TOP N 쿼리
특정 조건에 맞는 상위 N개의 행을 효율적으로 조회하는 방법
TOP N 쿼리
전체 결과에서 N개의 데이터를 보여주기 위한 쿼리
데이터를 어떤 순서로 정렬해서 보여줄 건지 결정해야 함
Oracle은 ROWNUM
SQL Server는 TOP (N)
그 외 TOP-N 행 추출 방법으로는 RANK, FETCH
ROWNUM
조회된 데이터에 가상의 번호를 매겨 원하는 개수의 데이터를 가져오는 방법
실제 값 x, 조회 조건 변경마다 값 바뀌게 됨
조회가 일어난 다음 첫 행이 1이 되고 그다음 행들의 번호가 매겨지는 방식이므로 1을 포함하지 않은 범위를 조회하면 조회 결과가 나오지 않음
WHERE절이 실행되는 순서가 ORDER BY 전이므로 이 순서를 고려해서 쿼리를 작성
SELECT ENAME, SAL
FROM EMP
WHERE ROWNUM < 4
ORDER BY SAL DESC;
급여가 높은 사람 3명이 아니라 먼저 뽑힌 3명을 급여순으로 정렬해서 보여줌
from - where - order by 순이라 ..
from - where - group by - having - select - orderby
FETCH 절
OFFSET 및 FETCH 절을 사용하면 쉽게 결과 집합의 특정 범위를 조절가능
ORDER BY 절 뒤에 위치하며 OFFSET을 이용하여 특정 위치에서 행을 건너뛰고 그 이후 FETCH를 통해 특정 수의 행을 선택
[OFFSET n {ROW | ROWS}]
[FETCH {FIRST | NEXT} n {ROW | ROWS} {ONLY | WITH TIES}]- OFFSET offset : 건너뛸 행의 개수 지정
- FETCH : 반환할 행의 개수나 백분율 지정
- FRIST : offset을 사용하지 않았을 때 처음부터
- NEXT : offset으로 건너뛴 이후부터
- ONLY : 지정된 행의 개수나 백분율만큼 정확한 갯수의 행 반환
- WITH TIES : 마지막 행에 대한 동순위를 포함하여 반환
-- 기본구조
SELECT 컬럼
FROM 테이블
ORDER BY 정렬기준
OFFSET N ROWS FETCH FIRST M ROWS ONLY;
OFFSET N ROWS : 앞에서 N행 건너뜀 (생략 가능)
FETCH FIRST M ROWS ONLY : 그 다음 M행만 가져옴
-- 급여
SELECT ENAME, SAL
FROM EMP
ORDER BY SAL DESC
FETCH FIRST 3 ROWS ONLY;
-- 이름
SELECT ENAME, SAL
FROM EMP
ORDER BY ENAME
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
급여순 정렬, 상위3명
이름순 정렬하고, 11번째부터 10명 보여줘
계층형 질의와 표준 셀프 조인
계층형 질의
계층형 데이터: 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터\
계층형 구조는 데이터 모델 설계를 통해 테이블로 만들 수 있다.
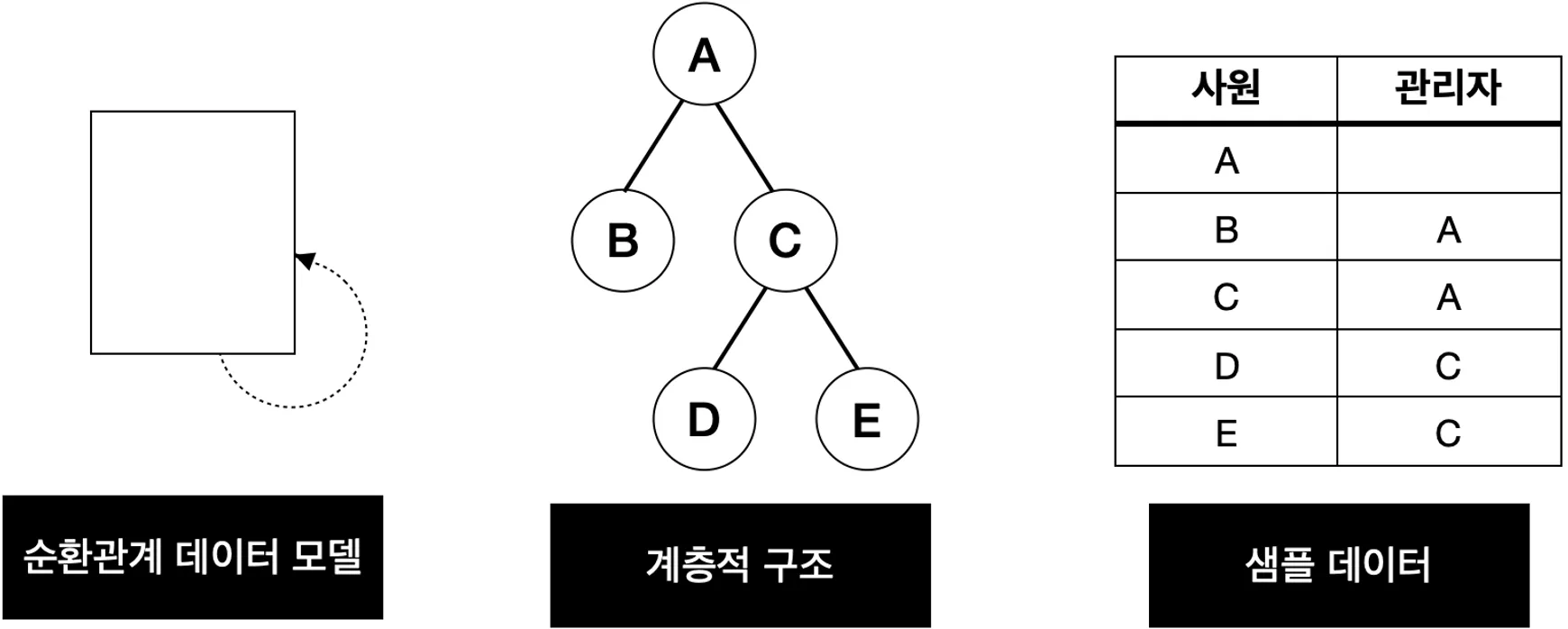
A 사원은 부모 데이터 즉, 관리자가 없음을 알 수 있고 B와 C는 모두 A 사원이 관리자임을 알 수 있다.
계층형 데이터를 조회하기 위해서는 계층형 질의를 사용해야 한다.
Oracle 계층형 질의
oracle 계층형 질의 구문
SELECT ...
FROM 테이블
START WITH 조건 -- 루트(시작점)
CONNECT BY [NOCYCLE] PRIOR 자식컬럼 = 부모컬럼
-
WHERE
- 모든 전개를 수행하고 나서 지정 조건을 만족하는 데이터만 추출
- 계층적으로 진행 후에 특정한 조건에 맞는 데이터만 가져옴
-
START WITH
- 계층 구조 전개의 시작 위치를 지정하는 구문
- 어디서부터 계층 질의를 시작하는지 루트 데이터(루트 노드 행)를 설정하는 구문
-
PRIOR
어느 컬럼이 부모이고 어느 컬럼이 자식인지 명시 -
CONNECT BY [NOCYCLE]
전개되어질 자식 데이터를 지정하는 조건 구문 (연결 고리)
자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 함
순환 참조(무한 루프) 방지 (있으면 좋음)
SELECT LEVEL, ENAME, EMPNO, MGR
FROM EMP
START WITH MGR IS NULL -- 가장 윗사람 (사장)
CONNECT BY PRIOR EMPNO = MGR; -- 사수가 부모
PRIOR EMPNO = MGR 이면 EMPNO가 부모, MGR이 자식
(즉 EMPNO가 MGR의 상사)
가상 컬럼
| 가상 컬럼 | 설명 |
|---|---|
LEVEL | 현재 노드의 깊이 (루트는 1) |
CONNECT_BY_ISLEAF | 자식이 없는 노드면 1, 있으면 0 |
CONNECT_BY_ROOT 컬럼 | 루트 노드의 컬럼 값 |
SYS_CONNECT_BY_PATH(컬럼, 구분자) | 루트부터 현재 노드까지의 경로를 문자열로 |
예시 EMP 테이블
| EMPNO | ENAME | MGR |
|---|---|---|
| 7839 | KING | NULL |
| 7566 | JONES | 7839 |
| 7788 | SCOTT | 7566 |
| 7876 | ADAMS | 7788 |
| 7902 | FORD | 7566 |
| 7369 | SMITH | 7902 |
SELECT ENAME,
LEVEL,
SYS_CONNECT_BY_PATH(ENAME, ' → ') AS 경로
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;
LEVEL: 루트부터 얼마나 깊은지
SYS_CONNECT_BY_PATH(ENAME, ' → '): 루트부터 현재 사원까지 이름으로 경로 출력
SYS_CONNECT_BY_PATH(컬럼, '구분자'): 루트 노드부터 현재 노드까지의 값을 구분자로 연결
KING이 루트 → 그 앞에는 아무것도 없음. 그래서 → KING
| ENAME | LEVEL | 경로 |
|---|---|---|
| KING | 1 | → KING |
| JONES | 2 | → KING → JONES |
| SCOTT | 3 | → KING → JONES → SCOTT |
| ADAMS | 4 | → KING → JONES → SCOTT → ADAMS |
| FORD | 3 | → KING → JONES → FORD |
| SMITH | 4 | → KING → JONES → FORD → SMITH |
추가함수
| 함수명 | 설명 |
|---|---|
SYS_CONNECT_BY_PATH() | 루트부터 현재 노드까지 경로 문자열로 보여줌 |
CONNECT_BY_ISLEAF | 자식이 없으면 1, 있으면 0 |
CONNECT_BY_ROOT | 루트 노드의 컬럼값 |
LEVEL | 현재 계층의 깊이 (루트는 1부터 시작) |
몽땅 적용하면
SELECT
LEVEL,
LPAD(' ', LEVEL * 2) || ENAME AS 계층표현,
CONNECT_BY_ISLEAF AS 말단여부,
CONNECT_BY_ROOT ENAME AS 최상위사람,
SYS_CONNECT_BY_PATH(ENAME, ' > ') AS 경로
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;
코드
| 요소 | 설명 | ||
|---|---|---|---|
LEVEL | 루트부터의 깊이 (1부터 시작) | ||
| `LPAD(' ', LEVEL * 2) | ENAME` | 이름 앞에 공백을 넣어 트리처럼 들여쓰기 | |
CONNECT_BY_ISLEAF | 말단 노드(leaf)면 1, 아니면 0 | ||
CONNECT_BY_ROOT ENAME | 이 계층의 루트(최상위 사람) 이름 | ||
SYS_CONNECT_BY_PATH(ENAME, ' > ') | 루트부터 현재 사원까지 경로 표시 |
결과
| LEVEL | 계층표현 | 말단여부 | 최상위사람 | 경로 |
|---|---|---|---|---|
| 1 | KING | 0 | KING | > KING |
| 2 | JONES | 0 | KING | > KING > JONES |
| 3 | SCOTT | 0 | KING | > KING > JONES > SCOTT |
| 4 | ADAMS | 1 | KING | > KING > JONES > SCOTT > ADAMS |
| 3 | FORD | 0 | KING | > KING > JONES > FORD |
| 4 | SMITH | 1 | KING | > KING > JONES > FORD > SMITH |
셀프조인
PIVOT절과 UNPIVOT절
요약된 데이터를 원래 형태로 변환하는 방법
PIVOT 절은 행 데이터를 열 데이터로 회전시키고, UNPIVOT 절은 열 데이터를 행 데이터로 회전
- 데이터 구조 변경
- PIVOT : LONG DATA → WIDE DATA
- UNPIVOT : WIDE DATA → LONG DATA
PIVOT
SELECT *
FROM (
원본 테이블 또는 서브쿼리
)
PIVOT (
집계함수(컬럼)
FOR 피벗할컬럼 IN (값1, 값2, ...)
);
-- 예제
SELECT *
FROM (
SELECT deptno, job, sal
FROM emp
)
PIVOT (
AVG(sal)
FOR job IN ('MANAGER' AS MANAGER, 'CLERK' AS CLERK, 'ANALYST' AS ANALYST)
);
- aggregate_function : 집계할 열 지정
- FOR 절 : PIVOT 할 열 지정
- IN 절 : PIVOT할 열 값을 지정
emp
| DEPTNO | JOB | SAL |
|---|---|---|
| 10 | MANAGER | 3000 |
| 10 | CLERK | 1300 |
| 20 | ANALYST | 3000 |
| 30 | SALESMAN | 1600 |
| 30 | CLERK | 950 |
aggregate_function: AVG(sal)은 각 부서(deptno) 내에서 직책(job) 별 평균 급여를 구하겠다는 뜻. 이게 값으로 들어감
FOR job: 피벗 기준이 되는 열. 즉, job 값이 새로운 열 이름으로 바뀌어 생성돼.
IN ('MANAGER' AS MANAGER, ...): MANAGER, CLERK, ANALYST 라는 job 값들을 열로 바꾸겠다는 선언. AS 뒤에 나오는 건 새로 생성될 열의 이름.
| DEPTNO | MANAGER | CLERK | ANALYST |
|---|---|---|---|
| 10 | 3000 | 1300 | NULL |
| 20 | NULL | NULL | 3000 |
| 30 | NULL | 950 | NULL |
UNPIVOT
열(column) 데이터를 행(row) 으로 바꾸는 것.
피벗된 데이터를 다시 원래처럼 세로로 만드는 데 사용
SELECT *
FROM (
피벗된 테이블 또는 원본 테이블
)
UNPIVOT (
측정값컬럼 FOR 피벗해제할컬럼명 IN (열1, 열2, ...)
);
-- 예제
SELECT *
FROM sales_data
UNPIVOT (
amount FOR year IN (Y2022 AS '2022', Y2023 AS '2023')
);
가로
| PROD | Y2022 | Y2023 |
|---|---|---|
| TV | 100 | 150 |
| PHONE | 80 | 120 |
-
amount
→ 원래 열이던 Y2022, Y2023에 들어있던 값들 (매출 금액 등)이 amount 열의 값으로 들어간다. -
FOR year
→ 원래 열의 이름(Y2022, Y2023)을 행 단위로 표시할 새 열 이름이 year이다.
예를 들어 Y2022 열에 있던 값은 year = '2022', amount = 값 이렇게 바뀌게 됨. -
IN (...)
→ 어떤 열을 펼칠 것인지, 그리고 펼치면서 새로 줄 열의 값이 무엇인지 지정하는 부분.
Y2022 AS '2022'이면, Y2022 열이 year='2022'이라는 행으로 변환된다.
결과
| PROD | YEAR | AMOUNT |
|---|---|---|
| TV | 2022 | 100 |
| TV | 2023 | 150 |
| PHONE | 2022 | 80 |
| PHONE | 2023 | 120 |
정규표현식
문자열 패턴을 검색하고 추출하는 강력한 도구
정규 표현식(regular expression) 기본
문자열의 규칙을 표현하는 검색 패턴으로 주로 문자열 검색과 치환에 사용
메타문자
문자 자체가 가진 의미가 아닌 다른 의미로 사용되는 문자
ex) 정규표현식에서 ‘’ 문자 그 자체가 아닌 ‘문자열의 끝’을 의미
리터럴 문자
문자 자체가 가진 의미 그대로 사용되는 문자
정규표현식에서 패턴 매칭 수행 시 처리되는 단위
ex) 알파벳, 한글 등
POSIX 연산자
- ‘REGEXP_SUBSTR’ : 문자열에서 일치하는 패턴을 반환
| 연산자 | 영문 | 설명 |
|---|---|---|
| . | dot | 임의의 한 문자 (newline 제외) |
| ex) a.b : acb, a-b, a1b … | ||
| or | ||
| \ | backslash | 다음 문자를 일반 문자로 취급 |
| 연산자 | 설명 | 예시 정규식 | 매치 예시 | ||
|---|---|---|---|---|---|
. | 임의의 한 문자 | a.c | abc, a1c | ||
^ | 문자열의 시작 | ^abc | abcdef (O), zabc (X) | ||
$ | 문자열의 끝 | abc$ | zabc (O), abcz (X) | ||
* | 앞 문자가 0번 이상 반복 | ab*c | ac, abc, abbbc | ||
+ | 앞 문자가 1번 이상 반복 | ab+c | abc, abbbbbc | ||
? | 앞 문자가 0번 또는 1번 | ab?c | ac, abc | ||
| ` | ` | OR (또는) | `a | b` | a, b |
() | 그룹핑 | `ab(cd | ef)` | abcd, abef | |
[] | 문자 집합 | [abc] | a, b, c | ||
[^] | 부정 문자 집합 | [^abc] | d, x (단 a, b, c 제외) | ||
{m} | m회 반복 | a{3} | aaa | ||
{m,n} | m~n회 반복 | a{2,4} | aa, aaa, aaaa |
이해를 돕기위한..
| 정규식 | 설명 | 예시 매칭 문자열 | |
|---|---|---|---|
ab*c | b가 0번 이상 반복 | ac, abc, abbbc | |
ab+c | b가 1번 이상 반복 | abc, abbbbbc | |
ab?c | b가 0~1번 나옴 | ac, abc | |
| `ab | cd` | ab 또는 cd | ab, cd |
| `ab(cd | ef)` | ab 다음에 cd 또는 ef | abcd, abef |
- 은 안나와도 됨
- 는 1번은 나와야 됨
