TIL - 250416
발등에 불 떨어진 정처기..
java 다형성(Polymorphism)
Parent p = new Child()
"부모 타입 변수(p)가 자식 객체(new Child())를 참조하고 있다"
타입은 부모, 객체는 자식일 때 → 다형성(polymorphism)이 적용
C언어 소수판별
진짜 먼말인지 이해안감
머신러닝 - 이상탐지
1. 이상탐지란?
정상 패턴에서 벗어난 관측값 = “이상치”
이상치(Anomaly)란 일반적인 패턴에서 벗어난 소수의 특이한 데이터이며, 이를 빠르고 정확하게 찾는 것이 핵심
분야 사례
보안 분야: 이상 거래(은행 거래 데이터에서 매우 드문 금액 혹은 비정상적 패턴) 탐지 → 사기( Fraud ) 예방
제조 분야: 센서 이상치(일반적인 동작 범위를 벗어나는 값) 탐지 → 고장 예측
의료 분야: 환자 상태 모니터링 → 조기 진단
금융기관의 카드 사기 탐지
의심스러운 패턴(예: 갑작스러운 해외 고액 결제)을 빠르게 찾아내어 사기 피해를 줄임
데이터센터의 서버 로그 관리
에러 로그나 해킹 시도 로그는 상대적으로 적게(드물게) 나타남.
로그에서 “이상 패턴”을 조기에 잡아내면 빠른 문제 대응과 서비스 장애 예방이 가능
2. 이상탐지 접근 방법
2.1 통계 기반 접근
정상 데이터가 특정 분포(예: 정규분포)를 따른다고 가정
장점: 이해하기 쉽고 계산량이 적음
단점: 데이터가 분포 가정을 벗어나면 성능이 떨어짐
2.2 머신러닝 기반 접근
-
비지도학습: 정상 데이터만으로 모델을 학습 → 이상치를 찾을 수 있음
예: Isolation Forest, LOF, Autoencoder(딥러닝 기반) -
지도학습: 정상/이상 라벨이 있는 데이터로 분류 모델을 학습
현실적으로 이상치 데이터 레이블이 부족하거나 왜곡되어 있는 경우가 많아 적용이 어려움
2.3 지도학습 vs. 비지도학습
비지도학습을 많이 사용함

3. 간단한 통계적 기법
- Z-score
- IQR(Interquartile Range)
4. 머신러닝 기법
4.1 Isolation Forest
무작위로 특징을 선택하고 분할하면서 샘플을 고립( isolation )시키는 방식
이상치는 소수이면서 빠르게 고립될 것이라는 가정
scikit-learn의 IsolationForest 클래스로 간단하게 사용 가능
데이터를 무작위로 쪼개면서 다른 애들과 많이 다른 놈(이상치)은 금방 '고립'된다는 원리
4.2 Local Outlier Factor(LOF)
한 데이터 포인트가 주변 데이터 밀도와 비교해 얼마나 외곽에 있는지 측정
이상치로 의심되는 샘플일수록 주변 이웃(Neighbor) 밀도가 현저히 낮음
4.3 One Class SVM
One-Class SVM은 정상 데이터만을 사용해 경계를 학습하고, 이 경계를 벗어나는 데
이터들을 이상치로 분류하는 비지도학습 기법
ν(nu)라는 파라미터로 결정 경계의 유연성을 조절하며, 일반적으로 데이터 중 이상치로 판단할 비율을 추정하는 역할
5. 파이썬 실습 예제
5.1 데이터 준비
5.2 통계 기법 실습
5.3 머신러닝 기법 실습
# IsolationForest 모델 학습
iso_forest = IsolationForest(random_state=42, contamination=0.01)
iso_forest.fit(data_2d)contamination=0.01: 이상치의 비율이 1%라고 가정
비지도 학습이니까 fit에 y값 안넣어도 됨
6. 평가 방법 & 마무리
6.1 평가 지표 (Precision/Recall/AUC 등)
- Precision, Recall: 이상치 탐지가 정확히 이상치만 골라내는지(Precision), 놓친 이
상치는 없는지(Recall) - F1-score: Precision과 Recall의 조화평균
- ROC AUC: 이상치에 대한 스코어를 기반으로 계산 가능 (지도학습 상황)
실제 현업에서는 이상치 라벨이 부족하거나 없는 경우가 많으므로, 샘플
지식과의 결합이 매우 중요
아 근데 진짜 라이브가 큰 도움이 되는지..(?)를 잘 모르겠다ㅠㅠ
실습코드 돌려봐야겠다는 생각만 계속 들어서..
아무튼 돌려보겠음
머신러닝 이상탐지 실습
One-class SVM과 Isolation Forest는 모두 비지도학습
정상1, 비정상 -1로 나옴
Brunch
Bunch는 내부에 data, target, feature_names 등등이 포함된 일종의 속성 딕셔너리
iris.data, iris.target처럼 점(.)으로 접근해야 함! 괄호 붙이지 않게 주의
.feature_name하면 열의 이름도 나온다
one-class SVM
이상치 nu
outliers_oc
from sklearn.svm import OneClassSVM
oc_svm = OneClassSVM(nu=0.05)
oc_svm.fit(X_2d)Isolation Forest
IsolationForest는 랜덤하게 트리 구조를 만들면서 데이터를 고립시키기 때문에 매번 실행할 때마다 결과가 조금씩 달라질 수 있음
-> 방지하기 위해서 random = 42
이상치 contamination
outliers_if
from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(contamination=0.05, random_state=42)
iso_forest.fit(X_2d)Local Outlier Factor(LOF)
이상치로 의심되는 샘플일수록 주변 이웃(Neighbor) 밀도가 현저히 낮음
n_neighbors는 "내가 비교할 이웃이 몇 명이냐?" 를 정하는 것
from sklearn.neighbors import LocalOutlierFactor
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.02)
pred_lof = lof.fit_predict(data_2d)
lof_outliers = data[pred_lof == -1]
print(f"LOF로 탐지된 이상치 개수: {len(lof_outliers)}")
print(lof_outliers)y_pred_lof = lof.fit_predict() LOF는 fit() 따로 안 쓰고 이걸로 바로 예측까지 바로가능
머신러닝 라이브 분류 실습
이거 너무많네.. 주말에 뜯어보자..
지금 뜯어보기엔... 시간이없서 ㅜ.ㅜ
머신러닝 라이브 - 회귀
회귀
연속형의 결과값을 예측하는 방법
1개 이상의 독립변수(X)와 종속 변수(Y) 간의 관계를 모델링
X와 Y 사이의 관계식을 만드는 것
y = β₀ + β₁x + ε
-
분류와의 차이점 : 결과값(Y)이 연속형
-
회귀모델의 기본원리
가장 실제 값에 근사한 예측값을 찾아내기 → 실제값과의 예측값 사이의 오차를 최소화 해야 한다.
→ 즉, 오차를 최소화하는 회귀계수를 찾는다
오차를 줄이고자 하는게 회귀의 목적임
비용함수(Cost Function,손실함수)
회귀모델의 목표는 오차를 최소화하는 것 = 비용함수의 값을 최소화
MSE(Mean Squared Error) - 오차를 제곱한 것의 평균
MAE(Mean Absolute Error) - 오차 절댓값의 평균
비용함수를 최소화하는 방식 : 최소자승법 vs 경사하강법
-
최소자승법(Ordinary Least Squares)
수학적으로 풀어서 직접 최적해를 계산하는 방법 -
경사하강법(Gradient Descent)
경험적으로 오차를 최소화 하는 계수를 찾아내는 방법
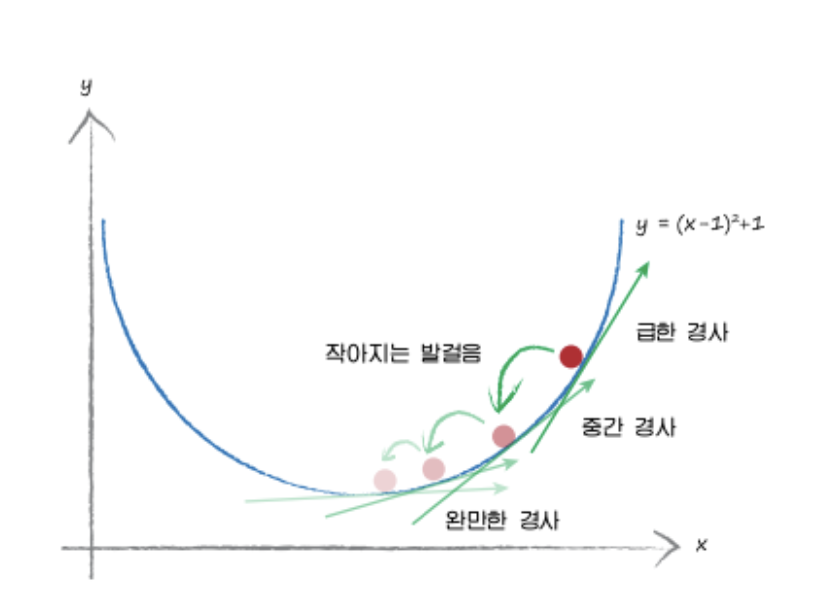
step1: 가중치를 임의의 값으로 설정하고, 첫 비용함수의 값을 계산함.
step2: 가중치를 새로운 값으로 업데이트 한 후 다시 비용함수의 값 계산
step3: 비용함수 값이 감소했으면 다시 step2를 반복. 더 이상 비용함수의 값이 감소하지 않을 때의
가중치를 구하고 반복을 중지함.
경사하강법을 시행할 때에는 최대 몇 번까지 반복(iteration)할 것인지 최대 시행횟수를 지정
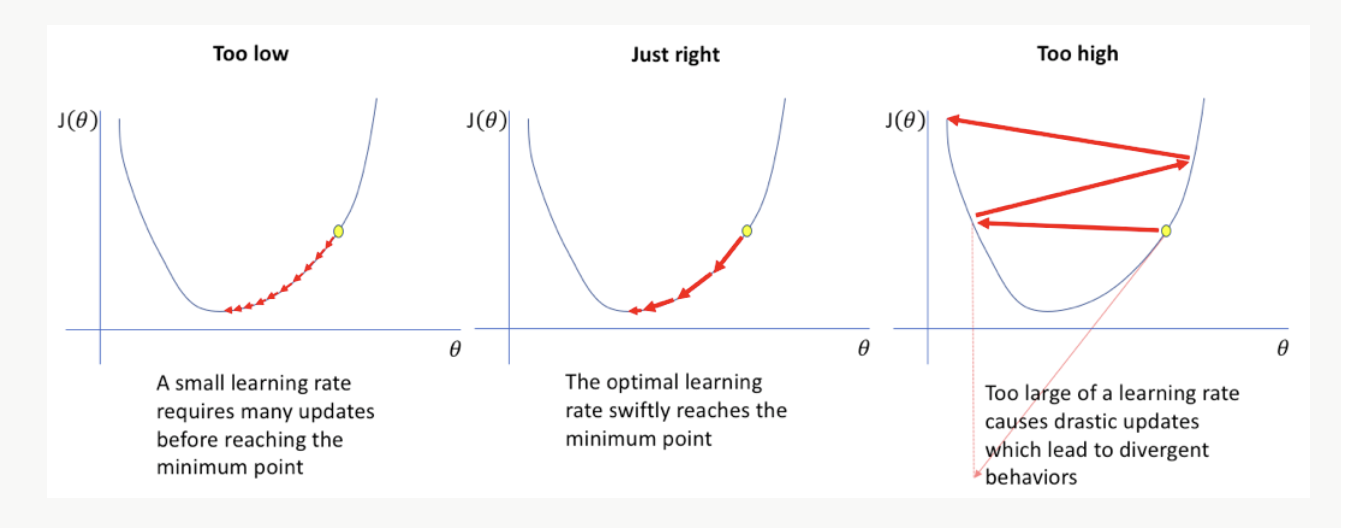
학습률(간격)이 너무 낮으면, 최대로 시행하여도 최소값에 도달하지 못한 채 경사하강법이 종료(좌측),
학습률이 너무 크면 최소값이 있을 범위까지 탐색할 수 없게(우측)됩니다.
그리고 너무 낮은 학습률은 학습 시간은 오래 걸리게 하기 때문에 모델의 성능을 위해서도 적절한 학습률 설정이 중요 학습하는 과정에 쓰이는 것
규제
-
Ridge(릿지, L2)회귀
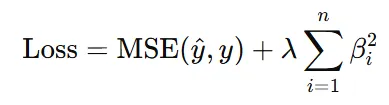
비용함수에 가중치의 제곱합(λΣβᵢ²)을 패널티로 추가
효과 : 가중치 크기를 줄임 -
라쏘 회귀 (Lasso, L1)
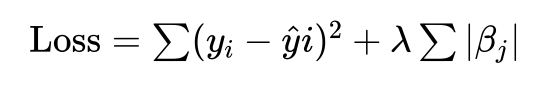
비용함수에 가중치 절댓값합(λΣ|βᵢ|) 항 추가
효과: 가중치를 0으로 만들어 변수 선택(Feature Selection) 효과
- 엘라스틱넷 (ElasticNet)

L1 + L2를 혼합
하이퍼파라미터 두 개: λ (정규화 세기), α (L1과 L2 비율)
효과 : 라쏘의 변수 선택 + 릿지의 안정성을 동시에 가져감
변수 선택도 가능하고 (L1), 계수 축소도 가능 (L2).
비선형회귀
(1) 회귀 트리 (Decision Tree Regressor)
데이터 분할 기반 예측
해석은 쉬우나 과적합 가능성 높음
(2) 앙상블 모델
랜덤포레스트 (RandomForestRegressor)
→ 여러 결정 트리를 평균하여 예측
그래디언트 부스팅 (XGBoost, LightGBM, GradientBoosti
→ 순차적으로 모델을 보완하며 예측 정확도 향상
회귀 평가 지표
실습하기
데이터 전처리
# casual, registered 는 비율로 변환 => 다중공선성 문제 해결 위함
# casual + registered = cnt
df['casual_prop'] = df['casual']/df['cnt']
df['registered_prop'] = df['registered']/df['cnt']casual: 비회원 이용자 수
registered: 회원 이용자 수
cnt: 총 이용자 수 (casual + registered)
다중공선성(multicollinearity) 회피
casual, registered는 cnt의 구성 요소
→ 회귀 모델에서 강한 다중공선성(multicollinearity) 문제가 생김
→ 그래서 비율로 바꿔서 구조를 분리
#불필요한 변수/ 다중공선성 위험 변수 제거
drop_columns = ['instant','dteday','casual','registered','registered_prop']
df.drop(drop_columns, axis=1, inplace=True)casual_prop + registered_prop = 1이므로
→ 둘 중 하나만 있어도 나머지 값은 자동으로 계산 가능
→ 그래서 둘 다 넣으면 정보 중복(다중공선성 발생)
→ 그래서 하나만 남긴 거야.
범주형 변수
범주형 변수 데이터 전처리시 bar plot 사용!
# 범주형 변수
fig, axs = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
cat_features = ['yr','mnth','season','hr','holiday','weekday','workingday','weathersit']
# cat_features에 있는 모든 칼럼별로 개별 칼럼값에 따른 count의 합을 barplot으로 시각화
for i, feature in enumerate(cat_features):
row = int(i/4)
col = i%4
# seaborn의 barplot을 이용해 칼럼값에 따른 count의 합을 표현
sns.barplot(x=feature, y='cnt', data=df, ax=axs[row][col])완전꿀팁
수치형 변수 데이터 전처리시 regplot/hist 사용
수치형 상관관계
# 수치형 변수- 피어슨 상관계수
con_features.append('cnt')
sns.heatmap(df[con_features].corr(), annot=True)
con_features.remove('cnt')annot = True 상관게수 출력
진짜 많은 도움이 된다..
모델의 성능을 높이려면 ㅎㅏ이퍼 파라미터를 건들던가 데이터 개수를 늘려야함..
L1 비율이 높다 =라쏘 비중이 올라감 = 피쳐 선택적인 경향성이 생김
실무에서 모델을 만들때는 어떤 변수가 중요한지 이해하는것도 중요함
action..
