TIL - 250417
머신러닝 라이브 - 군집
군집분석은 주기적으로 업데이트가 필요함
비지도는 나의 주관이 투영되어야한다(답이없잖아..)
클러스터링이란?
정답이 없을 때 정답을 찾아가는 과정
= 군집분석,
클러스터링은 데이터분석에서 피쳐(컬럼) 유사성의 개념을 기반으로 전체데이터셋을 그룹으로 나누는 그룹핑 기법각 그룹을 클러스터라고 함
데이터분석가는 의미있는 특징(컬럼)을 찾고, 최적의 그룹 갯수를 찾아 그룹별 인사이트를 도출해내는 역할을 수행
클러스터링 프로세스
프로세스(pre-processing)
기간 선정: 클러스터링을 위한 데이터 기간을 설정
의미있는 패턴을 도출하기 위해서는 최소 3개월 이상의 데이터셋이 권장.
(회사가 의도하는 목적에 따라서 유연하게 변경될 수 있다.)
기준이 뭐야? 모집단을 어떻게 설정하는지 결정하는게 기간선정.
클러스터링의 목적은, live 한 데이터의 유입시 해당 유저의 행동을 통해, 이를 알맞게 배치시키는 모델의 생성입니다. 해당 모델은 초기에 생성되고, 서비스 변동사항에 따라서 일정 주기에 따라 재시행.
이상치 기준선정 및 제외:
IQR, Z-SCORE 등 다양한 이상치 기법을 사용해보고, 이상치 비중을 기록.
이 역시, 통계적 기법이 사용될 수도 있겠으나 회사의 니즈에 따라 특정 조건에 따라 이상치의 기준을 정립하고 이를 적용하여 데이터 핸들링을 진행하기도
- 🌀 Z-Score
가장 많이 사용
데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지하는 방법
각 데이터(행) 마다 Z-score 를 구합니다. Z 값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값이며, 표준 점수라고 부름 표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여주며,
일반적으로 -3에서 3 사이의 값을 가지고 있다.
±3 이상이면 이상치로 간주하게 됨
- Z-Score : 0 해당 데이터는 평균과 같음을 의미(=평균에서 떨어진 거리가 0)
- Z-Score > 0 : 해당 데이터는 평균보다 크다. Z-Score가 1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 큰 값임을 의미.
- Z-Score > 0 : 해당 데이터는 평균보다 작음. Z-Score가 -1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 작음을 의미.
- 🌀 IQR(Interquartile Range)
- 데이터의 분포가 정규 분포를 이루지 않을 때 사용.
- 데이터의 25% 지점()과 75% 지점() 사이의 범위()를 사용합니다. 이를 벗어나는 값들은 모두 이상치로 간주
- IQR : (제 3사분위 값) - (제 1사분위 값)
- 이를 그림으로 그린 것= Box Plot, IQR 밖의 데이터 포인트는 이상치로 표시.
-
🌀 Isolation Forest
머신러닝 기법 중 하나로, 컬럼 갯수가 많을 때 이상치를 판별하기 용이
데이터셋을 결정트리 형태로 표현
- 결정트리는 질문에 질문들이 꼬리를 물고 이어져, 이에 각 값은 매, 펭귄, 돌고래, 곰 중 하나에 배치.
하지만 이상치의 경우, 이 어디에도 속하지 않을 확률이 높아 구분되지 x
- 한 번 분리될 때 마다 경로 길이가 부여되며, 트리에서 몇 번을 분리해야 하는지 (데이터까지의 경로 길이)를 기준으로 데이터가 이상치인지 아닌지를 판단. 즉 이상치는 다른 관측치에 비해 짧은 경로 길이를 가진 데이터
- 경로 길이로 점수는 0 에서 1 사이로 산출되며, 결과가 1 에 가까울수록 이상치로 간주
-
🌀 DBScan
밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지하는 방법, 복잡한 구조의 데이터에서 이상치를 판별하는 데 유용
주로 지리 데이터 분석, 이미지 데이터 분석의 이상치 기법으로 사용각 데이터의 밀도를 기반으로 군집을 형성시키고, 설정된 거리 내에 설정된 최소 개수의 다른 포인트가 있을 경우, 해당 포인트는 핵심 포인트로 간주
핵심 포인트들이 서로 연결되어 군집을 형성하며, 이와 연결되지 않은 포인트는 이상치로 분류
표준화(정규화):
데이터의 크기가 너무 크거나, 컬럼 간 데이터 range 에 차이가 많을 때 일부 컬럼에 대해 진행합니다.
- 🌀 minmax scale
모든 데이터의 값을 0과 1 사이에 배치. 이상치에 약하다는 특징
df[’pay_amt’] = 0,0,0,0,1,2,3,100 과 같은 값이 있다고 가정, 100 이 1에 배치되면서 나머지 값들은 상대적이나 0에 수렴하는 값을 가지게 되므로, 전체 데이터 분포가 뭉개지는 의미에서 이상치에 약하게 되는 것입니다!
- 🌀 standard scale
대표적으로 가장 많이 사용, 평균을 0, 표준편차를 1로 변환. minmax scale 이 가지는 한계점을 보완. standard scale 을 통해 각각의 data point 가 ‘평균으로부터 얼마나 떨어져 있는지’ 에 대한 수치로 변환가능, 군집분석시 가장 많이 쓰이는 표준화 기법.
여태 기준맞추기만 한 것.
차원 축소(PCA):
중요하다
차원 축소는 많은 컬럼으로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것(컬럼이 너무 많기 때문에 학습이 어렵고 더 좋은 특징만 가지고 사용하겠다는 것).
PCA는 가장 대표적인 차원 축소 기법. PCA는 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 기법.(데이터의 분포를 가장 잘 표현하는 성분을 찾아주는 것).
PCA 기법의 핵심은 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것인데, 이 축을 주성분이라고 함.
차원 축소의 목적은 크게 두가지로 나뉘게 됨.
😄 시각화: 데이터분석가가 PCA 의 결과를 눈으로 확인하기 위해서는, 축소된 차원의 개수를 2 또는 3으로 설정해야 함.
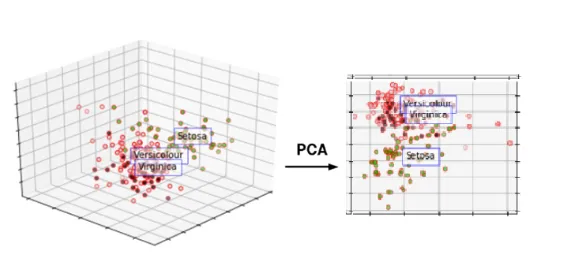
😄 Clusetring 성능향상: 축소된 차원의 개수를 4 이상으로 하거나, 설명 분산 비율 (explained variance ratio) 를 기준으로 설정
pca = PCA(n_components=0.95) # 전체 분산의 95%를 설명하는 만큼만 유지전체 데이터의 분산(정보)중에서 95%를 설명할 수 있을 만큼의 주성분만 자동으로 선택.
보통 ncomponents=3처럼 숫자로 명시하면 몇 개 쓸지 직접 정해야 하는데 개수를 정하지 않고 "정보의 양(=분산의 비율)"을 기준으로 차원 수를 자동 선택
explained_variance_ratio 기준으로 하면 정보를 충분히 살리면서도 불필요한 차원은 날려버릴 수 있음
이는 전체 시각화가 어렵다는 특징이 있는데 이 경우, 주성분 일부만 시각화하거나, Pairplot 으로 구현 가능하며, 경우에 따라서 고차원을 2 또는 3차원으로 축소하는 비선형 기법인 t-SNE / UMAP 이 사용될 수 있다.
PCA를 진행하는 두 가지 방식:
- 주성분의 개수(n_components)를 명시적으로 지정
PCA(n_components=3)
의미: "나는 무조건 주성분을 3개만 쓸 거야!"
장점: 주성분 개수를 고정해서 간단하게 다룰 수 있음
단점: 정보(분산)가 얼마나 담겼는지 보장 안 됨
→ 3개로는 너무 부족할 수도 있음
- 설명할 분산의 비율을 기준으로 자동 설정
PCA(n_components=0.95)
의미: "전체 데이터의 분산(정보) 중에서 95% 이상 설명할 수 있을 만큼만 주성분을 쓰자"
장점: 정보를 기준으로 똑똑하게 차원 축소
→ 상황에 따라 자동으로 주성분 개수를 정함
단점: 주성분 개수가 몇 개인지 미리 알 수 없음 → .ncomponents로 확인해야 함
프로세스(Experiment)
K값(군집갯수), 초기 컬럼(피쳐) 선정:
Silhouette Coefficient, elbow-point, Distance Map 을 통해 초기 군집의 갯수(K)를 지정. 초기 컬럼의 설정은 모든 컬럼을 기준으로 진행.
클러스터링을 반복진행하며, k값과 피쳐의 컨디션을 기록하고, 최적으로 구분된 컨디션을 찾게 됩니다. 경우에 따라서는 파생변수를 만들어 클러스터링을 진행하기도
-
🌀 Silhouette Coefficient(진짜참고)
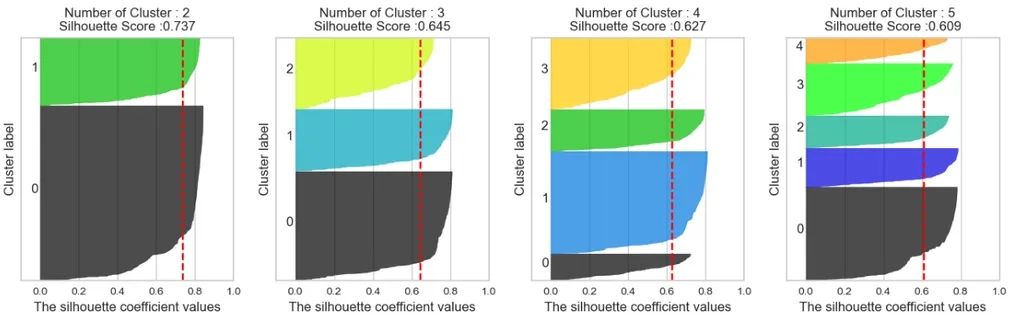
갯수가 많아질수록 score가 낮아짐(정상)
피쳐(컬럼)을 보고 판단해야함.
군집개수가 같은거끼리 피처를 바꿔서 score를 비교(제일 잘나오는 넘 사용)실루엣 분석은 각 군집간의 거리가 얼마나 효율적으로 분리되어 있는지를 나타냄.(효율적으로 잘 분리 되어있다 = 다른 군집과의 거리는 떨어져 있고, 동일 군집끼리 데이터는 서로 가깝게 뭉쳐있다는 의미).
실루엣 계수는 -1에서 1사이의 값을 가지며, -1이나 1에 가까울수록 근처의 군집과 멀리 떨어져있는 것이며 0에 가까울수록 근처 군집과 가깝다는 뜻.
즉, -1 이나 1에 가까울수록 군집 간 거리가 유의미하게 구분된다는 것을 의미.
- 🌀 scree plot의 elbow-point(유용)
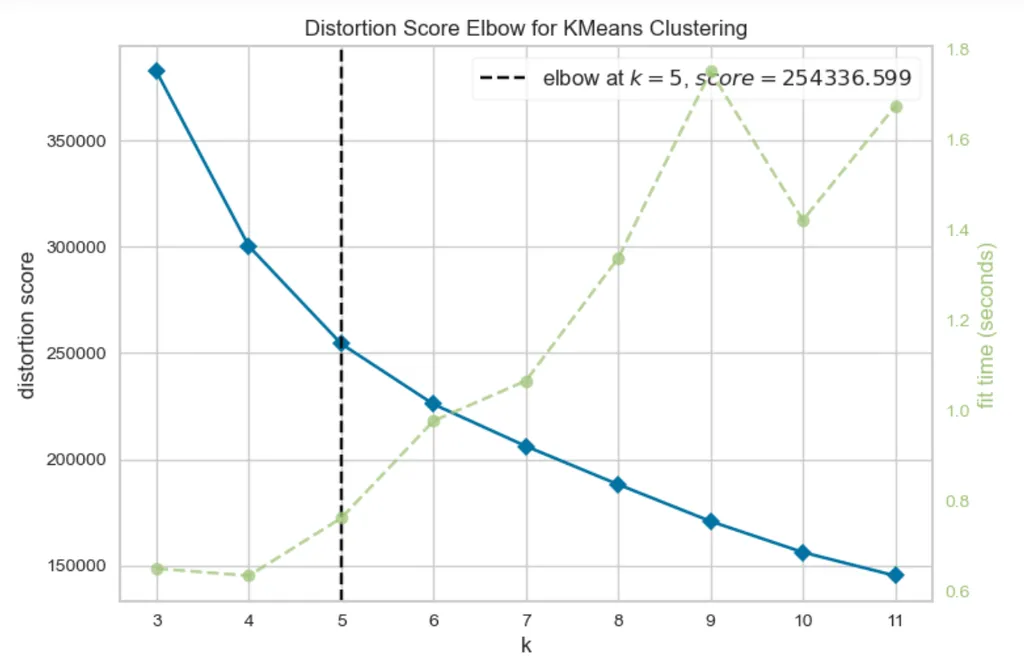
yellow brick library - elbow method를 사용하여, 알고리즘이 군집이 나뉘는 시간까지 고려한 k값을 도출해줍니다.
X축은 클러스터의 수 k (즉, 군집 개수)
왼쪽 Y축은 distortion score (또는 inertia라고도 불림) — 클러스터 안의 데이터들이 중심점에서 얼마나 멀리 퍼져 있는지를 나타냄. 작을수록 좋음.
같은 클러스터 안에 있는 데이터들이 중심점과 가까울수록 군집이 잘 된 거니까.
distortion score가 작다는 건? → 같은 클러스터끼리 잘 뭉쳐 있다! (좋은 군집)
오른쪽 Y축은 fit time — 각 k에서 모델을 학습시키는 데 걸린 시간
위 그래프에서 k=5일 때까지는 distortion score가 급격히 감소하고,
그 이후엔 줄긴 하지만 속도가 훨씬 느림 → 즉, 기울기가 완만해짐
그래서 k=5를 적절한 클러스터 수로 선택한 것
- 🌀 Distance Map(참고)
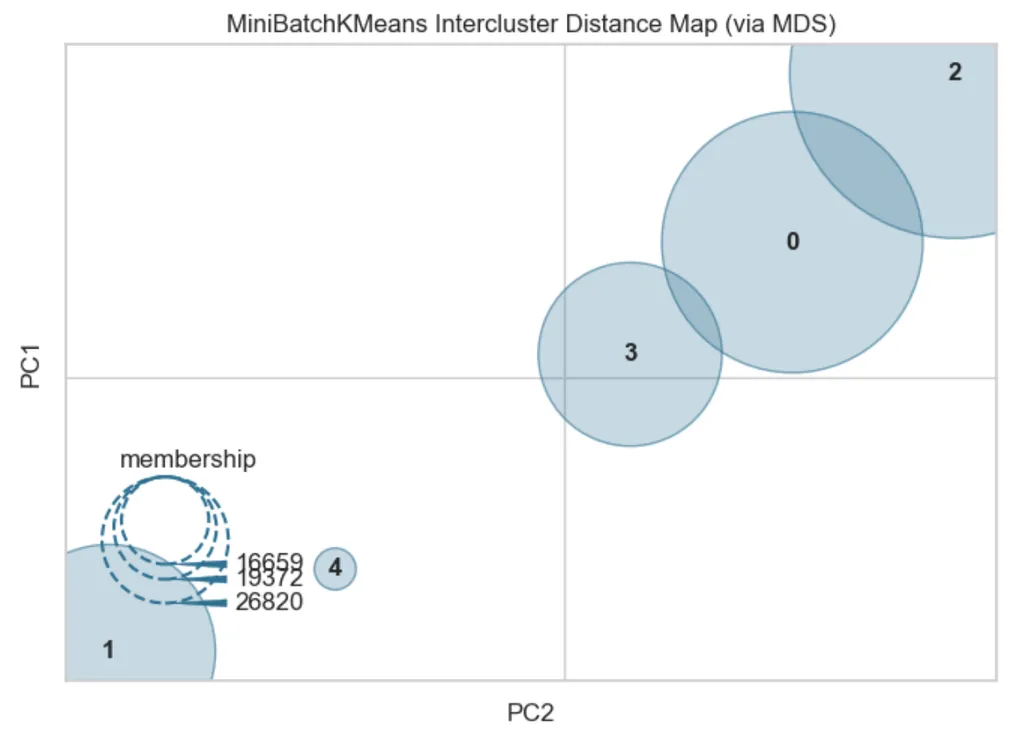
군집 간 거리를 시각화 해주는 기법, 실행마다 다르게 보여질 수 있다.
군집이 떨어져 있는 거리를 가시적으로 확인하기 위한 참고치
k-means clustering 시행:
데이터를 거리기반 K개의 군집(Cluster)으로 묶는(Clusting) 알고리즘입니다. K-means 알고리즘에서 K는 묶을 군집(클러스터)의 개수를 의미하고 means는 평균을 의미
각 군집의 평균(mean)을 활용하여 K개의 군집으로 묶는다는 의미입니다. (knn이랑 유사)
- 🌀 알고리즘
1. 군집 수 K 설정
2. 초기 중심점 K개 설정
3. 중심점을 기준으로 data point 들의 거리를 비교하고, 더 가까운 중심점에 군집할당
4. 할당된 점들의 중심점 위치 조정됨
5. 중심점의 위치가 변하지 않을때까지 반복
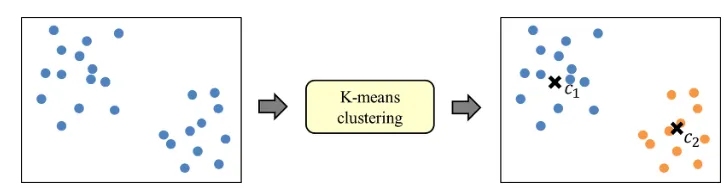
- 군집 분포 확인: 데이터셋을 기반으로 데이터가 잘(얼마나 밀도있게) 나뉘었는지 확인하는 과정
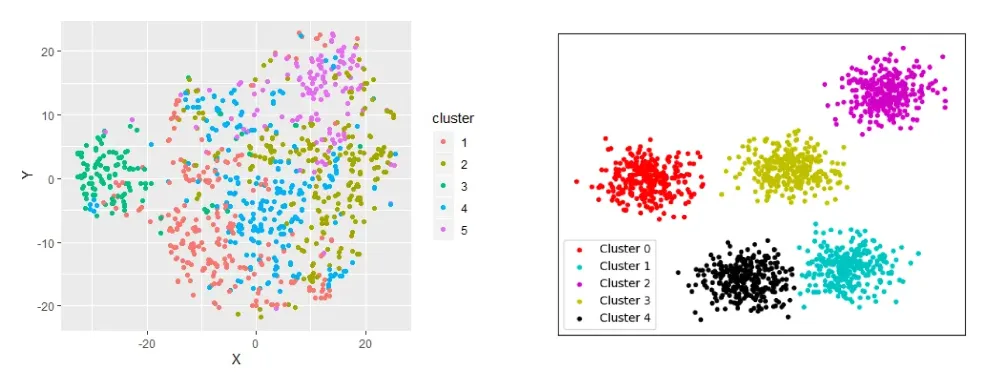
왼쪽에 보이는 scatter plot 은 군집이 잘 나뉘어지지 않은 것이 한눈에 보임.
K값과 컬럼(피쳐)를 조정하며, 오른쪽 scatter plot 과 같이 군집별 특성이 명확하고, 각각의 data point 가 충돌하지 않도록 실험을 반복해야함.
- 2~7번 과정을 반복하며 최적의 결과 도출: 실험을 수행할 때마다, 다양한 기준을 고려해야 함. 이는 통계학 적인 지식을 필요로 하지만, 이 부분이 클러스터링의 모든 부분을 설명해 주지는 않습니다. 비지도학습인만큼, 데이터분석가의 주관이 개입되어야 한다는 사실을 우리는 잊지 말아야 한다.
실험시 고려되어야 할 사항.
| • 한명의 고객에게 하나의 클러스터 매핑이 되었는지? (클러스터링시 unique id는 빼고 진행) |
|---|
| • 데이터 자체에 결측이 많지는 않은지? |
| • 데이터가 결측은 아니나, value가 0인 경우가 많은지? |
| • 데이터의 전반적인 분포는 어떠한지?컬럼 간 상관계수는 어떠한지? |
| • 데이터가 불규칙한지? |
| • 컬럼이 가지는 개념적인 의미는 무엇인지? |
| • 컬럼값이 이진형인지? |
| • cluster 비중이 지나치게 편향되어 있는지? |
편향: 하나의 군집이 전체의 절반을 차지한다면 다시 돌려야 함
-
모델링: 클러스터링 결과를 가지고 이를 모델에 학습시켜줌. 모델은 우리가 실험한 로직을 매번 수행하지 않도록 해주는 중요한 개념.
-
데이터 적재 및 자동화 설정: 이렇게 cluster 별로 나뉜 고객들을 별도 테이블에 저장. 이 모든 과정은 python 으로 진행될 수 있어요. 스케줄 기능을 통해, 주기별로 라이브한 데이터를 자동 테이블 적재하는 것까지가 클러스터링의 최종 작업이라고 할 수 있겠습니다.
-
인사이트 도출: 이렇게 적재된 테이블을 가지고 우리는 클러스터별로 인사이트를 도출할 수 있게 됩니다.
머신러닝 라이브 - 군집 실습
# pca임의 시행, 3차원 축소
pca = PCA(n_components=3)
pca.fit(scale_df)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
pca.explained_variance_ratio_.sum()Pca로 차원을 3개로 줄였다
= 기존 모든 feature을 섞어서 완전히 새로운 축을 3개 만들었다
(기존열을 혼합해서 새로운 좌표계로 바꾼 것)
import pandas as pd
# 각 주성분에 대해 원래 feature의 기여도 확인
pd.DataFrame(pca.components_, columns=scale_df.columns, index=['PC1', 'PC2', 'PC3'])pca.components_란?
주성분(Principal Components)이 기존 feature들로 어떻게 구성되어 있는지 나타내는 행렬
각 주성분(PC1, PC2, PC3...)이 원래의 feature들을 얼마나 섞어서 만들었는지를 나타내는 값들임.
KMeans
# KMEANS
# 군집개수(n_cluster)는 5,초기 중심 설정방식 랜덤,
kmeans = KMeans(n_clusters=5, random_state=42, init='random')
# pca df 를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_labels처럼 밑줄()이 붙은 속성은 모델이 학습하면서 만들어낸 결과
각 데이터가 속한 클러스터 번호(군집결과)를 알려줌 (리스트 형태)
📌 Scikit-learn (
sklearn) 속성 규칙 정리
| 타입 | 예시 | 의미 |
|---|---|---|
| 메서드 | .fit(), .predict() | 모델에 동작을 수행 (학습, 예측 등) |
| 일반 속성 | .n_clusters, .init | 사용자가 설정한 하이퍼파라미터 |
| 학습 후 생성되는 속성 💡 밑줄 _이 붙음 | .labels_, .cluster_centers_, .inertia_ | 모델이 .fit()을 통해 학습한 결과값 |
🧠 대표적인
_속성 목록
| 속성명 | 의미 | 사용 예시 |
|---|---|---|
labels_ | 각 데이터가 속한 클러스터 번호 | kmeans.labels_ |
cluster_centers_ | 각 군집의 중심점 좌표 | kmeans.cluster_centers_ |
inertia_ | 군집 내 거리 제곱합 (작을수록 좋음) | kmeans.inertia_ |
components_ | 주성분을 구성하는 벡터 (PCA) | pca.components_ |
explained_variance_ratio_ | 주성분이 설명하는 전체 분산의 비율 | pca.explained_variance_ratio_ |
feature_importances_ | 각 특성의 중요도 (트리 기반 모델에서) | model.feature_importances_ |
coef_ | 학습된 가중치 계수 (선형 회귀 등) | model.coef_ |
intercept_ | 절편 (y절편) | model.intercept_ |
💡 참고: fit()을 하기 전에는 _ 속성들이 생성되지 않아.
→ 즉, 학습 후에만 생긴다는 게 핵심!
3차원
plt.subplot(111, projection='3d')
ax.scatter(x, y, z, s=60, c=kmeans_df["Cluster"], marker='*', alpha = 0.7, cmap = 'Pastel1')plt.subplot(111):
전체 subplot 레이아웃: 1행 1열
그 중에서 1번째(=유일한) subplot을 그리겠다
결론: 그냥 "하나만 그릴 거다" 라는 뜻!
✨ 예시 몇 개 더 볼까?
plt.subplot(121) # 1행 2열 중 → 1번째 subplot (왼쪽 차트)
plt.subplot(122) # 1행 2열 중 → 2번째 subplot (오른쪽 차트)plt.subplot(111, projection='3d')
= "하나짜리 subplot 만들 거고, 3D로 그릴래요!" 라는 뜻
s=60: 각 데이터 포인트의 크기가 60(기본값 20)
