0-9A-_]나 결과는 동일하게 작동
[A-z] : [ \ ] ^ _ 등의 특수문자 + 알파벳정확하게 쓰려면 [A-Za-z0-9_]
-
③ ([[:alnum:]]|_)+
[:alnum:]은 POSIX 클래스 → 알파벳 + 숫자
POSIX(POrtable Operating System Interface)
: 유닉스 기반 시스템에서 정의한 규칙
범주로 묶인 문자집합을 표현하는 방식
[:alnum:]: 알파벳 + 숫자, [A-Za-z0-9]
[:alpha:] : 알파벳만, [A-Za-z]
[:digit:] : 숫자만, [0-9]
- ④ \w|\d+
\w는 한 글자만 매치
\d+는 숫자 여러 개
=> 한 글자짜리 영문자/숫자/밑줄
전체 이메일 아이디 덩어리를 못 잡고 한 글자나 숫자 덩어리만 추출할 수도 있음
\w|\d+에서 + 범위는 \d에만 적용된다. 따라서 한 글자의 단어 또는 숫자의 연속을 나타내므로 H 만 출력된다.
46 TCL
CREATE TABLE TAB1(NO NUMBER, NAME VARCHAR2(10));
-- 테이블 생성
INSERT INTO TAB1 VALUES(1, 'A');
INSERT INTO TAB1 VALUES(2, 'B');
COMMIT;
-- 여기까지 저장됨: (1, 'A'), (2, 'B')
UPDATE TAB1 SET NAME = 'C' WHERE NO = 2;
-- 아직 COMMIT 안 됨 → 임시 작업 중
SAVEPOINT SAVE1;
-- 여기서 저장점 설정 (작업 기억해둠)
INSERT INTO TAB1 VALUES(3, 'C');
-- 아직 COMMIT 안 됨
COMMIT;
-- 현재까지 변경사항 모두 확정!
-- (1, 'A'), (2, 'C'), (3, 'C') 저장됨
DELETE FROM TAB1 WHERE NO = 1;
-- 1번 행 삭제 (아직 COMMIT 안 함)
ROLLBACK TO SAVE1;
-- SAVE1 지점으로 되돌아감
-- 즉, 삭제(DML)도, SAVE1 이후 COMMIT도 무효 ❌
ROLLBACK;
-- 전체 트랜잭션을 이전 COMMIT 이후로 되돌림
save point는 트랜잭션 내부에서만 유효, commit하면 그 이전의 savepoint 무의미
COMMIT → 트랜잭션 종료 → 이전 SAVEPOINT 무효
ROLLBACK TO SAVE1은 트랜잭션 내부에서만 작동
ROLLBACK은 가장 마지막 COMMIT 이후로만 돌아감
47 DML vs DDL 구분
① TRUNCATE는 데이터 삭제 시 즉시 반영되는 DDL이다.
📌 DML: INSERT, UPDATE, DELETE
📌 DDL: CREATE, DROP, ALTER, TRUNCATE
② DELETE는 COMMIT을 하기 전까지는 삭제된 데이터를 삭제 전으로 다시 되돌릴 수 있다.
③ DROP은 테이블의 구조를 삭제하기 때문에 삭제된 이후에 테이블 조회가 불가능하다.
④ TRUNCATE는 일부 데이터만을 삭제할 수 없다.
전체 테이블을 날리는거기 때문에 where조건을 걸더라도 삭제할 수 없다(일부데이터만 삭제하는 것은 delete)
48 제약조건 생성 순서
| 제약조건 | 설명 | 예시 구문 |
|---|---|---|
NOT NULL | NULL 허용 안 됨 | 컬럼명 데이터타입 NOT NULL |
UNIQUE | 중복 불가 | 컬럼명 데이터타입 UNIQUE |
PRIMARY KEY | NOT NULL + UNIQUE | PRIMARY KEY(컬럼) |
FOREIGN KEY | 외래 키 | FOREIGN KEY (컬럼) REFERENCES 다른테이블(컬럼) |
CHECK | 조건 제한 | CHECK (급여 > 0) |
CREATE TABLE TAB1(
NO NUMBER PRIMARY KEY,
NAME VARCHAR2(10) NOT NULL
);
ALTER TABLE TAB1
ADD JDATE DATE NOT NULL DEFAULT SYSDATE;
alter table not null에서 기존 데이터가 있으면 문제발생
DEFAULT를 지정했더라도, NOT NULL은 ALTER에서 바로 줄 수 없다.
ADD 컬럼 시엔 NOT NULL은 조심! → 바로 주면 안 되는 경우 많음
4번 문장은 NOT NULL과 DEFAULT의 순서를 서로 변경해야 정상 처리된다.
50 VIEW
-
① 뷰 생성 후 뷰에 컬럼 정의를 변경할 수 없다.
-
② 뷰를 통해 원본 테이블에 데이터를 변경할 수 있다.
여러 제한이 생기긴 함
단일 테이블 / 단순 SELECT / 조건 없을때 테이블 변경 가능 -
③ 뷰에 직접 인덱스를 생성할 수 없다.
-
④ 서브쿼리나 조인을 사용한 복잡한 쿼리에 대한 뷰를 생성할 수 있다.
뷰의 정의를 변경할 수 없고, 뷰를 통한 원본 테이블 데이터를 변경할 수 있느나 여러 제한이 생긴다. 뷰에는 인덱스를 직접 생성할 수 없고, 조인이나 서브쿼리를 사용한 복잡한 쿼리를 갖는 뷰는 생성이 가능하다.
