SQL의 활용 1, 2
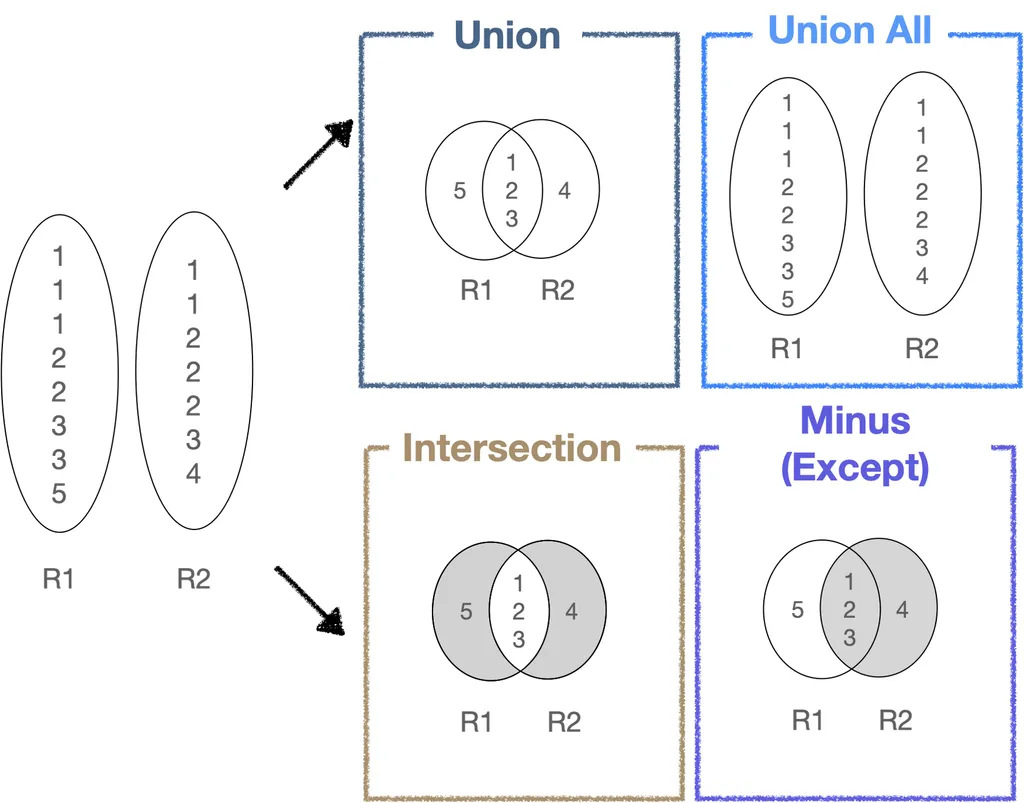
집합연산자(SET OPERATOR)
동일 테이블에서 서로 다른 질의의 결과를 합치고자 할 때 사용
집합연산자
2개 이상의 쿼리 수행 결과를 가지고 하나의 결과로 만들어줌.
(2개 이상의 테이블에서 Join 사용 x, 연관된 데이터 조회하여 합쳐서 볼 수 O)
집합 연산자를 사용하기 위해서는 SELECT 절의 칼럼 수가 동일해야한다.
집합연산자 종류
- union: 합집합, 중복 x
중복배제 위한 정렬연산 -> 시스템 부하SELECT first_name, height FROM participant WHERE nation_id = 1 UNION SELECT first_name, height FROM participant WHERE main_sport_id = 102; - union all : 합집합, 중복o
SELECT job FROM emp WHERE deptno = 10 UNION ALL SELECT job FROM emp WHERE deptno = 20; - intersect(intersection) : 교집합, 중복허용x, 하나의 행 만들어줌
SELECT job FROM emp WHERE deptno = 10 INTERSECT SELECT job FROM emp WHERE deptno = 20; - minus(except) : 차집합, a-b와 b-a의 결과가 다르다.(중복허용x)
SELECT job FROM emp WHERE deptno = 10 MINUS SELECT job FROM emp WHERE deptno = 20;
주의사항
- 두 집합의 칼럼 수가 일치해야 한다.
- 두 집합의 칼럼 순서가 일치해야 한다.
- 두 집합의 각 칼럼의 데이터 타입이 일치해야 한다.
- 각 칼럼의 사이즈는 달라도 된다.
☑️ 문제
| Q. 문제 | 집합연산자 UNION과 UNION ALL에 대한 설명으로 옳지 않은 것은? |
|---|---|
| A. (1) | UNION은 중복된 행은 하나의 행으로 만든다 |
| A. (2) | UNION은 중복 배제하기 위한 정렬 연산이 있어 시스템의 부하가 있다 |
| A. (3) | UNION ALL은 중복된 행을 그대로 보여주며 중복된 행을 제외하면 UNION과 결과 집합 및 그 순서가 동일하다 |
| A. (4) | UNION ALL은 일반적으로 여러 개의 질의 결과가 중복이 없을 때(상호 배타적일 때) 사용한다 |
- 정답
(3) UNION과 UNION ALL의 결과 집합의 순서가 다를 수 있다
서브쿼리
서브쿼리 기본
하나의 SQL 문안에 포함되어 있는 또 다른 SQL 문
항상 메인쿼리 레벨로 결과 집합이 생성
사용하는 곳
SELECT 절
FROM 절
WHERE 절
HAVING 절
ORDER BY 절
DML(INSERT, DELETE, UPDATE절)
GROUP BY 절에서 사용 불가
주의사항
서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용이 가능
-
단일 행 비교 연산자(=, !=, >, <, >=, <=)는 서브쿼리의 결과가 반드시 1건 이하여야 한다.
SELECT name FROM employees WHERE salary = ( SELECT MAX(salary) FROM employees ); -- 오류나는 경우 SELECT name FROM employees WHERE salary = ( SELECT salary FROM employees WHERE department = 'Sales' );sales 부서 직원 3명일경우 결과 3건나오는데
=을 사용하면 1건만 나와야함 -> 오류
-
복수 행 비교 연산자(IN, ANY, ALL)는 서브쿼리의 결과 건수와 관련이 없다. 1건도 가능하고 여러 건도 가능
SELECT name FROM employees WHERE salary IN ( SELECT salary FROM employees WHERE department = 'Sales' ); -
서브쿼리에서는 기본적으로 ORDER BY를 사용할 수 없다.
서브쿼리의 분류
동작방식과 데이터 반환 형태에 따라
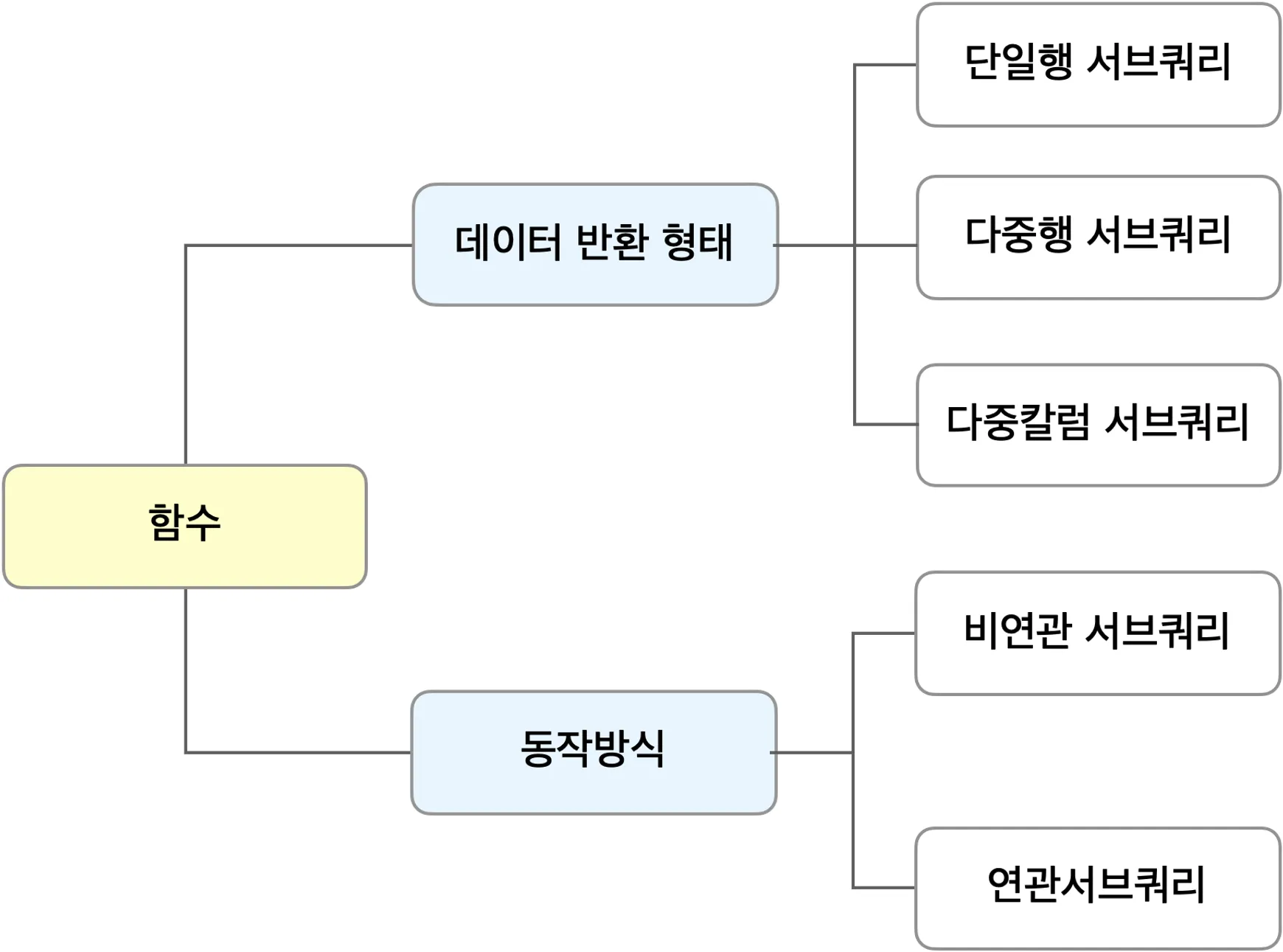
- 데이터 반환형태
- 단일행
- 다중행
- 다중 컬럼
- 동작방식
- 비연관
- 연관
동작 방식에 따른 서브쿼리
연관 서브쿼리
서브쿼리가 메인쿼리의 값을 사용하는 경우
메인쿼리 수행 이후 서브쿼리에 조건 맞는지 확인할 때 사용
(서브쿼리의 값이 결정되는데 메인쿼리에 의존)
- 특징
서브쿼리가 메인쿼리의 각 행마다 실행
서브쿼리 안에서 메인쿼리 컬럼 참조
SELECT e1.name
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
);
각 직원 e1에 대해 자기 부서의 평균 급여를 구해서 비교
부서별 평균이니까, 매번 부서 ID가 바뀜 → 반복 실행됨
where절에 e1값이 들어가있는거 확인
- EXISTS 서브쿼리
서브쿼리 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미
항상 연관 서브쿼리로 사용
서브쿼리의 결과가 참이라면 결과 집합에 포함
아무리 조건을 만족하는 건이 여러 건이더라도 조건을 만족하는 1건만 찾으면 추가적인 검색을 진행x
비연관 서브쿼리
서브쿼리가 메인쿼리의 값을 사용하지 않는 경우 (메인과 전혀 상관없이 독립적 실행)
서브쿼리가 메인쿼리에 값(서브쿼리 결과) 제공
- 특징
서브쿼리가 먼저, 한번만 실행된다
서브쿼리가 단독으로도 실행될 수 있다.
SELECT name
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);
select avg()가 한번만 계산
반환 형태에 따른 서브쿼리
서브쿼리가 몇개의 행 / 컬럼을 반환하는지에 따라
단일/다중/다중컬럼 서브쿼리로 구분
단일행
서브쿼리의 결과가 0건 혹은 1건
비교 연산자(=, <, <=, >, >=, <>)
SELECT first_name, main_sport_id, weight
FROM participant
WHERE weight > (SELECT MAX(weight)
FROM participant
WHERE main_sport_id = 101);다중행
서브 쿼리의 결과가 2건 이상인 SELECT문이 서브쿼리로 존재하는 것
반드시 다중행 비교 연산자(IN, ALL, ANY, EXISTS 등)와 함께 사용
-
📌 다중행 비교 연산자
- IN (서브쿼리)
서브쿼리 결과에 존재하는 임의의 값과 동일한 조건 - ALL (서브쿼리)
서브쿼리 결과에 존재하는 모든 값을 만족하는 조건 - ANY (서브쿼리) / SOME (서브쿼리)
서브쿼리 결과에 존재하는 어느 하나의 값이라도 만족하는 조건 - EXISTS (서브쿼리)
서브쿼리 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건
- IN (서브쿼리)
--정상 실행
SELECT A.EMPNO
, A.ENAME
, A.DEPTNO
FROM EMP A
WHERE A.DEPTNO IN
(
SELECT K.DEPTNO
FROM DEPT K
WHERE K.DNAME IN ('ACCOUNTING', 'SALES')
)
ORDER BY A.DEPTNO ;
--error 발생
SELECT A.EMPNO
, A.ENAME
, A.DEPTNO
FROM EMP A
WHERE A.DEPTNO = (
SELECT K.DEPTNO
FROM DEPT K
WHERE K.DNAME IN ('ACCOUNTING', 'SALES')
)
ORDER BY A.DEPTNO ;=은 결과값 하나만 받아야하는데
accounting과 sales 두개를 받으니까 오류가 남.
다중컬럼
서브쿼리의 결과로 여러 개의 칼럼이 반환되어, 메인쿼리의 조건과 동시에 비교되는 것
부서별로 가장 높은 급여를 받는 사원을 찾는 SQL 문
SELECT deptno, dname, empno, ename, sal
FROM (
SELECT e.deptno,
d.dname,
e.empno,
e.ename,
e.sal,
RANK() OVER (PARTITION BY e.deptno ORDER BY e.sal DESC) AS sal_rank
FROM emp e
JOIN dept d ON e.deptno = d.deptno
)
WHERE sal_rank = 1;기타 서브쿼리와 뷰
위치별 서브쿼리
SELECT 스칼라
하나의 행과 하나의 칼럼(1 Row - 1 Column)만을 반환
SELECT A.EMPNO , A.ENAME
, A.DEPTNO
, (SELECT L.DNAME FROM DEPT L WHERE L.DEPTNO = A.DEPTNO ) AS DNAME
FROM EMP A
WHERE A.DEPTNO IN (SELECT K.DEPTNO
FROM DEPT K
WHERE K.DNAME IN ('ACCOUNTING', 'SALES'))
ORDER BY A.DEPTNO;FROM 인라인뷰
FROM절에는 테이블명이 반드시 와야한다
FROM 절에 위치한 서브쿼리의 결과는 실행 시에 테이블인 것처럼 사용할 수 있다
동적 뷰(Dynamic View): SQL 문이 실행될 때만 임시적으로 생성되는 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다
WHERE 서브쿼리
여러 개의 서브쿼리가 겹쳐 있기 때문에 '중첩서브쿼리 (nested subqueries)'
HAVING 서브쿼리
그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해
UPDATE문의 SET 서브쿼리
서브쿼리를 사용한 변경 작업을 할 때 주의 : 서브쿼리의 결과가 NULL 을 반환할 때
WHERE 절은 UPDATE 대상이 되는 데이터의 범위를 결정하게 되는데,
WHERE 절이 누락되면 모든 데이터가 UPDATE 대상이 되므로 NULL 값으로 변경될 수 있기 때문
UPDATE emp
SET sal = sal + 1000
WHERE deptno IN (
SELECT deptno
FROM dept
WHERE loc = 'DALLAS'
);INSERT문의 VALUES 서브쿼리
INSERT_TEST 테이블을 생성 후 해당 테이블에 부서번호가 20인 직원의 가장 높은 급여를 삽입
CREATE TABLE INSERT_TEST (
DEPT_NO NUMBER
, MAX_SAL_AMT NUMBER(15) );
INSERT INTO INSERT_TEST
VALUES (20, (SELECT MAX(SAL)
FROM EMP
WHERE DEPTNO = 20)
);여러 서브쿼리가 섞인 개념
SELECT A.계좌번호 , B.고객번호 , B.고객명 , C.적립금,
(SELECT 이름
FROM 사원 A
WHERE D.사원번호 = A.사원번호 ) 담당자_이름 -- 스칼라 서브쿼리
FROM 계좌 A
(SELECT 고객번호, MAX(적립금) 적립금
FROM 포인트
WHERE 적립일 = '20211030') C -- 인라인 뷰
WHERE NOT EXISTS (SELECT 'X'
FROM 입금목록 B
WHERE A.계좌번호 = B.계좌번호
AND B.거래일자 LIKE '202109%') -- 서브쿼리
AND A.지점_위치 = '서울'
AND A.고객번호 = C.고객번호뷰(View)
-
데이터베이스에서 저장된 정보를 좀 더 편리하게 보여주기 위해 사용되는 가상의 테이블
-
이미 존재하는 데이터 테이블을 사용하여 원하는 정보를 필터링하거나 정리하여 새로운 "가상" 테이블을 만드는 것
-
뷰 사용의 장점
독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 됨
편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성 가능
보안성 : 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 때 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있음
CREATE VIEW V_DEPT_EMP AS
SELECT E.EMPNO,
E.ENAME,
E.JOB,
E.SAL,
D.DNAME
FROM DEPT D,
EMP E
WHERE D.DEPTNO = E.DEPTNO;그룹함수
다중행 함수 중에 하나
데이터 분석 개요
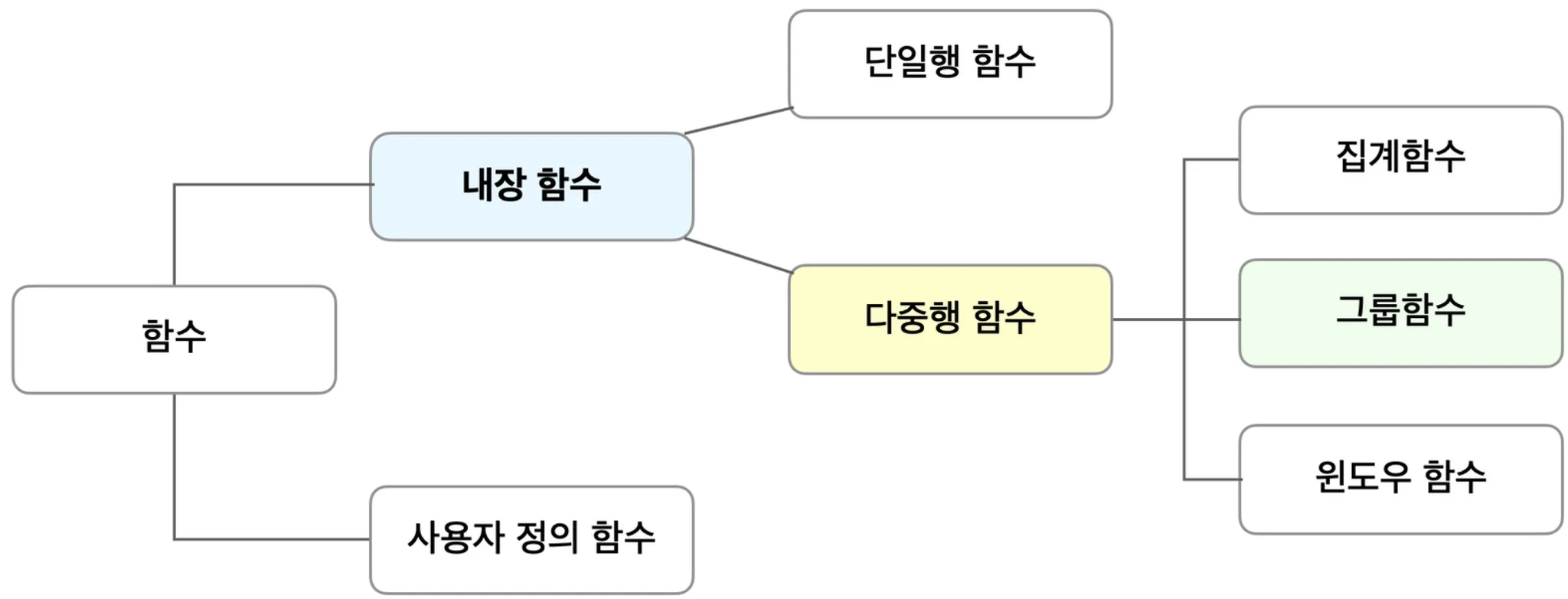
집계함수, 그룹함수, 윈도우함수
집계함수
COUNT, SUM, AVG, MAX, MIN
-
COUNT: 또는 하나의 칼럼만 사용 가능
COUNT(), COUNT(ORDER) -
SUM : 총 합을 출력하는 함수
-
AVG : 평균값을 출력하는 함수
NULL을 제외한 값을 리턴하므로 평균 연산 시 주의
NULL을 0으로 계산하여 출력하고 싶은 경우 예시
AVG(NVL(대상,0)) -
MIN/MAX : 최소, 최대값을 출력하는 함수
날짜, 숫자, 문자 모두 사용 가능 (오름차순 순서대로 출력됨)
window function
행과 행간의 관계를 나타내기 위해 사용
group function
데이터에 대한 결산 개념의 연산을 할 때 주로 사용되는 함수
계층형(Grouping Hierarchy) 집계 함수
-
ROLLUP
소그룹 간의 소계를 구하는 함수
함수 내부의 인자로 지정된 그룹화 칼럼 -> 소계를 생성하는 데 사용
그룹화된 칼럼의 수가 N개 -> 소계 N+1개 생성
계층 구조이기 때문에 함수 내의 인자 순서가 바뀌면 결과도 바뀌게 됨. -
CUBE
결합 가능한 모든 값에 대해서 다차원 집계를 구하는 함수
CUBE 함수의 인자가 N개라면 2^N 만큼의 소계가 생성 -
GROUPING SETS
특정 항목에 대한 소계를 구하는 함수입니다.
ROLLUP
칼럼으로 그룹을 만든 후 각 칼럼의 중간 합계를 만들기 위해 사용하는 함수
그룹화된 칼럼의 수가 N개 -> 소계 N+1개 생성 (+1 은 그룹화된 칼럼들의 전체 합계를 의미)
인수의 순서가 바뀌게 되면 수행 결과도 바뀌게 되므로 원하는 결과를 위해서는 인수의 순서에도 주의해야 함
계층적 소계 생성
| region | product | amount |
|---|---|---|
| East | A | 100 |
| East | B | 200 |
| West | A | 150 |
| West | B | 250 |
SELECT region, product, SUM(amount)
FROM sales
GROUP BY ROLLUP(region, product);
| region | product | sum |
|---|---|---|
| East | A | 100 (A, B) 상세 집계 |
| East | B | 200 (A, B) 상세 집계 |
| East | NULL | 300 ← A별 소계, East 지역 소계 |
| West | A | 150 |
| West | B | 250 |
| West | NULL | 400 ← West 지역 소계 |
| NULL | NULL | 700 ← 전체 총합 |
ROLLUP(A,B) : A별, (A,B)별, 전체 그룹 연산 결과 출력 (나열 대상의 순서가 중요)
(A, B)별 집계 + A별 소계 (B가 NULL로 나옴) + 전체 총계 (A, B가 둘 다 NULL)
grouping 함수
ROLLUP 이나 CUBE에 의해서 그룹화 된 칼럼의 소계가 계산된 결과를 1로 표시하고 그 외의 결과는 0으로 표시해 주는 함수
ROLLUP, CUBE로 만들어진 집계 결과 중 소계/총계에서 그 칼럼이 실제로 그룹핑된 값인지, NULL이라 소계인 건지 알려주는 함수
ROLLUP 함수에 기재한 칼럼을 GROUPING 함수의 인자로 출력하면 합계를 표현하는 행에 대해서는 1이 출력
소계와 합계로 집계되어 출력된 행을 구분할 때 사용
SELECT
region,
product,
SUM(amount) AS total,
GROUPING(region) AS grp_region,
GROUPING(product) AS grp_product
FROM sales
GROUP BY ROLLUP(region, product)
ORDER BY region NULLS LAST, product NULLS LAST;
| region | product | total | grp_region | grp_product | 의미 |
|---|---|---|---|---|---|
| East | A | 100 | 0 | 0 | 일반 행 |
| East | B | 200 | 0 | 0 | 일반 행 |
| East | NULL | 300 | 0 | 1 | 👉 product 소계 |
| West | A | 150 | 0 | 0 | 일반 행 |
| West | B | 250 | 0 | 0 | 일반 행 |
| West | NULL | 400 | 0 | 1 | 👉 product 소계 |
| NULL | NULL | 700 | 1 | 1 | 👉 전체 총계 |
ROLLUP과 CASE문
NULL대신 어떤 그룹화된 값인지를 표현하고 싶은 경우 CASE 문을 사용
SELECT
CASE
WHEN GROUPING(region) = 1 THEN '전체'
ELSE region
END AS 지역,
CASE
WHEN GROUPING(product) = 1 THEN '소계'
ELSE product
END AS 상품,
SUM(amount) AS 금액
FROM sales
GROUP BY ROLLUP(region, product)
ORDER BY 지역, 상품;
| 지역 | 상품 | 금액 |
|---|---|---|
| 부산 | A | 150 |
| 부산 | B | 250 |
| 부산 | 소계 | 400 |
| 서울 | A | 100 |
| 서울 | B | 200 |
| 서울 | 소계 | 300 |
| 전체 | 소계 | 700 |
ROLLUP과 괄호
괄호로 결합하여 두 칼럼을 하나의 집합 칼럼처럼 간주하여 사용
-> 칼럼으로 묶인 칼럼은 칼럼 별 집계를 따로 계산하지 않아도 됨
CUBE
표시된 그룹화된 칼럼에 대한 계층별 집계
여러 열을 기반으로 데이터를 다양한 방식으로 집계하며 다차원적인 소계를 계산하는 기능이기에 결합 가능한 모든 값에 대해 집계를 생성
그룹화된 데이터의 모든 가능한 조합에 대해 합계를 계산
ROLLUP과는 다르게 평등한 관계이므로 칼럼의 순서가 바뀌어도 정렬되는 순서는 바뀌지만 데이터의 결과는 동일
ROLLUP 함수에 비해서 시스템의 연산 대상이 많은 것이 특징
CUBE (A,B) : A별, B별, (A,B)별, 전체 그룹 연산 결과 출력
그룹으로 묶을 대상의 나열 순서는 중요하지 않음
SELECT
region,
product,
SUM(amount) AS 금액
FROM sales
GROUP BY CUBE(region, product);
| region | product | 금액 | 의미 |
|---|---|---|---|
| 서울 | A | 100 | 개별 값 |
| 서울 | B | 200 | 개별 값 |
| 서울 | NULL | 300 | ✅ 서울의 전체 소계 |
| 부산 | A | 150 | 개별 값 |
| 부산 | B | 250 | 개별 값 |
| 부산 | NULL | 400 | ✅ 부산의 전체 소계 |
| NULL | A | 250 | ✅ A 상품 전체 소계 |
| NULL | B | 450 | ✅ B 상품 전체 소계 |
| NULL | NULL | 700 | ✅ 전체 총계 (지역 + 상품 전체) |
CUBE(region, product)는 아래 조합을 전부 보여줌
(region, product) → 실제 원래 데이터
(region, NULL) → 지역별 소계
(NULL, product) → 상품별 소계
(NULL, NULL) → 전체 총계
| 항목 | ROLLUP(region, product) | CUBE(region, product) |
|---|---|---|
| 소계 개수 | N (칼럼 수) + 1 | 2ⁿ (칼럼 수에 따라 조합 폭발) |
GROUPING SETS
GROUPING SETS를 이용하면 GROUP BY 문장을 여러 번 반복하지 않아도 다양한 소계 집합을 만들 수 있다.
즉 ROLLUP 과 CUBE 와 비슷한 결과를 얻을 수 있지만 좀 더 명시적으로 원하는 그룹 수준을 정할 수 있다.
SELECT region, product, SUM(amount)
FROM sales
GROUP BY GROUPING SETS (
(region, product), -- 원래 데이터
(region), -- 지역별 소계
() -- 전체 합계
);
| region | product | amount |
|---|---|---|
| 서울 | A | 100 |
| 서울 | B | 200 |
| 부산 | A | 150 |
| 부산 | B | 250 |
| 서울 | NULL | 300 |
| 부산 | NULL | 400 |
| NULL | NULL | 700 |
→ ❗ 원하는 소계만 선택적으로 가져옴
→ CUBE처럼 상품별 소계는 계산하지 않음
→ ROLLUP보다 더 자유도 높은 소계 선택 가능!
윈도우함수
행과 행 간의 관계를 정의
분석함수, 순위함수라고도 함
WINDOW FUNCTION
순위나 합계, 평균, 행 위치 등을 조작
GROUP BY 구문과 병행하여 중첩(NEST) 사용할 수 없지만, 서브쿼리에서는 사용할 수 있다
SELECT WINDOW_FUNCTION(ARGUMENTS)
OVER ([PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절])
FROM 테이블 명;WINDOWING
함수의 대상이 되는 행 기준의 범위를 지정
| 구분 | 설명 | 특징 |
|---|---|---|
ROWS | 물리적 행 단위 범위 지정 | 같은 값이어도 각 행을 따로 계산 |
RANGE | 논리적 값 기준 범위 지정 | 같은 값이면 묶어서 한 번에 계산 |
BETWEEN A AND B | 윈도우 범위의 시작과 끝 위치 지정 | A, B는 PRECEDING, CURRENT ROW, FOLLOWING 사용 |
N PRECEDING | 현재 행 기준으로 이전 N개 포함 | 시작 위치 지정 |
N FOLLOWING | 현재 행 기준으로 이후 N개 포함 | 끝 위치 지정 |
UNBOUNDED PRECEDING | 처음부터 현재 위치까지 | 범위 시작의 기본값 |
UNBOUNDED FOLLOWING | 현재부터 끝까지 포함 | 범위 끝의 기본값 |
CURRENT ROW | 현재 행 기준 | 현재 행을 기준으로 설정 가능 |
쉬운말로 하면..
| 절 | 의미 | 예시 |
|---|---|---|
ROWS | 몇 행 포함할지 | ROWS BETWEEN 2 PRECEDING AND CURRENT ROW |
RANGE | 몇 값 범위 포함할지 | RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING |
PRECEDING | 앞쪽 범위 | 1 PRECEDING: 앞 1개 |
FOLLOWING | 뒷쪽 범위 | 2 FOLLOWING: 뒤 2개 |
UNBOUNDED | 처음/끝까지 다 포함 | 시작점: UNBOUNDED PRECEDING, 끝점: UNBOUNDED FOLLOWING |
CURRENT ROW | 현재 행 기준 | 기준점으로 자주 사용됨 |
예시
sales테이블
| day | amount |
|---|---|
| 1일 | 100 |
| 2일 | 200 |
| 3일 | 100 |
| 4일 | 300 |
| 5일 | 100 |
SELECT day, amount,
SUM(amount) OVER (
ORDER BY day
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) AS rolling_sum
FROM sales;
-- range의 경우
SELECT day, amount,
SUM(amount) OVER (
ORDER BY amount
RANGE BETWEEN CURRENT ROW AND CURRENT ROW
) AS grouped_sum
FROM sales;
-
rows
day amount rolling_sum 계산 과정 1일 100 100 (자기 자신만) 2일 200 100 + 200 = 300 1일 + 2일 3일 100 200 + 100 = 300 2일 + 3일 4일 300 100 + 300 = 400 3일 + 4일 5일 100 300 + 100 = 400 4일 + 5일 -
range : 같은 값이면 묶어서 한 번에 계산
CURRENT ROW AND CURRENT ROW : 현재 행의 amount 값 자체와 같은 amount 값을 가진 모든 행"을 대상으로day amount grouped_sum 설명 1일 100 300 1일, 3일, 5일 합 (100x3) 3일 100 300 same 5일 100 300 same 2일 200 200 혼자 amount 200 4일 300 300 혼자 amount 300
그룹 내 순위 함수
테이블 이름: emp
| empno | ename | sal |
|---|---|---|
| 101 | A | 3000 |
| 102 | B | 3000 |
| 103 | C | 2500 |
| 104 | D | 2000 |
| 105 | E | 2000 |
| 106 | F | 1800 |
rank
동일한 값에 대해서는 동일한 순위를 부여하게 되며 다음 순위는 누적된 순위로 계산
dense_rank
순위를 누적시키지 않고 순차대로 순위를 부여
row_number
동일한 순위라도 고유한 순위를 부여할 때 사용
어떤 순서가 정해질지는 각 벤더 별로 결과가 다르게 나옴
| ename | sal | RANK | DENSE_RANK | ROW_NUMBER |
|---|---|---|---|---|
| A | 3000 | 1 | 1 | 1 |
| B | 3000 | 1 | 1 | 2 |
| C | 2500 | 3 | 2 | 3 |
| D | 2000 | 4 | 3 | 4 |
| E | 2000 | 4 | 3 | 5 |
| F | 1800 | 6 | 4 | 6 |
일반 집계 함수
SUM, MAX, MIN, AVG, COUNT 함수
sum
- 누적합
-- range방법(기본)
SELECT
MGR,
ENAME,
SAL,
SUM(SAL) OVER (ORDER BY SAL)
FROM EMP
ORDER BY SAL;
-- rows between
SELECT
MGR,
ENAME,
SAL,
SUM(SAL) OVER (ORDER BY SAL ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS SUM_SAL
FROM EMP
ORDER BY SAL;
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
UNBOUNDED PRECEDING → 제일 첫 행부터 시작
그룹 내 행 순서 함수
FIRST_VALUE
LAST_VALUE
LAG
이전 행 들고옴
LEAD
이후 행 들고옴
그룹 내 비율함수
RATIO_TO_REPORT
전체 컬럼에 대한 행 별 칼럼 값의 백분율
0 ≤ X ≤ 1
PERCENT_RANK
제일 먼저 나온것 0, 제일 마지막 1 -> 행의 순서 백분율
0 ≤ X ≤ 1
CUME_DIST
현재 행보다 작거나 같은 건수에 대한 누적 백분율
0 < X ≤ 1
NTILE
각 파티션(그룹) 안에서 전체 행 수를 N등분해서, 행을 N개의 그룹으로 나눠주는 것
인자값에 주어진 수대로 등급 할당
